
※ Notification
본 포스팅은 작성자가 이해한 내용을 바탕으로 작성된 글이기 때문에 틀린 부분이 있을 수 있습니다.
잘못된 부분이 있다면 댓글로 알려주시면 수정하도록 하겠습니다 :)
Intro
오늘은 어제에 이어서 Kaggle의 다양한 의료 데이터셋으로 분류 프로젝트를 진행했다.
OpenCV vs ImageDataGenerator
 label별로 Directory가 잘 구성되어 있다고 하더라도 회사 내규나 기타 사정상 Tensorflow를 사용할 수 없을 수도 있다. 때문에 ImageDataGenerator만 사용하는 것이 아니라 OpenCV를 통해 라이브러리를 구현하는 것 모두 사용할 수 있는 유연함을 가져야 한다.
label별로 Directory가 잘 구성되어 있다고 하더라도 회사 내규나 기타 사정상 Tensorflow를 사용할 수 없을 수도 있다. 때문에 ImageDataGenerator만 사용하는 것이 아니라 OpenCV를 통해 라이브러리를 구현하는 것 모두 사용할 수 있는 유연함을 가져야 한다.
I/O process in Colab
Kaggle의 Dataset을 보다보면 항상 label별로 Directory가 구성되어있는 것은 아니다. 이런 경우 우리가 사용하기 편한 형식으로 데이터셋을 변경해주는 작업이 필요한데, 이 작업을 Colab과 같은 서버 환경에서 진행한다면 매우 비효율적이고 어쩌면 제대로 작업이 진행되지 않을 수도 있다.
서버는 File I/O 작업에 최적화 된 것이 아니기 때문에 서버 내에서 최대한 I/O 작업을 줄여야 한다. 때문에 주로 압축된 파일 형태로 데이터를 전송하게 된다.
그 이유는 파일을 전송할 때 하나의 session이 생성되는데 파일을 하나 보내면 session이 열리고 transaction이 발생하게 된다. 모든 작업을 끝낸 후 session이 닫히게 되는데 이 과정에서 세션을 항상 열어놔야 하므로 보안에도 좋지 않다.
파일을 여러 개 전송하는 경우에는 세션을 여러 개 열어야 하며, 소켓도 계속 열려 있어야 한다. 때문에 1개의 파일을 보내더라도 압축 형식의 파일로 보내는 것이 좋다.
서버의 기본은 세션을 최소한으로 유지하는 것이기 때문에.
 실제로 Colab에서 폴더를 압축 없이 업로드하려하면 이처럼 오류가 나게 된다.
실제로 Colab에서 폴더를 압축 없이 업로드하려하면 이처럼 오류가 나게 된다.
Medical, Safety dataset
Medical dataset
수업을 계속 의학 데이터로 진행하는데 그 이유를 간략히 설명해주셨다.
의학 데이터의 경우 접하기가 쉽지 않은데, 의학 데이터에는 개인정보들이 많이 담겨있기 때문에 상당히 민감하다. 때문에 데이터를 구하기 어려운 것이며 kaggle에 있는 데이터들을 통해 학습을 진행하고, 추후에 의학 관련 데이터 기업에도 한번 도전해보라고 하셨다.
Safety dataste
의학 데이터와 비슷하게 데이터가 거의 없는 분야가 있는데, 바로 안전 분야이다.
안전 사항은 기업이나 정권에 매우 중요한 사항이기 때문에 데이터에 있어서 더 민감하다.
예를 들어 각종 안전 데이터들을 통해 성수대교의 붕괴확률이 95%가 나왔다고 치면, 큰 혼란을 야기할 수도 있기 때문이다.
Kaggle
Brain tumor dataset에 이어서 다음 3개의 데이터로 프로젝트를 진행해봤다.
- chest X-Ray Images(Pneumonia)
https://www.kaggle.com/datasets/paultimothymooney/chest-xray-pneumonia - Blood cell Images
https://www.kaggle.com/datasets/paultimothymooney/blood-cells - COVID-19
https://www.kaggle.com/datasets/tawsifurrahman/covid19-radiography-database
데이터를 프로젝트에 사용하기 편리하게 만드는 것을 중점으로 프로젝트를 진행했다.
Chest X-Ray Images(Pnumonia)
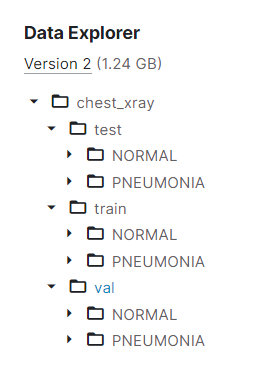 Chest X-Ray dataset의 경우 train, test, validation에 대해 label별로 디렉토리가 구성되어 있어 별도의 처리 없이 사용할 수 있었다.
Chest X-Ray dataset의 경우 train, test, validation에 대해 label별로 디렉토리가 구성되어 있어 별도의 처리 없이 사용할 수 있었다.
 하지만 validation data가 거의 없다시피하고 train과 test data 또한 충분히 많지 않았다.
하지만 validation data가 거의 없다시피하고 train과 test data 또한 충분히 많지 않았다.
때문에 전이학습을 진행했으며, train과 test만으로 모델을 돌려봤을 때 train accuracy는 96%가량 나오는 반편 test accuracy는 78%를 보였다.
이를 통해 train data와 test data가 이질적이라는 것을 알 수 있었고, train과 test의 데이터를 섞어주어 이질적인 부분을 완화시켜주었다.
(모델 결과 추가 예정)
Blood cell Images
 Blood cell dataset의 경우 dataset-master와 dataset2-maset를 포함하고 있는데, 네모친 부분을 보면 알 수 있듯이 dataset-master는 Segmentaion을 위한 데이터셋이고, dataset2-master는 우리가 원하는 분류를 위한 데이터셋이다.
Blood cell dataset의 경우 dataset-master와 dataset2-maset를 포함하고 있는데, 네모친 부분을 보면 알 수 있듯이 dataset-master는 Segmentaion을 위한 데이터셋이고, dataset2-master는 우리가 원하는 분류를 위한 데이터셋이다.
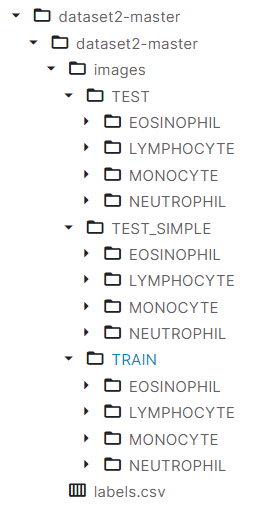 dataset2-master의 경우 다음과 같은 구조를 가지고 있다. Chest X-Ray dataset에서는 하위 폴더가 train, test, val이었지만 Blood cell dataset의 경우 images라는 하위 디렉토리가 존재하고, 이를 처리해줘야 한다.
dataset2-master의 경우 다음과 같은 구조를 가지고 있다. Chest X-Ray dataset에서는 하위 폴더가 train, test, val이었지만 Blood cell dataset의 경우 images라는 하위 디렉토리가 존재하고, 이를 처리해줘야 한다.
이런 전처리 작업은 어디에서 하나 상관없지만 개인 PC에서 재압축하는 것이 편하고 좋을 것 같다.
 이렇게 만들어진 데이터셋을 통해 프로젝트를 진행했는데 test simple의 개수는 너무 적어 train과 test만 사용해 모델을 학습했다.
이렇게 만들어진 데이터셋을 통해 프로젝트를 진행했는데 test simple의 개수는 너무 적어 train과 test만 사용해 모델을 학습했다.
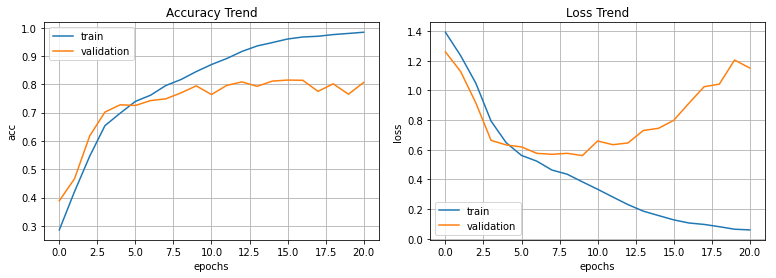 하지만 역시나 두 데이터간의 이질성이 확인되었고 먼저 test simple을 test에 편입시켜 다시 학습을 진행해봤다.
하지만 역시나 두 데이터간의 이질성이 확인되었고 먼저 test simple을 test에 편입시켜 다시 학습을 진행해봤다.
그 결과 큰 변화가 없었고, 이번에는 모든 데이터를 합쳐서 섞은 다음 8:2의 비율로 train과 test로 분할해서 학습을 진행해봤다.
(결과 추가 예정)
COVID-19 Radiography Database
 마지막으로 COVID-19 Data를 통해 프로젝트를 진행했는데 Usability가 무려 10이다. Usability는 이름 그대로 데이터의 사용성을 이야기 하며, 그만큼 전세계에서 COVID-19에 대해서 관심을 가지고 있다고 생각해볼 수 있다.
마지막으로 COVID-19 Data를 통해 프로젝트를 진행했는데 Usability가 무려 10이다. Usability는 이름 그대로 데이터의 사용성을 이야기 하며, 그만큼 전세계에서 COVID-19에 대해서 관심을 가지고 있다고 생각해볼 수 있다.
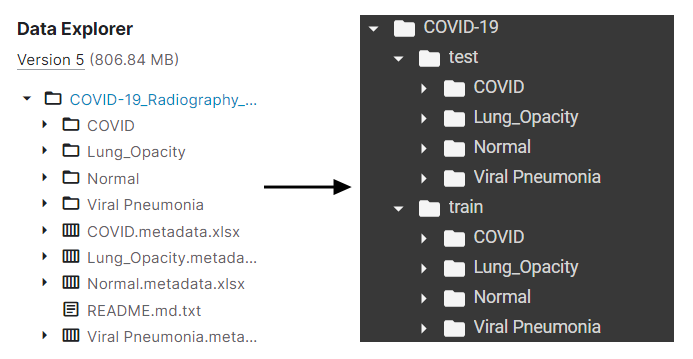 COVID-19 Dataset의 경우 label directory 뿐만 아니라 다른 잡다한 파일들도 함께 있는데, 이러한 파일들 또한 적절히 처리해주어야 한다.
COVID-19 Dataset의 경우 label directory 뿐만 아니라 다른 잡다한 파일들도 함께 있는데, 이러한 파일들 또한 적절히 처리해주어야 한다.
이를 위해 먼저 COVID-19 directory와 train, test 하위 디렉토리를 만들어주고 train directory 안으로 label directory들을 옮겨주었다. 그 후 8:2의 비율로 test 데이터를 shuffle하여 분리해줬다.
번거롭게 합치고 다시 나누는 과정을 하지 않아서 더 편리한 느낌도 들었다.
간단히 돌려봤을 때 정확도 역시 train 81%, test 85%로 크게 차이나지 않았다.
하이퍼파라미터 조정을 통해 90% 이상의 모델 성능도 기대할 수 있을 것으로 예상된다.
글을 작성하는 동안 몇 가지를 수정하여 모델을 돌려놨는데 글을 다 작성하고 나니 다 돌아가 있었다.
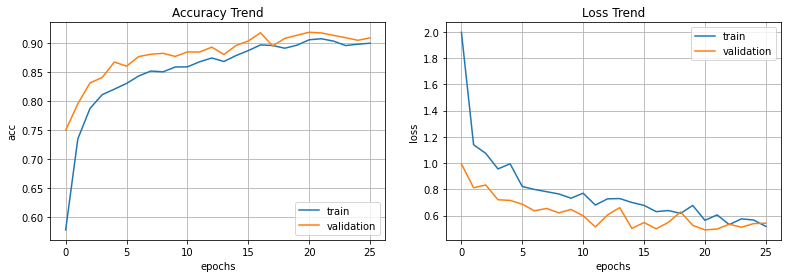
그 결과는 예상과 같이 train accuracy 93%, test accuracy 91%로 둘 다 90%가 넘는 정확도를 보여줬다. 또한 그래프를 보면 overfitting도 크게 일어나지 않았다.
다만 그래프가 다소 부드럽지 못하게 나와줬는데 learning rate의 조절으로 좀 더 smooth한 결과를 얻을 수 있을 것 같다.
Outro
프로젝트를 진행하면서 그동안 배웠던 내용들을 하나하나 정리해나가고 있다.
평소에는 별 생각 없이 남들이 다 쓰니까~ 하면서 클론 코딩 식으로 진행했다면 이제는 하나하나 이유를 생각해가면서 프로젝트를 진행하는 느낌이 들었다.
