1. 개요
Django QuerySet API reference를 보던 중 QuerySets are lazy / When QuerySets are evaluated에 대한 부분을 보고 직접 구현해봄으로써 확인해보고자 한다.
2. QuerySets are lazy
https://docs.djangoproject.com/en/4.1/topics/db/queries/#querysets-are-lazy
q = Entry.objects.filter(headline__startswith="What") q = q.filter(pub_date__lte=datetime.date.today()) q = q.exclude(body_text__icontains="food") print(q)
- 내용 中
세 개의 데이터베이스 적중처럼 보이지만 실제로는 마지막 줄( print(q))에서 데이터베이스에 한 번만 적중합니다. 일반적으로 QuerySet의 결과는"요청"할 때까지 데이터베이스에서 가져오지 않습니다. 그렇게 하면 데이터베이스에 액세스하여 QuerySet가 평가 됩니다. 평가가 수행되는 정확한 시기에 대한 자세한 내용은 QuerySets가 평가되는 시기 를 참조하십시오 .
3. When QuerySets are evaluated
https://docs.djangoproject.com/en/4.1/ref/models/querysets/#when-querysets-are-evaluated
- Iteration / Asynchronous iteration
for e in Entry.objects.all(): print(e.headline) async for e in Entry.objects.all(): results.append(e)
- slicing
보통 평가하지않은 쿼리셋을 슬라이스하는 것은 또다른 평가하지않은 쿼리셋을 반환한다. 하지만 step 파라미터를 포함한 경우에는 예외로 바로 평가하게 된다.# not hitting DB todo_list = Todo.objects.prefetch_related("user").all()[:5] # hitting DB todo_list = Todo.objects.prefetch_related("user").all()[:10:2]
- len() / list() / bool()
# len() entry_len = len(Entry.objects.all()) # list() entry_list = list(Entry.objects.all()) # bool() if Entry.objects.filter(headline="Test"): print("There is at least one Entry with the headline Test")
- repr()
entry_repr = repr(Entry.objects.all())
- Pickling/Caching
import pickle query = pickle.loads(s) # Assuming 's' is the pickled string. qs = MyModel.objects.all() qs.query = query # Restore the original 'query'.
4. Queryset 평가 시기 확인
지난번 [230131 - TIL] Django Logging - DB 접근 확인하기 (prefetch_related) 에서 사용한 코드 결과를 다시 확인해보자
todo_list = Todo.objects.prefetch_related("user") print("====== test ======") for todo in todo_list: print(todo.user)
쿼리셋
todo_list는 print문보다 앞서 정의되었지만 DB접근은 print문 이후 for문이 실행될때 1번만 실행되는 것을 알 수 있다.
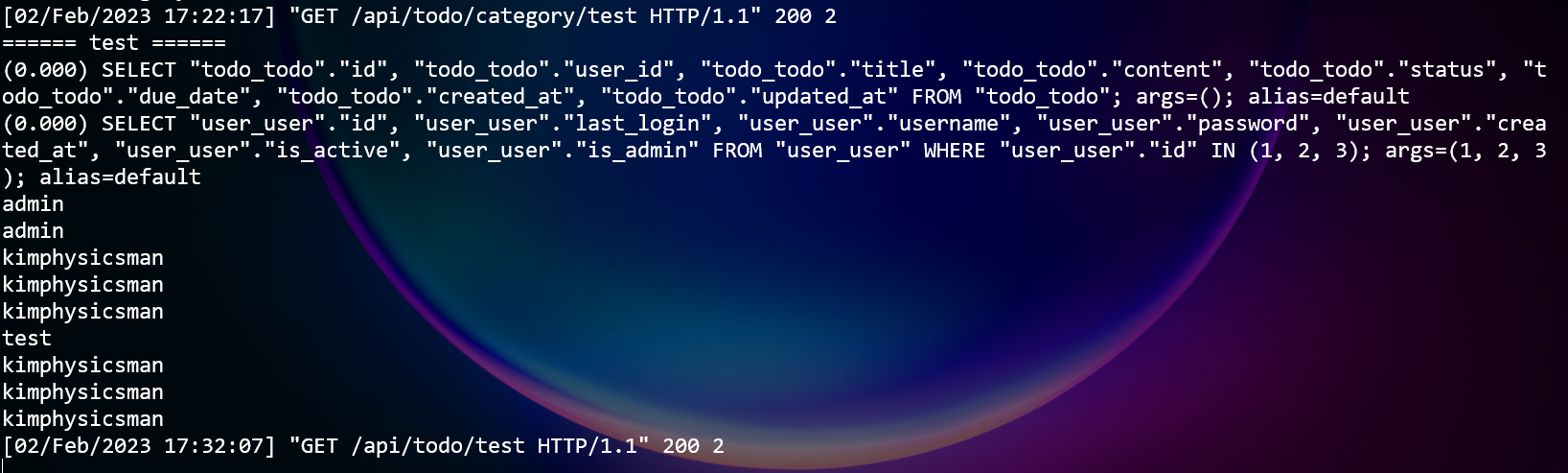
- repr()를 호출하면 어떻게될까
todo_list = Todo.objects.prefetch_related("user") print(repr(todo_list)) print("====== test ======") for todo in todo_list: print(todo.user)
print문 이전에 repr를 호출한 시점에 DB에 접근하는 것을 알 수 있다.

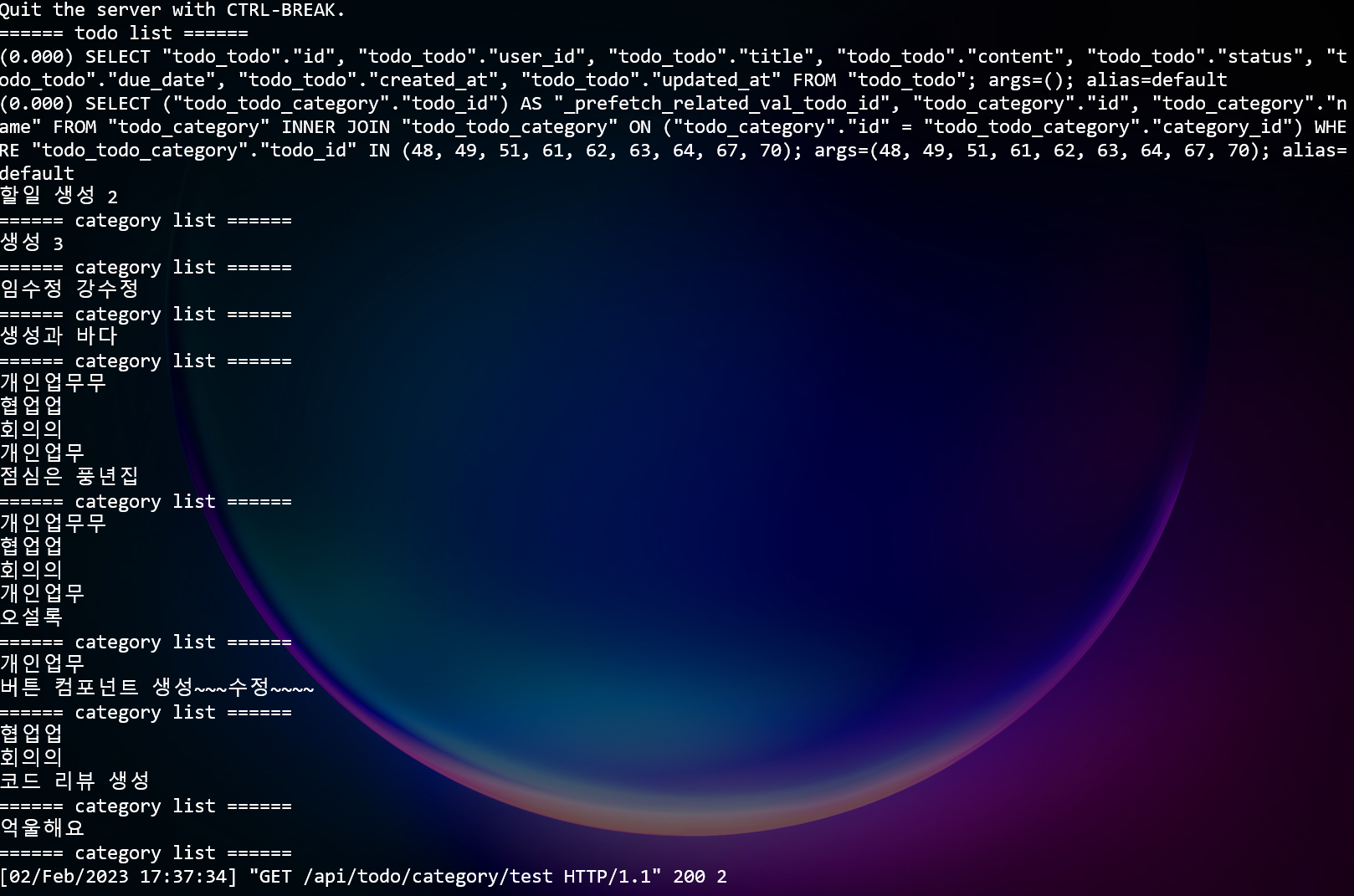
- ManyToMany 관계에서는?
todo_list = Todo.objects.prefetch_related("category").all() print("====== todo list ======") for todo in todo_list: print(todo.title) category_list = todo.category.all() print("====== category list ======") for category in category_list: print(category.name)
역시나 print문 이전에 선언된 쿼리셋이지만 for문이 실행될때 1번만 DB에 접근하는 것을 알 수 있다.
- slicing에 따른 DB 접근 순서
todo_list = Todo.objects.prefetch_related("user").all()[:5] print("--- test ---") for todo in todo_list: print(todo) todo_list = Todo.objects.prefetch_related("user").all()[:10:2] print("--- test ---") for todo in todo_list: print(todo)
첫번째 쿼리에서는 슬라이스를 해도 DB에 접근하지않고 print문이 먼저 실행되지만 두번째 쿼리에서는 print문보다 먼저 DB에 접근

참고

kimphysicsman