1. 개요
외부 API 리소스를 이용한 데이터 업데이트의 마무리작업으로 업데이트 속도 성능을 측정하고 개선하는 작업을 진행했다. 실제 데이터들을 대량으로 넣고 업데이트를 하니 생각보다 엄청 느렸고 어디서 시간이 오래걸리는지 찾아보고 어떻게 성능을 개선할 수 있을지 고민하다가 요즘 핫하다는 ChatGPT에게 물어보았다.
2. 기존 코드 & 성능
- 코드의 전체적인 구조는 다음과 같았다.
for raw_data in raw_data_list: data_obj = data.objects.get(shop=shop, data_no=raw_data["data_no"], data_code=raw_data["data_code"]) data_obj.info = int(float(raw_data["data_info"]["info"])) data_obj.save(update_fields=["info"])외부 API 응답데이로 받은
raw_data_list를 순회하면서 해당 데이터에 해당하는 객체를 get()을 통해 찾고 정보를 업데이트한뒤 다시 save()하는 식이다.
- 성능 : 3200여개의 데이터로 271초 소요
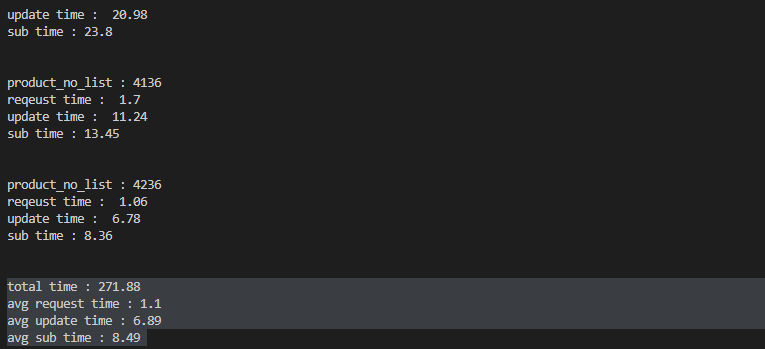
3. ChatGPT의 솔루션
1. get() -> filter()로 성능 개선
163초로 성능향상

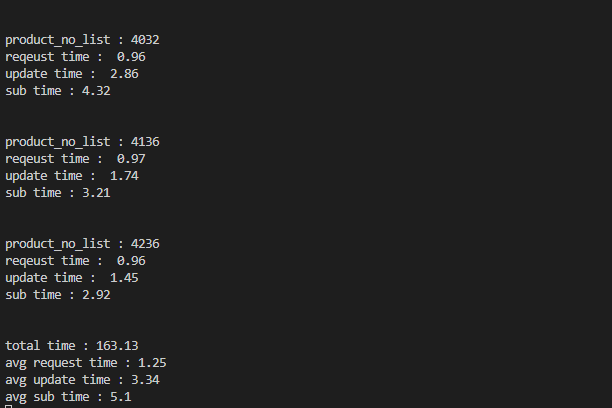
2. save() -> bulk_update()로 개선
68초로 성능향상
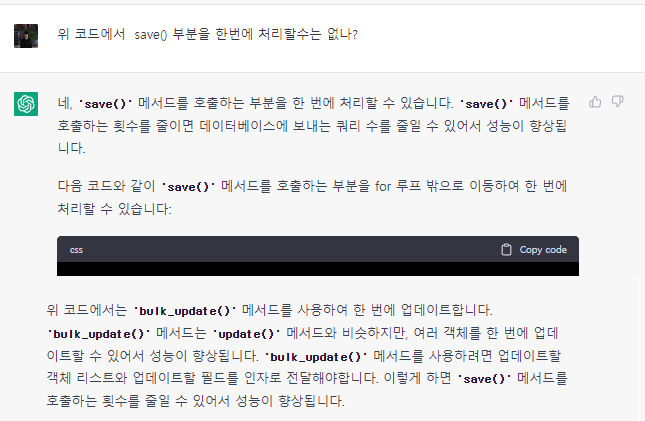

4. ChatGPT의 실수
하지만 그렇다고 해서 ChatGPT가 완벽한 것은 아니었다. 다음 내용을 보자. 위 개선 내용에서 사용한
bulk_update()에 대해서 물어보았다.
update() vs bulk_update()
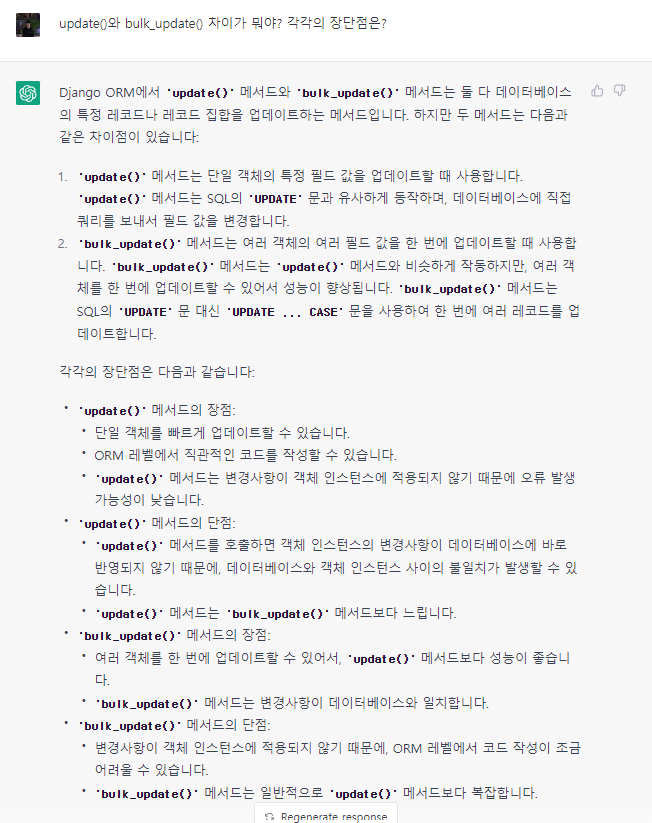

참고 문서를 주면 정확해진다.
위 대화내용처럼
update()와bulk_update()에 대한 특징을 서로 혼동해서 설명하거나 아예 다르게 설명하는 부분이 있었다. 따라서 ChatGPT를 사용하더라도 참고용으로 사용하고 내용에 대한 검증은 한번씩 다시 해봐야할 것이다.
팁이 있다면 두번째 대화내용처럼 공식문서와 같은 신뢰성있는 자료를 참고하라고 알려주면 좀 더 정확하게 알려주는 것 같다.
결론
결론적으로 ChatGPT가 제안한 개선방법만으로 속도가 70% 가까이 빨라졌다. 지금까지 토이프로젝트와 같은 작업만 했었기 때문에 실제 대량의 데이터를 다룰 때 무엇을 고려해할지 전혀 생각하지 않았었는데 ChatGPT가 좋은 가이드를 준 것 같다.
다만 아쉬운 점이 있다면 성능개선 방법을 고민할 때 전혀 기대하지않고 재미삼아 검색했던 것이라 먼저 내 스스로 방법을 찾아보거나 고민할 시간이 없었기 때문에 그냥 바로 정답지를 찾아본 것 같은 기분이 들긴 했다.
다음부터는 ChatGPT를 사용하더라도 먼저 스스로 방법을 찾아보고 고민하는 시간을 충분히 가져야할 것이다.
