
Intro
분석을 친구가 진행하고 그동안 나는 ML 모델이 완성되면 이를 배포할 수 있는 방법을 찾기로 했다.
이를 위해서 간단한 Python API를 개발했다. 우선은 로컬에서 코드를 작성하고 서버를 띄워서 동작을 확인해보자.
FastAPI를 활용한 API 개발과 함께, 배포의 효율성과 이식성을 고려하여 컨테이너 기반 가상화 도구인 Docker를 사용했다.
Verse
FastAPI
FastAPI를 이용해 간단한 애플리케이션을 제작해보자.
# main.py
from fastapi import FastAPI
app = FastAPI()
@app.get("/")
async def read_root():
return {"message": "Hello, FastAPI!"}
@app.get("/health")
async def healthcheck():
return {"status": "healthy"}
if __name__ == "__main__":
import uvicorn
uvicorn.run(app, host="0.0.0.0", port=8000)if __name__ == "__main__" 코드를 통해 main.py가 직접 실행될 때 uvicorn을 사용하여 FastAPI 애플리케이션을 구동한다.
Dockerize
이렇게 작성된 FastAPI 애플리케이션을 Docker 컨테이너로 패키징하기 위해 아래와 같이 Dockerfile을 작성해주자.
# Dockerfile
FROM python:3.10 # python 3.10 버전 이미지를 base로 사용
WORKDIR /app # 컨테이너 내에서의 작업 디렉토리를 /app으로 설정
COPY . /app # 호스트의 현재 디렉토리(.)를 /app에 복사
RUN pip install -r requirements.txt # requirements.txt에 명시된 패키지들을 설치
CMD [ "python", "main.py" ] # 컨테이너가 시작될 때 main.py를 실행하여 FastAPI 애플리케이션을 구동Python은 3.10 버전을 사용하였고, requirements를 통해 필요한 패키지를 설치한다.
requirements.txt에는 우선 fastapi와 uvicorn만을 사용하므로 두 패키지를 명시해준다.
이후 필요에 따라 패키지를 추가하고, 패키지의 버전을 명시해주는 것이 좋다.
현재 단계에서는 패키지의 버전은 따로 명시하지 않겠다.
# requirements.txt
fastapi
uvicornLocal test
Dockerfile, main.py, requirements.txt 파일이 모두 준비됐으면 local에서 FastAPI 서버가 잘 띄워지는지 확인해보자.
터미널에서 아래 명령을 통해 FastAPI 서버를 띄워보자.
docker build -t fastapi-img .먼저 이미지를 빌드해주고, 해당 이미지로 컨테이너를 실행하자.
테스트에만 사용하고 컨테이너를 재사용하지 않을 것이기 때문에 --rm 옵션을 통해 컨테이너가 종료되면 자동으로 삭제되게 해주자. (매번 지워주기 은근 귀찮다.)
docker run -it -p 8000:8000 --rm --name FastAPI-container fastapi-img명령 실행 후 아래와 같은 로그가 출력된다면 정상적으로 FastAPI 서버가 띄워진 것이다.
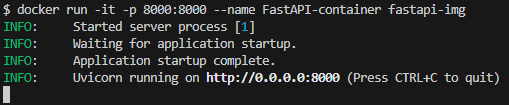
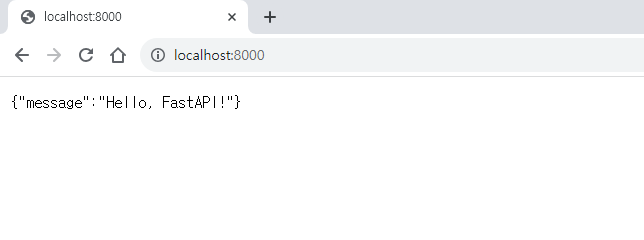
웹 브라우저를 통해 정상 접근을 확인해보자.
아래와 같은 화면을 만날 수 있을 것이다.
Outro
이제 위 내용을 바탕으로 로컬이 아닌 클라우드에 API 서버를 배포해보자.
