Numble - Kubernetes로 모니터링 시스템 구축하기 회고
Numble(딥다이브)는 다양한 기술적 주제를 갖고 호스트님의 가이드라인/QnA 를 기반으로 참가자들이 해당 주제에 대해서 딥다이브하고, 내용을 공유하거나 피드백 받을 수 있도록 다양한 챌린지를 운영하고 있습니다.
이 회고록에서의 작업 및 내용은 https://github.com/kimsehwan96/numble-k8s 에서도 확인 가능합니다.
 (5월 3일 현재 기준 모집중인 챌린지들)
(5월 3일 현재 기준 모집중인 챌린지들)
DevOps 업무를 수행하지만 항상 부족하고 또 부족해서 여러모로 알아보고 공부하다가 이 서비스에서 Kubenretes로 모니터링 시스템 구축하기! 라는 챌린지를 대단하신 호스트님과 함께 진행한다는 소식을 듣고 잽싸게 신청하고 참가하게 되었습니다!
그렇게 OT날이 다가오고. 팀 단위의 과제 수행(그렇지만 인프라는 각자 프로비저닝하는)을 한다는 소식에 팀장을 맡기로하고 그렇게 5주간의 챌린지를 시작하게 되었습니다.
팀장을 처음부터 하겠다는 생각은 없었지만.. 비슷한 연차의 팀원들을 구성해주시기도 했고, 애초에 이러한 챌린지를 참여하신다는것이 어떤 참여 의지(?) 열정이 있으실것이라는 생각 하에 팀장이라해도 큰 일을 할건 없겠구나(?) 싶어서 하게 되었고. 정말로 다들 현업에서 열심히 하시는 분들이다보니 팀장이 크게 매니징하거나 조율해야하는 일은 없었던 것 같아 다행(?)이었습니다.
Kubernetes로 모니터링 시스템 구축하기 목차
이 챌린지에서 우리가 수행해야하는 작업은 아래와 같았습니다.
- Kubenretes 인프라 구축 (ncloud를 곁들인)
- ArgoCD 설치
- 로그 모니터링(ELK 스택과 함께)
- 지표 모니터링(kube-prometheus-stack)
쿠버네티스 인프라나, ArgoCD, ELK 스택이나 prometheus, grafana 같은 것들은 직접 설치, 연결해보기 보다는 기존에 잘 되어있는걸 추가하거나 사용하는 입장으로 일을 하고있었다보니, 직접 생성하고 설정 해 볼 일이 많이 없었는데 이번 챌린지의 주제가 딱 그런 부분들을 긁어주는 내용이다 보니 회고록을 쓰는 이 시점에서는 참 많은(?)것을 얻어 간 것다는 생각이 듭니다.
 (이렇게 가이드라인을 줍니다!)
(이렇게 가이드라인을 줍니다!)
Kubernetes 인프라 구축
Numble이 Ncloud(네이버 클라우드)와 제휴를 맺어 신규 가입 10만 크레딧 외, 20만크레딧 + 70만크레딧 즉 최대 총 100만 크레딧까지 지원 받을 수 있기 때문에 챌린지 기간 내내 Ncloud 서비스를 사용하면서 개인적인 지출을 하지 않았습니다. (고마워요 넘블!)
대부분의 팀원들은 10만크레딧(Ncloud 신규 가입자) + 20만크레딧(넘블 제휴 크레딧)이면 충분하게 사용했고 필요시 70만크레딧을 더 받아서 매우 널널하게 사용 할 수 있었습니다.
사실 학교 다닐때부터, 그리고 회사에서 일을 하면서 접하는 클라우드 공급자는 오직 AWS였기때문에 (물론 회사에서 테스트 차원에서 Ncloud를 아...주 잠깐 썼었지만..) 익숙하지 않음에 대한 거부감이 있었지만 막상 직접 인프라를 프로비저닝하고 설정하는데 있어서 문서도 잘 만들어져있고 terraform과 같은 IaC 툴 지원도 매우 매끄럽게 되는지라 회고록을 작성하는 지금 시점에서는 Ncloud 쓰길 잘했고, 매우 쓸만하다! 라는 인상을 느꼈습니다.
Terraform 을 통한 Infra provisioning
AWS, GCP, Azure 와 같은 다른 퍼블릭 클라우드 공급자들과 마찬가지로 NCloud 또한 Terrafom 을 이용해서 인프라 리소스를 생성 가능합니다.
(https://registry.terraform.io/providers/NaverCloudPlatform/ncloud/latest/docs)
따라서 NKS(Naver K8s service)를 사용하기 위해 VPC 리소스 및 Bastion Host를 생성하도록 terraform을 작성하고, 이후 NKS 위에 워커노드를 생성하도록 아래와 같이 terraform을 작성하였습니다.
terraform {
required_providers {
ncloud = {
source = "NaverCloudPlatform/ncloud"
}
}
required_version = ">= 0.13"
}
// Configure the ncloud provider
provider "ncloud" {
support_vpc = true
region = var.region
access_key = var.access_key
secret_key = var.secret_key
}
// Create a new server instance
resource "ncloud_vpc" "vpc" {
ipv4_cidr_block = "10.0.0.0/16"
}
// Create private and public subnets
resource "ncloud_subnet" "public_subnet_1" {
vpc_no = ncloud_vpc.vpc.id
subnet = "10.0.100.0/24"
zone = "KR-1"
name = "public-subnet-1"
network_acl_no = ncloud_vpc.vpc.default_network_acl_no
subnet_type = "PUBLIC"
usage_type = "GEN"
}
resource "ncloud_subnet" "private_subnet_1" {
vpc_no = ncloud_vpc.vpc.id
subnet = "10.0.1.0/24"
zone = "KR-1"
name = "private-subnet-1"
network_acl_no = ncloud_vpc.vpc.default_network_acl_no
subnet_type = "PRIVATE"
usage_type = "GEN"
}
resource "ncloud_subnet" "private_subnet_load_balancer_1" {
vpc_no = ncloud_vpc.vpc.id
subnet = "10.0.200.0/24"
zone = "KR-1"
name = "private-subnet-lb-1"
network_acl_no = ncloud_vpc.vpc.default_network_acl_no
subnet_type = "PRIVATE"
usage_type = "LOADB"
}
resource "ncloud_login_key" "loginkey" {
key_name = "numble-cluster-login-key"
}
data "ncloud_server_image" "image" {
filter {
name = "product_name"
values = ["ubuntu-20.04"]
}
}
data "ncloud_server_product" "worker" {
server_image_product_code = data.ncloud_server_image.image.product_code
filter {
name = "product_type"
values = [ "STAND" ]
}
filter {
name = "cpu_count"
values = [ 4 ]
}
filter {
name = "memory_size"
values = [ "16GB" ]
}
filter {
name = "product_code"
values = [ "SSD" ]
regex = true
}
}
// kubernetes cluster
data "ncloud_nks_versions" "version" {
filter {
name = "value"
values = ["1.24"]
regex = true
}
}
resource "ncloud_nks_cluster" "cluster" {
cluster_type = "SVR.VNKS.STAND.C002.M008.NET.SSD.B050.G002"
k8s_version = data.ncloud_nks_versions.version.versions.0.value
login_key_name = ncloud_login_key.loginkey.key_name
name = "my-cluster"
lb_private_subnet_no = ncloud_subnet.private_subnet_load_balancer_1.id
kube_network_plugin = "cilium"
subnet_no_list = [ ncloud_subnet.private_subnet_1.id ]
vpc_no = ncloud_vpc.vpc.id
zone = "KR-1"
log {
audit = true
}
}
resource "ncloud_nks_node_pool" "node_pool" {
cluster_uuid = ncloud_nks_cluster.cluster.uuid
node_pool_name = "numble-node-pool"
node_count = 1
product_code = data.ncloud_server_product.worker.product_code
subnet_no = ncloud_subnet.private_subnet_1.id
autoscale {
enabled = false
min = 1
max = 1
}
}
// Creat NAT Gateway for K8s Worker node on private subnet to access internet
resource "ncloud_nat_gateway" "nat_gateway" {
vpc_no = ncloud_vpc.vpc.id
zone = "KR-1"
}
resource "ncloud_route" "nat_route" {
destination_cidr_block = "0.0.0.0/0"
target_type = "NATGW"
target_name = ncloud_nat_gateway.nat_gateway.name
target_no = ncloud_nat_gateway.nat_gateway.id
route_table_no = ncloud_vpc.vpc.default_private_route_table_no
}
// for bastion server
resource "ncloud_network_interface" "bastion_network_interface" {
name = "bastion-network-interface"
description = "bastion network interface
subnet_no = ncloud_subnet.public_subnet_1.id
access_control_groups = [
ncloud_nks_cluster.cluster.acg_no,
ncloud_vpc.vpc.default_access_control_group_no
]
}
resource "ncloud_server" "bastion" {
subnet_no = ncloud_subnet.public_subnet_1.id
name = "numble-bastion-server"
server_image_product_code = data.ncloud_server_image.image.product_code
login_key_name = ncloud_login_key.loginkey.key_name
network_interface {
network_interface_no = ncloud_network_interface.bastion_network_interface.id
order = 0
}
}
resource "ncloud_public_ip" "bastion_public_ip" {
server_instance_no = ncloud_server.bastion.instance_no
}
위 terraform 코드를 이용하면 아래와 같은 인프라가 생성됩니다.
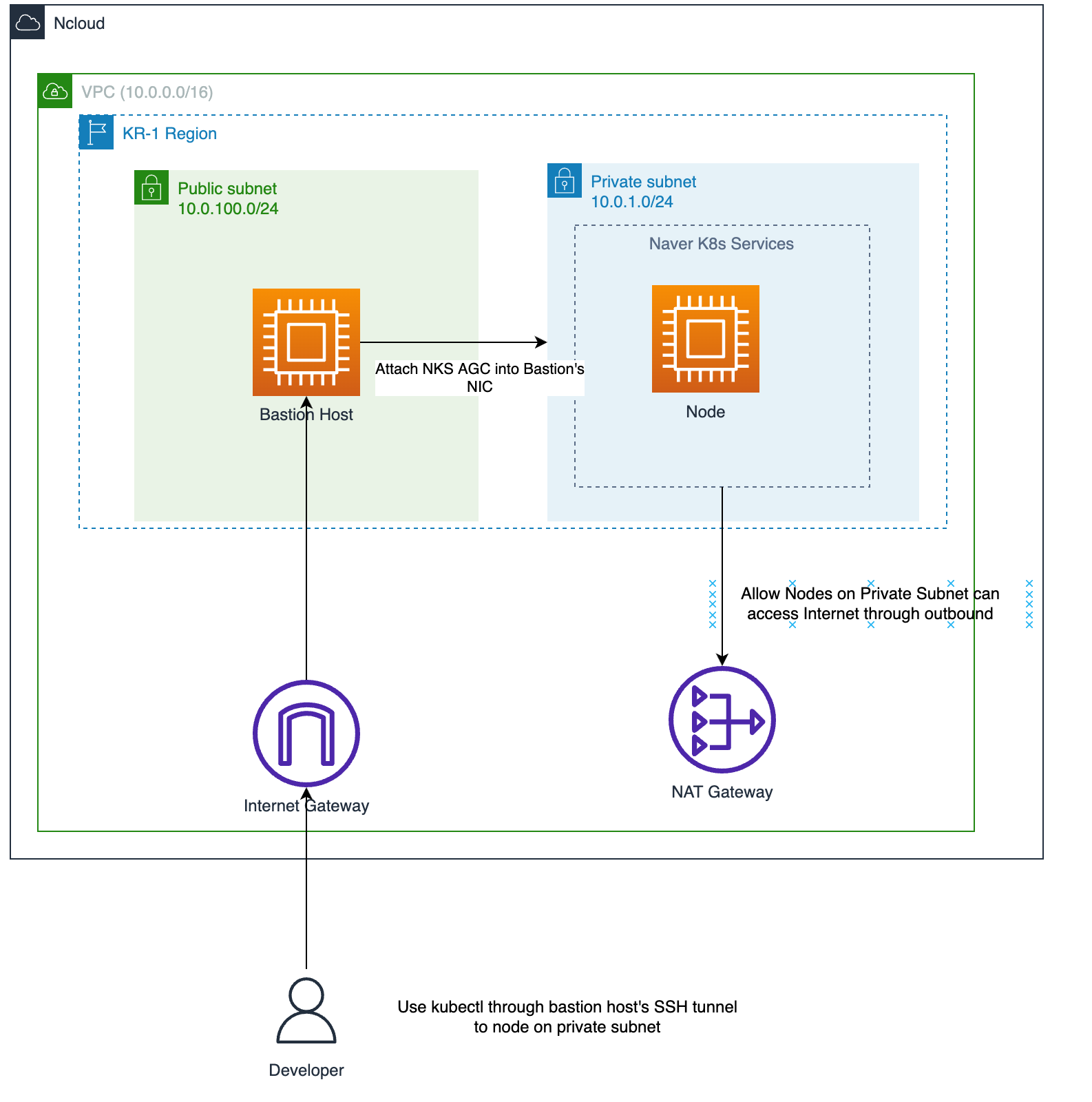
Private Subnet에 K8s 워커노드를 올려놓고(통제되지 않은 인터넷을 통한 inbound를 막기 위해서), Public Subnet에 존재하는 Bastion Host를 통해 Private Subnet에 존재하는 워커노드에 SSH 접근이나, Kubectl 등을 하도록 생성하였습니다.
이 때 Private Subnet에 존재하는 워커노드는 NAT Gateway와 같은것이 없는 경우 외부 internet access가 되지 않기 때문에 워커노드와 연결해주었습니다.
이후 https://guide.ncloud-docs.com/docs/k8s-iam-auth-ncp-iam-authenticator
ncp-iam-authenticator 등을 통하여 손쉽게 kubeconfig ($HOME/.kube/config)를 생성하고, kubectl을 사용 할 수 있었습니다.
인프라를 프로비저닝하면서 크게 어려움을 겪은 부분은 없었습니다. 대부분의 퍼블릭 클라우드가 그렇듯 비슷한 기능을 비슷한 용어로 사용하기 때문에 기존에 AWS를 사용하시던 분들이라도 충분히 Ncloud를 쉽게 사용 하실 수 있을 것 같습니다.
다만 product_code(?), cluster_type(i.e "SVR.VNKS.STAND.C002.M008.NET.SSD.B050.G002") 등을 지정하거나 찾아내는 대에 조금 어려움이 있긴 했었습니다만. 이거는 사용하시다보면 충분히 어떻게 사용하고, 어떤 의미인지 이해 할 수 있을 것 같다는 생각이 들었습니다. (물론 전 아직도 어렵습니다..)
ArgoCD 구축
ArgoCD를 설치하고, App of apps 패턴을 알려주고 반영하도록 가이드 되었습니다.
이 과정에서 Helm에 대해서 알아보도록 가이드 되었습니다. 이 과정에서.. 저 뿐만 아니라 대부분의 팀원분들께서 Helm에 대해 어려움을 느끼시고 또 많이 시간을 들여 공부하게되는 그런 과정을 거치게 되었습니다.
저 또한 Helm을 그냥 남들 따라서 사용해보고. kustomize를 이용해서 외부 저장소의 helmChart를 pull하고 value 만 조금 수정해서 프로비저닝하는, 그런것만 경험해보았는데. 이번 기회에 Helm Chart 생성 방법, template이 무엇이고 values가 무엇인지, 어떤 구조로 동작하는지에 대해서 많이 알아보게 되는 계기가 되었습니다.
 (직접 구축한 argocd)
(직접 구축한 argocd)
 (App of apps 패턴 구성)
(App of apps 패턴 구성)
App of apps 에 대해서 간단히 설명하자면, 다양한 서비스(argocd, elastic stacks, nginx, front-end app, back-end app, etc..)들을 하나 하나의 애플리케이션으로 두고, 이 애플리케이션들을 argocd에 생성하도록 하는 최상위의 App 을 생성하는 방법입니다.
보통 Cluster bootstarping (클러스터 새로 생성한 이후 초기 셋업을 한다든지..)에 유용하게 쓰이는 패턴입니다.
이번 가이드에서는 호스트님의 github repo에 예제가 있어서 유용하게 참고하면서 작업 할 수 있었는데요.
이 App of apps 패턴 또한 내용은 알겠는데 어떻게 구현해야하나.. 고민하던 찰나에 호스트님의 예제로부터 많은 힌트를 얻고 반영이 가능했습니다.
Helm을 이용해서. templates 에 argocd application을 생성하도록 하는 템플릿을 생성하는 방식으로 진행되었습니다.
values 에 지정된 namespace / name 등을 기반으로 argocd application 들이 생성되도록 작업이 되었습니다.
{{- range .Values.apps }}
---
apiVersion: argoproj.io/v1alpha1
kind: Application
metadata:
name: {{ .name }}
namespace: argocd
finalizers:
- resources-finalizer.argocd.argoproj.io
spec:
destination:
namespace: {{ .namespace }}
server: https://kubernetes.default.svc
project: default
source:
path: {{ .name }}
repoURL: {{ $.Values.repoURL }}
targetRevision: HEAD
{{- if .ignoreDifferences }}
ignoreDifferences:
{{- toYaml .ignoreDifferences | nindent 4 }}
{{- end }}
syncPolicy:
automated:
prune: false
selfHeal: false
syncOptions:
- CreateNamespace=true
- ServerSideApply=true
{{- end }}위와 같이 values 내의 apps 배열을 순회하면서 이 yaml 파일(argocd application)이 생성되고 반영되는데요.
repoURL: https://github.com/kimsehwan96/numble-k8s
apps:
- name: apps
namespace: argocd
- name: argocd
namespace: argocd
- name: nginx
namespace: nginx
- name: istio
namespace: istio-system
ignoreDifferences:
- group: admissionregistration.k8s.io
jqPathExpressions:
- .webhooks[].failurePolicy
kind: ValidatingWebhookConfiguration
name: istio-validator-istio-system
- name: eck-operator
namespace: elastic-system
ignoreDifferences:
- group: admissionregistration.k8s.io
kind: ValidatingWebhookConfiguration
jqPathExpressions:
- .webhooks[]?.clientConfig.caBundle
- name: eck-elasticsearch
namespace: elastic-system
- name: eck-kibana
namespace: elastic-system
- name: logstash
namespace: elastic-system
- name: eck-beats
namespace: elastic-systemvalues에는 위와 같이 작업하여서 각 namespace 별 application name을 지정하도록 하였습니다.
로그 모니터링
로그 모니터링은 사실상의 표준인 ELK 스택을 활용해서 진행하도록 가이드 되었습니다.
ECK-Operator 를 설치하여서 ES, Kibana, Beat 를 설치하도록 진행하였으며, 역시 모두 Helm을 이용합니다.
Elastic에서 Elasic Cloud on Kubernetes Operator를 제공하기때문에 (줄여서 ECK-Operator) 이것을 설치 한 이후에 ElasticSearch, Kibana 등을 설치 할 수 있습니다.
namespace: elastic-system
resources:
- ./eck-namespace.yaml
helmCharts:
- name: eck-operator
includeCRDs: true
repo: https://helm.elastic.co
releaseName: eck-operator
version: 2.6.1
namespace: elastic-system저는 위와 같이 별다른 설정 없이 고대로 설치해서 사용했었고. namespace 나 release name 등은 회사나 조직의 내부 룰이 따라서 지정해서 사용하면 되겠습니다.
이후에 elasticsearch를 설치하고자 하는데. 문제는 Elastic 의 helm repo를 pull 해서 반영하게되면 license 문제가 발생해서 (아마 Helm으로 설치하는것을 라이센스 정책을 반영하려는 것인지는 잘 모르겠으나..)
https://github.com/elastic/cloud-on-k8s/tree/main/deploy/eck-elasticsearch
직접 chart / template / values 를 자신의 레포에 copy하고,
templates/elasticsearch.yaml 내에 eck.k8s.elastic.co/license annotation 을 enterprise -> basic 으로 수정해주어야 한다.
---
apiVersion: elasticsearch.k8s.elastic.co/v1
kind: Elasticsearch
metadata:
name: {{ include "elasticsearch.fullname" . }}
labels:
{{- include "elasticsearch.labels" . | nindent 4 }}
annotations:
eck.k8s.elastic.co/license: basic
{{- if .Values.annotations }}
{{- toYaml .Values.annotations | nindent 4 }}
{{- end }}eck-kibana, eck-beats 또한 동일하게 templates 내의 yaml 템플릿을 직접 수정해주어야 한다.
이렇게 하고 helm을 통해 설치하면 ELK 스택이 완성된다. (ES + Logstash + Kibana)
실제 로그수집은 Filebeat -> Logstash -> ES 의 흐름으로 진행되도록 가이드 되었는데
Filebeat 에서 알아볼만한 내용인 스크래핑할 로그파일 위치, Autodiscover 등에 대해서는 example 을 거의 그대로 따라했지만, 추후에 다시 딥다이브 해볼만한 부분이 많아 조만간 다시 공부를 해봐야겠습니다.
Logstash에서는 Beat 와 ES 사이의 정말 stash 하는 역할을 한다는것을 많이 느꼈고, Logstash에서의 filter 설정을 통해 특정 필드를 제거하거나, 값을 바꾸거나 하는 등의 Beat <-> ES 사이의 Pipeline 설정에 대해서 더 알아보고 실험해보아야 겠다는 생각이 많이 들었습니다.
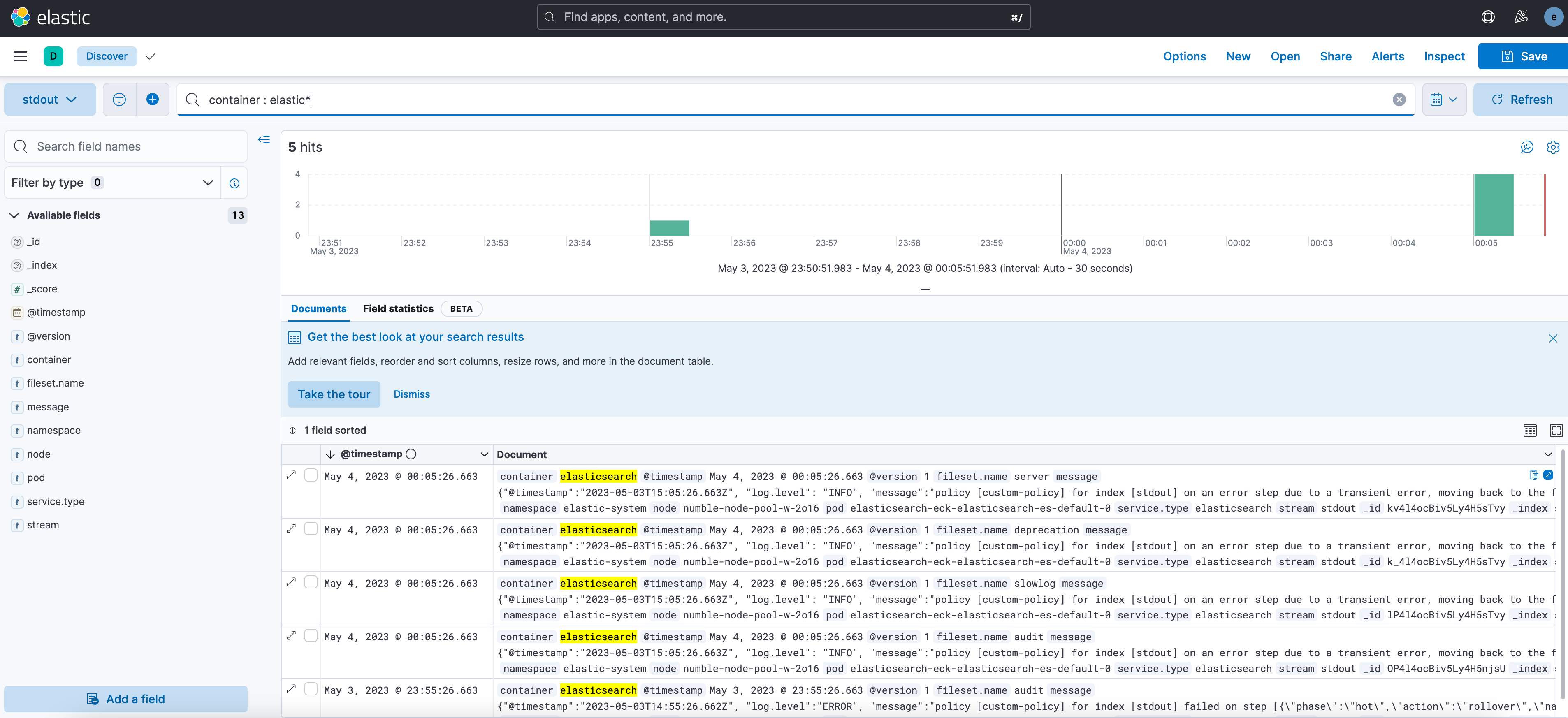 (직접 설치/구성한 Kibana)
(직접 설치/구성한 Kibana)
이 과정에서 ELK 스택에 익숙해져서(잘하진 않습니다) 기존 회사에 설치된 Elasticsearch / Kibana 관련 작업에 있어서 허들이 조금 낮아지는 느낌과, 내가 이 챌린지에서 고민하면서 작업했던 내용 중 반영할게 있을 수 있겠구나 하는 그런 생각이 많이 들었습니다.
지표 모니터링
지표 모니터링은 kube-prometheus-stack을 이용해서 구성하도록 가이드되었습니다.
kube-prometheus-stack은 prometheus, grafna, alertmanager, kube-state-metrics, node-exporter 등으로 구성되어있으며, 원하는 것만 골라서 설치 할 수 있습니다.
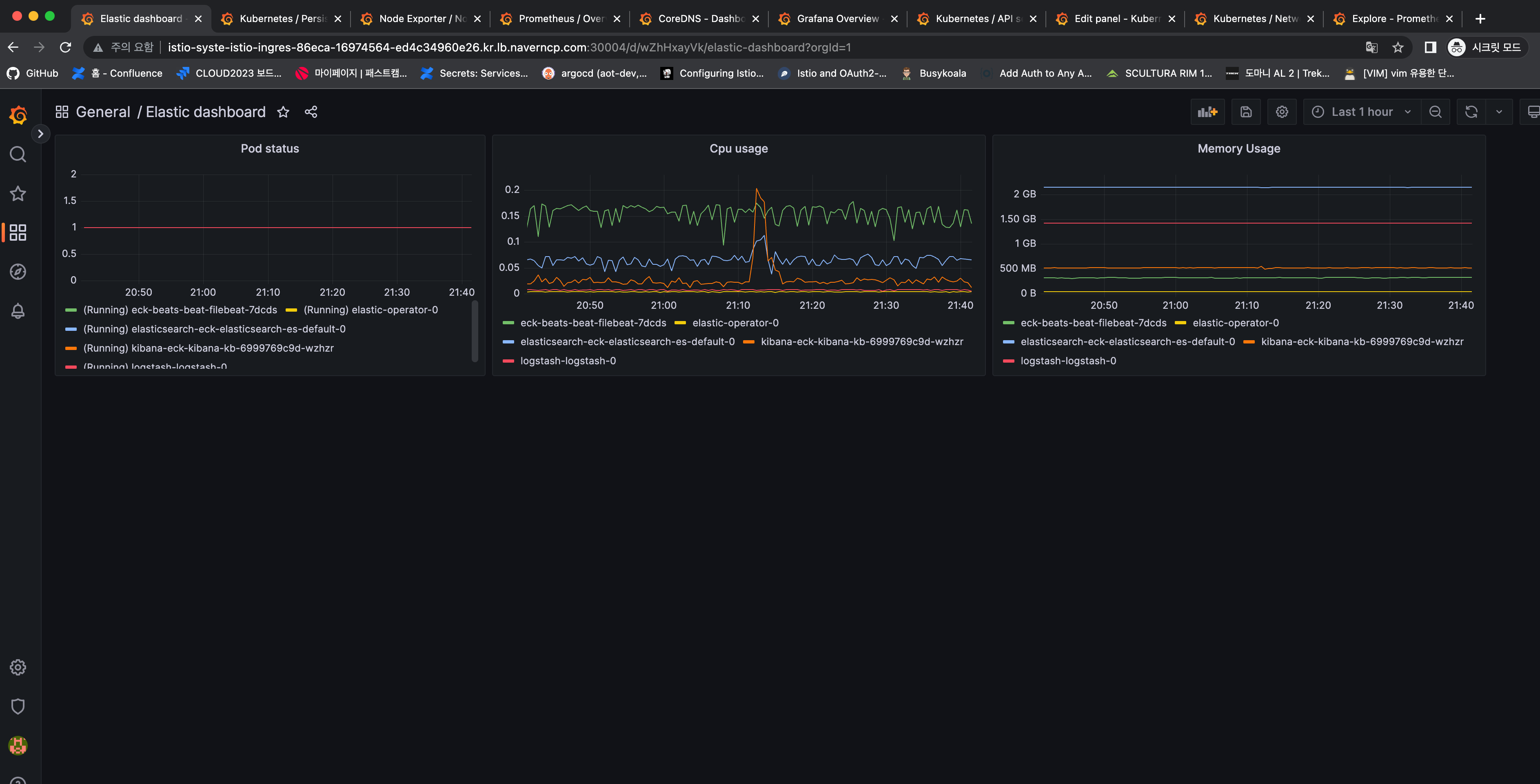
여기서는 grafana 를 통해 커스텀 Dashboard를 생성해보도록 하는 과제도 제공되었는데요. 개인적으로 누군가 해놓은 Dashboard 만 보거나, 그것 조차 보지 않으면서 작업을 해왔었는데..(반성합니다 ㅠ) 이제는 필요 한 경우 수집된 metric을 시각화하고, 그것을 alertmanager를 통해 notificate 하는 등의 작업도 할 수 있겠다는 자신감이 들었습니다.
그러면서 현재 사내에서 수집해야하는 metric 중 수집하지 않는 것들은 prometheus를 통해 더 scrape 하도록 하고, 시각화 해야하는 metric 들은 grafana dashboard 로 생성하고. 그것을 json 파일로 export 해서 관리하는 등의 작업을 해야겠다는 생각이 드는 섹터였습니다.
느끼는 점
이렇게 큰 4단원을 5주간 퇴근하고 틈틈이 (물론 많은 시간을 쓰진 못했습니다만..) 하면서 참 배운것도 많고, 내가 K8s eco system에 대해서 많이 모르고 작업해왔구나, 기본기가 많이 부족했구나를 다시 한 번 느끼는 계기가 되었습니다.
한 편으로는 이번 챌린지를 통해 앞으로 내가 무엇을 공부해야 할지 다짐하게 되는 계기도 된 것 같습니다.
Helm 더 이해하기, K8s 환경을 위한 VPC, LB, NAT 등 리소스의 관계나 Best Architecture 생각해보기, ELK 스택 더 파보기(ES Index가 정확히 무엇이고, Index Life Cycle은 어떻게 지정하는게 좋으며.. 등등), Prometheus, Grafana 를 더 효율적으로 사용할 방법이 무엇인지, Metric 수집을 못하는 서비스(자체 개발하였는데 Metric 수집 엔드포인트가 없다든지...)는 어떻게 Metric 수집을 할 수 있도록 바꿀것인지 등등..
모든걸 다 잘 하고 깊게 알 수는 없겠지만, 그래도 어떤 것들을 알아야 하는지 큰 그림을 그릴 수 있었던 챌린지였던것 같습니다.
가능하면 Numble의 다른 챌린지도 참여해보고 싶기도 합니다.
또, DevOps 엔지니어로서 커리어를 쌓아나가고 싶은 마음이 크기 때문에 부족한 기본기, CS지식, K8s 지식 등등을 채워서 호스트님같은 인사이트나, 개발능력을 갖고 싶고 궁극적으로는 그러한 호스트가 되어서 또 다른 사람들에게 나의 배움이나 지식을 전파하고 싶기도 합니다.
여러분들도 괜찮은 넘블 챌린지를 보셨다면 주저하지 말고 참여해보시길 바랍니다!
