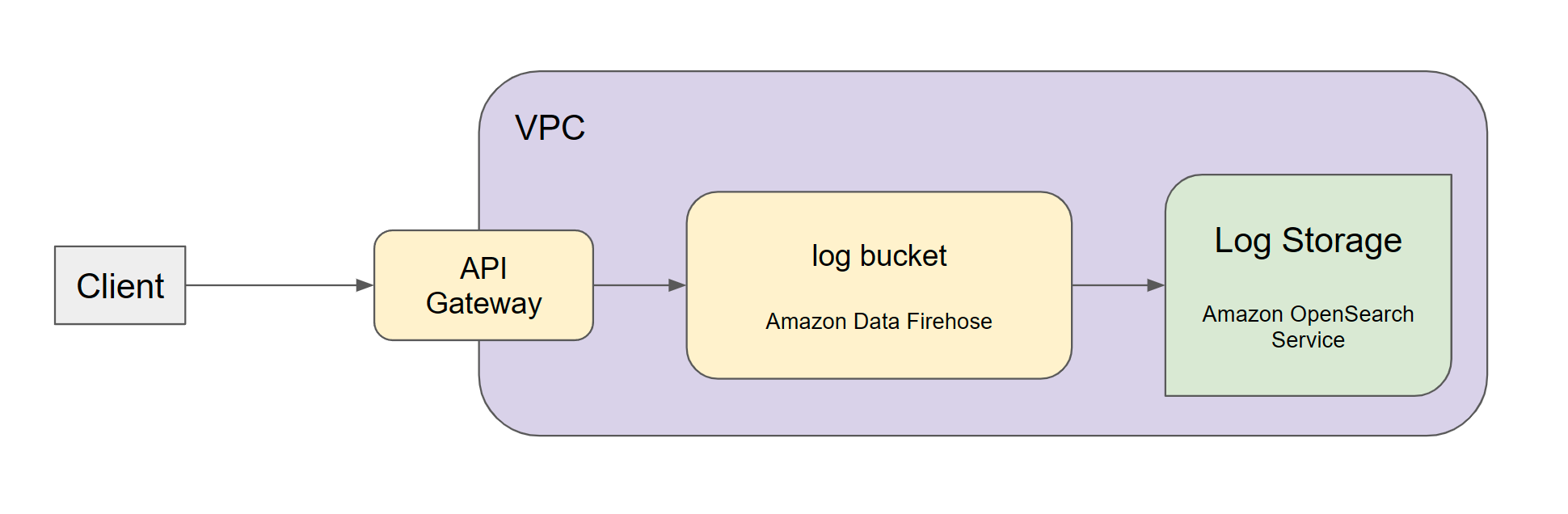
개요
이번 스프린트에서 유저활동데이터 수집을 위한 시스템을 구축할 기회가 생겼다. 사실 작년부터 해당 사항은 우리회사의 산개된 위성 서비스들이 모두 사용할 수 있는 통합 로깅 아키텍처를 설계했었다. 하지만 그 당시까지만 해도 로깅통합은 비중이 큰 작업이 아니었고 당장 닥친 데이터통합작업으로 무기한 연기되었던 것이 드디어 수면위로 올라오게된 것이다.
그 당시부터 지금까지의 히스토리를 한번 쭉 정리해보고자한다.
로그? 유저활동데이터?
유저활동데이터란 쉽게말해 웹에서 우리 서비스를 이용하는 유저들이 발생시키는 활동(이벤트) 데이터다. 유저가 특정 화면을 보는 것, 위젯을 클릭하는 것, 물건을 구매하는 것 등등 우리가 정의한 특정 행동을 이벤트로 취급한 하나의 로그데이터를 유저활동데이터라고 말할 수 있다.
이전까지는 그저 로그라는 비교적 범용적인 용어로 사용되었고 데이터 확인용 같은 비교적 단순한 용도로밖에 사용되지않았다. 하지만 앞으로 해당 데이터들을 기준으로 특정 기능을 서비스하거나 이벤트를 발생시키는 등 우리 서비스의 핵심적인 용도로 사용될 것이고 이를 위한 체계화된 관리 체계가 필요해진 것이다.
2023년 6월
로깅 관련 조사는 무려 1년도 더 전인 작년 6월즘에 최초로 시작되었다. 이 당시, 그리고 어느정도 데이터통합이 진행된 현재까지도 각 위성서비스들은 각자의 기능들에서 발생하는 웹로그들을 각자 관리하고있었고 대부분 각 서버로 로그를 전송하여 RDBS에 로그를 저장하는 식이었다. 하지만 이렇게 수많은 단순 로그성 데이터를 RDBS에 넣고 쿼리하여 데이터를 가져오는 방식은 당연히 좋지 않아보였다.
예상 시나리오 제작
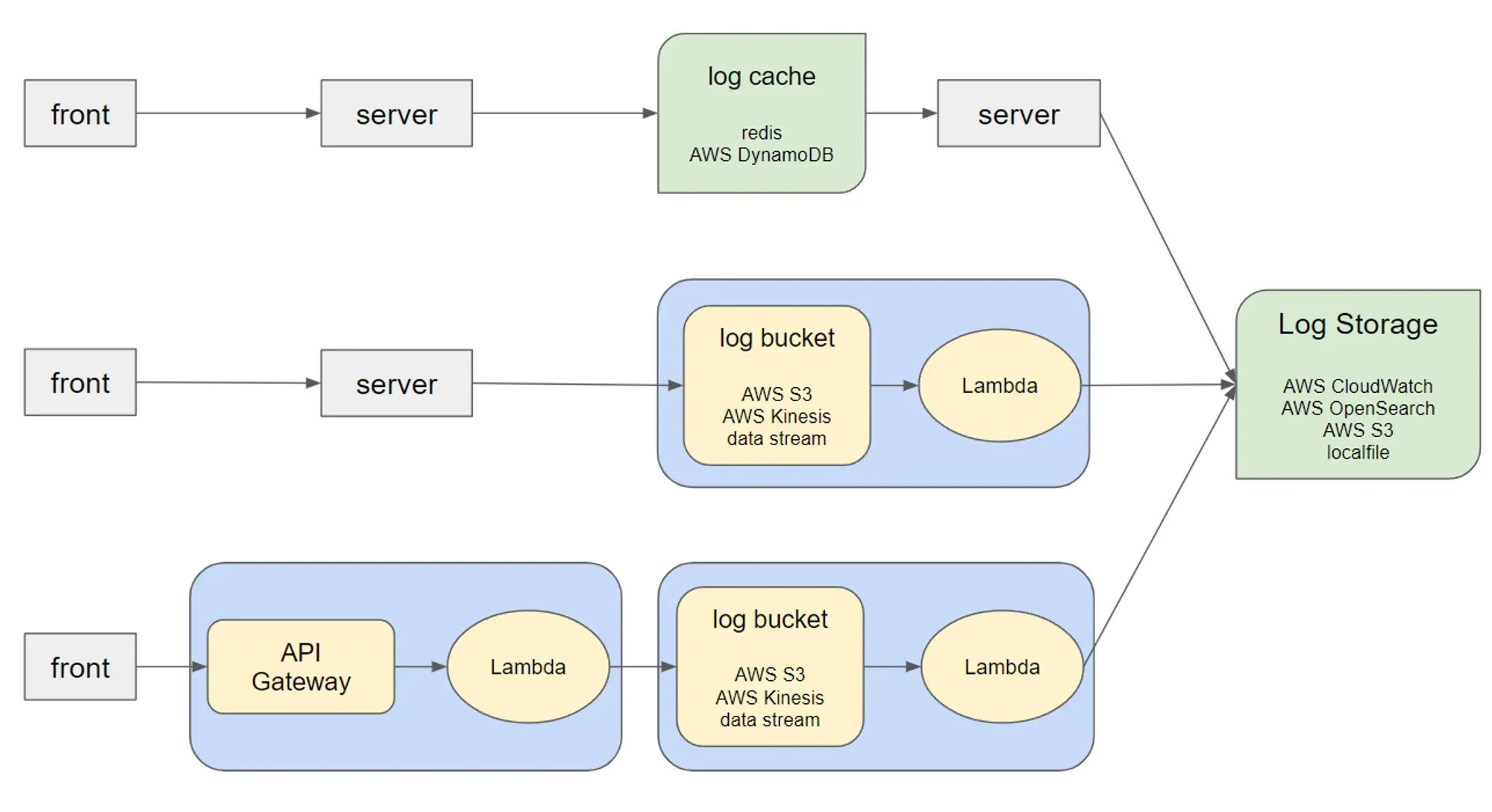
그 당시에 개발 6개월차였던 내가 각종 레퍼런스들을 찾아보며 생각했던 로그 관련 시나리오는 크게 위 3가지 방식이었다.
1번 방식 - 서버에서 로그데이터를 관리하는 방식
- front(웹) 에서 로그 데이터를 server로 전송
- server는 log cache(임시 저장 공간)에 이 로그데이터를 쌓아놓는다.
- 일단위로 log cache의 데이터를 다시 server가 log storage(실제 로그 관리용 저장공간)에 넣는다. log cache에서는 해당 데이터를 지운다.
2번 방식 - log bucket
1번 방식에서는 log cache의 데이터가 날라가버리면 그날의 데이터가 몽땅 날라가버리기 때문에 위험하다고 판단했다. 따라서 log cache가 아닌 log bucket(버퍼 역할)을 놓고 최대한 짧은 간격으로(하지만 log storage에는 무리가 가지 않을 정도로) log storage에 넣도록 하였다.
3번 방식 - API Gateway
하지만 2번 방식에서도 아직 해결되지 않은 문제는 앞단에서 모든 로그데이터의 요청을 서버가 감당해야하는 것이다. 그래서 3번방식에서는 완전 서버의 의존성을 지우고 API Gateway에서 해당 요청을 받으면 이를 lambda에서 log bucket에게 데이터를 이동시키도록 설계했다.
위 구조를 설계하면서 가장 중점을 둔 2가지는
-
log storage 역할을 RDBS가 하지않는 것.
앞서 말한 것처럼 수많은 로그데이터를 관계형 데이터베이스에 다 때려박고 쿼리를 통해 데이터를 분석하는 것은 좋지않다고 생각했고, 실제로도 많은 해당 시점에 많은 시간을 잡아먹고 있었다.
-
최대한 server로부터의 의존성을 끊어내는 것. == serverless 방식으로 설계하는 것.
로그데이터를 저장하는 것은 사실 우리의 비지니스 기능을 구현하고 동작하게 하는 server와는 사실 전혀 별개의 작업으로 볼 수 있다. 서비스에 이상이 생겼는데 로그가 수집이 안되거나 로그수집때문에 서비스에 이상이 생기는 것은 불필요한 문제라고 생각했다.
하지만 현실에서 가장 중요한 문제
따라서 위 2개의 기준으로는 당연히 3번 방식이 3가지 중에서 가장 개선된 방법이라고 생각할 수 있다. 하지만 현실에는 위 2개의 기준보다 더 중요한 문제가 존재했다. 바로 ‘돈’ 이다. 당시 내가 최선으로 생각한 구조를 위해서는 api gateway, lambda, kinesis data stream, opensearch service 등을 사용했고 당시 수집하던 로그데이터 양을 고려했을 때 발생하는 예상비용은 회사에서는 굳이? 라는 반응이였다. 때문에 최대한 요금이 발생안하도록 현재 사용중인 서비스들을 이용하는 식으로 얘기가 진행되었고 결국 1번 방식으로 elasticache, s3를 이용하기로 결정되었다.
그마저도 중간에 다른 작업에 밀려 잠시 홀딩되었다가 9월에서나 진행할 수 있었다. 그리고 어찌어찌 데이터검증까지 끝내며 어느정도 해당 시스템구축을 완성했지만 데이터통합작업이 시작되면서 적용할 시간이 없었고 결국 개선도 타협하여 어느정도만 하였지만 그마저도 미적용상태로 남는 결말을 맞이하였다.
2024년 10월
그 이후 난 다른 팀으로 옮겨가 각 위성서비스들을 통합관리하는 코어시스템을 구축했고 (여기서도 정말 많은 일들이 있었다) 지난 7월부터는 지금 있는 팀으로 옮겨와 개발 리드역할을 맡고있다. 그동안 개발팀 내외부적인 여러 문제들을 직면했었지만 그때마다 최선의 선택을 하려고 노력했고 또 믿고 따라주는 좋은 동료들 덕분에 극복할 수 있었다.
어쨋든 이제는 작년 6월과는 상황이 많이 달라진 것이다. 나도 내 스스로 문제해결을 위한 행동을 할 수 있는(책임을 질수있는? 져야하는?) 개발자가 되었고, 로그데이터에 대한 중요도도 거의 핵심이라고 할정도로 중요해진 것이다. 작년의 내가 구상했던 완전 serverless의 로깅 아키텍쳐를 유저활동데이터 수집이라는 명목으로 다시 제대로 구현해볼 기회가 온 것이다.
현재 시나리오
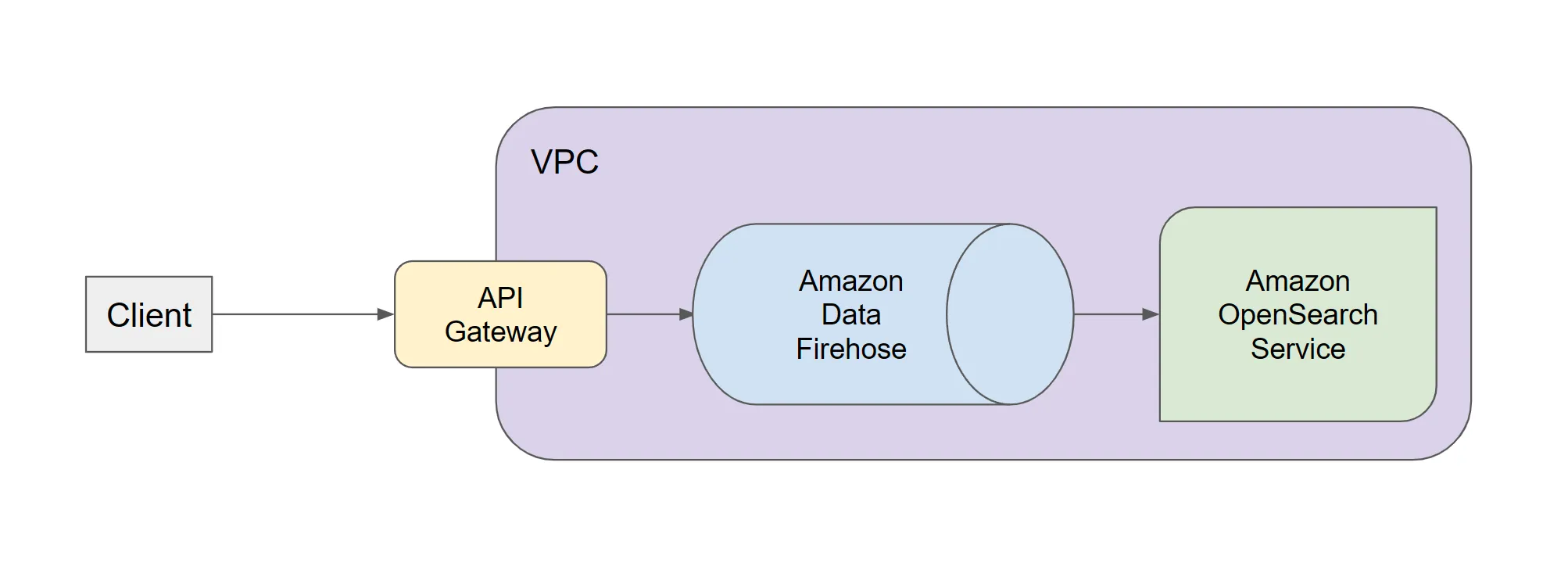
현재 구축한 시나리오는 다음과 같다. 과거 위 3번방식을 설계할 때는 Log Storage 역할인 Amazon OpenSearch Service에 데이터를 전송하는 역할로 Amazon Kinesis Data Streams를 생각했었는데 좀더 자료를 찾아보니 우리의 상황에는 Amazon Data Firehose가 더 적절하다고 판단했다. 그리고 각각의 단계별로 데이터 전송 역할을 lambda에 직접 코딩을 할 필요없이 AWS 설정만으로 유저활동데이터를 OpenSearch에 저장할 수 있었다.
고려사항
인덱스
데이터 범주를 나누는 단위이다. 해당 인덱스를 기준으로 쿼리를 하기 때문에 RDBS의 Table과 비슷한 개념이라고 보면 될 듯하다.
유저활동데이터를 조회하는 경우는 업체별 + 날짜별로 검색하는 경우가 많을 것이기 때문에 인덱스 구성 후보는 다음과 같았다.
alpha-data: 단순히 유저활동데이터를 명시한 인덱스. 업체명이나 날짜를 쿼리 정보가 넣어야한다.alpha-data-{shop_id}: 업체별로 데이터를 나눈다.alpha-data-{shop_id}-{year}-{month}: 업체별+년월별 데이터를 나눈다.
하지만 Firehose에서 OpenSearch로 데이터를 넘겨줄때 인덱스를 설정해야했으므로 1번으로 설정하되 firehose에서 월별 인덱스를 롤링하는 식으로 설정했다. 결론적으론 alpha-data-{year}-{month}가 되었다.
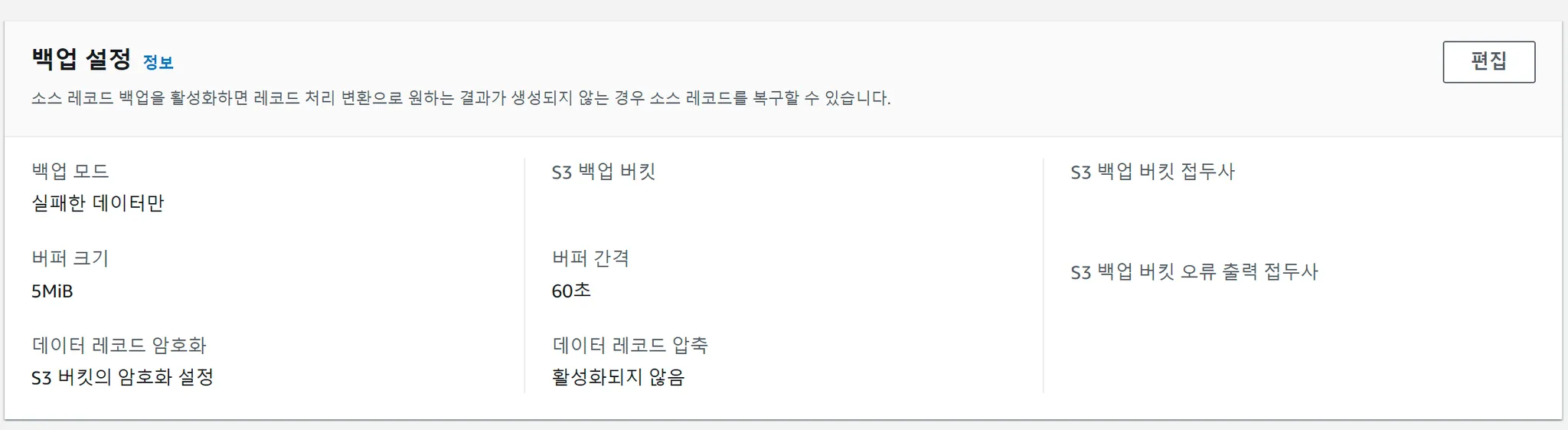
버퍼 및 오류로그 설정
Amazon Data Firehose에서 Amazon OpenSearch Service로 데이터를 전송할때 버퍼설정을 할 수 있다. 5Mib/300초가 기본값이고 현재 이 값을 사용해도 문제없을 것으로 예상하고 있다. 또한 전송시 에러가 발생하면 에러로그나 백업데이터를 S3에 저장할 수 있다. 이때 s3에 전송할때도 버퍼설정이 가능하고 5Mib/60초로 설정하였다. 즉, API Gateway로 요청을 보내더라도 실제로 Opensearch에 저장되기까지 5분이 걸리고 에러가 발생했다면 1분더 딜레이가 걸려서 s3에 저장된다는 뜻으로 볼 수 있다. (해당 설정 기준 경험상 10분까지도 더 걸리는 것 같다.)
남은 개선점
-
현재 API Gateway에서 요청받은 유저활동데이터가 Amazon Data Firehose를 거쳐 Amazon OpenSearch Service까지 저장하는 것까지만 테스트가 완료된 상태다.
이제 client의 script에서 API Gateway에 요청보내는 로직을 SDK로 감싸 캡슐화하는 것을 고민하고있다.
-
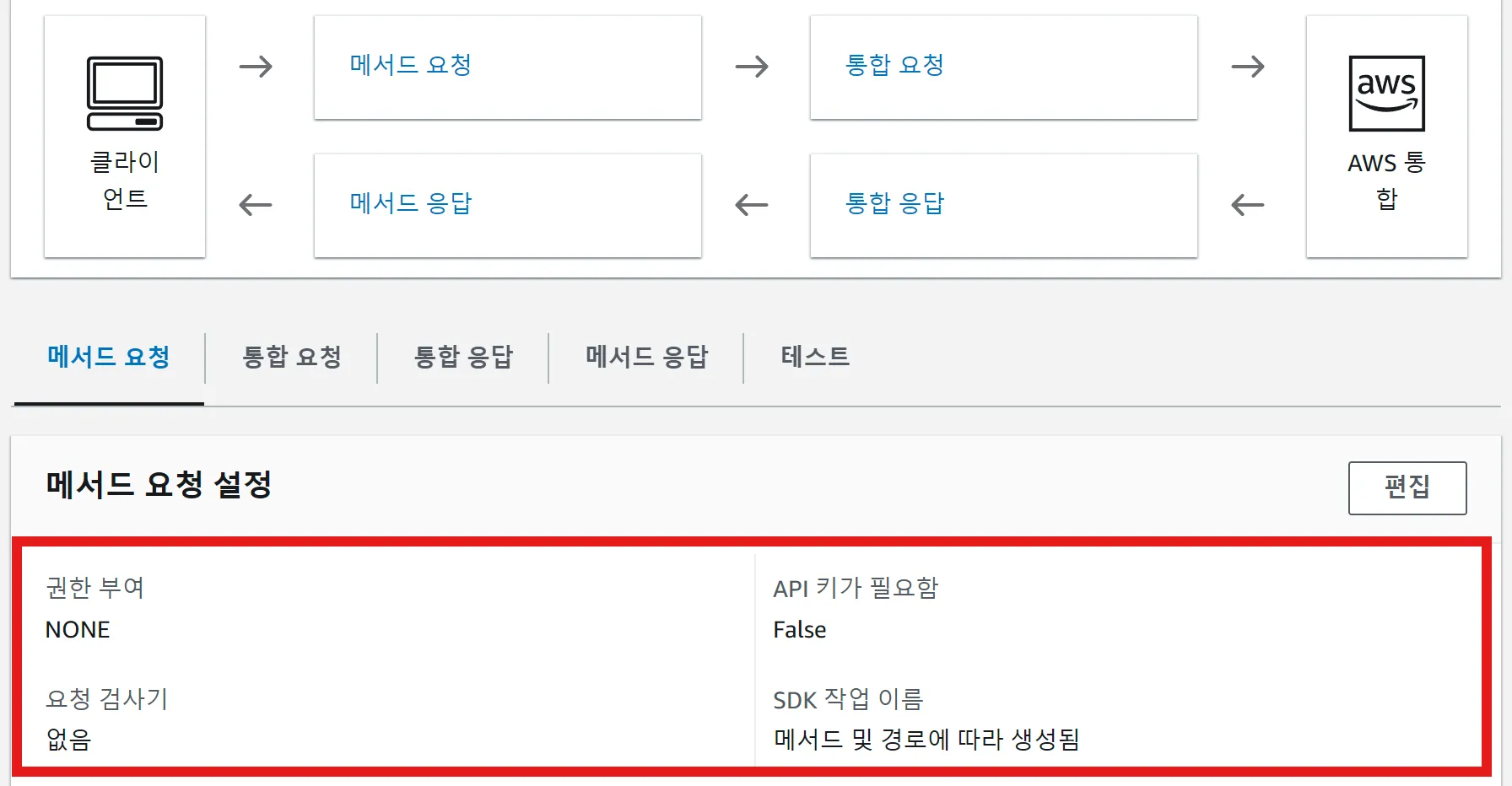
또한 현재 유저활동데이터의 요청에 대한 어떠한 인증절차가 존재하지않는다. 추후에는 API Gateway의 메소드 요청 설정에 인증 절차를 추가할 계획이다.
-
데이터 조회
OpenSearch 대시보드를 이용하면 datadog 대시보드처럼 다양한 인사이트를 만들 수 있다. 하지만 그만큼 설정해줘야하는 것들이 많기 때문에 이는 나중에 유저활동데이터를 활용한 요구사항이 많아질 경우 작업될 것 같다.
-
동시성
Amazon Data Firehose에 버퍼 설정이 되어있지만 이걸로 모든 유저활동데이터를 감당할 수 있을지는 지켜봐야할 것 같다.
트러블슈팅
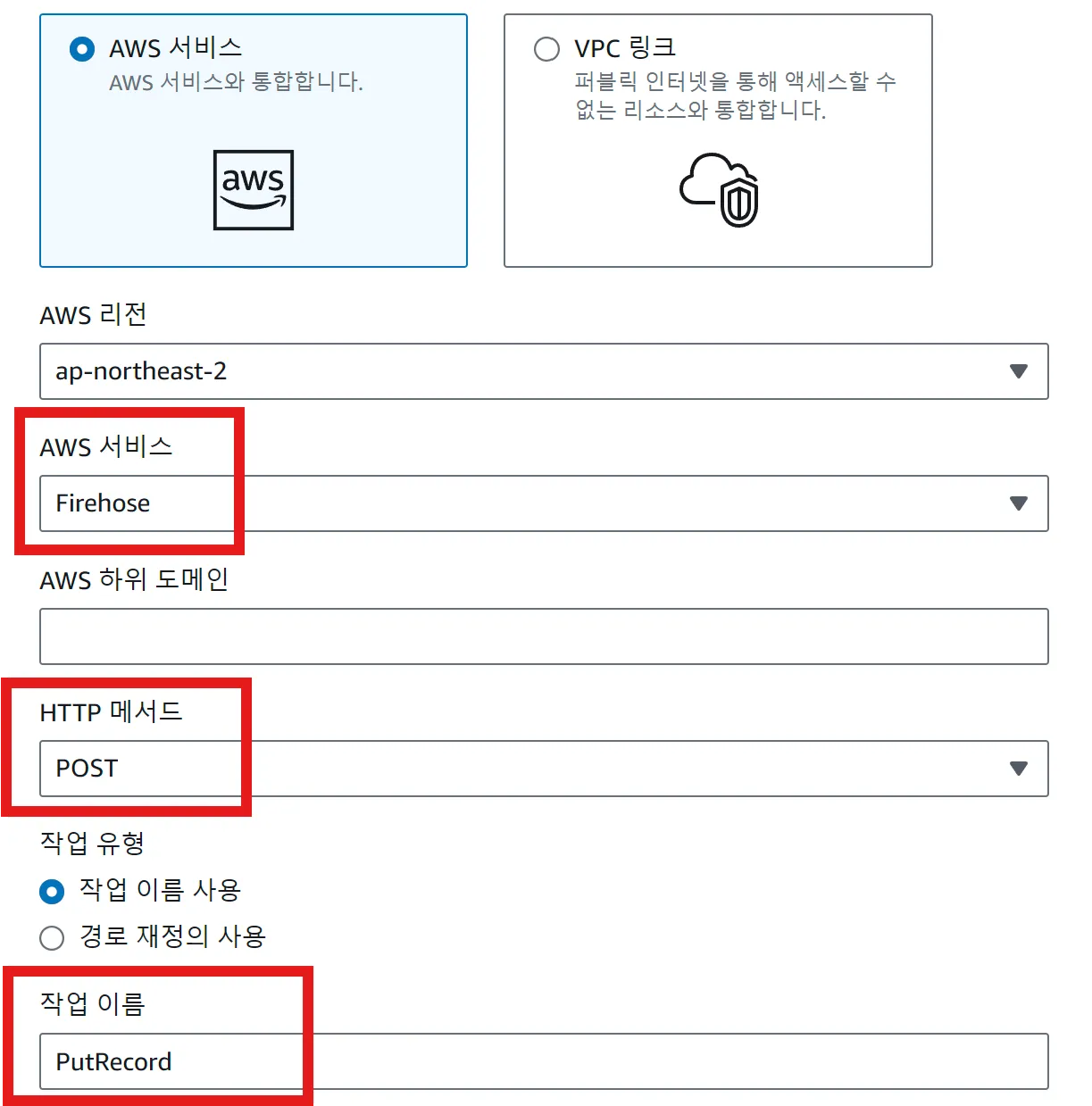
API Gateway에서 Amazon Data Firehose을 대상 설정시 매핑 템플릿
API Gateway에서 Amazon Data Firehose로 요청을 전달하면 다음과 같은 에러가 응답되었다.
{"__type":"SerializationException"}원인은 Amazon Data Firehose는 데이터를 바이너리로 관리하기 때문에 작업명 설정과 함께 매핑 템플릿을 정의해줘야했다.
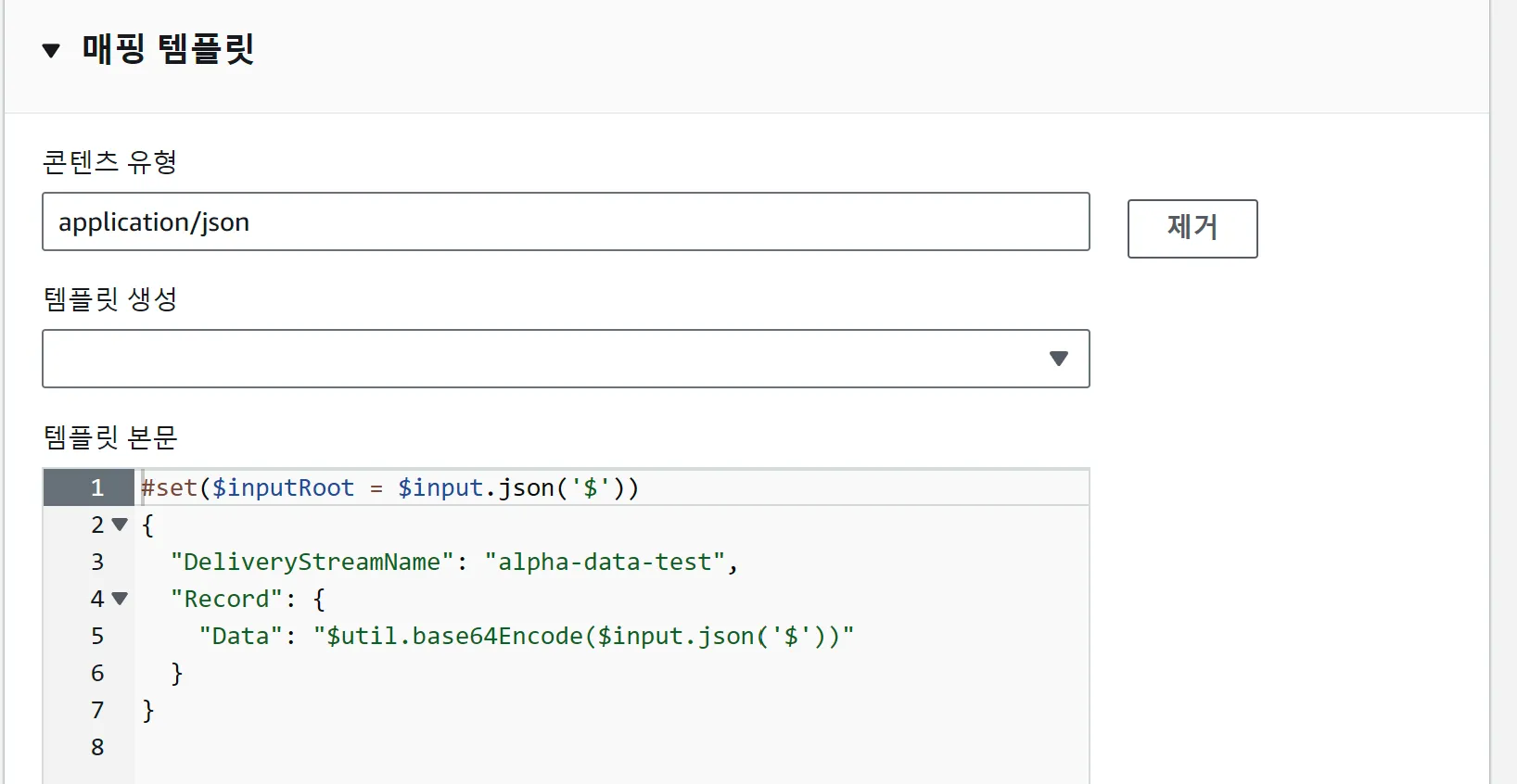
#set($inputRoot = $input.json('$'))
{
"DeliveryStreamName": "alpha-data-test",
"Record": {
"Data": "$util.base64Encode($input.json('$'))"
}
}
OpenSearch 내에 권한 설정
Amazon Data Firehose에서 데이터를 Amazon OpenSearch Service로 전송할 떄 계속 아래와 같은 권한 에러가 발생하며 전송되지않았었다.
[security_exception] no permissions for [indices:data/write/bulk] and User [name=arn:aws:I am::<account_id>:user/my_user, backend_roles=[], requestedTenant=null]처음에는 Amazon Data Firehose의 IAM 역할과 Amazon OpenSearch Service의 정책 설정에 문제가 있는 것 같아서 해당 설정을 변경해가며 테스트해보았는데 해결되지않았다.
관련 이슈를 찾아보다 아래링크에서 힌트를 얻었고 AWS 내 권한 설정이 아닌 OpenSearch 내부에서 권한 설정을 해야한다는 것을 알게되었다.
OpenSearch 대시보드내에서 Security > Roles 에서 Firehose의 IAM을 역할을 indices:data/write/bulk 권한이 포함되도록 등록해주면되는데 나는 all_access 라는 역할에 해당 IAM 역할 arn을 추가하는 것으로 해결했다.

느낀점
사실 작년에 로깅시스템을 열심히 Serverless 방식으로 설계하고 OpenSearch에 대해서도 엄청 조사하고나서 현실적인 문제로 이를 적용시킬 수 없었을 때에는 굉장히 허무하기도 했다. 또 어찌어찌 개선된 구조로 구축해놓고도 실제로는 미적용한 상태로 다른 작업으로 넘어갔을 땐 진짜 지금까지한게 있는데 아무것도 바뀐게 없어서 걱정되기도 했다.
하지만 시간이 지나서 보니 그 결정하나하나가 다 의미가 (선택의 이유가) 있는 것들이었다.
-
로그를 서버가 감당하고 RDBS로 쿼리를 하더라도 지금까지 큰 문제가 있었던 것은 아니었다.
당시에 그걸 해결하면 좋았겠지만 그러면 그만큼 리소스를 소비하고 다른 일을 못했을 것이다. 결과론적이지만 현재 기준에서 적당히 그렇게 둔것이 오히려 더 최선의 선택이었다고 할 수 있겠다.
-
OpenSearch에 대해 공부했던 것은 1년이 훌쩍넘어 지금 써먹고 있다.
만약 지금 OpenSearch에 대해 처음 알아보고자 했다면 그때처럼 자세하게 조사하진 못했을 것이다. 이것말고도 신경써야하는 것이 많으니까. 돌이켜보니 그 당시에는 따로 할게없어서 그것에만 몰두에서 자세히 기록해놓고 문서화 해놓은 것이 지금와서보니 정말 보석같아보였다.
그래서 앞으로는 지금 당장 내가 할 수 있는 일에 더 집중해야겠다는 생각이 들었다. 요즘 리드역할을 맡으면서 신경쓸 것들이 많아지니 이것도해야되는데, 저것도해야되는데 하는 생각들이 날 유혹할때가 많다. 하지만 정작 그런 생각들 때문에 아무것도 제대로 못하고 깨작깨작 시간이 지날때가 많았다. 그래서인지 최근에 분명히 한 일은 많은데 뭔가 기록으로 나중에 확인할 수 있는 것들은 많지 않았다. 이런 시점에 과거 내가 딱 하나만 할 수 있던 시절에 그거 하나라도 제대로하려고 이것저것 찾아보고 기록해놓고 했던 것들을 보며 도움을 받아보니 지금이라도 다시 시작하자는 생각이 들었다. 예전에 작성했던 TIL을 다시한번 읽어보러 가야겠다.
Reference.
https://aws.amazon.com/ko/solutions/implementations/centralized-logging-with-opensearch/
