해당 포스트는 python 3.8 version을 기준으로 작성하였습니다.
what is boxplot?
boxplot은 전체 데이터의 분포 정도를 박스 모양으로 표현한 그래프의 일종이다.
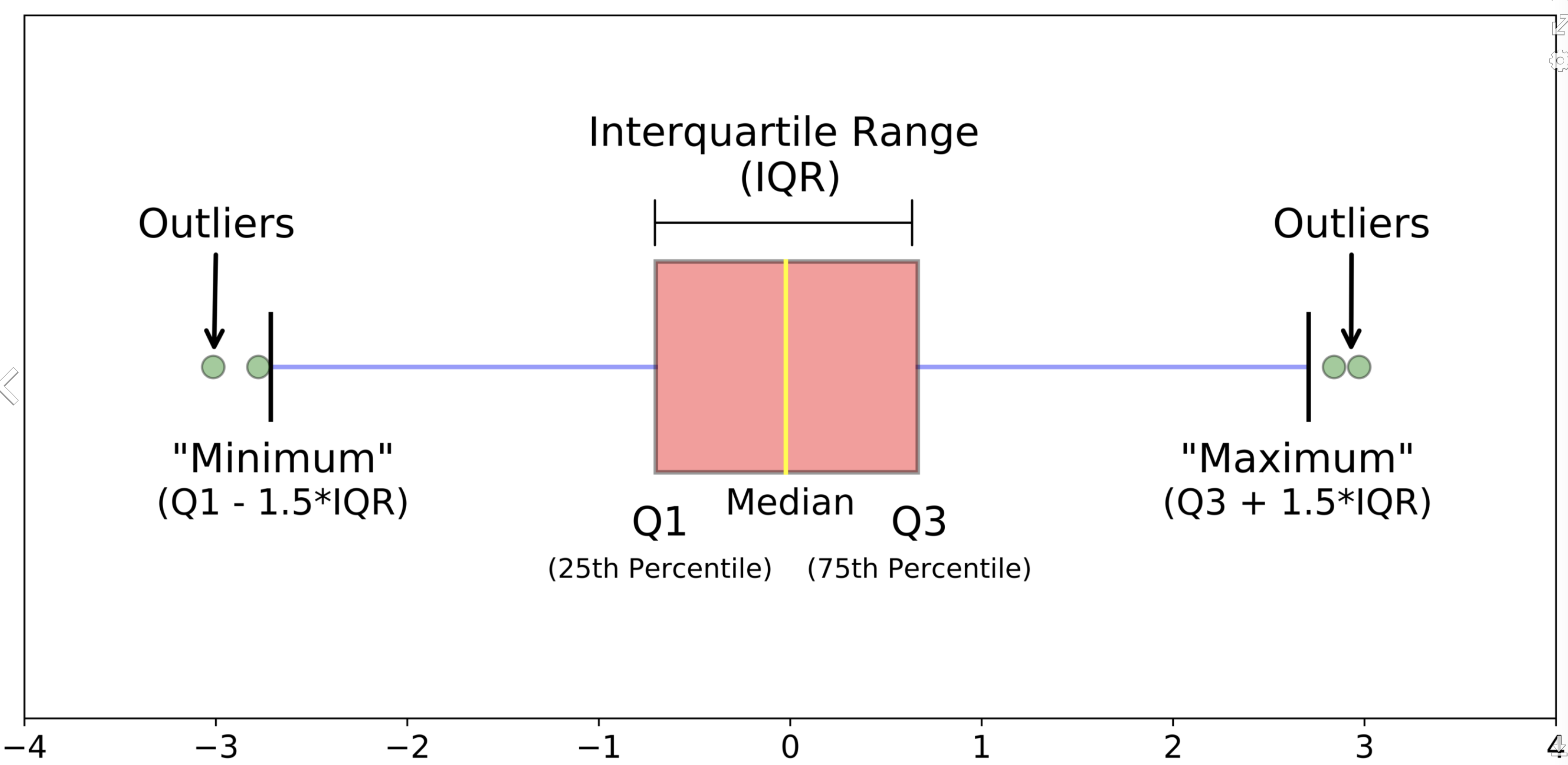
위 그림과 같이 생겼으며, 우리는 해당 데이터의 1분위수, 평균, 3분위수, 이상치, 최솟값, 최댓값 등을 손쉽게 알 수 있다.
자세한 내용은 위키에서 더 알 수 있다.
how to draw boxplot using python package?
데이터 분석가로서 데이터 분포도를 볼 때 박스플롯은 예삿일로 사용하게 된다.
특히 python을 이용해서 jupyter notebook을 통해 그려보는 사람이라면, matplotlib나 seaborn 혹은 plotly등 다양한 시각화 패키지를 통해서 많이 그려봤을 것이다.
보통 아래와 같은 구문을 이용한다. (필자는 seaborn의 색감이 좋아서 seaborn을 즐겨 사용한다.)
import matplotlib.pyplot as plt
import seaborn as sns
plt.figure(figsize=(20,5))
# y column's boxplot per x column
sns.boxplot(x = 'x column', y = 'y column', data = data)
plt.show()구문에서 알 수 있다시피, 해당 패키지는 raw 데이터 전체를 사용한다.
x축에 들어갈 컬럼을 넣고, y축으로 보여줄 컬럼을 넣는 방식이다. 해당 구문운 어떤 카테고리별로 보고 싶은 분포도가 있을 경우 사용한다.
하지만, 항상 분석가에게 raw 데이터가 주어지지는 않는다.
특히 개발 환경, 분석 환경에 따라 raw 데이터가 과하게 커서 데이터 load자체가 되지 않는 경우가 있다. 빅데이터 시대 아닌가..!
그렇다면 boxplot은 포기해야 할까?
how to draw boxplot only using mean, max, min...
위키를 보면 알 수 있다시피, boxplot은 raw 데이터 전체를 이용한 것이 아니라 데이터의 요약정보를 가지고 와서 보여주는 그래프이다.
이 말인 즉슨, 개발 환경 및 분석 환경으로 인해 raw 데이터를 전부를 load할 수 없을 때, 요약정보만을 불러와서 boxplot을 그릴 수 있다. 는 말이다.
방법은 다음과 같다.
1. raw데이터를 다룰 수 있는 환경에서 요약정보만 추출한다.
groupby하여서 해당 데이터의 min, max, median, mean, 제1분위수, 제 3분위수 등을 추출한다. 이렇게 큰 데이터의 요약정보는 아주 작은 크기의 csv파일로 저장이 가능해지고, 어디로든 load가 가능해진다.
2. 요약정보를 dictionray형태로 만든다.
해당 부분은 요약하는 과정에서 만들어도 되고, 작아진 요약정보를 load해서 사용해도 된다. 필자는 후자의 상황이었고, 아래와 같은 function을 정의해서 dictionary로 만들어주었다.
import numpy as np
def get_stats(data, x_value):
# 각 카테고리별로 데이터 불러서 사용
data_1 = data.query(f"x_column == '{x_value}'")
df = np.array(data_1) # array로 만들기
return {'med': df[0,4], 'q1': df[0,3], 'q3': df[0,5], 'whislo': df[0,1], 'whishi': df[0,2]}
# 해당 숫자는 numpy array형태에서의 위치로, 사용자마다 다를 수 있다.
stats_list = []
for x_value in data['x_column'].tolist():
stats_list.append(get_stats(data, x_value))참고로, whislo는 min값이고, whishi는 max값이다.
3. bxp 패키지 활용해서 그리기
fig, ax = plt.subplots(figsize=(20,5))
ax.bxp(stats_list, showfliers=False,)
ax.set_xticklabels(data['x_column'].tolist())
plt.show()해당 패키지를 활용하면 dictionary로 만들어진 요약정보를 자동으로 그려서 보여준다.
subplots를 해야 그림이 그려지니, 꼭 해당 구문이 있어야 한다.
