본 시리즈은 비전공자가 공부한 computer science, 그중에서도 컴퓨터구조를 정리한 글입니다. 틀린내용이 있다면 댓글로 알려주시면 정말정말 감사하겠습니다. 참고한 책은 Computer Organization and Design MIPS Edition입니다

오늘은 본격적으로 내용을 정리하기전에 컴구를 공부하면서 느꼈던점을 간단하게 말하고 시작하겠습니다. 뭔가 공부하면할수록 세상이 넓어지는 느낌이랄까요.
처음에는 컴구를 공부하는데 코딩하는데 한번도 본적없고 볼일없을거같은걸 공부하는 느낌이라 이걸 대체 왜 공부해야하는지 차라리 이럴거면 네트워킹을 공부하는게 낫겠다라는 생각도 하긴했었습니다 의문이 들었는데 제 기준으로는 오늘 포스팅하는 내용을 공부한 순간부터 컴퓨터구조라는 과목을 다시 보게되었답니다...
그러면 잡담은 그만하고 본격적인 내용에대해서 알아보도록 하겠습니다!
Procedure and Stack
처음에 procedure이라는 단어가 너무 낯설어서 검색을 해보니
어떤 특정 작업을 수행하는 함수
네.. 그냥 함수라네요 function밖에 몰랐는데...
아무튼 함수와 스택이라는 주제입니다
우리가 맨날 코딩을할때 함수를 쓸때 어떤 step으로 실행되는걸까요? parameter들은 어디다가 저장되는걸까요? 내부 local변수는 어떤식으로 저장되고 사용되는걸까요? 이런 의문이 들으셨던 분이라면 이 내용을 공부하고 나시면 궁금증이 해소되실거같아요
우선 본격적인 내용에 대해 알아보기전에 큰 그림을 좀 그리고 가보겠습니다.
- Place parameters in registers
- Branch to procedure
- Acquire storage for procedure
- Perform procedure’s operations
- Place result in register for caller
- Return to the caller
영어지만 괜찮습니다. 우리에겐 파파고가 있으니까요! 도와줘요 파파고
우선 1번을 보면 파라미터를 register에 저장한다고 합니다.
2번을 보면 함수로 branch한다고 하네요.
3번으로 가볼까요 함수를 위해 storage를 할당한다고하네요. 이건 함수내부에서 사용할 변수들을 위한것으로 보입니다.
4번은 함수를 수행하는 step인거같고 5번은 결과를 register에 저장한다고 합니다. 그리고 마지막으로 caller로 돌아간다고 합니다.
사실좀 정리가 잘 안되는거같아서 간단하게 그림으로 정리를 해봤습니다

1번 step에 있던 파라미터를 register에 저장의 파라미터들은 노란색변수를 의미합니다. 그리고 3번 step에 있던 함수를 위해 storage를 할당의 의미는 그림에서 초록색처럼 함수를 실행하면서 임시로 만든 local 변수를 위해 메모리를 만들어두겠다는 겁니다. 마지막으로 return은 파란색을 이야기합니다.
그러면 이번엔 전체적인 흐름을 한번 파악해보겠습니다. 아래 사진을 보시죠
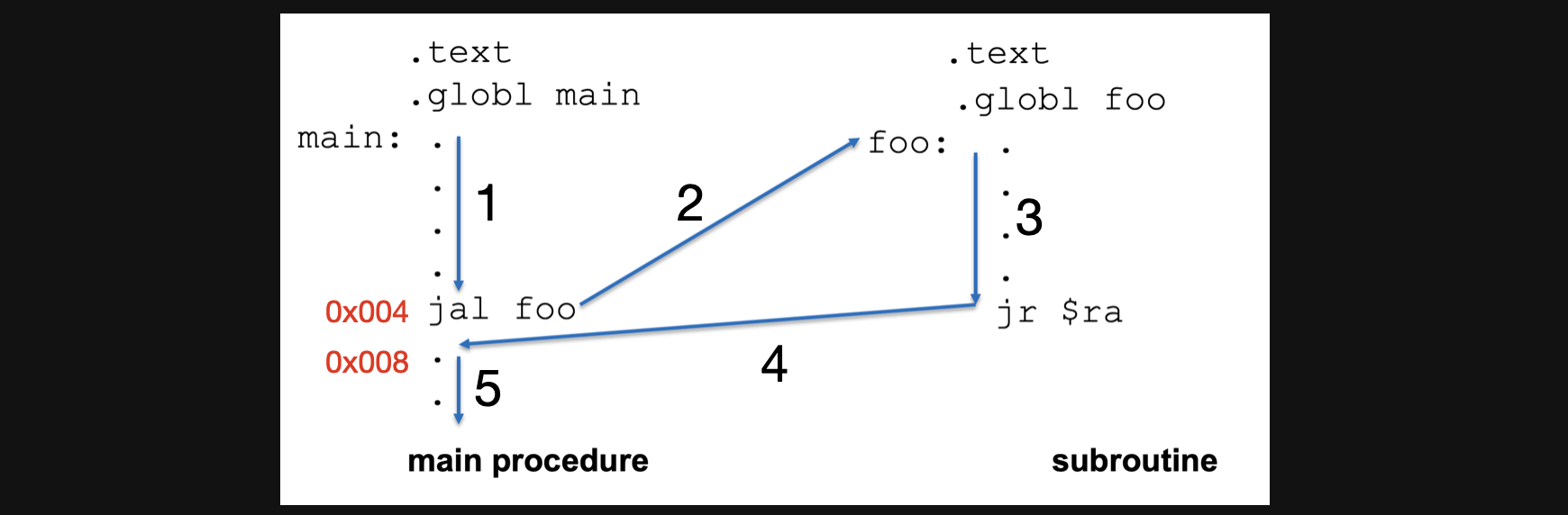
우선 가장 main함수가 실행되겠죠? 그러면 1번 화살표를 따라서 instruction이 쭉 실행될겁니다. 그러다가 jal foo에서 어떤일이 일어나나면 foo로 jump를 하고 $ra에 0x008이라는 data가 저장되게되게됩니다. foo함수가 끝나면 돌아올 pc를 저장해놓는거죠.
그러고 foo로 jump를해서(2번 화살표) 순서대로 실행을하고(3번 화살표) jr $ra를 만나서 ra에 저장되어잇는 0x008로 돌아오게되고 다시 순서대로 5번화살표를 따라서 instruction을 수행하게되는게 함수의 실행의 흐름입니다
함수가 실행될때 사용되는 register

간단하게 우리가 함수를 사용할 때 사용되는 register에 대해 간단하게 알아보고 넘어가겠습니다
func leaf_example(g,h,i,j) {
let f = 0
f = (g+h)-(i+j)
return f
}우선 위의 함수에서 g, h, i, j는 a0~a3 register에 저장되고 모자라다면 stack에 저장됩니다. temporaries는 함수에서 let f = 0처럼 로컬에서만 사용하는 변수입니다. 이 변수의 값들은 s0~s7에 저장됩니다. 그리고 계산중간중간에 임시로 저장되는 변수들, 예를들어서 g+h의 값과 i+j의 결과를 임시로 저장해놔야 그 두개를 뺴서 f에다가 저장할수있기때문에 이렇게 정말 임시적으로 넣을 register가 필요한데 t0~t9에다가 저장합니다.
근데 t와 s가 무슨차이인지 좀 헷갈릴수가있는데 무슨차이가있냐면 t의 경우엔 정말 임시적인 값이기때문에 값이 바뀌어도 상관없는 친구를 넣습니다. 근데 s의 경우에는 만약에 값이 바뀌게되면 나중에 원래 값으로 복원을 해줘야합니다.
지금은 의문이 드실수도있지만 이게뭔소리야ㅡㅡ 뒤의 설명을 들으시면 이해가될거라고 생각합니다. 편하게 따라와주세요.
Memory Layout
이제부터 함수의 실행과 stack영역을 묶어서 볼거기 때문에 메모리 영역이 어떻게 되어있는지 알아야합니다. 간단하게 설명을 해보면 우선 메모리는 코드 데이터 힙 스택이렇게 네부분으로 나눠져있습니다.
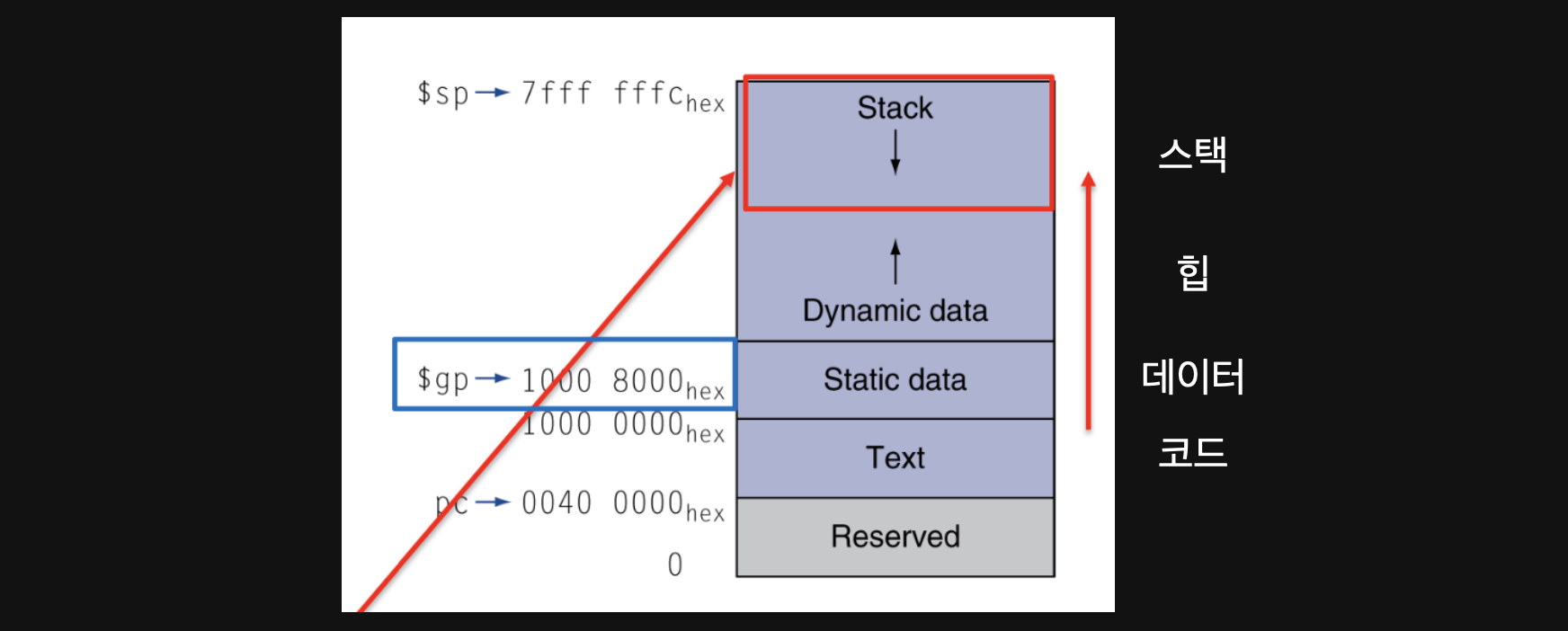
코드영역엔 말그대로 코드가 있고 데이터영역엔 글로벌변수들이 저장되어있습니다. 힙영역엔 dynamic data가 있다고 하는데... swift기준으로는 class의 인스턴스들이 있습니다. 스택영역에는 swift기준으로 여러가지 값타입들이 저장되게됩니다
저기보이는 $gp가 뭐냐면 우리가 매번 pc의 시작주소를 초기화를 해주고 사용했는데 고정되어있는 저 값을 사용하면 귀찮음을 조금 덜수있어서 이런식으로 offset만을 이용할수있게 절대적인 pointer값을 저장해놓는 register라고 생각하시면 좋을거같습니다.
함수가 실행될때 stack에서 일어나는 일

자! 이제 본격적으로 함수를 실행할때 stack에서 일어나는 일에대해 알아보겠습니다
func leaf_example(g,h,i,j) {
let f = 0
f = (g+h)-(i+j)
return f
}우선 위의 함수를 main함수에서 실행한다는 가정은 그대로 가져가겠습니다
Argument인 g,h,i,j은 각각 $a0, $a1, $a2, $a3에 넣고 f는 $s0에 Result는 $v0에 저장한다고 가정하겠습니다.
앞뒤에 어떤 코드들이 있는데 그 코드들까지 포함해서 아래와같은 assembly text가 있다고 가정해보겠습니다
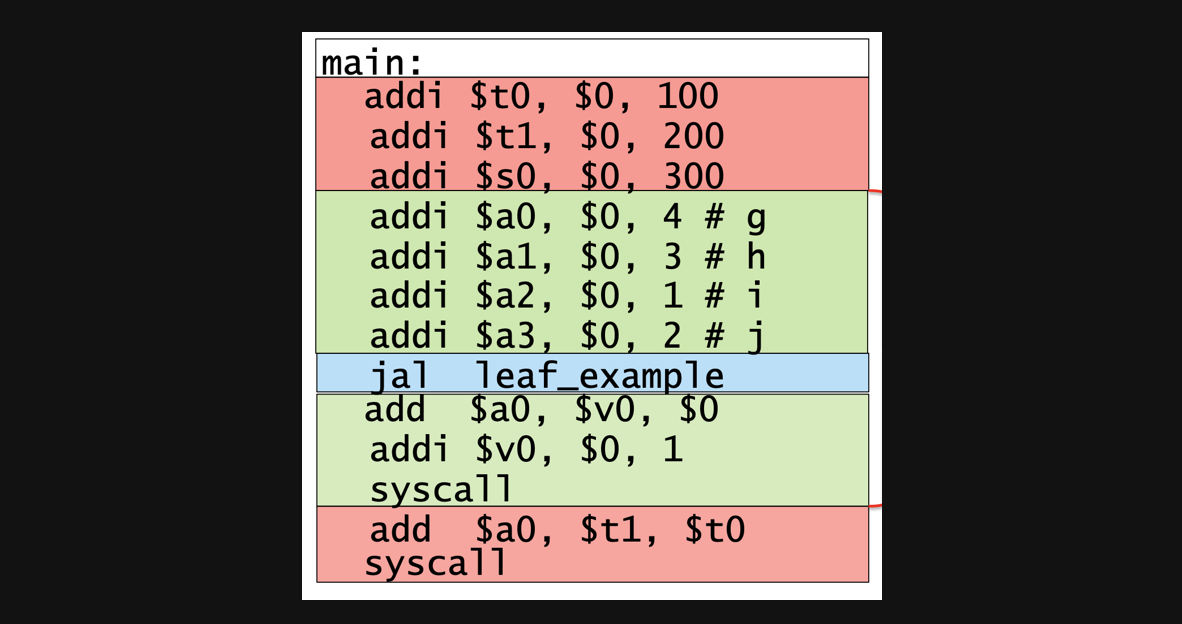
우선 t0에 100을 넣고 t1에 200을 넣고 s0에 300을 넣습니다, 그리고 함수에서 사용할 register에 값을 넣어주고 그리고나서 leaf_example을 실행한다고 쳐보죠. 그리고 함수실행이 끝나게되면 다시 jal 아래줄로돌아와서 쭉 실행을하게됩니다.
여기서 찜찜한부분이 있습니다. 분명 우리는 처음에 t1과 t0에 각각 100과 200을 넣었는데 leaf_example내부에서 t1과 t0를 썼다고 하면 우리가 원하는 300이라는 값을 잘 출력할 수 있을까요...?
여기서 우리는 t0~t9의 register은 쓰고난 뒤에는 원래값으로 초기화를 해줘야한다는걸 알게됩니다... 그래서 실제로 leaf example에서는 이런 flow로 실행됩니다
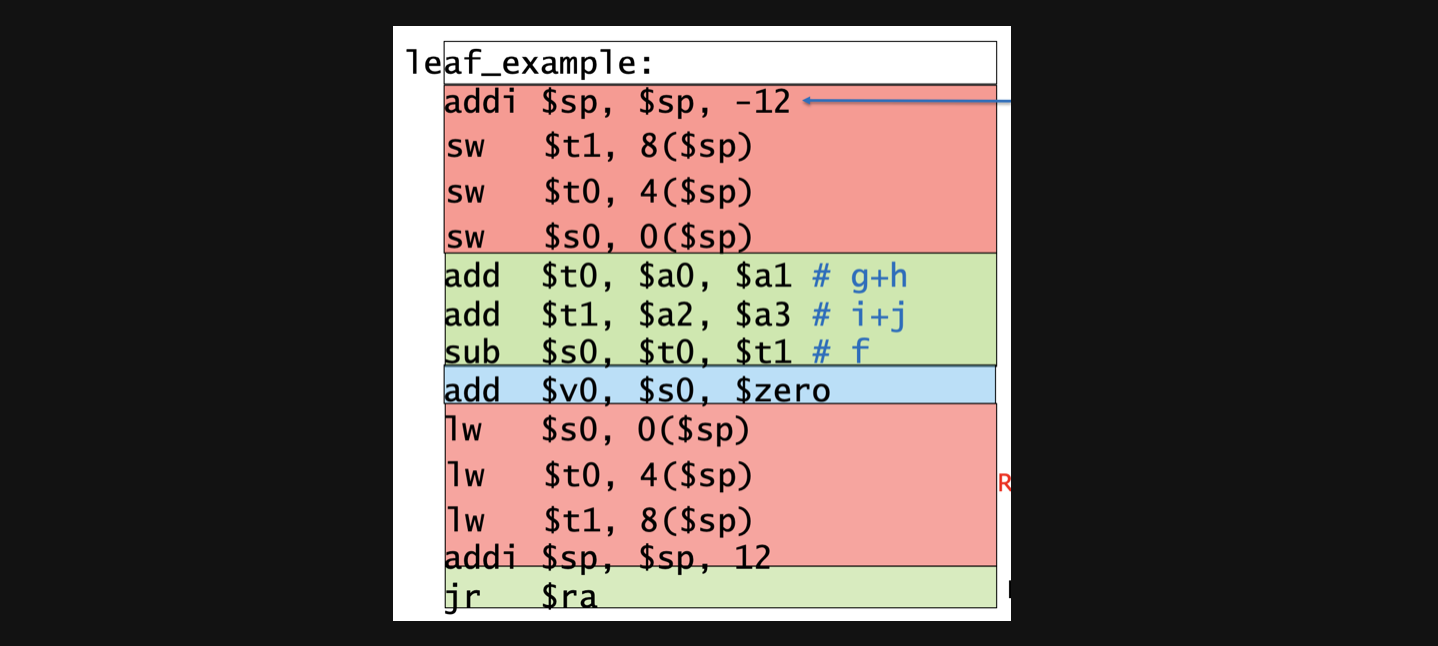
기존에 t1과 t0에 있던 값을 stack영역에 저장하고 함수내부의 일시적인 변수들을 저장하고 쓴다음 다시 원래 $ra의 pc로돌아가기전에 register의 원래값으로 lw(load)해주게됩니다.
이렇게 해서 우리는 함수호출이 끝난이후에도 원래 값을 가지고 원하는 연산결과를 얻게됩니다.
그건 이해가 되는데 저기있는
addi $sp, $sp, -12는 뭔가요...?
사실 이부분을 알기 위해서는 우리가 stack에 대한 한가지 개념을 더 알고가야합니다. 우선 data주소가 위쪽으로 커진다면 stack은 아래방향으로 expand되는 특징을 가지고 있습니다.
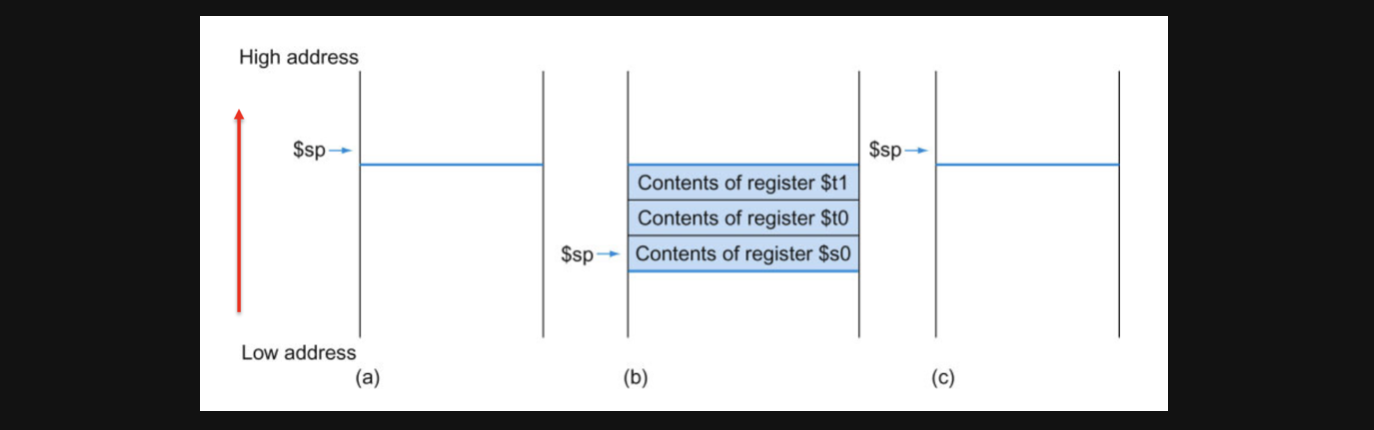
그래서 우리가 원래 stack영역에서 값을 저장하기위해선 stack영역을 expand해야하는데 주소값이 양의방향이 아니라 음의방향으로 expand해야하기때문에 -12를 더해주는겁니다 -12인 이유는 int인 4byte값을 3개 저장해야하기 때문입니다.
즉, 3개의 값을 저장하기 위해 12byte만큼의 stack영역을 expand하고 4byte씩 저장하고 나중에 저장된 주소에서 값을 원래 register에 load하고 expand한 stack영역을 되돌린다(stack pointer를 원래위치로 되돌린다)는 흐름으로 함수가 실행되게 됩니다
nested call
그런데 여기서 한가지 의문이 들 수가 있습니다
근데 왜 함수는 stack과 함께사용하나요...?
결론부터 말하자면 함수가 다른함수를 호출하기 때문입니다. 우리가 방금봤던 함수의 경우를 보면 그냥 함수하나를 실행한거같지만 사실은 우리가 main함수에서 leaf_example함수를 호출한것이기때문에 함수안에서 함수를 호출한것과 마찬가지입니다.
결국 우리가 nested call을 해야하기때문에 stack을 이용해야할 필요가 있는겁니다. 사실 이렇게말하면 당연히 이해가 잘 안될 수 있기때문에 우리가 방금 본 leaf_example을 main함수안에서 호출했다는 시각으로 다시 보도록하겠습니다
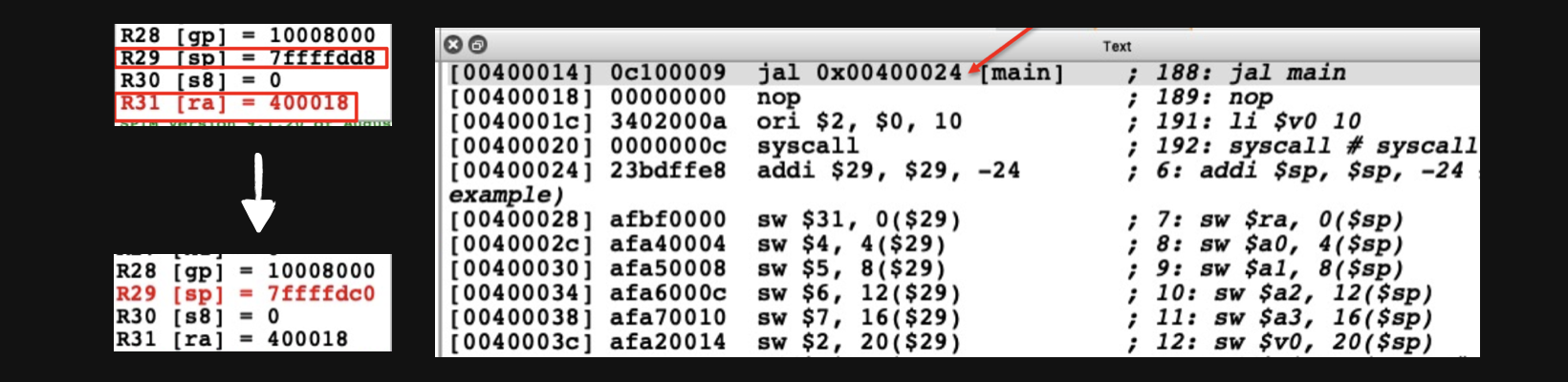
우선 pc주소 00400014가 main함수를 실행하는 부분입니다 jal을 통해 main의 pc인 00400024로 jump를 하는 동시에 $ra에 00400018을 저장하게 됩니다. 이러면 비로소 main함수가 실행되게 되는것이죠
우리가 main함수를 사용하려고 봤더니(00400024) 총 6개의 register의 값을 메모리에 store해야하는 상황이발생합니다. 그러기 위해서 우리는 우선 stack을 24만큼 expand해줘야하고(그런데 stack영역의 반대쪽으로 expand해야하기때문에 -24만큼의 offset을 설정해줘야합니다) 순서대로 데이터들을 sw해줍니다.

그러고나서 leaf_example을 실행하고 return된 value($v0)를 print해주고 다시 register를 원래의 값으로 초기화해주는 lw instruction을 수행해줍니다. 그리고 나서 main함수 다음 pc로 이동시켜주면 됩니다.
자 그러면 이번엔 stack입장에서 한번 데이터가 어떤식으로 저장되는지 생각해보면 좋을거같습니다
함수의 실행 순서
- main함수가 실행되면 stack이 6칸 늘어나게 되고 각각의 메모리에 값들이 저장되게 됩니다. (ra=31번, a0=4번, a1=5번, a2=6번, a3=7번, v0=2번)
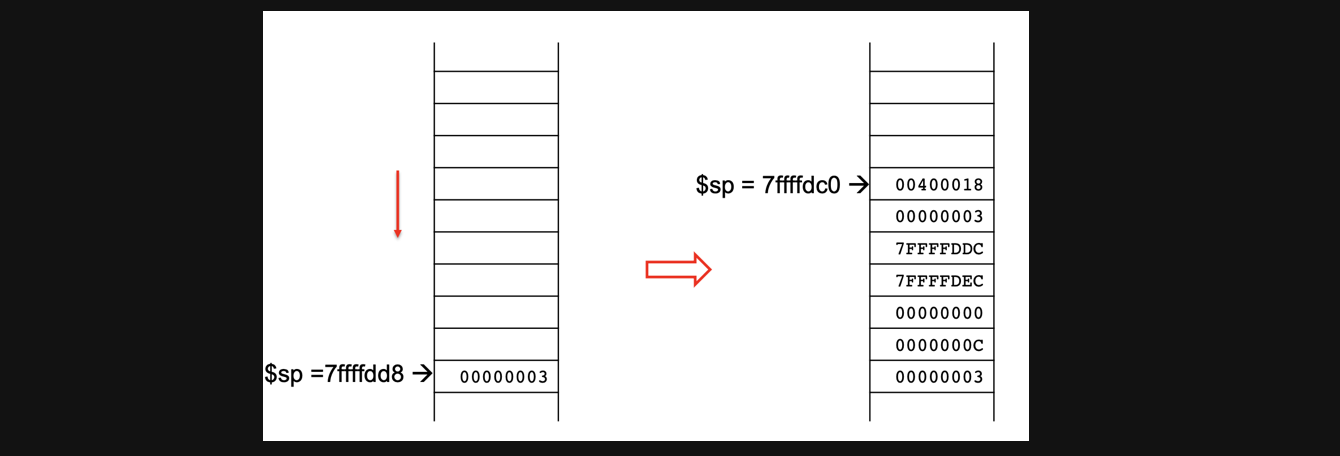
-
함수의 parameter에 들어갈 값들을 각각 4번~7번에 넣어줍니다
-
leaf_example이라는 함수가 실행되고 함수내부에서는 $8,$9,$16를 사용하기 위해서 기존에 있던 값들을 stack에 저장합니다. 그렇게하기위해서 stack을 offset 12만큼 expand하고 값들을 저장합니다.
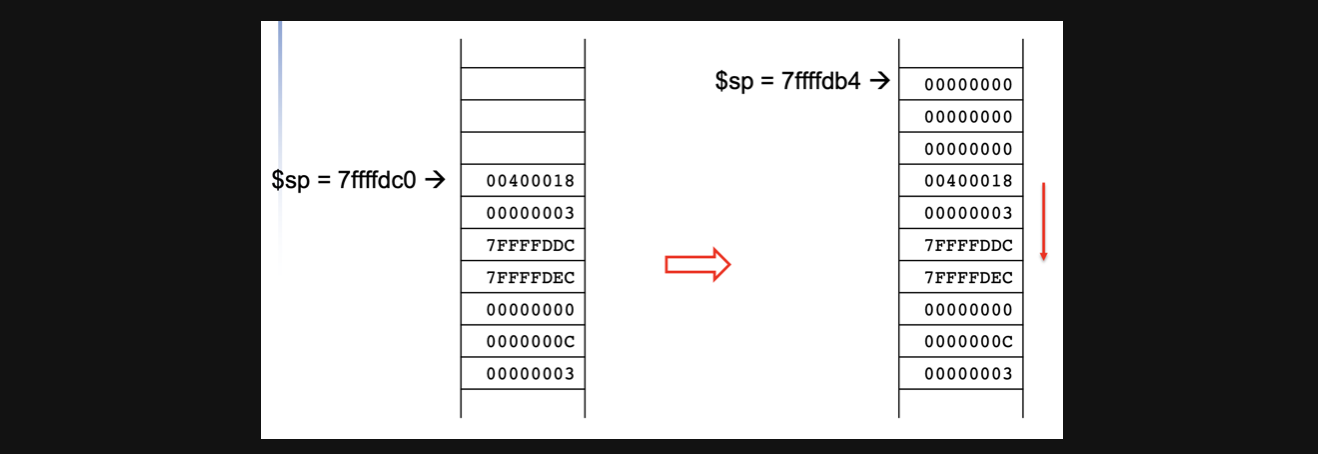
-
4번~7번 register의 값들을 이용해서 새로운 값들을 8,9,16에다가 넣어주고 return할 값을 v0(2번)register에 넣어주고 8,9,16에 원래 값들로 다시 초기화 시켜주고 stack의 sp를 12만큼 줄여줍니다. 그러면 아래와 같은 stack모양이되고 main함수로 돌아가게됩니다.
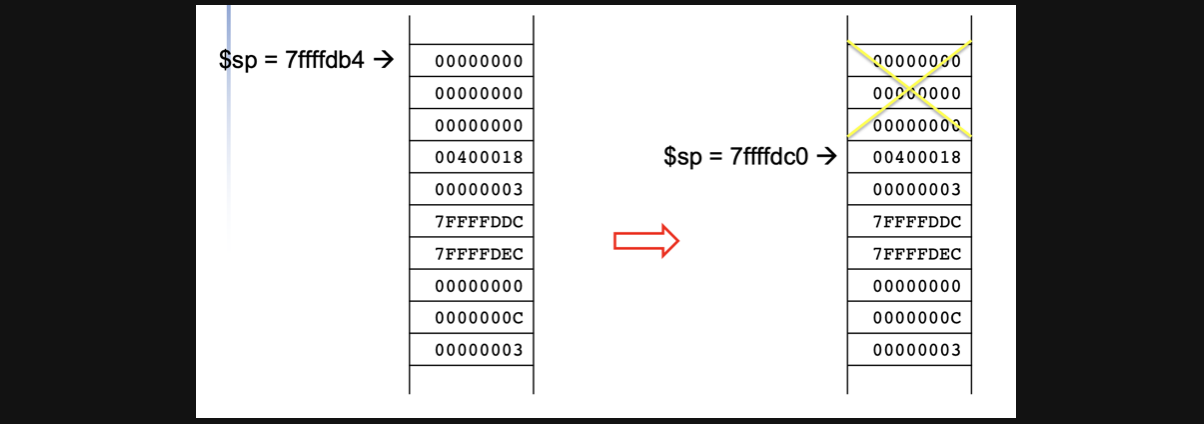
-
main함수로 돌아가서 4번 register에 syscall 명령어를 넣어주고 사용할 register를 다 사용했으니
ra=31번, a0=4번, a1=5번, a2=6번, a3=7번, v0=2번들에 원래 값으로 lw instruction을 수행해주고 expand햇던 stack을 원래대로 돌려주면 아래와같은 모양이됩니다. 그러면 처음 ra의 메모리로 jr하게되고 main함수가 종료되고 다음 pc의 명령을 수행하게됩니다.
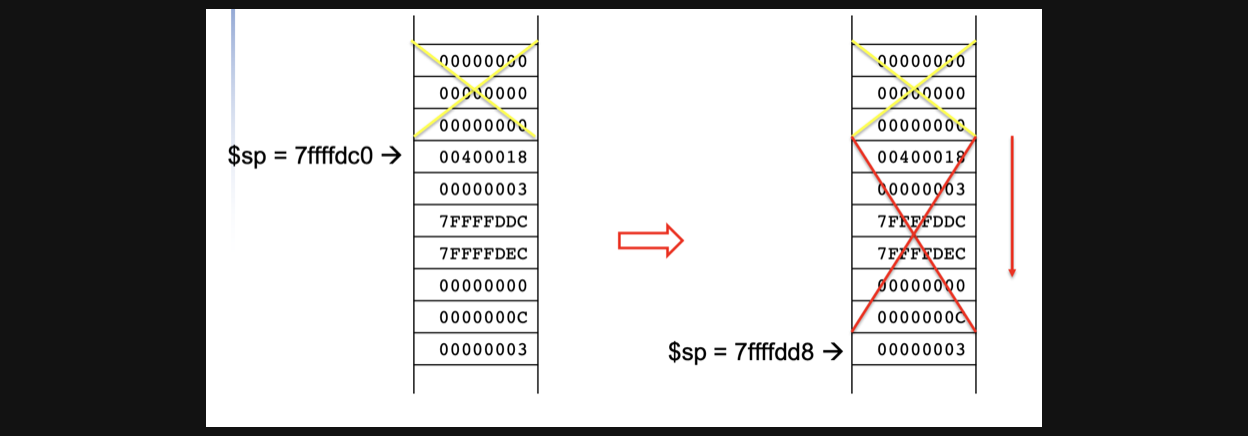
Recursive Procedure
함수내부에서 함수를 사용하는 것중에 대표적인것이 재귀함수입니다. 제목의 recursive가 재귀라는 뜻입니다. 이번에는 재귀함수를 실행하는데 있어서 stack을 한번 보도록하겠습니다.

위와같은 코드가 있다고 가정해봅시다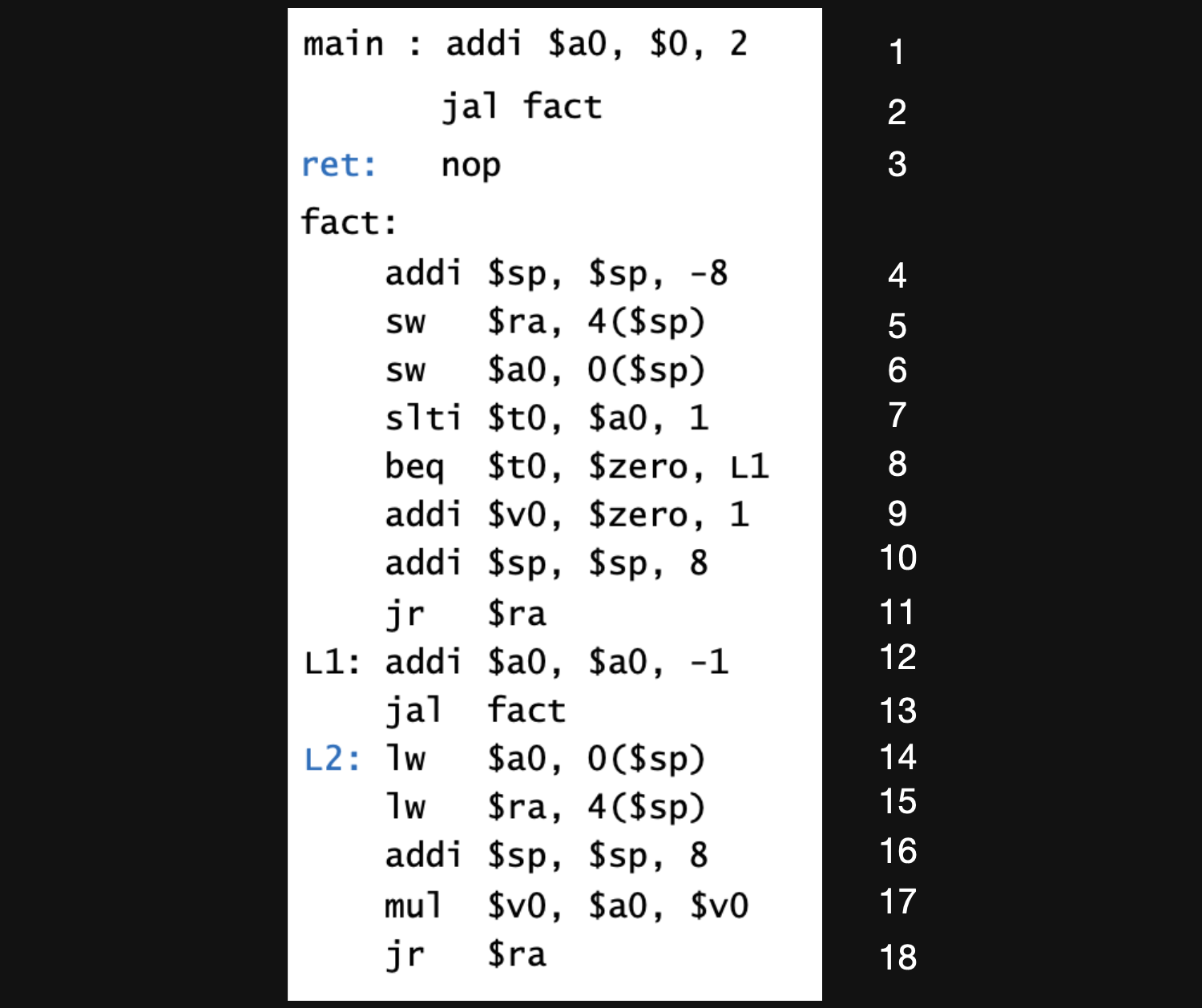
코드를 complie하면 위와같은 assembly text가 됩니다. 자그러면 순서대로 차근차근 알아봅시다.
-
a0에 라는 값을 저장합니다. 그리고 fact라는 함수를 실행하는데 이때 ra에 ret의 pc를 저장합니다
-
그림의 4번째줄로 jump해서 instruction을 수행합니다. 이때 우리는 a0와 ra라는 register를 초기값으로 돌려줘야하기때문에 stack에 두개만 저장하면됩니다. 그러면 -8의 offset만큼 stack을 expand해주고 기존값을 저장해줍니다
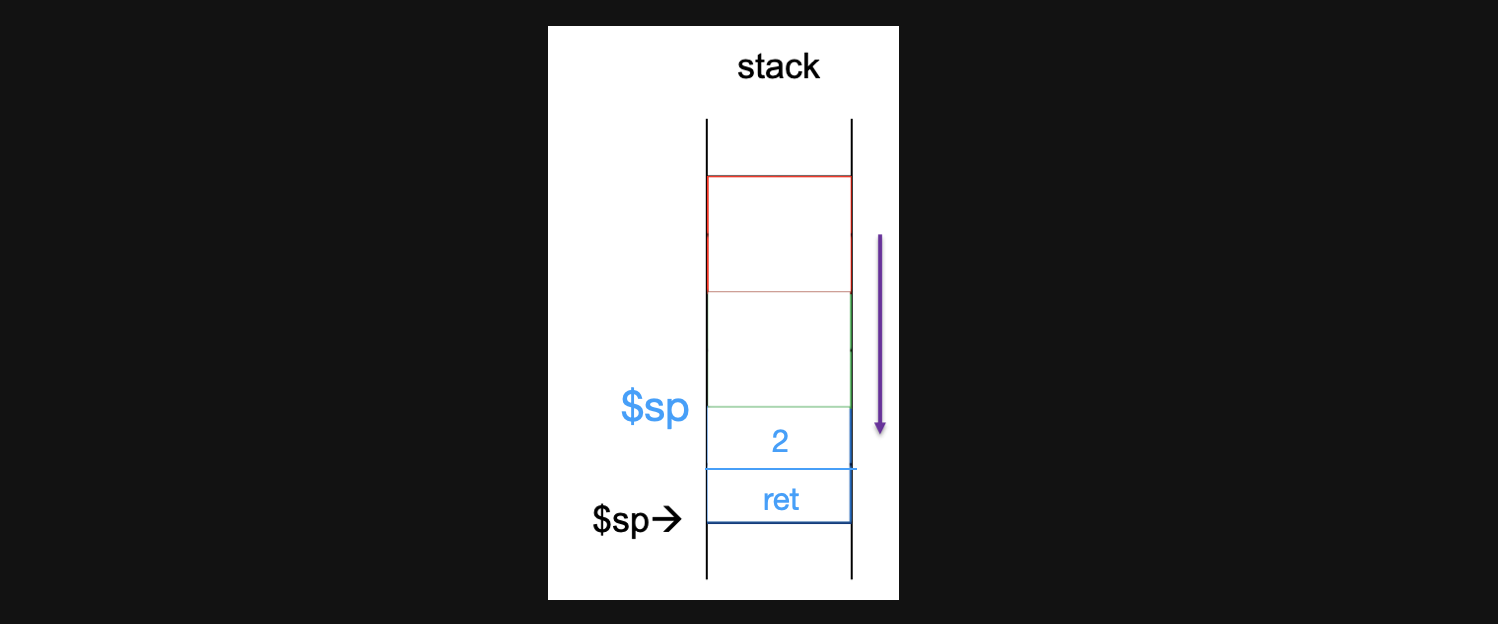
stack영역은 현재 위와같은 상태일겁니다. -
7번째줄로 가서 2와 1을 비교했을때 참이 아니므로 t0에 0이 저장되고 아래로 내려가서 beq는 0과 0이라 equal이기때문에 L1으로 branch하게됩니다.
-
기존에 $a0에 저장되어있던 값에 -1을 해주고 fact로 jal하는데 그렇게 되면 ra에는 이 다음 줄인 14번쨰줄(L2의 시작점) pc가 저장되게 됩니다.
-
다시 4번째줄로 돌아와서 stack을 -8offset만큼 expand해주고 ra값과 a0값을 저장해줍니다(1과 L2시작점 pc) stack은 아래와같은 상태가 될겁니다
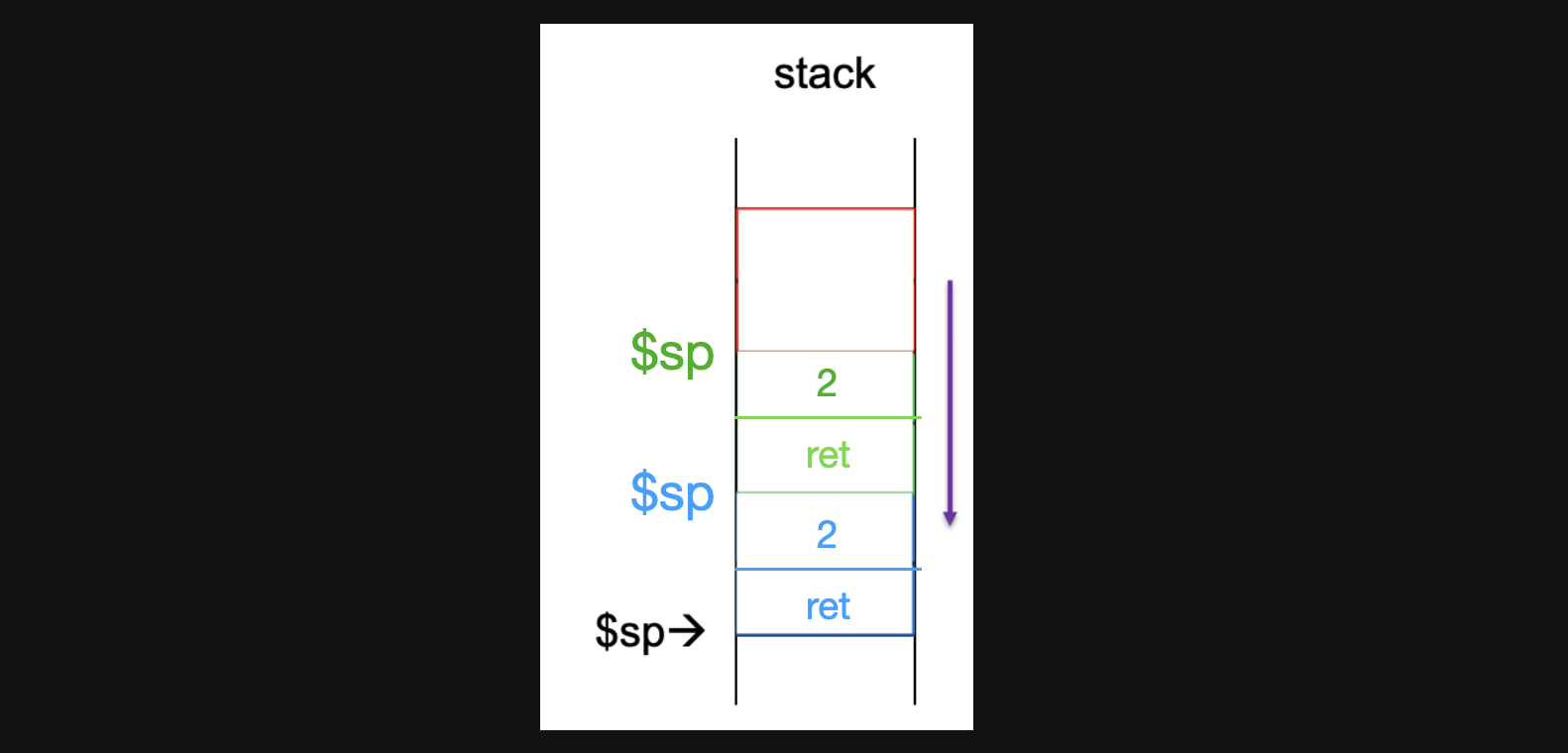
-
그리고 다시 7번째줄로와서 slti를 수행해주고 여전히 1보다 작지 않으니까 L1으로 넘어가고 a0에있는 값을 -1 더해주고(⭐️이제 a0에는 0이 저장되어있음) jal fact를 하게되면 이번에도 ra에는 L2의 pc가 저장되게 됩니다.
-
다시 4번째줄로 돌아가서 stack을 2칸 expand하고 기존에 가지고있던 a0의 0와 L2 pc주소를 stack 저장합니다. 그러면 아래와같은 stack 상태가 됩니다.
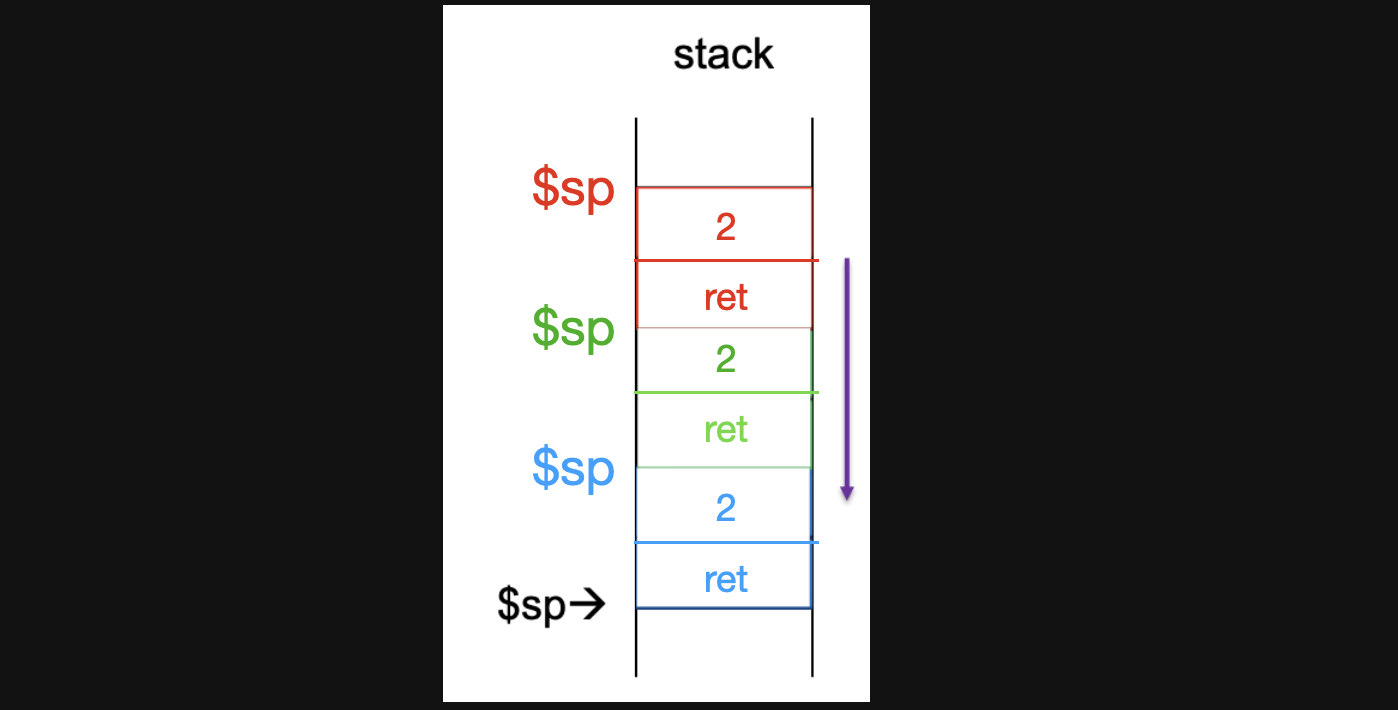
-
하지만 이번에는 7번째줄의 결과가 1이 되고 8번째줄에서 not equal하기때문에 L1으로 branch하는게 아니라 9번째줄로 넘어오게됩니다. 그러면 결국 f(n<1)이 만족햇기때문에 1을 return하기 위해서 v0에 값을 넣어주게 되고 return되면 함수가 종료되기때문에 가장 위에있던 함수 stack을 지워줍니다. 그래서 jr $ra 하기 직전의 stack 상태는아래와 같은 상태가 됩니다
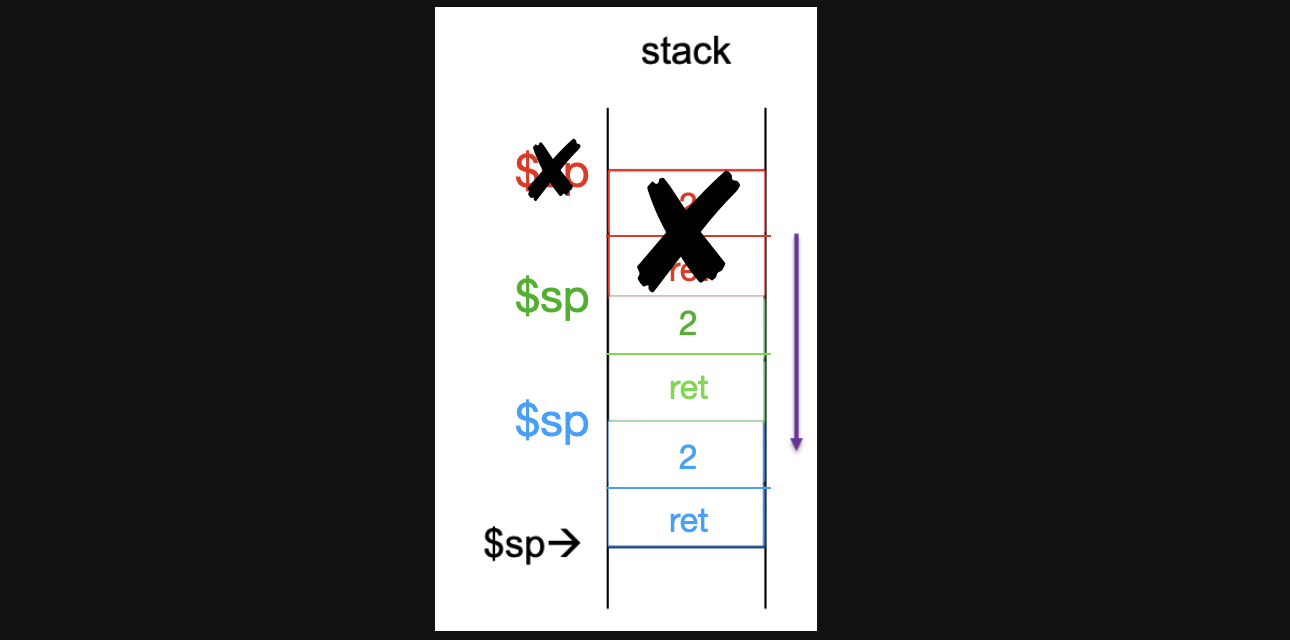
-
이 상태에서 11번째 줄이 실행되면 $ra에 있는 pc로 jump해야하기때문에 L2로 jump를 하게되고 14번째줄이 실행되게 됩니다. a0에 현재 sp의 offset 0인 데이터가 저장되므로 a0에는 1이라는 값이 들어가게 되고 ra에는 sp의 offset 4인 L2의 pc값이 들어가게됩니다. 그리고 나서 다시 sp에다가 8을 더해줍니다(함수를 종료하기 위해서 함수스택을 pop해줍니다). 이 상태에서 stack은 아래와같습니다.
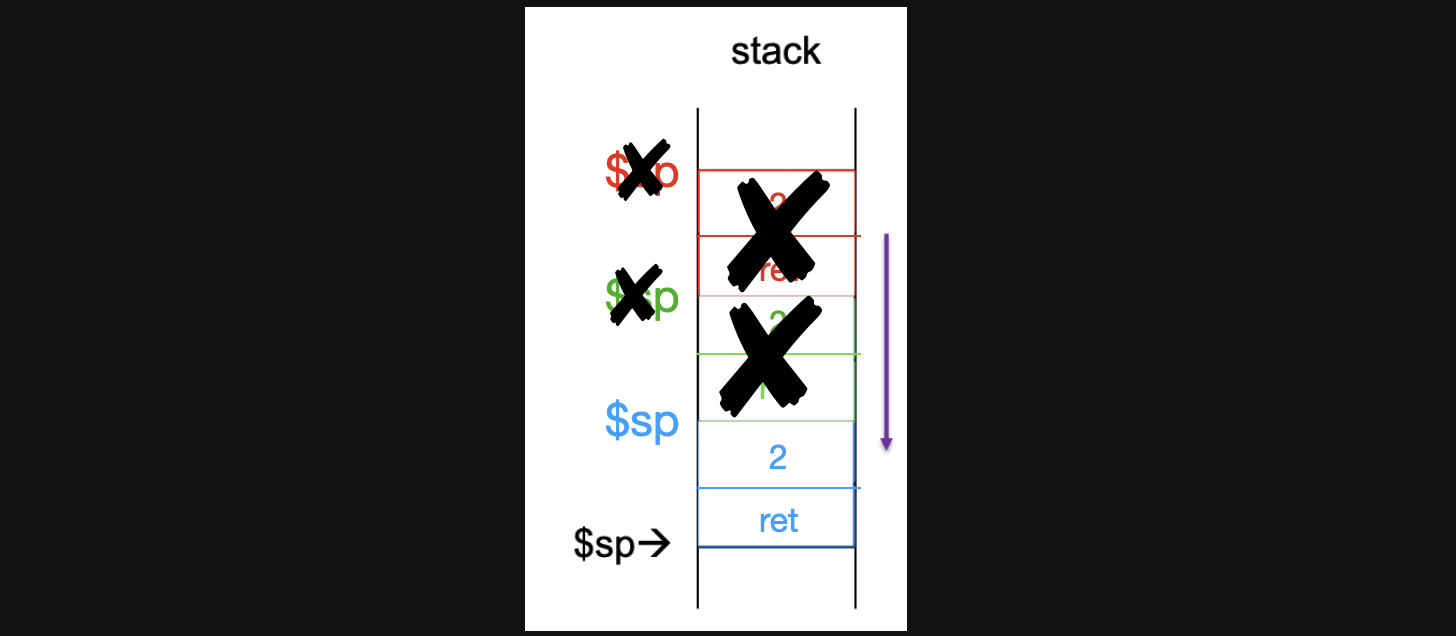
-
return value를 v0에 저장하는데 기존에 저장되어있던 v0의 값(1)에 방금 최신화된 a0의 값인 1을 곱해주고 이를 v0에 넣어주고 다시 ra로 jump합니다. 이 때 ra에는 L2의 pc값이 들어있기 때문에 다시 14번째 줄로 돌아오게됩니다.
-
a0와 ra에 현재 stack point에 있는 값들을 load해주고(a0에는 2가 들어가고 ra에는 ret의 pc주소가들어갑니다) stack영역을 원래상태로 바꿔줍니다. 이상태에서 stack영역은 처음상태로 돌아갑니다
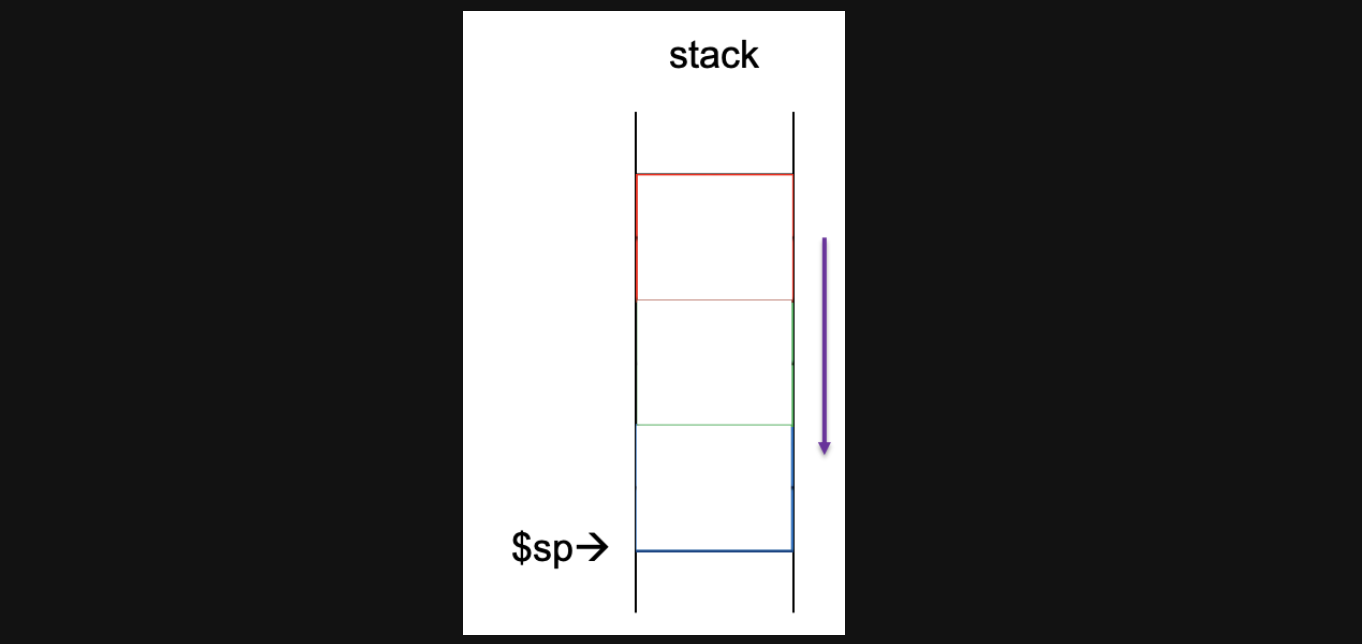
-
그리고 나서 v0(1*1의 결과값)과 a0에있던 2를 곱해서 2라는 최종 결과를 v0에 넣어주고 이번에는 ret으로 jump해줍니다. 그리고 나서 3번째줄의 instruction인 nop을 실행해줍니다.
아주아주 복잡하죠...? 하지만 복잡하긴해도 정확한 규칙을 통해 stack안에서 함수를 위한 data가 load되고 store되는것을 알 수있습니다. 이런 흐름으로 재귀함수가 실행된다는걸 꼭 알고 넘어가면 좋을거같습니다.
Static Libaray/Dynamic Libaray
이번에 볼 내용은 사실 swift와 연관지어서 이해하면 아주 의미있는 내용이 될거라 생각됩니다. 이 내용은 제가 WWDC를 볼 때 이게뭐지...?하고 넘어갓던 내용인데 이렇게 컴구에서 배우니까 이해가 잘되더라고요. 이번 포스팅의 마지막 내용이니 집중해서 보도록하죠
우리가 지금까지 배운건 우리의 code가 compiler를 통해 assembly text가 되고 assembler를 통해 binary machine language가 되는 과정에대해서 공부를 했습니다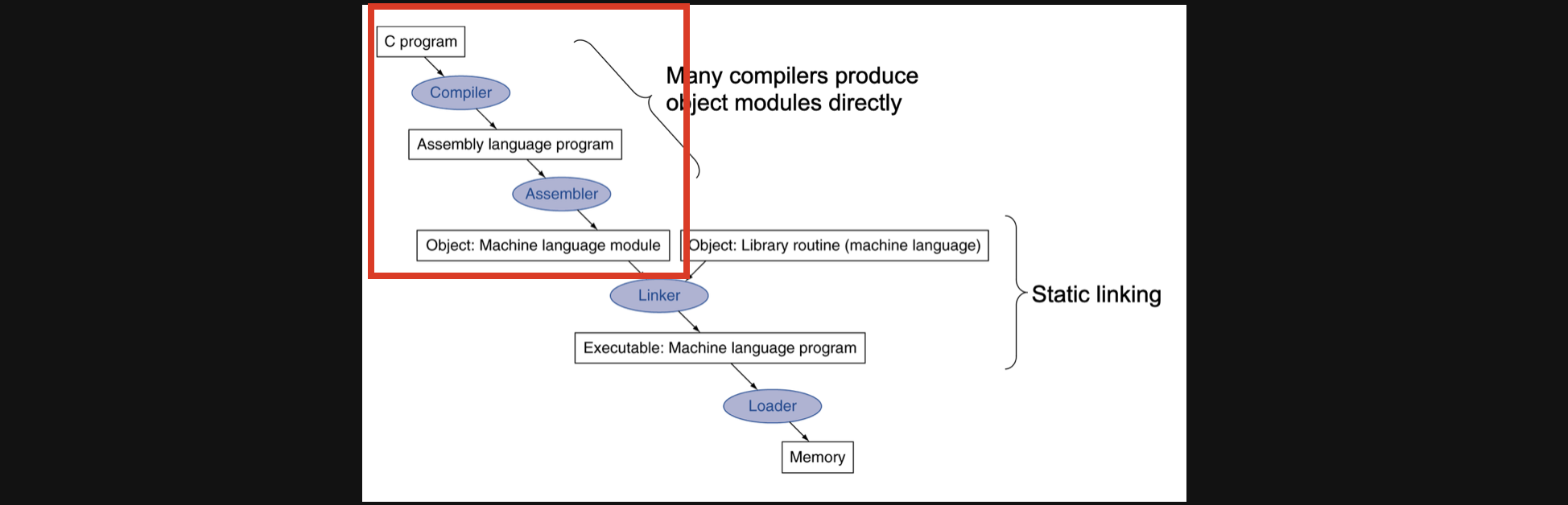
사진에서 빨간색 네모부분을 배운거라고 생각하시면 됩니다. 나머지부분은 사실 컴퓨터 내부에서 다 해주긴합니다.
g++ -o ab a.cpp b.cpp -lm
위의 코드를 한번 해석을 해보겠습니다
g++라는 complier를 통해 a.cpp와 b.cpp파일을 각각 object파일로만든다음에 라이브러리와 link해서 ab라는 executable파일을 만들어줄게~
라는 의미가 됩니다.
그림으로 정리하면 이런느낌이겠네요. 하지만 여기서 중요한 개념이 있습니다. 바로 libary를 link하는 방식에 대한 이야기입니다.
우선 executable파일을 만들떄 object파일과 libary를 link하는데 이떄 라이브러리를 copy해서 executable파일에 넣는 방식이 static libary방식입니다. 이렇게 되면 애초에 executable파일이 커지겠죠 그리고 혹여나 라이브러리가 업데이트된다면 그때마다 executable파일을 다시만들어줘야합니다.
두번째 방식은 dynamic libary방식입니다. 이방식은 라이브러리를 executable 파일에 포함시키지않고 libaray코드의 reference만 가지고 있게 하는 방식입니다. 이 방식을 통해 라이브러리 함수를 호출하게되면 해당 라이브러리의 함수 ID를 받아서 라이브러리에잇는 함수로 jump를 해서 함수를 실행하게 되고 이떄 ID를 가지고 알게된 특정함수의 주소를 segment에 저장해놓습니다. 이렇게 되면 같은 메서드를 두번째 실행할때는 ID를가지고 jump를 하는것이 아니라 segment에 있는 주소로 바로 jump를 할수있게됩니다. 물론 이 방식은 라이브러리가 업데이터되더라도 executable 파일을 다시 만들 필요가 없어집니다.
이를 Lazy Linkage라고하는데 그림과같은 실행시퀀스를 가집니다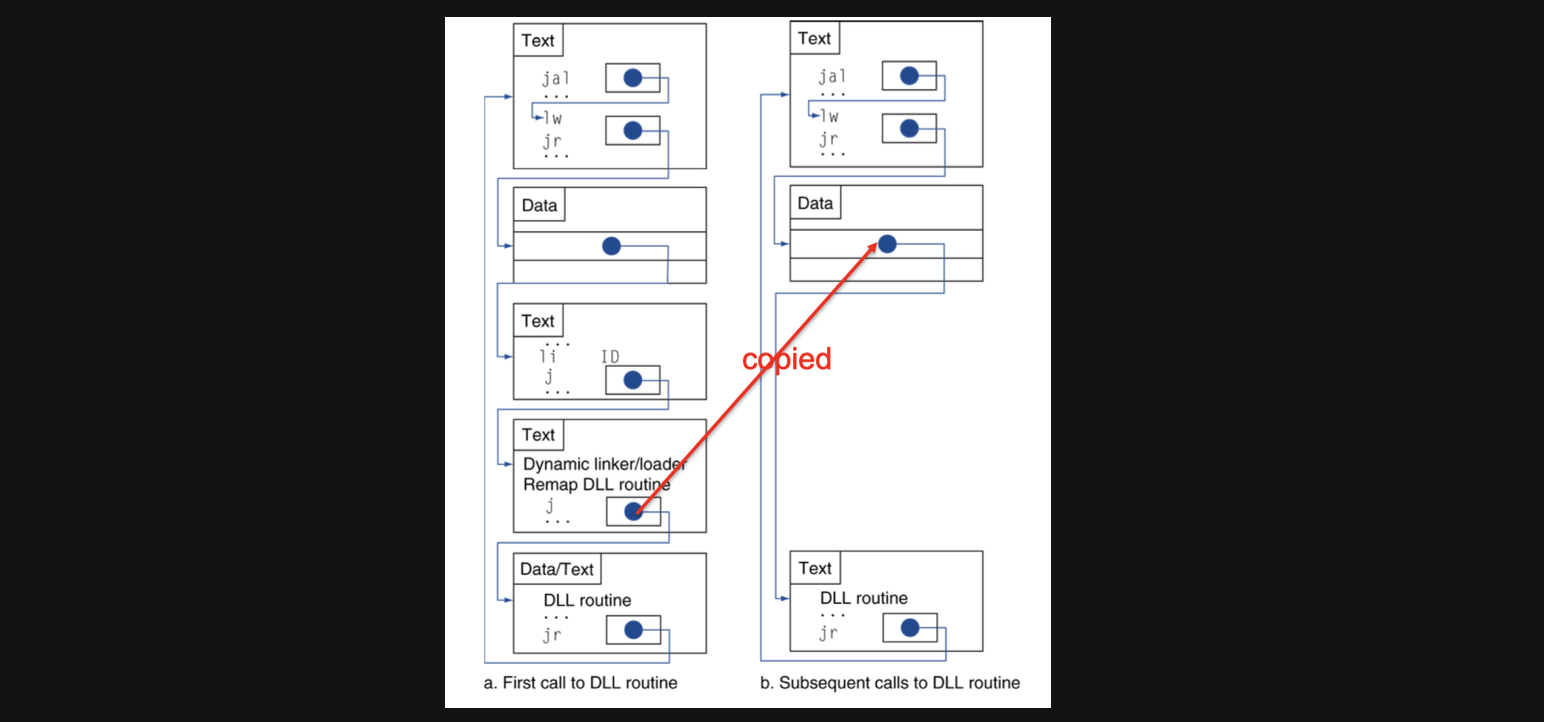
하지만 당연히 reference를 타고타고 들어가야하기때문에 런타임에서 시간이 조금 느려질수는 있습니다.
즉, 정리를 해보면 static Libary의 경우엔 컴파일이 느리고 런타임에서 함수의 실행속도가 빠르지만 라이브러리의 업데이트가 있을시 executable파일을 다시 만들어야합니다. 반대로 dynamic Libary의 경우 executable파일을 빠르게 만들수있어 컴파일이 빠르고 라이브러리 함수를 실행할때도 reference를 가지고 실행하게됩니다. 이는 함수의 업데이트에도 유연하게 사용가능하지만 아무래도 아주조금 느릴수가있습니다.
swift의 경우엔 기본적으로 libary들이 dynamic으로 설정되어있다고 합니다.
오늘 내용이 정말 역대급으로 길었네요...근데 함수와 스택은 정말 중요한내용이라고 생각해서 정말 한줄한줄 꼼꼼히 설명을 하기위해 노력했습니다!
전공책을 기반으로 정리하는 글이기때문에 나름대로 최대한 이유가있는 설명을 한다고는하지만 분명히 틀리거나 추가로 들어가야할 내용이 있을수있기때문에 언제든지 댓글로 알려주세요!
그럼 20000!!!!
