
Crawling
수많은 인터넷상의 데이터들을 수집하기 위한 작업.
python을 활용해서 내가 원하는 정보를 쉽게 크롤링 할 수가 있다.
일반적으로 beautifulsoup4 & selenium 과 같은 라이브러리가 쓰인다.
CSV 파일
엑셀과 비슷한 행렬 구조의 데이터를 저장하기 위한 포멧. 크롤링과 함께 따라다닌다.
1.환경설치
pip install beautifulsoup4 #뷰티풀숩
pip install selenium #셀레니움
pip install request # 웹사이트로 요청을 할 때 필요하기 때문에 설치가 필요하다.2.기본세팅
기본 적으로 아래와 같이 라이브러리 및 패키지들을 import 해주고,
csv파일로 저장 하겠다고 선언.
특히, 크롬을 통해 크롤링 할때는
driver = webdriver.Chrome(ChromeDriverManager().install())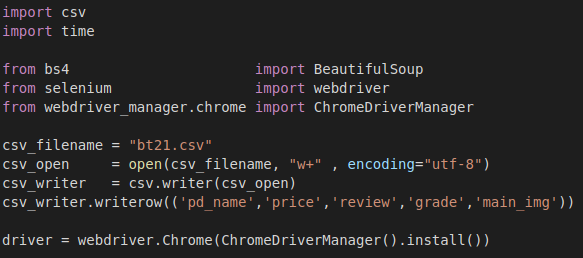
3.find & find_all
크롤링에서 가장 많이 사용하는 함수이다.
find는 가장 앞에 있는 한가지를, findall은 모두 다 찾아서 list 형태로 저장한다.
*선택자: select
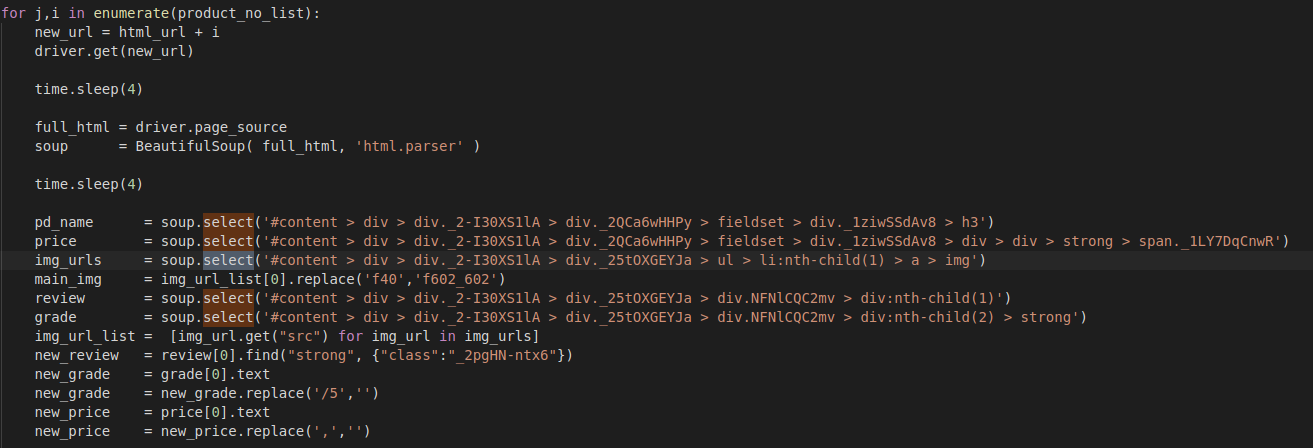
보통 위 사진과 같이 크롤링에서는 for문과 같이 많이 쓰이고, 특정 범위를 지정할 때 많이 쓰인다.

multi-national communicator with programming (back-end)