
※ Notification
본 포스팅은 작성자가 이해한 내용을 바탕으로 작성된 글이기 때문에 틀린 부분이 있을 수 있습니다.
잘못된 부분이 있다면 댓글로 알려주시면 수정하도록 하겠습니다 :)
Intro
오늘부터 본격적인 코딩에 들어갔다.
TensorFlow(이하 TF)를 이용해 모델을 구축하고 학습, 평가하는 법을 배웠고, 이항 분류와 다항 분류의 차이를 학습하였다.
강의에서는 TF와 Keras를 혼용해서 사용하지만 두 가지가 동일하다고 봐도 무방하다고 하셔서 본 포스팅에서는 TF로 통일하겠다.
optimizer
Optimization은 손실 함수(loss function)의 결과를 최소화하는 모델의 파라미터(가중치)를 찾는 것을 의미하며, Opmitization의 알고리즘을 Optimizer라고 한다.
TF modeling
 TF에서는 model을 통해 Box(틀)를 생성하고 layer를 통해 각각의 층을 구현한다.
TF에서는 model을 통해 Box(틀)를 생성하고 layer를 통해 각각의 층을 구현한다.
Model은 다음 3가지 방법으로 구현한다.
- Sequential
- Functional API
- Subclassing
Sequential
# Sequential API sample code
model = Sequential() # 모델 생성
model.add(Flatten(input_shape=(1,))) # 입력층
# Hidden layer
model.add(Dense(1, activation='linear')) # 출력층
# model.add(Dense(1, input_shape=(1,), activation='linear'))
# 입력층을 다음과 같이 한줄로 줄일 수도 있음Model의 80%가 Sequential을 이용해 만들어진다.
아마도 직관적이고 단순하기 때문이 아닐까 싶다.
Functional API
# Functional API sample code
input_ = Input(shape=(1,)) # 입력층
# Hidden layer
output_ = Dense(1, activation='linear')(input_) # 출력층
model = Model(inputs=input_, outputs=output_) # 모델 생성 및 layer connectionoutput_ = Dense(1, activation='linear')(input_)
코드를 보면 일반적으로 함수를 호출해서 사용하는 것과 유사하게 생겼다. 때문에 Functional이라고 불린다.
20% 정도 비중을 차지하고 있고, 주로 Segmentation 분야에서 사용된다.
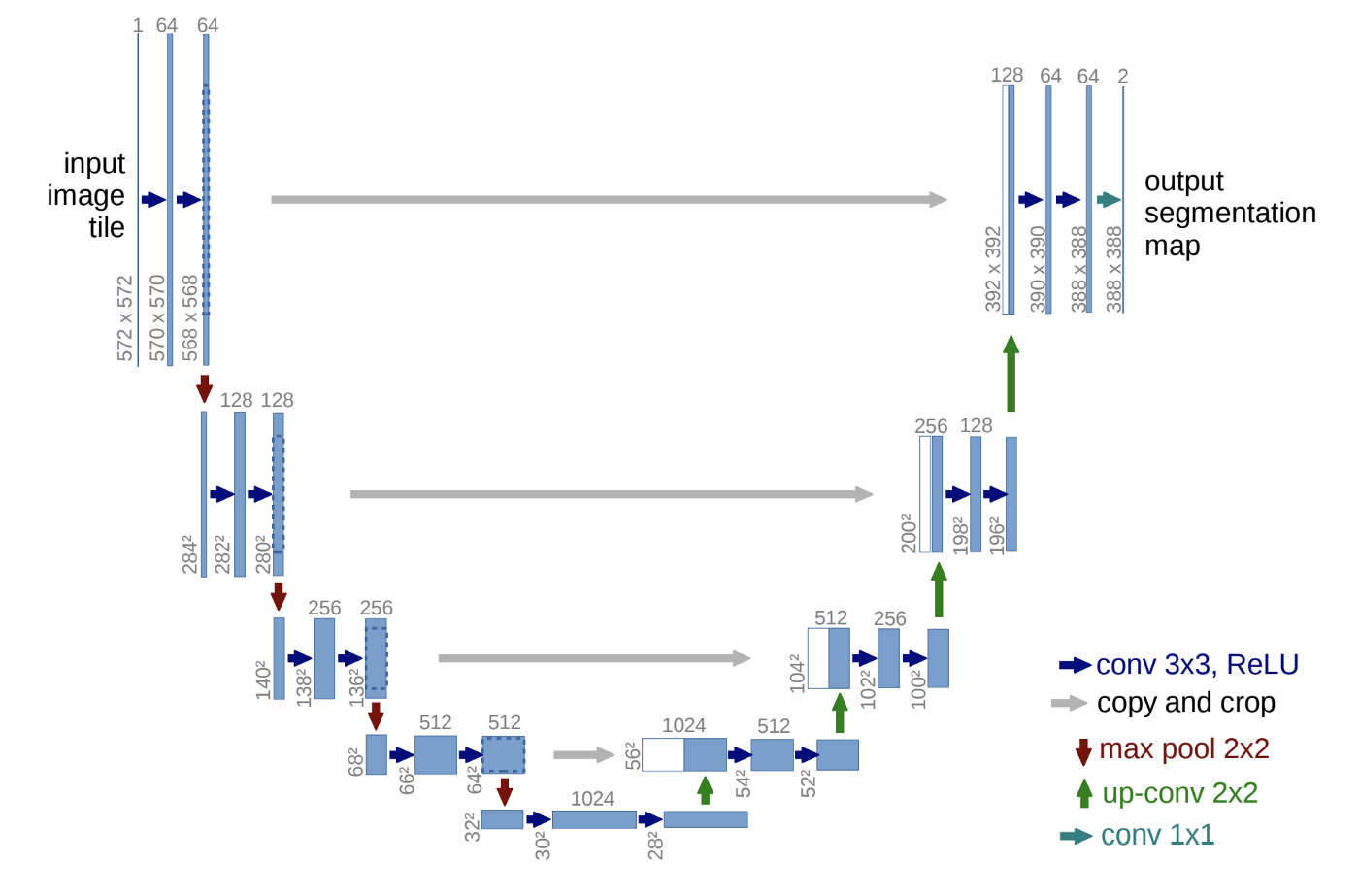 예시로 U-Net에서 업샘플링 할 때 이전 layer를 concatenate 해주게 되는데(사진에서 copy and crop 부분) 이를 위해 Functional API를 사용한다.
예시로 U-Net에서 업샘플링 할 때 이전 layer를 concatenate 해주게 되는데(사진에서 copy and crop 부분) 이를 위해 Functional API를 사용한다.
Subclassing
Subclassing은 잘 사용되지 않는다고 한다.
이전에 TF Tutorial을 공부할 때 작성했던 코드의 일부를 가져와봤다.
배울 때도 그랬지만 확실히 다른 API에 비해서 복잡한 것 같다.
class CNNBlock(layers.Layer):
def __init__(self, out_channels, kernel_size=3):
super(CNNBlock, self).__init__()
self.conv = layers.Conv2D(out_channels, kernel_size, padding='same')
self.bn = layers.BatchNormalization()
def call(self, input_tensor, training=False):
x = self.conv(input_tensor)
x = self.bn(x, training=training)
x = tf.nn.relu(x)
return xloss function & activation function
데이터에 형태에 따라서 사용하는 loss function과 activation function이 다른데, 한번 정리하면 좋을 것 같아서 정리해보았다.
물론 MSE, MAE, tanh 등 다양한 loss function과 activation function이 존재하지만 이해를 위해 대표적으로 한 개씩만 적어보았다.
| 실수 | 이항 분류 | 다항분류 | 다항분류 One hot encoding | |
|---|---|---|---|---|
| Loss function | MSE | Binary Cross Entropy | Sparse Cross Entropy | Categorical Cross Entropy |
| Activation function | Linear | Sigmoid | Softmax | Softmax |
이항분류 & 다항분류
이항분류와 다항분류에 대해서 좀 더 자세히 비교해보면 다음과 같다.
| 이항분류 | 다항분류 | |
|---|---|---|
| 정답의 개수 | 2개 | 2개 이상 |
| 출력 노드 개수 | 1개 | 정답의 개수 |
| Activation function | Sigmoid | Softmax |
| loss function | Binary Cross Entropy | Categorical Cross Entropy (One hot O) Sparse Cross Entropy (One hot x) |
❔ 다항분류의 경우 정답이 2개 이상인 경우인데, 그렇다면 정답이 2개일 경우에는 이항분류와 다항분류 중에서 어떤 것을 써야할까?
✔ 이 경우에는 혼란을 방지하기 위해 이항분류를 사용한다.
Softmax
결과를 확률 분포로 알고싶을 때 Softmax를 사용한다.
각각의 결과가 나올 가능성을 확인할 수 있어 각각의 확률을 보고 왜 결과가 그렇게 나왔는지 역추적이 가능하다.
이를 이용한 분야가 eXplainable Artificial Intelligence(XAI)이다.
XAI가 아니더라도 A, B, C에 대해 10%, 20%, 70%의 결과가 나왔다면 B가 20% 확률이 나온 이유를 살펴보면서 모델을 수정할 수 있고, 이러한 과정을 통해 성능을 향상시킬 수도 있을 것 같다.
선형 & 비선형
선형
linear라는 것은?
데이터가 임의의 직선 근처에 있다는 것이다.
선형회귀에서 Acc?
정답 1인데 예측값이 0.000009이다.
정확하다고 할 수 있는가?
linear regression에서는 근사치를 사용한다. 따라서 Accuracy를 사용하지 않는다.
하지만 분류(Classification)에서는 정답이 있으니 정확도를 판별할 수 있으므로 Accuracy를 사용한다.
비선형
딥러닝에서는 Activation function을 통해 비선형성을 추가시켜준다.
때문에 수학적으론 복잡해지지만 데이터를 좀 더 자세히 설명할 수 있다.
신경망은 비선형성을 계속 추가해서 데이터를 좀 더 정교하게 맞출 수 있게 하는 것. 즉, 비선형 방정식을 푸는 것이다.
Note
따로 빼서 작성하긴 애매하고 개인적으로 기억하고 싶은 것들을 남겨두는 곳
- 함수의 return 값과 type은 습관적으로 확인!
- predict의 출력은 (input 개수, 출력층 노드 수)
- model.fit()의 batch_size의 Default는 32이다.
Outro
코드 수업이 진행되어 포스팅할 내용이 별로 없을 줄 알았는데, 개념을 알려주고 이를 이해하는 차원에서 코딩을 진행한다고 하셔서 내용이 부족할 일은 없을 것 같다.
