본 시리즈은 비전공자가 공부한 computer science, 그중에서도 컴퓨터구조를 정리한 글입니다. 틀린내용이 있다면 댓글로 알려주시면 정말정말 감사하겠습니다. 참고한 책은 Computer Organization and Design MIPS Edition입니다
안녕하세요! 킴스캐슬입니다
드디어 컴퓨터구조의 마지막 주차를 맞이하게 되었습니다
처음 아무것도 모르던 1주차시절의 저를 생각하면 그때보다는 그래도 내실을 조금 다진거같다는 느낌이 드네요
같이 스터디하는 친구의 말을 빌려보자면
이번주차에 포스팅할 캐시와 메모리는 컴구에서 가장 중요한 주제중에 하나라고 하더라고요
무슨 주제가 안중요하겠습니까 근데 이렇게까지 말하는걸로 봐서는 운영체제로 넘어가기전에 꼭 제대로 알고넘어가고 싶어서 포스팅도 총 세개로 나눠봤습니다
Cache(캐시)에 대한 포스팅 그리고 Memory(메모리)에 관한 포스팅 마지막으로 Cache와 Memory가 실제로 동작하는 방식을 하나의 instruction set을 통해 따라가보는 포스팅 이렇게 세가지로 마무리를 해보려 합니다
그러면 마지막주차 컴퓨터구조도 열심히 달려봅시다
Memory Hierarchy
우리가 이전시간에 processor이라고 부르는 CPU의 성능(performance)에 대해서 이야기를 했었는데요
정말정말 빠른 속도로 성능이 좋아졌다는걸 알 수 있었습니다
근데 결국 우리가 어떤 연산을 하기 위해서는 연산할 데이터를 메모리에서 불러와야 하잖아요?
아무리 CPU의 처리속도가 빨라도 메모리가 그만큼 성능이 따라주지 않는다면 CPU의 성능이 좋아진것만큼 컴퓨터가 좋아지지 않을겁니다
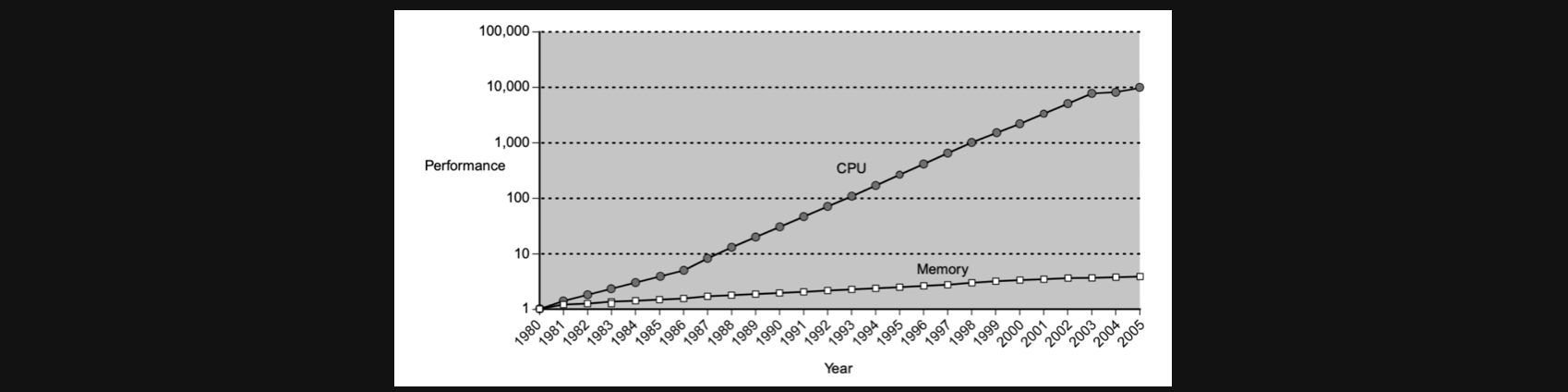
실제로 CPU가 log scale로 증가하는 속도에 비해서 memory의 성능향상 그래프는 그에 미치지 못하는 모습입니다
CPU가 좋아지면 좋아질수록 Memory와의 성능의 차이가 발생하게됩니다(memory의 성능은 메모리의 용량이 아니라 데이터를 읽고쓰는 능력의 속도입니다) 그렇게 되면 아까 말했던것처럼 아무리 CPU가 좋아져봤자 메모리에서 병목현상이 발생해 컴퓨터의 성능향상 일정수준에서 머무를수 밖에 없습니다
Different Memory Technologies
메모리의 성능 대해 알아보기전에 어떤 종류의 메모리가 있는지부터 알아보겠습니다

우선 SRAM이 있습니다 Static RAM인데 왼쪽 그림의 구조로 생긴 메모리입니다
SRAM의 특징이라고 하면 매우 빠르지만 회로를 구성할때 공간이 더 필요하게됩니다
하나의 SRAM을 구성하는데 4개에서 6개의 register가 필요하기 때문입니다
물론 여기서 공간이 더필요하다는 말은 DRAM과 비교했을때를 뜻합니다
DRAM은 Dynamic RAM인데 오른쪽 그림의 구조로 생긴 메모리입니다
pass register와 capacitor가지고 만들수있기 때문에 공간이 덜필요하다는 장점이 있지만
SRAM에 비해서 5~10배가량 느리다는 단점이 있습니다
생각해보면 DRAM은 작으니까 같은 공간에 많이 만들수있어 같은 공간대비 큰 용량을 가질 수 있지만 느리고 SRAM은 같은 공간대비 작은용량밖에 못가지지만 빠르다는 장점이 있습니다
Exploiting Memory Hierarchy

물론 SRAM과 DRAM외에도 Flash Semiconductor memeory와 실제 하드 disk메모리인 Magnetic disk도 있습니다. 이 네가지를 각각 access time과 GiB단 가격을 기준으로 분류한 표입니다
위에서 아래로 갈수록 느려지지만 가격이 저렴해지는 특징이 있습니다
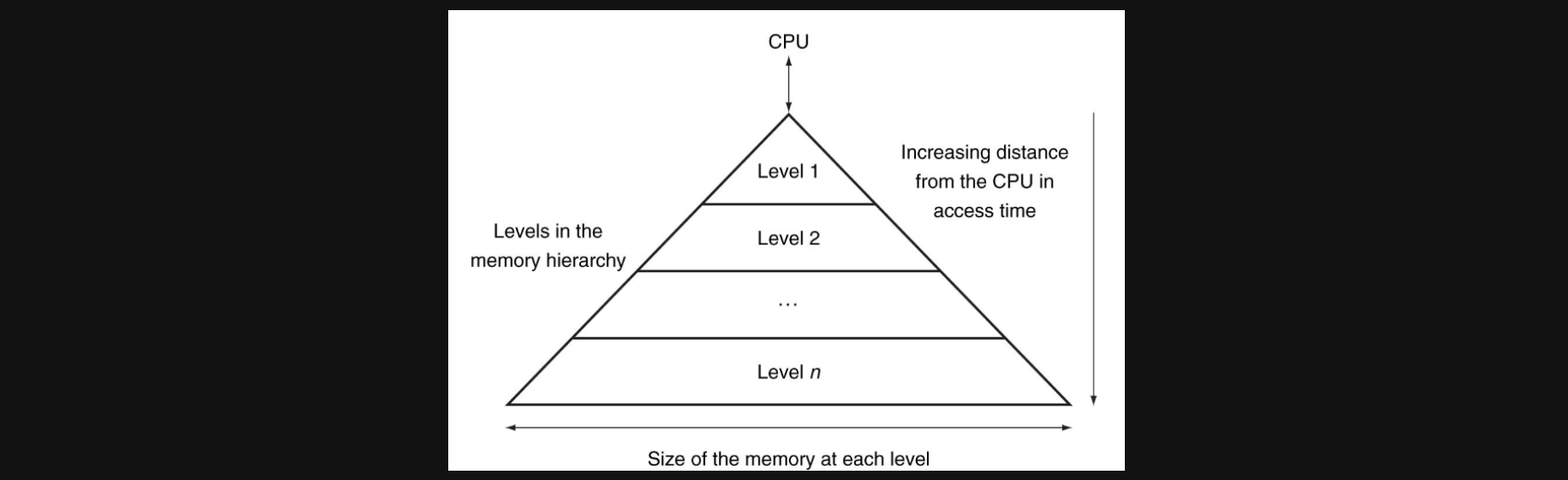
그리고 이런 메모리들의 특성을 고려해 메모리들을 계층적으로 구성한것을 Memory Hierarchy라고 합니다
그림을 한번 보면 CPU와 가까울수록 용량은 작지만 빠른 메모리를 두고 CPU와 멀어질수록 용량은 크지만 access하는데 시간이 더 걸리는 메모리를 위치시킨 구조라는걸 알 수 있습니다
Cache(캐시)란?
Two Levels of Memory
본격적으로 Cache에 대해 알아보기 전에 Memory Hierarchy를 알아봤는데 level이 n개가 있다고 하면 N levels of memory라고 하는데 Two levels memory에 대해 알아보겠습니다
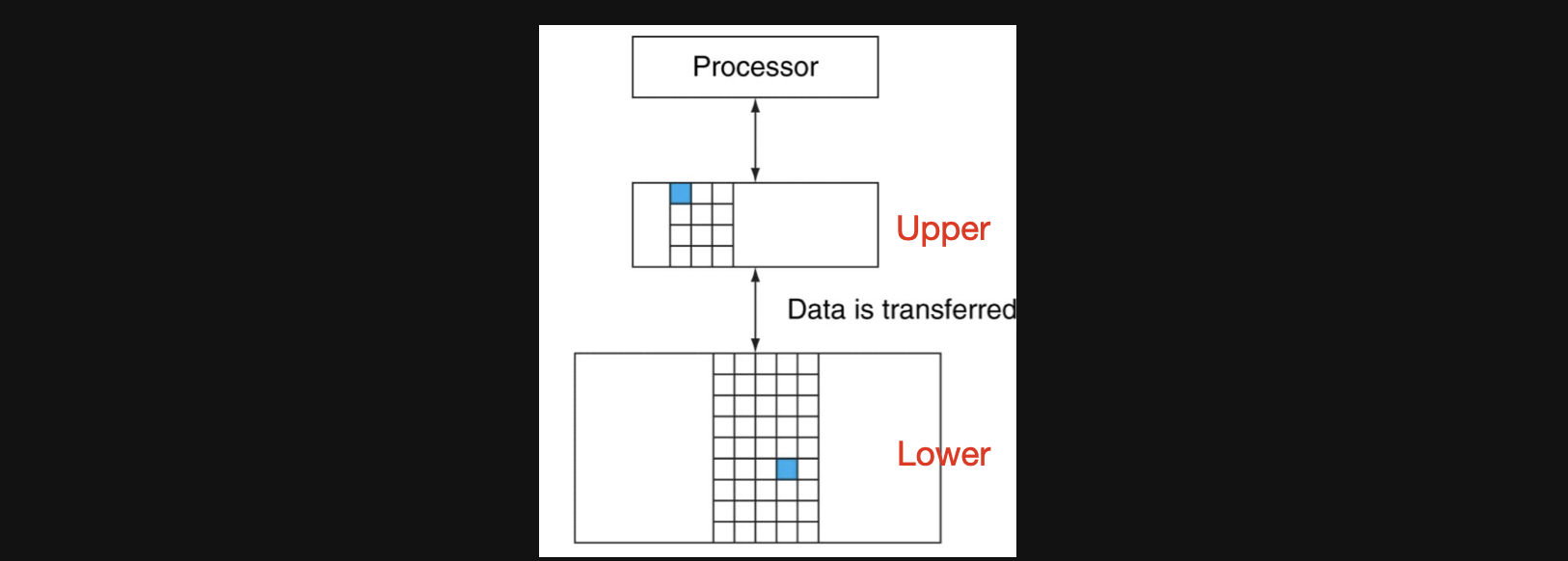
Two levels memory란 말그대로 CPU와 가장 가까운쪽에 level1의 메모리 그 뒤로 level2의 메모리가 위치한 형태입니다
지금부터는 이러한 메모리 형태에서 꼭 알고있어야할 용어에 대해서 정리해보겠습니다
우선 upper, lower입니다
upper: CPU와 가장 가까운 메모리로 빠르지만 값이 비싸고 용량이 작다
lowr: CPU와 upper에 비해 먼 메모리로 upper에 비해 느리고 값이 싸면 용량이 크다
upper과 lower로 나눈 이유는 결국 메모리의 성능을 향상시키기 위함인데요 만약에 CPU가 원하는 데이터가 upper에 있다면 아주 빠르게 데이터를 받아올수있게됩니다 하지만 upper에 없다면 lower에서 upper에 원하는 데이터를 복사하여 추후에 해당데이터를 upper에서 access할수있게 하기 위한 구조라고 보시면 됩니다
(upper는 빠르지만 비싸고 용량이 작기때문에 모든 메모리를 upper로 구성할 수 없기 때문입니다)
그 다음 용어는 block입니다
block: CPU가 원하는데이터가 lower에 있을때 upper로 복사를 하는데 그때 복사되는 단위
upper에 원하는 데이터가 없다면 lower에서 복사를 해야하는데 이때 복사하는 단위를 block이라고 합니다
마지막으로 hit과 miss입니다
hit: CPU가 원하는 데이터가 upper에 있을때 hit이라고 합니다
miss: CPU가 원하는 데이터가 upper에 없을때 hit이라고 합니다
여기서 좀 헷갈렸던 부분이 miss의 경우 "hit은 upper에 있을때니까 miss는 lower에 있을때겠네?"라고 생각했었는데 결국 모든데이터는 hit이나 miss나 lower에는 존재하고 그 데이터가 빠르게 access하기 위해서 block단위로 upper에 copy가 되었는지를 알려주는게 hit과 miss입니다
Principle of Locality
Principle of Locality은 중요한 개념입니다
제가 느낀바로는 이 원칙을 기반으로 Cache라는 메모리성능 방식이 가능해졌다고 생각합니다
만약에 어떤 data가 reference되었을때
(reference 되었다는건 acess되었을때라고 생각하시면 될거같습니다)
temporal locality(시간적 지역성)이 존재할수도 있고 spatial locality(공간적 지역성)이 존재할 수도 있습니다
당연히 지금은 이게 무슨소리인지 이해가 안되시는게 맞습니다
차근차근 알아가보죠
우선 temporal locality(시간적 지역성)에 대해서 알아보겠습니다
시간적 지역성이란 같은 data가 시간적으로 가까운 시기에 다시 access될수도 있다라는것입니다
그렇다면 spatial locality(공간적 지역성)은 뭘까요?
공간적 지역성이란 어떤 data가 access될때 주변에 있는 data들이 시간적으로 가까운 시기에 다시 access될수도 있다라는것입니다
아직 조금 헷갈리실수도 있을거같아서 예시를 들어보겠습니다
instruction을 읽는 경우를 생각해보겠습니다.
이때 시간적지역성이 생기는 경우는 어떤걸까요? 가까운 시기에 같은 instruction에 accesss하는 경우, 대표적으로 loop가 있습니다
공간적지역성이 생기는 경우는 아주 보통의 경우입니다 1000번 pc의 instruction이 access된경우 대부분은 다음 instruction은 1004번 pc가 읽혀질겁니다. 이런 보통의 경우에 공간적지역성이 생기게 됩니다
이번에는 data를 읽는 경우를 생각해볼까요.
우리가 전역변수를 하나 생성해놓으면 그 변수에 계속 접근할때가 많죠 그럴때는 같은 data에 계속 access하는 경우가 생기는거니까 시간적지역성이 생기는 경우겠네요
혹은 우리가 a라는 변수 바로 뒤에 b라는 변수를 만들어 놓으면 연관성이 있는 변수인 경우엔 a를 acess하면 b를 access할 확률이 높겠죠? 이런경우엔 공간적지역성이 생기게됩니다.
함수안에 있는 local한 변수들의 경우엔 비슷한 시기에 같이 불릴 확률이 높으니 이또한 공간적지역성이 생기게 됩니다
정리를 한번 하고 넘어갈까요?
program을 수행하면 principle of locality 때문에 메모리의 특정 위치를 집중적으로 access하게됩니다. 이 덕분에 memory hierarchy로 구성했을때 프로그램의 성능이 좋아지게됩니다
Basic of Cache
이제 본격적으로 실제 컴퓨터상에서 Cache의 동작에 대해 알아보겠습니다
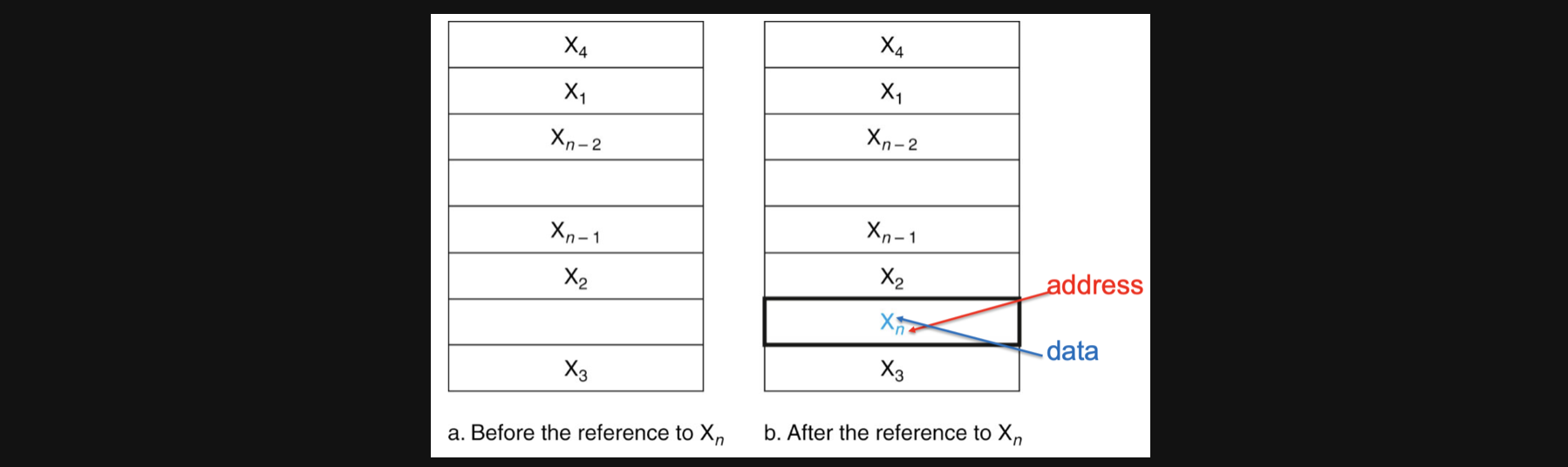
가장 기본적인 아이디어는 위 그림과 같습니다 왼쪽 모습이 X에 access하기 전이고 오른쪽이 X에 access한 후의 모습입니다
만약에 어떤 X라는 데이터에 접근을하고싶은데 cache라는 upper의 메모리에 데이터가 없다면 그 데이터를 낮은 lower에서 block단위(불러올때 주변에 있는 데이터도 같이 큰 block으로 불러옴)로 copy해오고 추후에 공간적지역성과 시간적지역성에 따라 같은 데이터나 주변데이터를 빠른 cache메모리에서 불러올 수 있어 메모리의 성능적인 향상을 기대할 수 있게됩니다
그러면 이런 의문이 드실수도 있습니다
아니그럼 cache에 데이터가 있는지 없는지는 어떻게 알아요?
만약에 있다는걸 안다해도 정확히 cache에 어디있는지 어떻게 알아요?
그리고 본질적으로는 이런 의문이 드실수도 있습니다
우리가 계산하는 메모리 주소는 lower의 메모리주소인데 cache는 cache의 주소를 가지고 있잖아요 그러면 우리가 instruction으로 계산한 lower의 address를 가지고 cache의 주소를 알 수 있어야하지 않을까요?
이러한 의문점들을 해결해줄수 있는 방법이 있습니다!
Direct Mapped Cache라는 방식과 Set Associative Cache라는 방식인데요 지금부터 이 두가지 방식에 대해 알아보겠습니다
Direct Mapped Cache
Direct Mapped Cache방식의 기본적인 아이디어는 이렇습니다
각 메모리주소를 cache의 block갯수로 나눈 나머지를 cache의 주소로 하자!
이를 수식으로 만들어보면 이렇겠죠
cache index=memory address%the number of blocks in the cache
(cache의 address는 index라고 부릅니다)
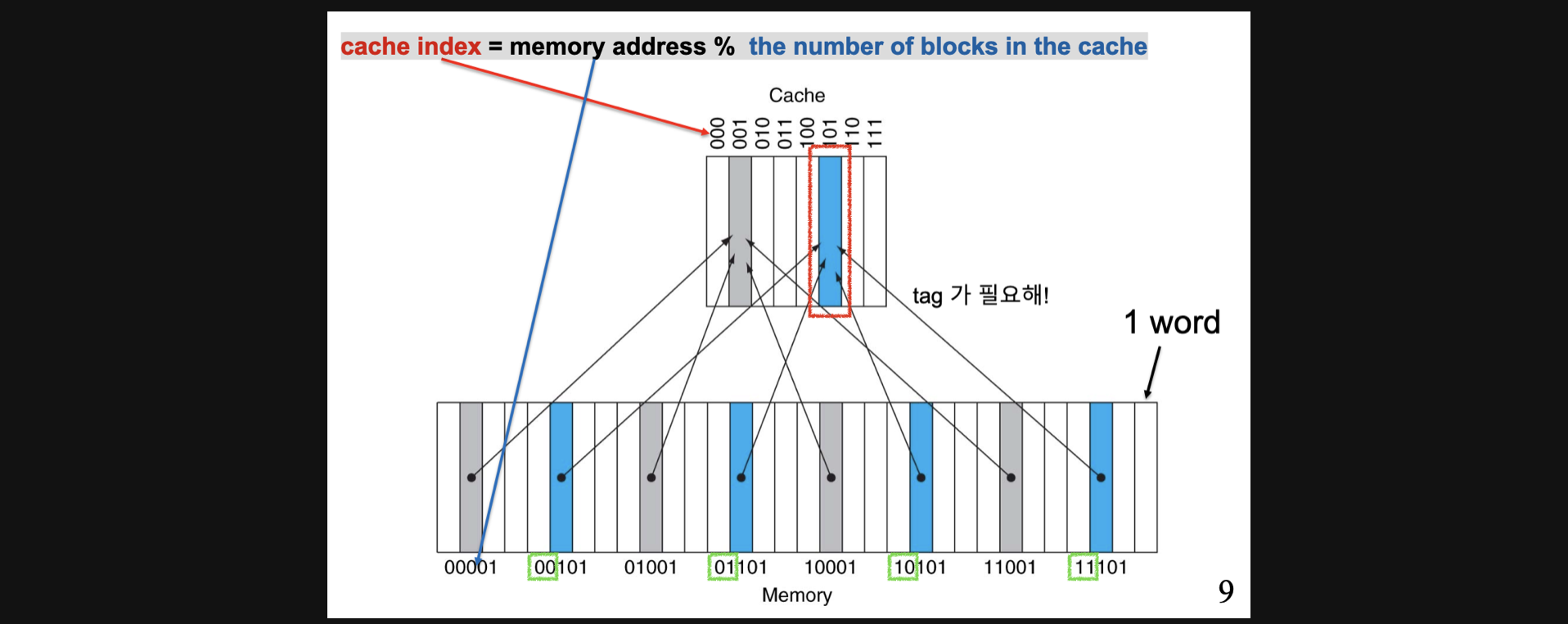
우선 어떤 메모리(lower)에서 upper인 cache에 데이터를 copy할때 파란색을 위주로 보면 cache의 block갯수는 8개이니 각 lower의 address를 8로 나눈 나머지인 101이라는 index에 데이터를 넣으면 됩니다
하지만 00101도 01101도 10101도 11101도 전부 같은 cache index에 저장됩니다
사실 메모리에 비해 cache의 용량이 적어서 이렇게 덮어쓰여지는건 어쩔수가없습니다 하지만 반대로
cache에 101 Index에 접근했을때 이 데이터가 memory에 어느 주소에서 온 데이터인지 알수가 없습니다
8로 나눈나머지가 101인 메모리주소가 그림에서는 4개나 되니까요
그래서 tag라는 개념이 등장하게 됩니다
사실 2의 3제곱인 8로 나눈나머지를 구하는데 필요한 bit의 갯수는 3개입니다 처음부터 3개가 나머지가 되니까요 애초에 그 뒤에 bit는 딱 나눠떨어지니까 나머지연산에서 의미상 필요가 없는 bit가 됩니다 근데 이 bit는 결국 address를 나타내기에 unique함을 나타낼수있습니다
결론적으로 2의 3제곱 갯수만큼 cache block을 가지고 있는 경우 lower의 address에서 3개의 bit를 제외한 나머지를 tag로 설정되게 되고 이를 통해 어떤 lower block에서 cache로 copy가 되었는지를 구분할 수 있게됩니다
예를 들어서 그림에서 101 Index에 있는 값의 tag가 00이라면 lower에서 맨 처음 파란블럭에서의 데이터라는걸 알 수 있게되는겁니다
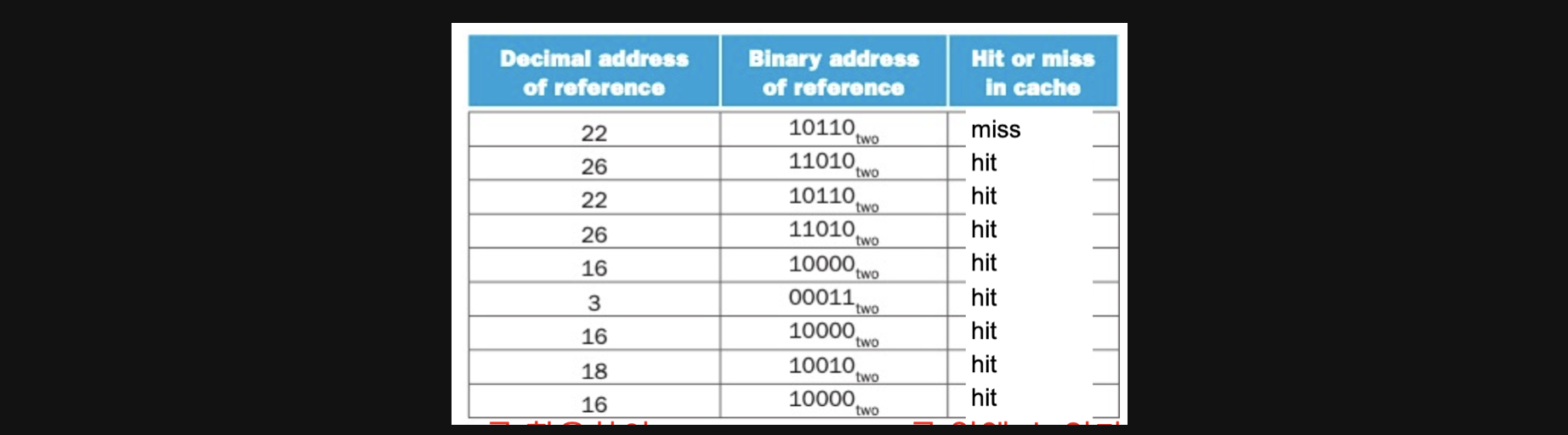
실제로 이런 Direct Mapped Cache가 어떻게 동작하는지 보겠습니다
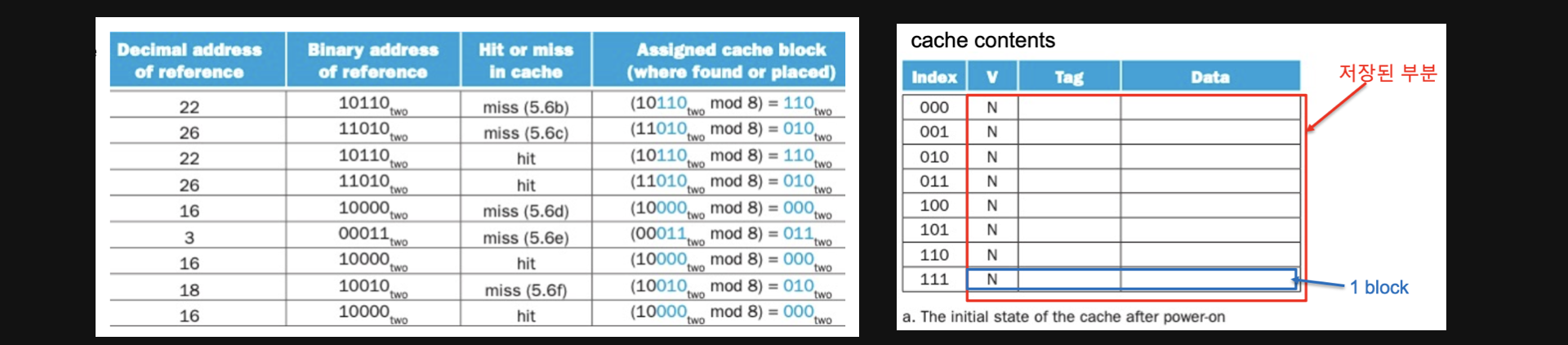
왼쪽이 실제 memory address에서부터 data를 가져오기 위한 명령어의 순서입니다
그리고 오른쪽 표가 cache를 나타냅니다 총 8개의 index가 있기때문에 memory의 address를 2의 3제곱으로 나눈 나머지 값을 cache의 index로 가집니다
우선 첫번째 명령인 address number가 22인 명령을 실행시켜보겠습니다
- address number는 이진수로 10110이기때문에 뒤에 3개 bit인 110이 나머지고 나머지 10이 tag가 됩니다
- 우선 Index가 110이니까 cache의 110 Index로 가니까 Vaild가 No네요 그럼 데이터가 없다는 뜻이니까 cache miss가 됩니다
여기서 vaild라는게 나오는데요 cache는 tag와 더불어 vaild도 가지고 있습니다 데이터가 있는지 없는지를 확인합니다 아얘없으면 애초에 cache hit이 일어날 수 없으니까요 근데 vaild가 Yes인데 miss일 경우가 있죠
Index는 맞지만 tag가 다른경우, 그런경우도 miss가 됩니다
결국은 valid가 Y이고 tag까지 같아야 hit이 된다는걸 알수있습니다
둘중하나라도 조건이 맞지 않는다면 miss인거죠
참고로 valid가 N인 경우, 애초에 프로그램이 시작할때 처음 불리는 데이터라 어쩔수없이 miss가 발생하는 경우를 cold miss라고 합니다
그러면 miss가 되었으니 lower에서 데이터를 가져다가 cache에 넣어야겠죠
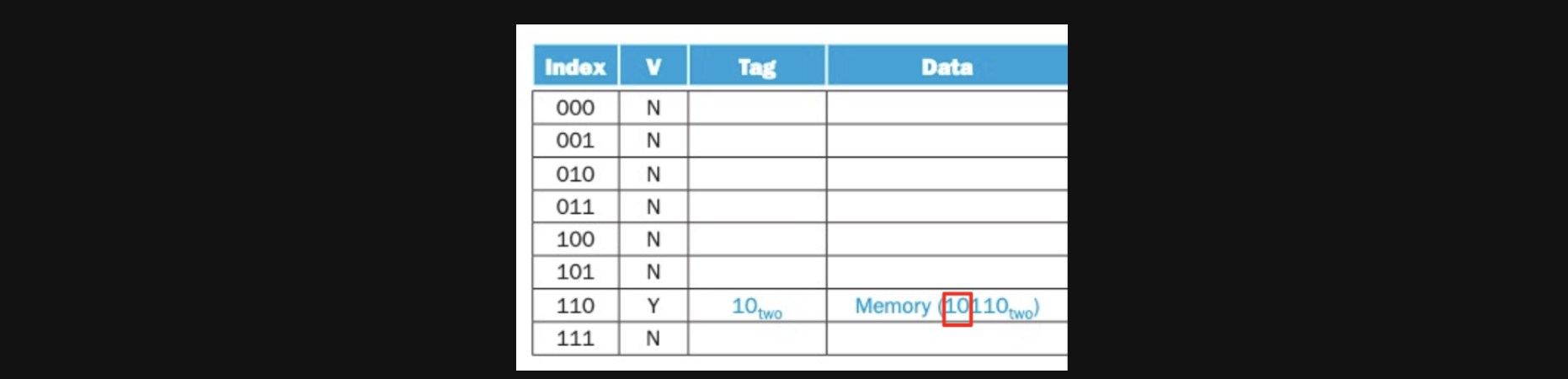
valid가 Y로 바뀌고 tag도 들어갔습니다 Data에 들어있는 Memory(10110)이라는 뜻은 메모리에 10110이라는 주소에 있는 데이터를 의미합니다
(사실여기서는 데이터를 가져오는 방식이기때문에 뭐가들어있는지는 관심이없어서 이렇게 표현을 했습니다)
자 그럼 두번째 주소에있는 데이터를 access해볼텐데요
26이니까 이진수로 11010이네요 index는 010이고 tag는 11인데 valid가 N니까 이번에도 cold miss네요 lower에서 가져와서 넣어줍시다
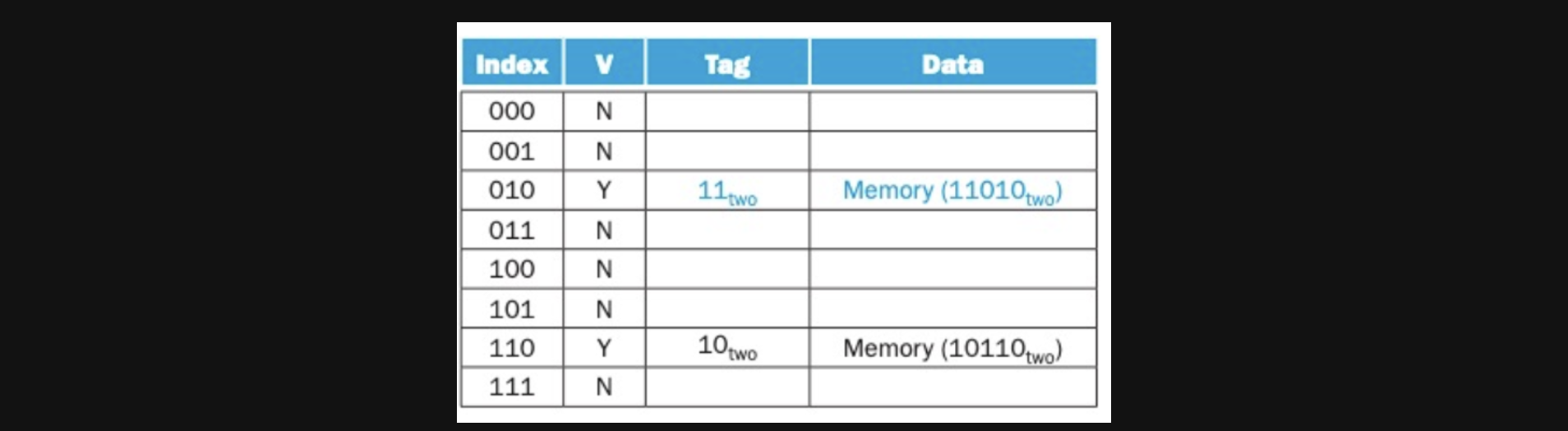
세번째 address에서 data를 access해볼텐데요
22니까 10110이고 index는 110, tag는 10이 됩니다
cache에 110으로 갔더니 valid가 Y이고 tag가 10이네요 lower에 가지 않아도 되는 hit입니다
네번째인 26도 마찬가지겠죠
여기서 각 22들과 26들은 서로 시간적지역성덕분에 cache에서 데이터를 빠르게 access할수있게 된거라고 볼 수 있습니다
22를 access한지 얼마안되서 다시 22에 access했으니까요(26도 마찬가지고요)
그리고 address 16의 data를 access하면 이친구도 cold miss니까 lower에서 copy해와야겠네요
이때까지의 결과는 아래와 같습니다 (3도 cold miss입니다)
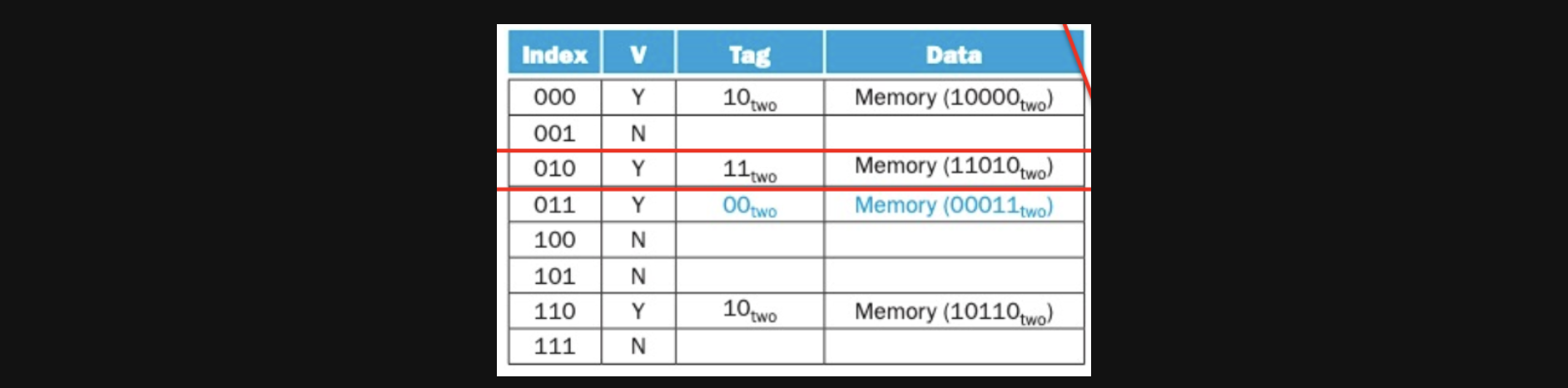
이렇게까지 왔을때 address 18의 data에 access해보겠습니다
18은 이진수로 10010이니까 index는 010이고 tag는 10이죠
그리고 cache로 가니까 010 index에 이미 값이 존재하고 그 값의 tag가 다릅니다
이럴경우 데이터를 바꿔줘야합니다 이런경우를 conflict miss라고 합니다

왼쪽의 cache가 오른쪽의 cache로 바뀌었습니다
이후에 다시 26 address의 data에 access하려면 어떤일이 발생할까요 이전에는 시간적지역성 때문에 cache에서 빠른 access가 가능했는데 시간적으로 가깝지 않아서(이전 26이 불린지 시간이 좀 지남) 시간적 지역성의 특징이 사라지게된겁니다
지금까지 본 예시는 cache의 한블럭에 저장된 data가 하나의 주소만 가지고 있습니다 하지만 실제로는 이렇게 되지 않고 byte단위로 address를 설정하게 됩니다
cache에서 하나의 data가 1word라고 가정하고있는데 사실 여기에는 하나의 address가 있는게 아니라 총 4개의 address가 존재하는것이 byte addressing방식이고 실제로 이런방식으로 동작합니다
byte addressing
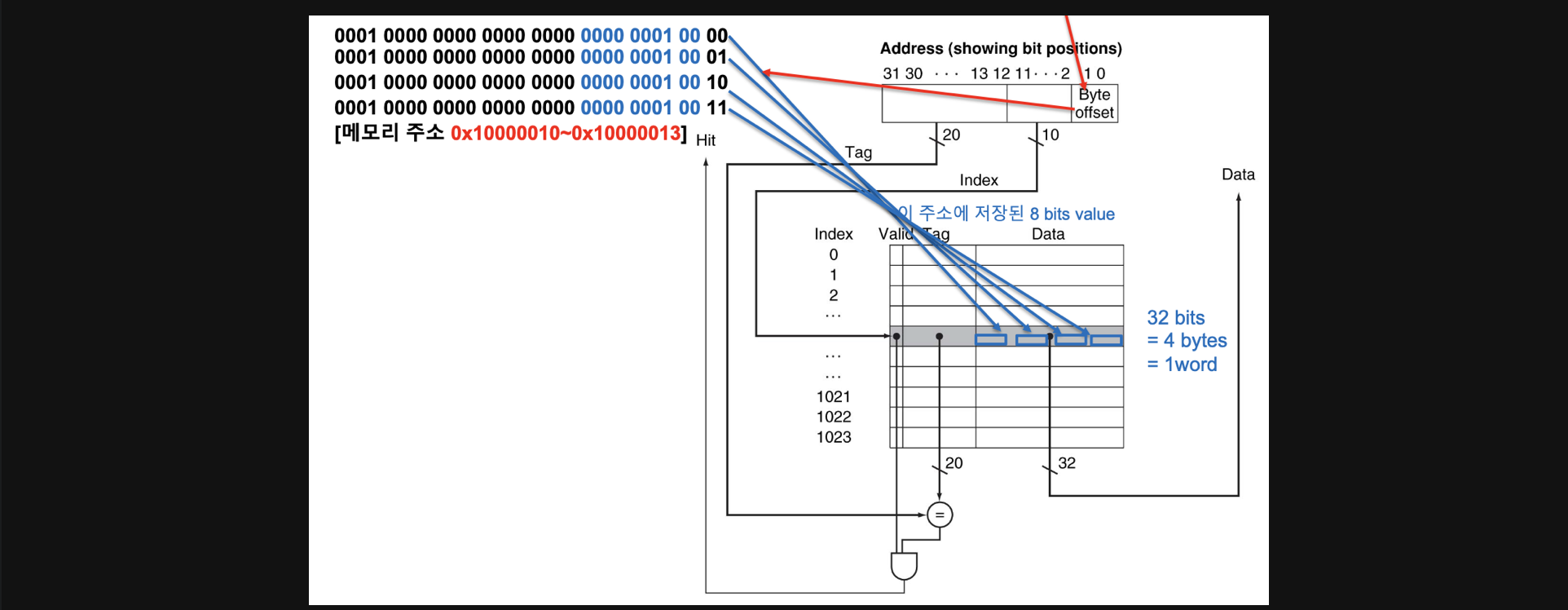
무슨말이지...? 하실수도 있습니다
1word라는 크기의 데이터는 32bit가 총 4개 들어갈수있습니다
하지만 우리가 이전에 배웠을때 하나의 address는 32bit를 가질수있고 이게 4byte씩 끊어서 address를 갖는다는말과 같은말이라고 배웠습니다
그렇다는 말은 1words안에는 사실 4개의 address가 들어가야한다는 뜻이됩니다
그런데 결국 그 word안에서 4개의 address는 두개의 비트만으로도 구분이 가능하기때문에
address의 맨뒤에 두bit는 해당 cache블럭내에서 데이터단위로 구분할수있는 byte offset으로 사용하게되고 그 두bit를 제외한 10개의 bit를 index로 사용하고 나머지를 tag로 사용하게됩니다
10개의 bit를 index로 사용하는 이유: 이번그림에서 cache의 블럭 갯수가 1024개(= 2의10제곱)이기 때문에
이부분이 계속 헷갈릴수도있기때문에 한번더 설명을 해보겠습니다
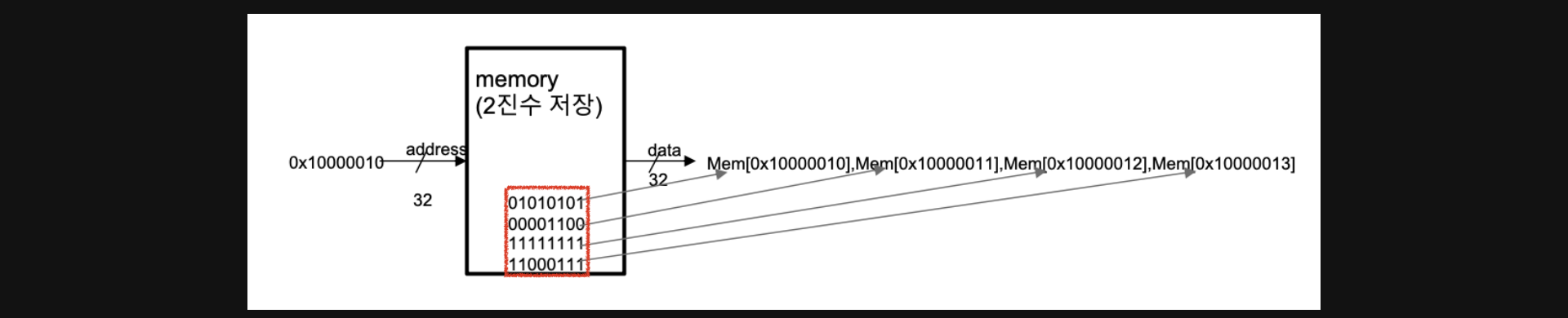
예를들어서 0x100000010이라는 address에서 빨간색네모의 데이터가 저장되어있다고 가정하겠습니다
실제로 0x100000010에서 1word만큼의 데이터를 가져온다는건 4byte씩 4개를 가져온다는 의미입니다
하지만 실제 메모리에서는 4byte당 하나의 address를 가지고 있기때문에
0x100000010에서 1word만큼의 데이터를 가져온다는건 이 address를 시작점으로 4개의 address에서 data를 가져온다는 뜻이됩니다
다시말해서 0x100000010에서 1word만큼의 데이터를 가져온다는건
0x100000010주소에있는 01010101이라는 데이터와
0x100000010바로다음 주소 0x100000011에 있는 00001100이라는 데이터와
0x100000011바로다음 주소 0x100000012에 있는 11111111이라는 데이터와
0x100000012바로다음 주소 0x100000013에 있는 11000111이라는 데이터를 들고온다는 뜻이됩니다
다시 이 그림을 보겠습니다
우리가 0x100000010이라는 address에 데이터를 access할거라는 얘기는
1block당 1word이기때문에 4개의 주소가 하나의 block에 들어간다는 의미이고
block내에 주소가 4개들어있어 address에서 두개의 bit를 byte offset으로 사용하게됩니다
그렇게 되면 cache에서 tag는 0x10000이 됩니다(파란부분은 10bit로 index로 사용한다)
Direct Mapped Cache에서의 spatial locality
좀전에 봤던 예시는 block당 1word의 data가 있는 상태였는데요 이를확장해서 1block당 16word가 되면 어떤일이 생길까요?
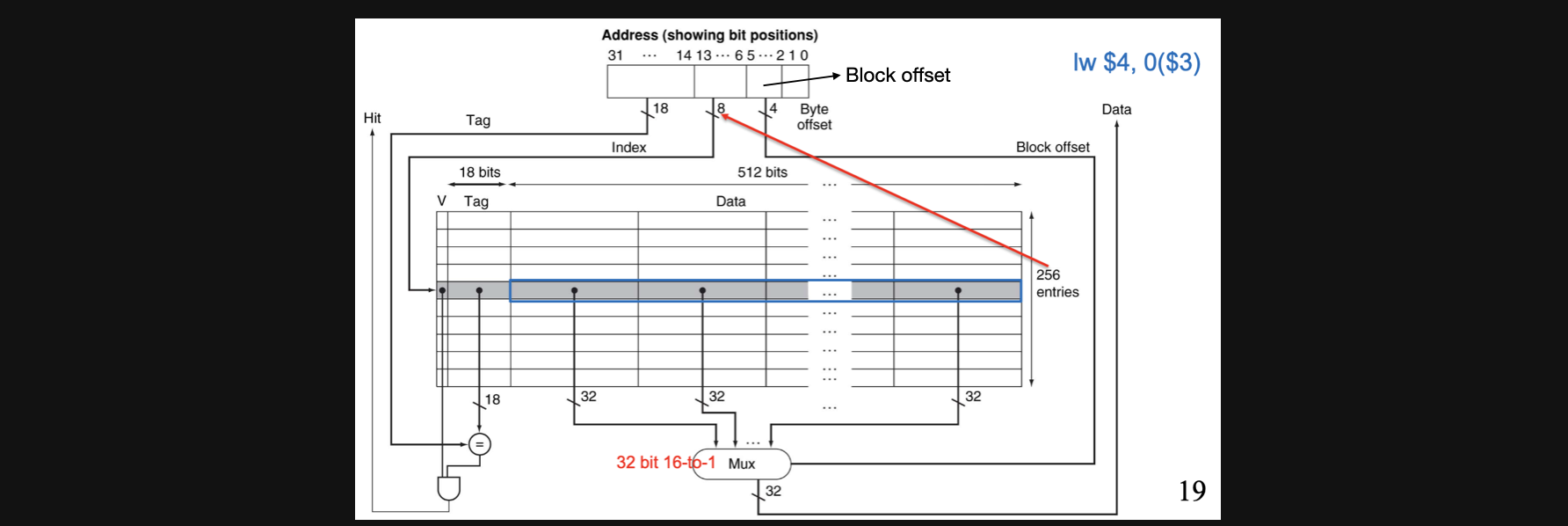
lw연산이 있고 여기서 $3에서 offset을 0더해준 address에서 data에 access해야한다고 생각해봅시다
16word라는건 결국 word안에는 4개의 address가 있어야하니까 address에서 맨뒤에 두 bit는 byte offset으로 사용할 수 있습니다
그런데 이번에는 word끼리도 구분을 해야하죠? 그리고 16word라는건 2의 4제곱이기때문에 4bit를가지고 구분이 가능합니다. 그러면 byte offset을 제외한 맨 뒤에 4bit는 block offset으로 사용해야합니다
그리고 총 cache의 Index가 0부터 255까지 256개가 있으므로 2의 8제곱이라 나머지 bit들중에서 8bit는 index를 나타내고 나머지 bit들이 tag를 나타내게 됩니다
그래서 각 word들의 data중에서 block offset이 일치하는 저녀석을 골라주는 16-to-1 mux를 통해서 하나의 data에 access할 수 있게됩니다

16word cache에서 하나의 data에서 불러온 16word데이터중에 일부를 가져와봤습니다 한번 분석해보겠습니다
우선 빨간박스를 보면 byte offset앞에 초록색 글씨로 0000이 공통이라는건 이 네개의 데이터가 0번째 word에 있다는 의미입니다
그리고 이 word는 0x04번 Index에 있는거고 tag는 0x00000입니다
파란색 박스를 보면 index와 tag는 빨간박스와 동일한데 block offset이 0100이니까 4번째 word에 있다는겁니다
초록 박스를 보면 빨간박스 파란박스와 동일한 cache index에 있고 16번째 block에있습니다
이렇게 16word로 direct mapped cache를 하게되면 어떤 장점이 있을까요 우리가 이전에 했던 예시를 그대로 한번 해보면(한번 해보세요 어렵지 않습니다!)

물론 처음에 22라는 address의 data에 access할때는 cold miss가 발생하겠지만 이후에 접근하는 모든 address의 index와 tag가 동일하기 때문에 매번 hit이 가능합니다
지금까지 공부한 내용을 보면 이런 생각이 들수도있습니다
그러면 blocksize를 최대한 키우는게 좋겠네요?
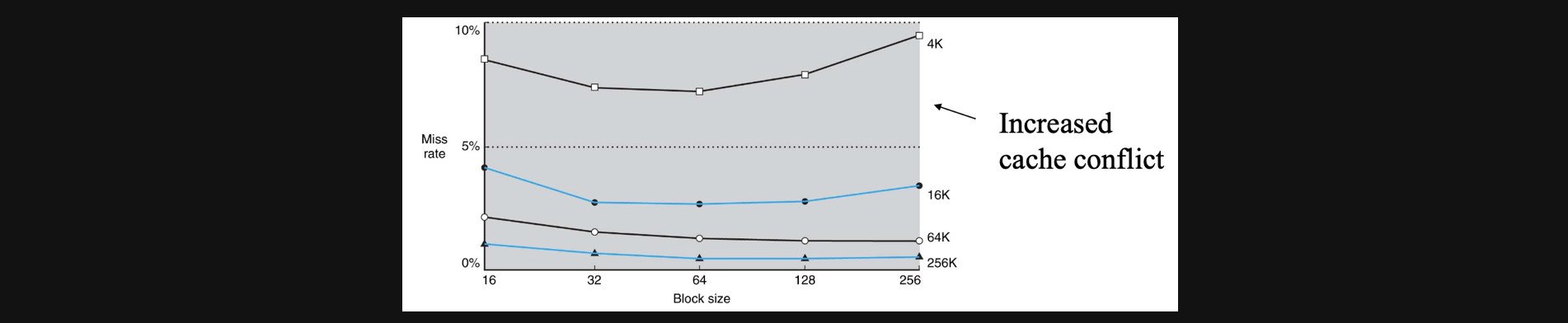
대체로 그렇긴하지만 cache의 size자체가 작다면 block의 size가 커지면 어느 순간 miss rate가 증가할수도있습니다
또한 만약에 miss가 발생해서 upper인 cache로 copy를 해야할때 block size가 크다는건 큰 용량의 데이터를 copy해야한다는 의미이기 때문에 miss ratio는 낮을지라도 한번 miss했을때 그 panalty가 크다는 문제가 있습니다
따라서 절적한 block size를 설계하는것이 중요합니다
Hits vs Misses
지금까지 저희가 봤던 hit이나 miss는 전부 data에 access할때, read할때였는데요
그러면 write할때는 어떻게 될까요
상황을한번 가정해보면 우리가 어떤 값을 write하려하는데 hit이되어서 cache에다가 데이터를 write하면
lower인 메모리에 있는 데이터가 틀린 data가 됩니다
그리서 이런 일관성(consistance)문제가 발생하게 됩니다
이를 해결하는 방법에는 두가지가 있는데요
- cache가 업데이트 될 때마다 memory를 업데이트하는 방식
- 읽을 때도 cache에서 읽을테니까 우선 memory에 업데이트를 하지 않는다 하지만 conflict miss때문에 지워질수도있는데 그 시점에 memory에 data를 새로운 값으로 업데이트 시킨다
이런방식을 통해서 write할때의 cache구조에서의 consistance문제를 해결할 수 있습니다
Set Associative Cache
우리가 performance 즉, CPU의 성능을 계산할때 이런공식으로 계산을 했습니다
CPU Time=Instruction CountXCPIXClock cycle Time
근데 만약에 어떤 이유로인해서 stall이 발생한다면 Instruction을 수행하는 시간에 stall의 갯수와 stall하나당 수행시간을 추가해줘야합니다
그리고 stall은 miss ratio와 miss panalty에 비례합니다
그렇기때문에 stall을 줄이기위해선 miss ratio와 miss panalty를 줄여야하는데
Set Associative Cache방식은 이중에서 miss ratio을 줄이기 위한 방식으로 사용됩니다
다시 1blcok당 1word의 cache로 돌아가보겠습니다
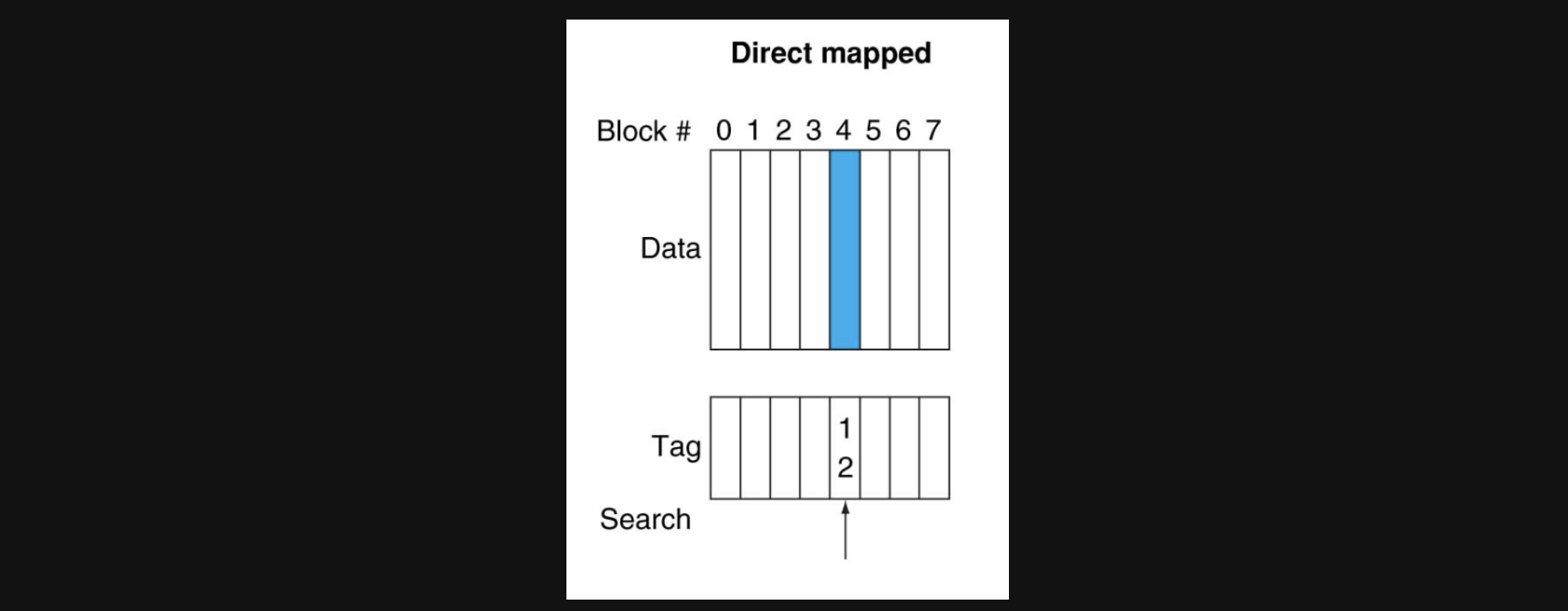
이 경우 direct mapped방식의 경우 각각 address가 index와 tag를 가지고 cache에 특정한 위치에 저장되는 방식이었습니다. 이렇게 하게되면 index가 같더라도 tag가 다르면 매번 confict miss가 발생하게 됩니다
Set Associative cache 그중에서도 우선 2 way associative방식을 보겠습니다
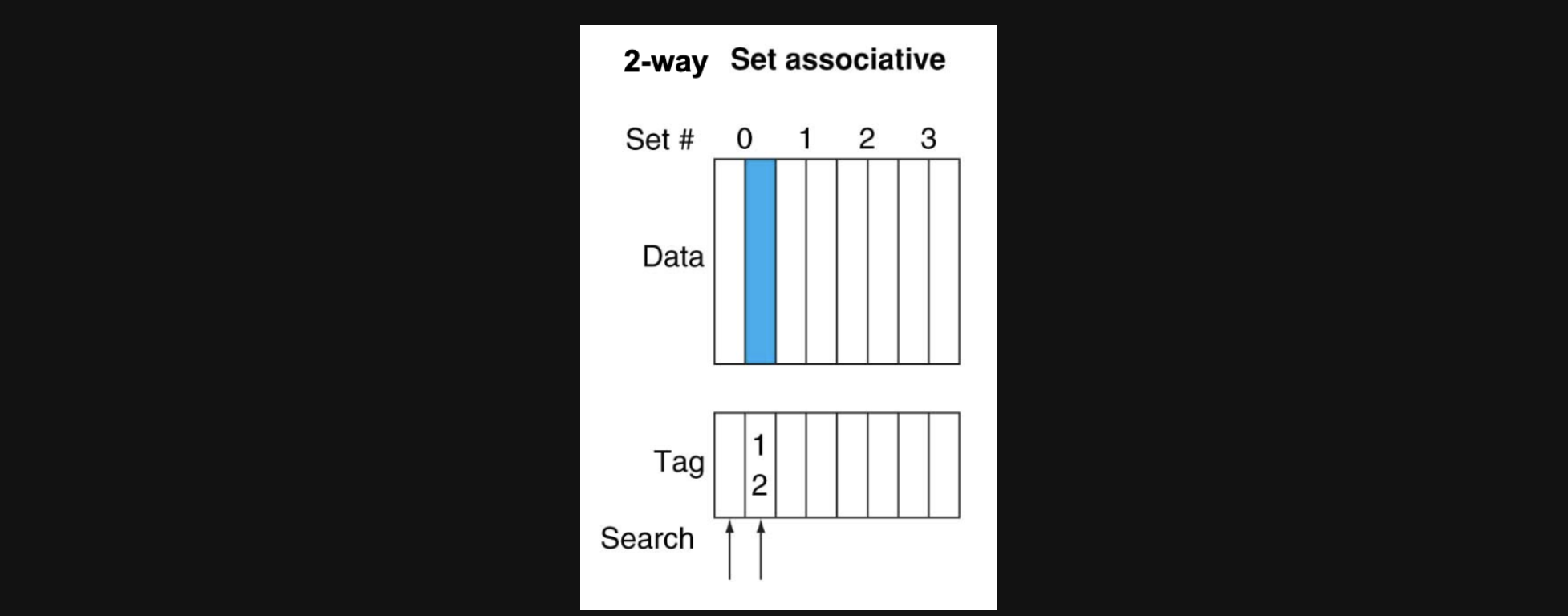
2way associative방식을 사용하게되면 하나의 index가 두개의 tag데이터를 저장할수있는 구조로 바뀌게 됩니다 이렇게되면 index가 같은데 tag가 다른 두개의 data를 저장할수있어서 tag가 다르다고 무조건 conflict이 발생하지 않게됩니다
기존의 direct mapped방식보다 miss ratio가 줄어들게 됩니다
4way라면 하나의 index영역에 4개의 tag를 가진 data를 저장할수있어 2 way보다는 miss ratio가 더 줄어들수있습니다 그리고 Fully associative가 있는데 모든 cache영역에 데이터를 tag별로 순차적으로 저장해서 사용할 수 있습니다
예를들어서 우리가 0,8,0,6,8이라는 address에 있는 data에 access할때
direct mapped cache라면 아래와같은 결과를 얻을 수 있습니다
cache가 4개의 block을 가지고 있기때문에 4로나눈나머지가 index가 됩니다
0의 index는 0, 8의 index는 0, 6의 index는 2가 됩니다

cold miss와 conflict miss가 연쇄적으로 발생하기도 했고 순서대로 address에 data에 access할때마다 miss가발생해서 miss ratio가 100%입니다
이순서 그래도 2 way set associative cache방식으로 data access를 수행해보면

한번의 hit이 발생했고 miss ratio가 80%로 개선된걸 확인할 수 있습니다
그러면 fully associative cache방식으로 하면 어떻게 될까요

두번의 hit이 발생해서 miss ratio가 60%로 개선될걸 확인할 수 있습니다
Replacement Policy
우리가 cache에서 어떤 data를 지우고 새로쓸때 어떤기준으로 지울걸 결정해서 명령을 수행해야하는지에 대해 잠깐 알고가야할 필요가 있습니다
사실 direct mapped방식에서는 선택할필요가 없죠 그냥 내자리에 있는 녀석을 지우고 값을 넣으면되니까요
그런데 set associative방식에서는 2way일때 index가 같고 tag가 다른데 이미 두개가 차있다면 둘중하나를 지워야합니다
어떤 기준으로 지워야할지에대한 내용이라고 생각하시면 편할거같아요 두가지방식이있습니다
첫번째는 Least-recently used라고 불리는 LRU방식이있고 오랫동안 사용되지 않은 녀석을 지우는 방식입니다
두번째 방식은 Ramdom이고 말그대로 랜덤하게 한친구를 골라서 지우는 방식입니다
4-way set associative cache
4-way의 set associative cache의 예시를 한번 보기전에 set associative cache와 direct mapped cache의 차이점에 대해서 한번 짚고 넘어가겠습니다
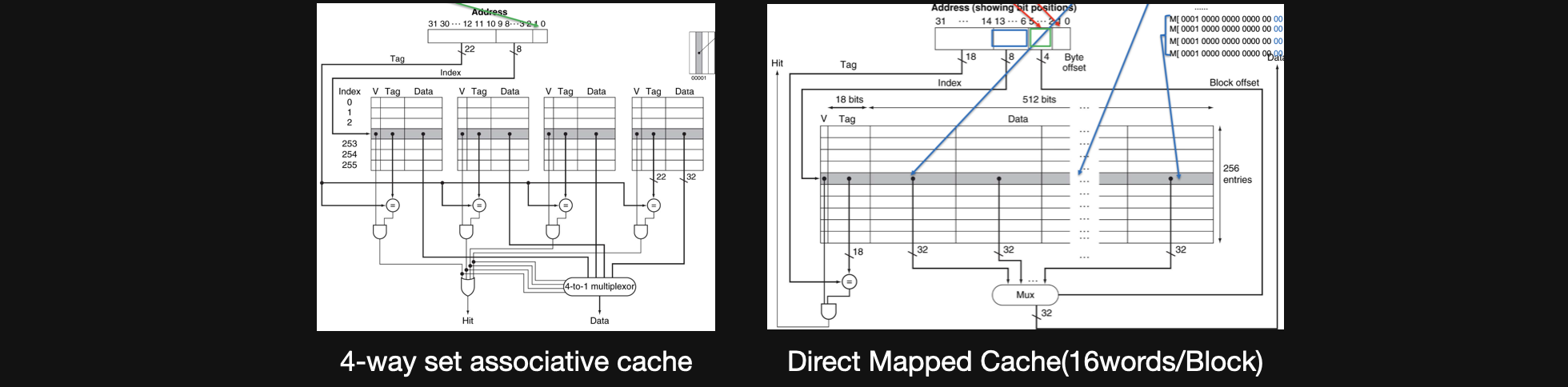
set associative cache의 경우에 하나의 index에 여러개의 valid, tag, data의 set이 들어있는 형태이고 direct mapped cache의 경우 하나의 index, valid, tag에 매우 큰 데이터 묶음이 하나 들어있는 형태입니다
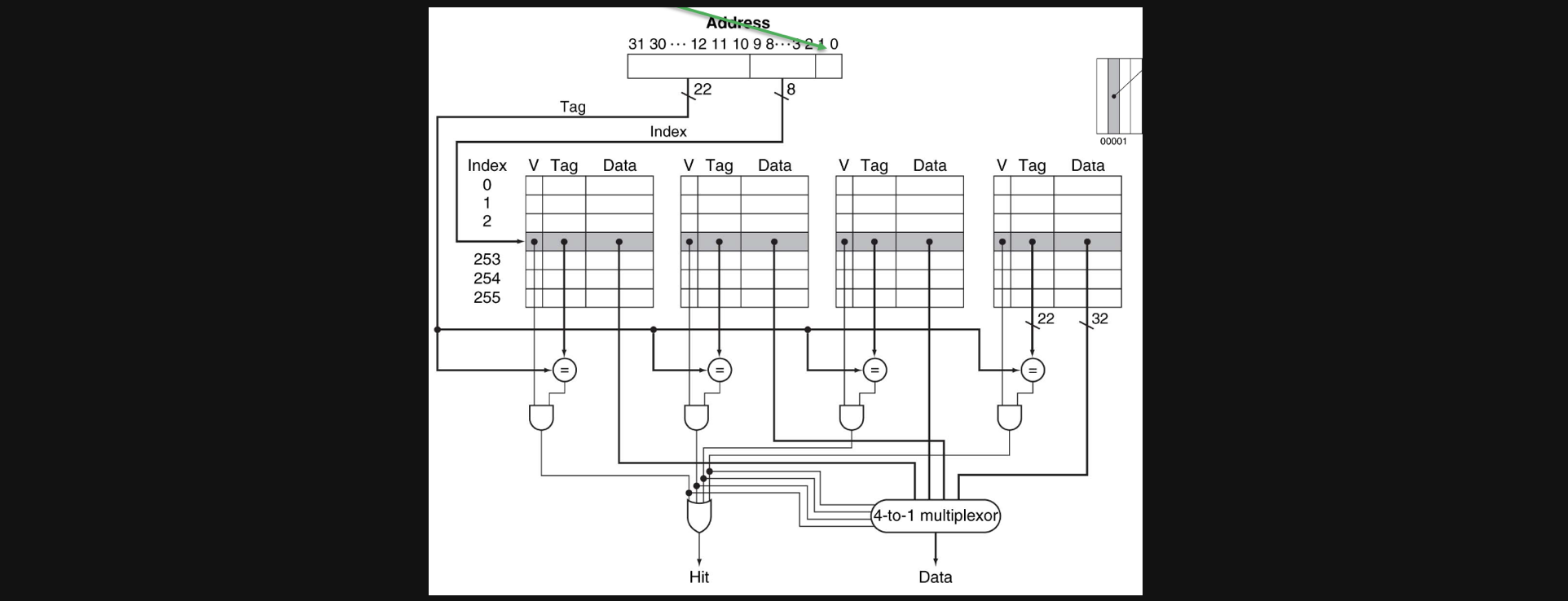
우선 이번에 보는 4way set associative cache는 1word/block이라고 가정하겠습니다
그렇게 되면 하나의 block에는 4개의 byte가 들어가기때문에 address에서 두bit만 byte offset으로 사용되고 index가 256개이므로 2의8제곱이라 8bit는 index, 나머지는 tag를 위한 bit로 사용됩니다
index를 가지고 valid, tag, data의 set각각을 address에서의 tag와 비교해주고 만약에 있으면 hit을 주고 그중에서 맞는 data에 access할수있게 mux회로를 거치게됩니다
예시를 하나 보겠습니다

빨간네모안에 있는 data들은 1word안에있는 데이터이기때문에 4byte씩 주소를 가지고있습니다 이러한 byte offset을 2bit가지고 있고 index는 256 = 2의8제곱이기 때문에 8bit로 나타내야합니다
그렇게 하면 빨간네모안에는 0x03이라는 index에 들어있고 tag는 0x100000이됩니다 set associative cache는 같은 index안에 valid, tag, data의 set을 가지고 있기때문에 tag가 0x100000인 set에 data가 들어가게됩니다
초록색네모를 보면 index가 그대로 0x03이고 tag는 0x20020C입니다 같은index에 있지만 다른 set에 들어있는 데이터입니다, 이런방식으로 파란색 네모도 같은 index에 들어있게됩니다
특정 address가 들어오면 가리키는 index에 있는 모든 set들을 tag와 비교해서 맞는게 하나라도 있으면 hit을 내보내주고 그중에서 한개를 access하게 해줍니다
이런방식이 set associative cache입니다
Cache Performance as a function of associativity
그러면 way를 늘릴수록 miss ratio가 줄어드니까 늘릴수록 좋은거라고 생각할수도있지만 실제 그래프를 보면
cache의 크기가 작을때는 way가 늘어나도 실제로 miss ratio가 줄어들지 않는 결과를 보여줍니다
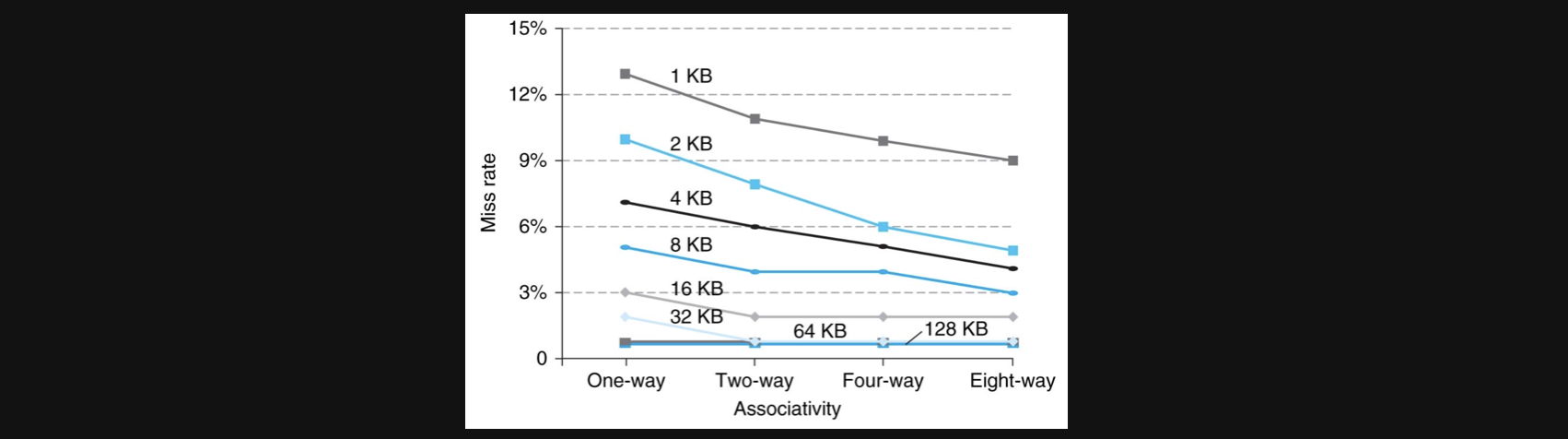
따라서 set associative cache또한 무조건 늘리기보다는 상황에 맞게 결정해야합니다
Cache Misses

지금까지 cache를 통해 CPU의 성능을 향상시키는 여러방법을 알아봤습니다
만약에 cache size를 키운다면 당연히 capacity miss가 줄어들겠지만 cache에서 데이터를 찾는데 늘어난 size만큼의 과정이 더필요하기때문에 access time이 더 필요할 수 있습니다
set associativity를 늘리면 miss ratio를 줄일수있지만 이것도 cache size와 마찬가지로 cache에서 데이터를 찾는 과정이 좀더 길어져 access time이 더 필요할 수 있습니다
그럼 block size를 늘리면 miss rate을 줄일 수있지만(spatial locality) 만약에 miss가 발생하면 큰 panalty를 감수해야하며 이전에 그래프에서 봤듯이 무작정 block의 size를 늘리다보면 특정 상황에서는 오히려 miss rate이 증가할수가 있습니다
결론적으로는 모든방식이 miss rate을 줄여서 CPU의 성능을 향상시키위한 방법이지만 trade off관계나 상황에따라 negative한 performance effect가 발생해서 예상치못한 결과를 얻게될수도있기에 이런부분을 잘 예상하고 설계해야합니다

매주 최대길이 포스팅을 갱신하는거같은데 기분탓이겠죠...?
최대한 자세히 설명을한다고 했는데 혹시나 헷갈리시는 부분이 있으면 댓글로 남겨주세요!
캐시라는 말을 그냥 들어보기만했지 이런방식으로 동작한다는걸 처음알았네요
저와 비슷한 진로를 꿈꾸는 분들은 대부분 알고계실 개념이었겠지만 저는 처음 배우는거라 신기한 마음이 더 큰거같아요 그런 신기한 마음으로 컴구를 거의 끝내간다고 생각하니까 뿌듯하기도하네요 공부할때마다 기록을 남겨놔서 그런가 한달조금넘는시간동안 나름 열심히 했구나라는 생각이드네요
하지만 아직 두개정도의 포스팅이 더 남았습니다!
마지막까지 꼼꼼하게 공부하고 기록해보도록 하겠습니다
전공책을 기반으로 정리하는 글이기때문에 나름대로 최대한 이유가있는 설명을 한다고는하지만 분명히 틀리거나 추가로 들어가야할 내용이 있을수있기때문에 언제든지 댓글로 알려주세요!
그럼 20000!!!!
