
※ Notification
본 포스팅은 작성자가 이해한 내용을 바탕으로 작성된 글이기 때문에 틀린 부분이 있을 수 있습니다.
잘못된 부분이 있다면 댓글로 알려주시면 수정하도록 하겠습니다 :)
Intro
오늘은 MNIST dataset을 이용해 layer에서의 feature map을 시각화하고, feature map에 대해 이해하는 시간을 가졌다.
또한, CIFAR10 dataset를 이용해 Model의 Architecture를 다양하게 변경해보면서 overfitting이 일어나지 않는 적절한 Model을 구성하는 연습을 했다.
Feature map
다음과 같은 Architecture를 가지는 Model을 구현하고, 첫 번째 Conv2D layer의 학습 전과 후 Feature map을 확인해봤다.
Model: "sequential_1"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d_3 (Conv2D) (None, 28, 28, 32) 320
max_pooling2d_3 (MaxPooling (None, 14, 14, 32) 0
2D)
dropout_3 (Dropout) (None, 14, 14, 32) 0
conv2d_4 (Conv2D) (None, 14, 14, 64) 18496
max_pooling2d_4 (MaxPooling (None, 7, 7, 64) 0
2D)
dropout_4 (Dropout) (None, 7, 7, 64) 0
conv2d_5 (Conv2D) (None, 7, 7, 128) 73856
max_pooling2d_5 (MaxPooling (None, 4, 4, 128) 0
2D)
dropout_5 (Dropout) (None, 4, 4, 128) 0
flatten_1 (Flatten) (None, 2048) 0
dense_1 (Dense) (None, 10) 20490
=================================================================
Total params: 113,162
Trainable params: 113,162
Non-trainable params: 0
_________________________________________________________________학습 전
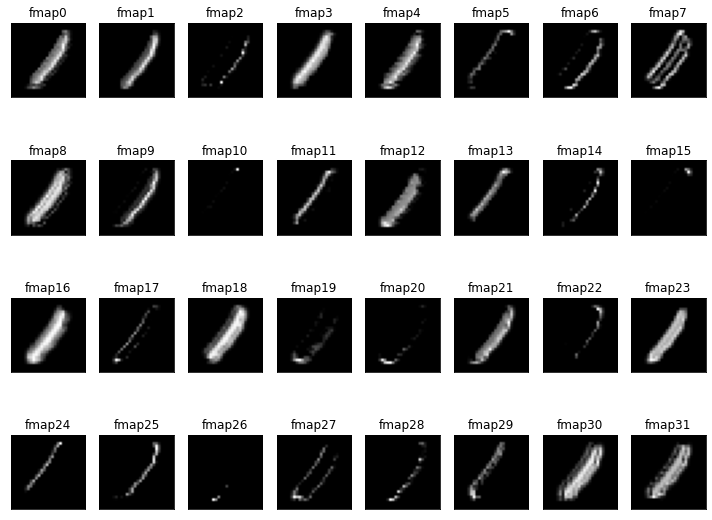
학습 후
 좀 더 비교하기 쉽도록 하나의 Feature map만 골라봤다.
좀 더 비교하기 쉽도록 하나의 Feature map만 골라봤다.
 왼쪽이 학습 전, 오른쪽이 학습 후 Feature map이다. 위 사진으로 봐서 위 Filter는 대각선을 인식하는 Fliter이지 않을까 생각된다.
왼쪽이 학습 전, 오른쪽이 학습 후 Feature map이다. 위 사진으로 봐서 위 Filter는 대각선을 인식하는 Fliter이지 않을까 생각된다.
이처럼 학습을 통해 Filter들의 Weight를 학습한다.
Model에서 원하는 layer의 Feature map을 선택하는 코드는 의외로 간단하다.
partial_model = Model(inputs=model.inputs, outputs=model.layers[0].output)위와 같이 Model의 일부분을 떼어내어 새로운 작은 Model을 만들어 그 결과를 확인하는 방식이다.
전체 Model architecture에서 첫 번째 layer가 Conv2D이기 때문에 layer[0]을 선택해주었다.
Model: "model_10"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d_3_input (InputLayer) [(None, 28, 28, 1)] 0
conv2d_3 (Conv2D) (None, 28, 28, 32) 320
=================================================================
Total params: 320
Trainable params: 320
Non-trainable params: 0
_________________________________________________________________위 코드로 만들어진 Model은 다음과 같으며, 다른 layer의 featrue map을 확인하고 싶다면, outputs 부분을 변경하면 된다.
CIFAR10
CIFAR10은 MNIST와 더불어 많이 사용되는 dataset일 것이다.
다음과 같이 10가지의 Class로 구성되어 있으며, 60,000개의 컬러 이미지이다.

MNIST에서 사용했던 Model을 기반으로 다음과 같은 Model을 만들어 CIFAR10 데이터로 학습했다.
Conv2D - Conv2D - MaxPool - Dropout
Flatten - Dense - Dropout - Dense
cnn = Sequential()
cnn.add(Conv2D(32,(3,3),activation='relu',padding='same',input_shape=(32,32,3)))
cnn.add(Conv2D(32,(3,3),activation='relu',padding='same',input_shape=(32,32,3)))
cnn.add(MaxPool2D(pool_size=(2,2)))
cnn.add(Dropout(0.25))
cnn.add(Conv2D(64,(3,3),activation='relu',padding='same'))
cnn.add(Conv2D(64,(3,3),activation='relu',padding='same'))
cnn.add(MaxPool2D(pool_size=(2,2)))
cnn.add(Dropout(0.25))
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d (Conv2D) (None, 32, 32, 32) 896
conv2d_1 (Conv2D) (None, 32, 32, 32) 9248
max_pooling2d (MaxPooling2D (None, 16, 16, 32) 0
)
dropout (Dropout) (None, 16, 16, 32) 0
conv2d_2 (Conv2D) (None, 16, 16, 64) 18496
conv2d_3 (Conv2D) (None, 16, 16, 64) 36928
max_pooling2d_1 (MaxPooling (None, 8, 8, 64) 0
2D)
dropout_1 (Dropout) (None, 8, 8, 64) 0
conv2d_4 (Conv2D) (None, 8, 8, 64) 36928
conv2d_5 (Conv2D) (None, 8, 8, 64) 36928
max_pooling2d_2 (MaxPooling (None, 4, 4, 64) 0
2D)
dropout_2 (Dropout) (None, 4, 4, 64) 0
flatten (Flatten) (None, 1024) 0
dense (Dense) (None, 128) 131200
dropout_3 (Dropout) (None, 128) 0
dense_1 (Dense) (None, 10) 1290
=================================================================
Total params: 271,914
Trainable params: 271,914
Non-trainable params: 0
_________________________________________________________________정확도 85%까지 뽑을 수 있으면 해보라고 하셨는데 아무리 해도 82%가 최대였다.
좋은 Model을 만들기 위해서는 많이 해보는 수 밖에 없다고 하셨다.
Model의 성능을 올리기 위해 해야할 순서도 알려주셨는데, 첫 번째가 데이터를 더 확보하는 것이고 두 번째가 Model의 Architecture를 바꾸는 일이라고 하셨다.
항상 강조하시는 것이 Simple is best인데 간단하게 만들면 성능이 잘 안나오더라.....
이 또한 많이 해봐야 느는 것이겠지 싶다.
Note
- Model의 성능을 올리기 위해서는?
1. 더 많은 데이터를 사용
2. Model의 Architecture를 변경
Outro
리뷰 진행하실 때 빨리빨리 진행하신다고 하시면서 하셔서 코딩할 때 이해할 충분할 시간이 있을까 걱정했는데 하나를 알더라도 확실하게 알고 가야한다고 하시면서 시간도 넉넉하게 주셔서 걱정할 필요는 없는 것 같다.
