
그래프 탐색
그래프 탐색은 깊이 우선 탐색(DFS)와 너비 우선 탐색(BFS) 두 방식이 널리 쓰인다. 두 개의 탐색 방식은 이름 그대로 그래프의 깊이를 우선하여 탐색하는 방식이며, 너비 우선 탐색 또한 너비를 우선하여 탐색하는 방식이다. (너무 이거는 이거다 식이지만 사실이 그렇다...)
두 개의 방식 모두 어떤 정점을 방문했는지 기록할 방법이 필요하다. 그렇지 않으면 무한 루프에 빠질 가능성이 높다.
그래프 - 인접 리스트
다음은 자바로 구현한 인접 리스트이다. 깊이 우선 탐색과 너비 우선 탐색 메서드 모두 해당 클래스에 추가할 것이다.
public class Vertex {
private String value;
private List<Vertex> adjacentVertices;
public Vertex(String value){
this.value = value;
this.adjacentVertices = new ArrayList<>();
}
public String getValue(){return value;}
public List<Vertex> getAdjacentVertices(){return adjacentVertices;}
// 정점 추가
public void addAdjacentVertex( Vertex vertex ){
if( vertex.getAdjacentVertices().contains( vertex ) ) return;
adjacentVertices.add(vertex);
vertex.addAdjacentVertex(this);
}
}깊이 우선 탐색
깊이 우선 탐색(DFS;Depth-First-Search)부터 알아보자. 깊이 우선 탐색은 해시 맵을 사용하며, 어떤 정점이 해시 맵에 존재하면 이미 방문했다는 뜻이다.
깊이 우선 탐색은 아래의 단계로 동작한다.
- 그래프 내 임의의 정점에서 시작한다.
- 현재 정점을 해시 맵에 추가해 방문했던 정점임을 표시한다.
- 현재 정점의 인접 정점을 순회한다.
- 방문했던 인접 정점이면 무시한다.
- 방문하지 않았던 인접 정점이면 그 정점에 대해 깊이 우선 탐색을 수행한다.
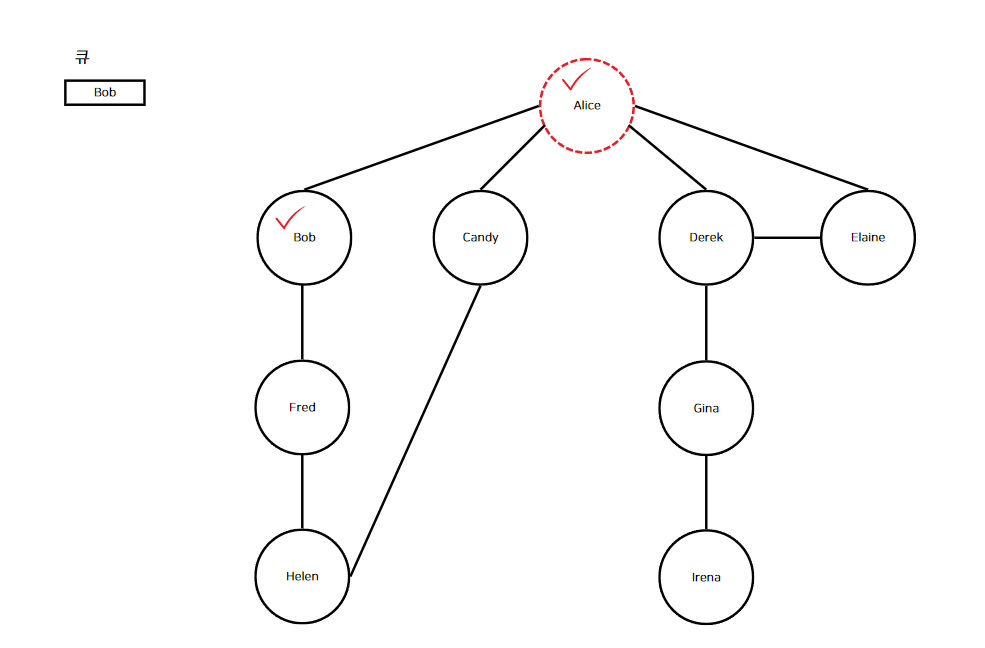
아래 이미지로 이해해보자. 빨간색 점선으로 표시된 정점이 현재 정점이며, 체크 부호는 해시 맵에 등록된 정점이라는 표시이다.
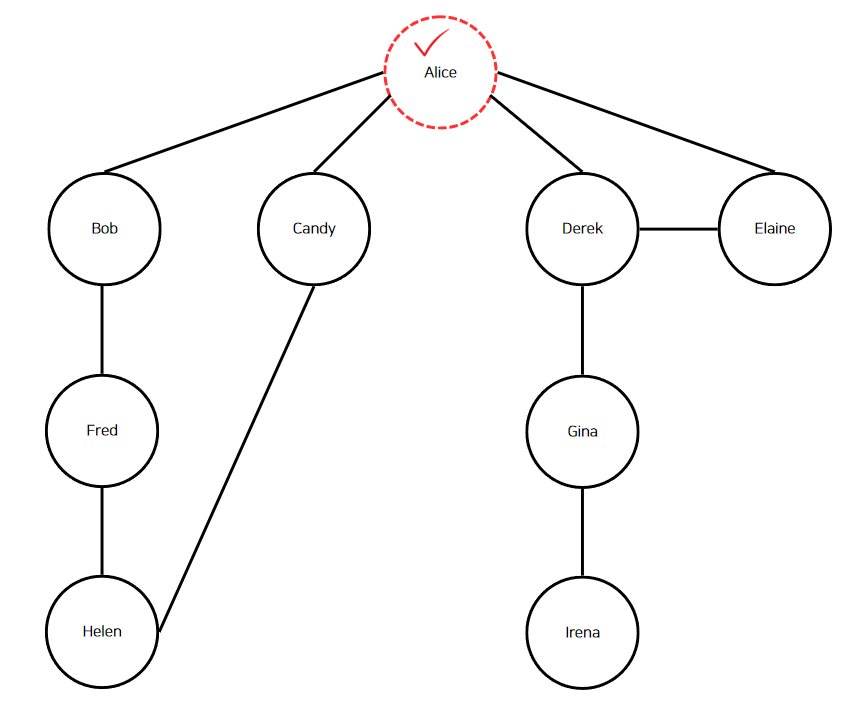
앨리스의 친구를 순회한다. 친구는 위의 이미지와 같이 "Bob", "Candy", "Derek", "Elaine"이다. "Bob"부터 깊이 우선 탐색을 수행한다. 여기서 주의할 점은 재귀가 사용된다는 점이다. "Bob"에 대해 깊이 우선 탐색을 수행한다고 하였지만, 아직 "Alice"는 호출스택에 남아있으며 "Alice"의 친구는 "Candy", "Derek", "Elaine"가 남아있다. 다시 "Bob"으로 돌아가서 순회를 계속해보자.
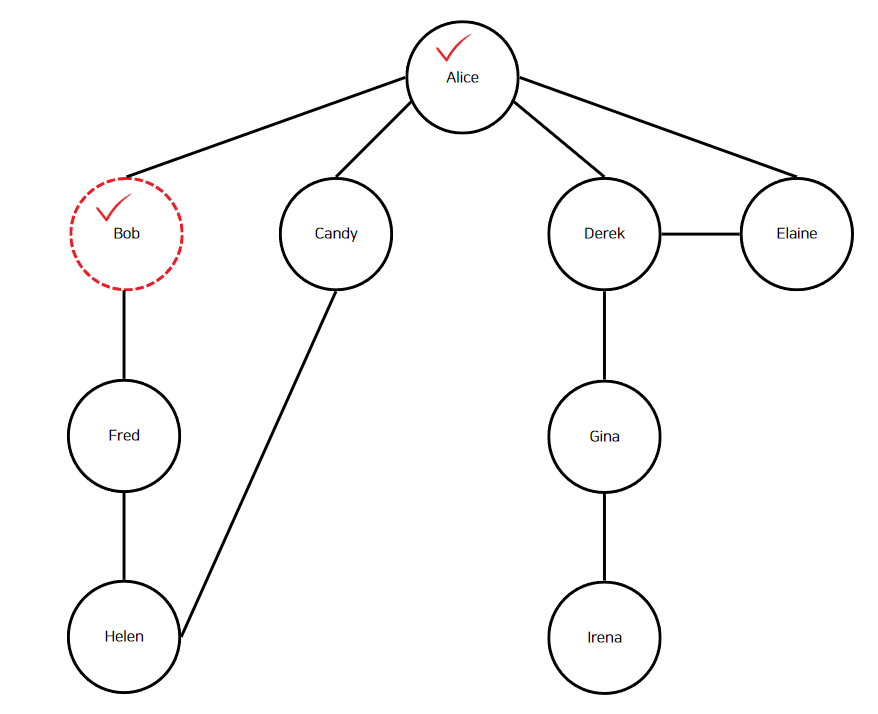
"Bob"이 현재 정점이 되고, 해시 맵에 "Bob" 정점이 등록된다. 이어서 "Bob"의 인접 정점인 "Alice"와 "Fred"를 순회한다.
"Alice"는 이미 방문했으니 무시한다. "Fred"에 대해서 깊이 우선 탐색을 수행한다.
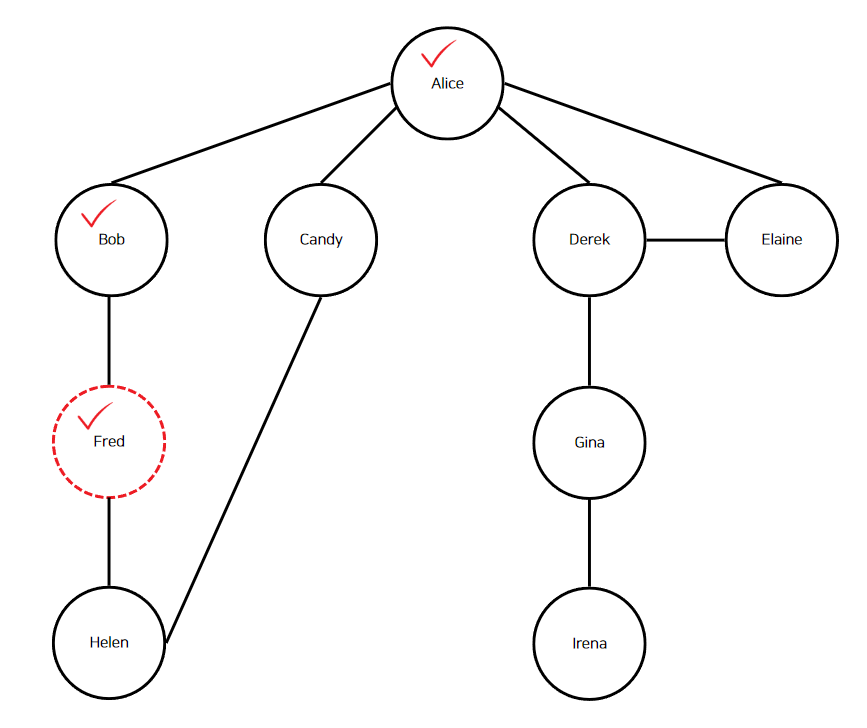
"Fred"는 현재 정점이 되고, 해시 맵에 "Fred" 정점이 등록된다. 이어서 "Fred"의 인접 정점인 "Bob"과 "Helen"을 순회한다.
마찬가지로 "Bob"은 방금 전에 방문했으니 "Bob"은 무시한다.
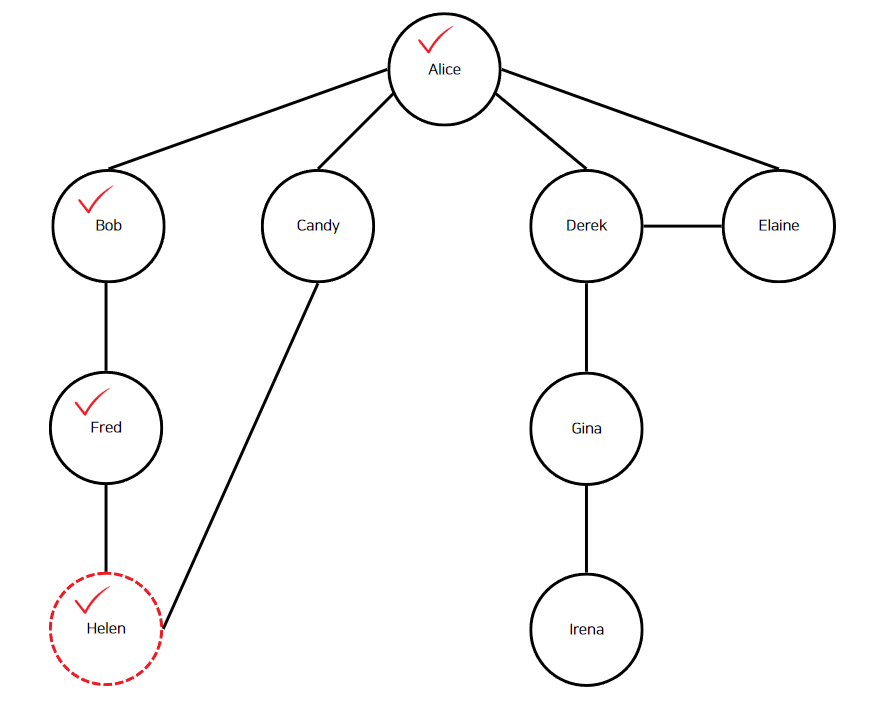
"Helen"은 현재 정점이므로 해시 맵에 등록한다. "Helen"의 인접 정점은 "Fred"와"Candy"이다. "Fred"는 해시 맵에 존재하니 "Candy"에 깊이 우선 탐색을 수행한다.
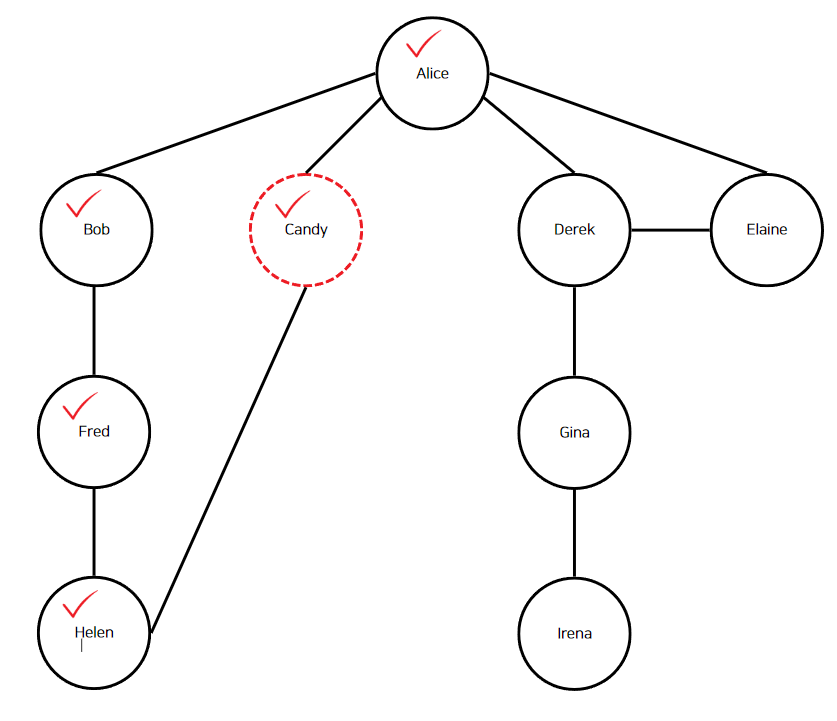
"Candy"는 현재 정점이므로 해시 맵에 등록한다. "Candy"의 인접 정점은 "Helen"과 "Alice"이다. "Helen"과 "Alice" 모두 방문했으니 메서드는 종료되고 최초의 호출 스택으로 돌아간다.
지금까지의 호출 과정을 되새겨보자. 맨 처음 "Alice"부터 시작해서 "Candy"까지 스택에 쌓였을 것이다.
요컨데 스택의 상황은 아래 이미지와 같을 것이다.
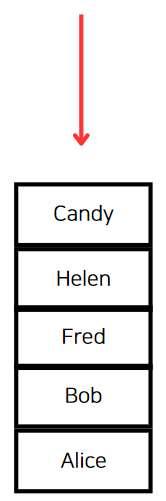
호출 스택을 하나씩 해제해보자. "Candy", "Helen", "Fred", "Bob" 모두 인접한 정점을 다 방문하였으므로 별 다른 수행없이 호출 스택이 해제되고, "Alice"가 남는다.
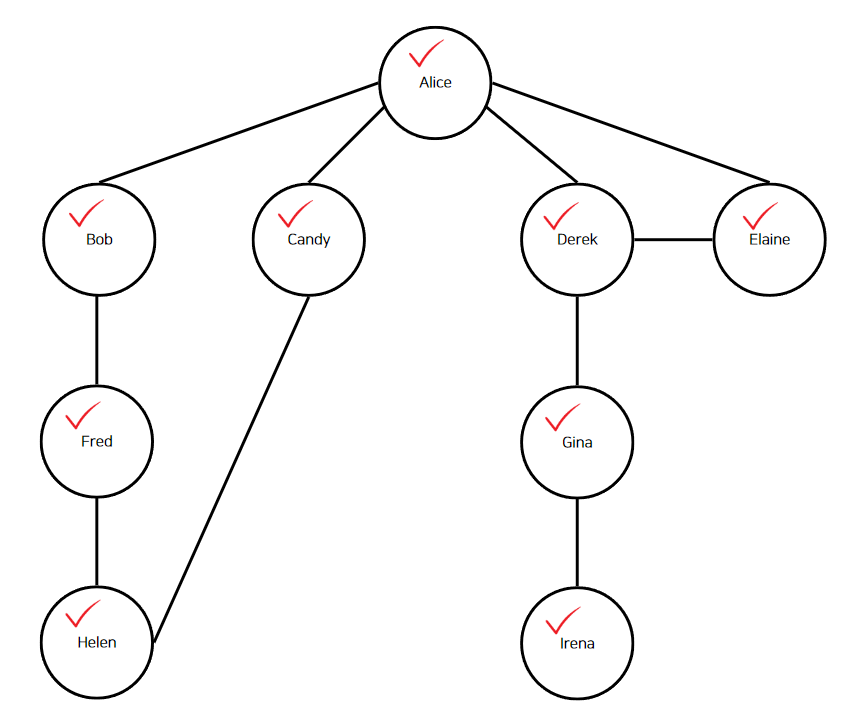
"Alice"는 아직 모든 인접 정점을 방문하지 않았다. "Derek"과 "Elaine"이 남아있다.
위에서 진행한 과정을 그대로 적용해보자. "Alice"는 "Derek"에 대한 깊이 우선 탐색을 호출하고, "Derek"은 인접 정점인 "Elaine"과 "Alice"를 호출한다. "Elaine"의 인접한 정점인 "Alice" "Derek" 모두 해시 맵에 등록되어있는 상태일 것이므로 다시 "Derek"으로 돌아가 나머지 인접 정점인 "Gina"를, "Gina"는 "lrena"에 대한 깊이 우선 탐색을. "lrena"의 인접 정점은 "Gina"이며 이미 방문했으므로 끝이난다. 모든 정점을 순회한 것이다.
깊이 우선 탐색 - 코드 구현
다음은 자바로 구현한 깊이 우선 순회이다. Vertex 클래스에 추가하였다.
// 깊이 우선 탐색
public void dfsTraverse(Vertex vertex, HashMap< String, Boolean > visitedVertices ){
// 정점을 해시 테이블에 추가해 방문했다고 표시한다.
visitedVertices.put( vertex.value, true );
// 정점의 값을 출력해 제대로 순회하는지 확인한다.
System.out.println(vertex.value);
// 현재 정점의 인접 정점을 순회한다.
for( Vertex v : vertex.getAdjacentVertices() ){
// 이미 방문했던 인접 정점은 무시한다.
if ( !visitedVertices.containsKey(v.value) ) {
// 인접 정점에 대해 메서드를 재귀적으로 호출한다.
dfsTraverse(v, visitedVertices);
}
}// end for
} // end dfsTraverse
위의 dfsTraverse 메서드는 단순히 순회만하므로 아래의 메서드를 사용하여 찾고 싶은 정점을 찾을 수 있다.
// 깊이 우선 탐색 Vertex 검색
public Vertex dfsVertexSearch( Vertex vertex, String searchValue, HashMap<String, Boolean> visitedVertices ){
// 찾고 있던 정점이면 원래의 vertex를 반환한다.
if( vertex.value.equals(searchValue) ) return vertex;
visitedVertices.put( vertex.value, true );
for( Vertex v : vertex.getAdjacentVertices() ){
if( !visitedVertices.containsKey( v.value ) ) {
// 인접 정점이 찾고 있던 정점이면
// 그 인접 정점을 반환한다.
if( v.value.equals( searchValue ) ) return v;
// 인접 정점에 메서드를 재귀적으로 호출해
// 찾고 있던 정점을 계속 찾는다.
Vertex vertexWereSearchingFor =
dfsVertexSearch( v, searchValue, visitedVertices );
// 위 재귀에서 올바른 정점을 찾았다면
// 그 정점을 반환한다.
if( vertexWereSearchingFor != null ) return vertexWereSearchingFor;
}
} // end for
return null;
} // end dfsVertexSearch너비 우선 탐색
너비 우선 탐색(BFS;Breadth-First-Search)은 깊이 우선 탐색과 달리 재귀를 사용하지 않고 자료구조 큐를 사용한다.
너비 우선 순회는 다음과 같은 단계로 동작한다.
- 그래프 내 아무 정점에서 시작하며, 이 정점을 시작 정점으로 정한다.
- 시작 정점을 해시 맵에 추가해 방문했다고 표시한다.
- 시작 정점을 큐에 추가한다.
- 큐가 빌 때까지 실행하는 반복문을 시작한다.
- 루프 안에서 큐의 첫 번째 정점을 삭제하고 해당 정점을 현재 정점으로 정한다.
- 현재 정점의 인접 정점을 순회한다.
- 이미 해시 맵에 존재하는(방문한) 인접 정점이면 무시한다.
- 아직 해시 맵에 없는 정점이라면 맵에 추가한 후 큐에 추가한다.
- 큐가 빌 때까지 4단계부터 반복한다.
아래의 이미지로 쉽게 이해해보자.
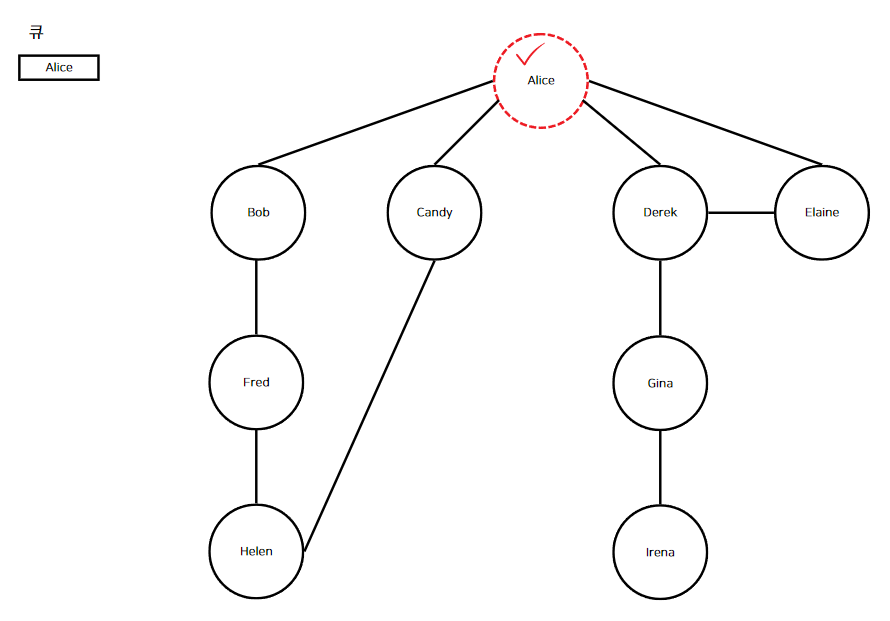
이번에도 "Alice"부터 시작한다. "Alice"를 시작 정점으로 정하고, 해시 맵과 큐에 추가한다.
여기서부터 중요한데, 위에서 제시한 단계를 집중해서 따라가야한다. 방금 1, 2, 3 단계를 수행했으므로 4단계부터 시작이다.
큐에서 첫 번째 정점을 삭제해 현재 정점으로 만든다. 삭제될 정점은 "Alice"이다. "Alice"의 인접 정점을 순회한다.
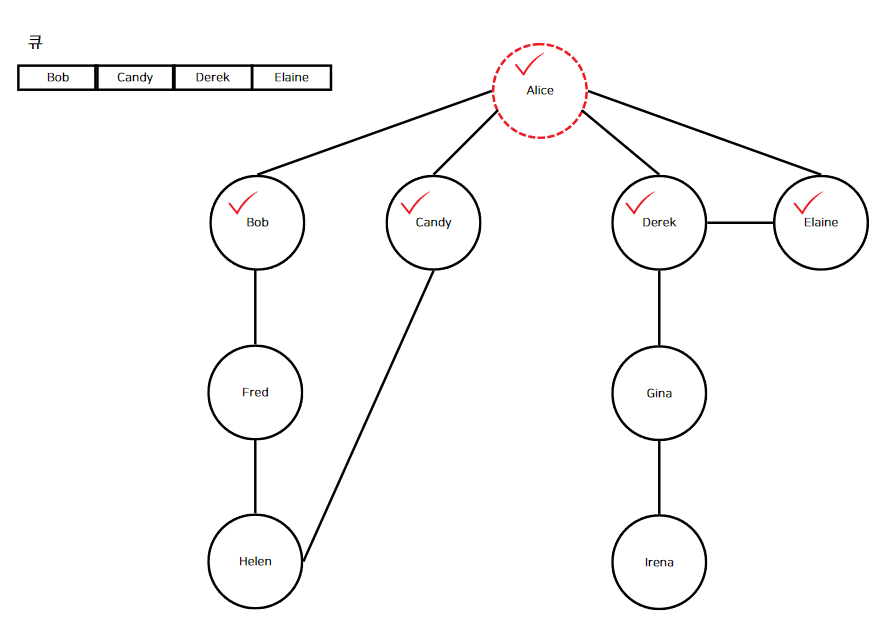
"Bob"을 방문했으므로 해시 맵과 큐에 "Bob"을 추가한다. "Alice"의 정점을 큐에서 삭제하고 현재 정점으로 삼았다고 했으니 현재 큐는 "Bob"외에는 다른 정점이 없을 것이다. 이런 식으로 "Candy", "Derek", "Elaine"을 방문하며 큐와 맵에 추가한다.
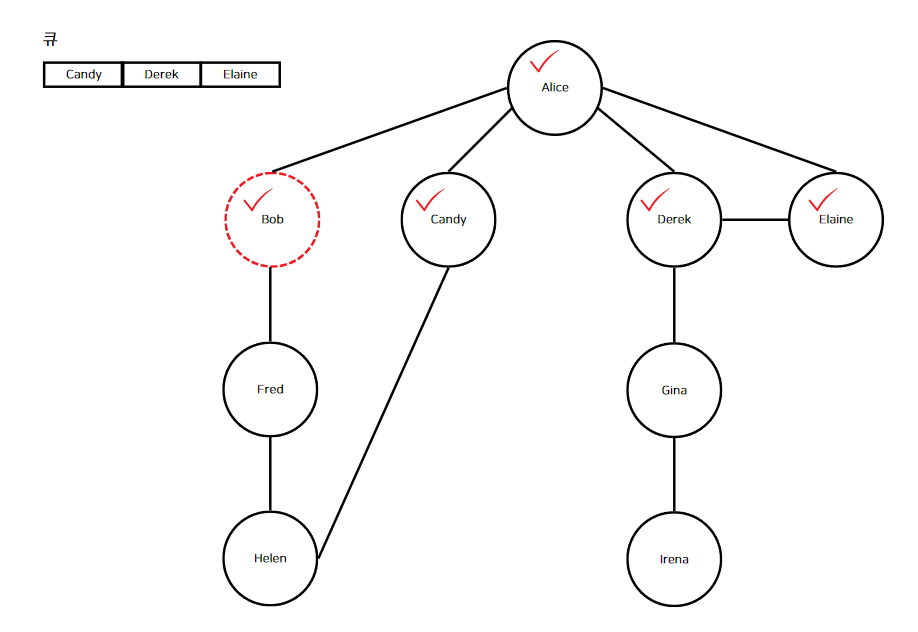
9단계까지 무사히 마쳤으므로 다시 4단계로 돌아가 반복한다. 큐의 맨 앞에 "Bob"이 들어있으니 "Bob"을 디큐하고 현재 정점으로 만든다.
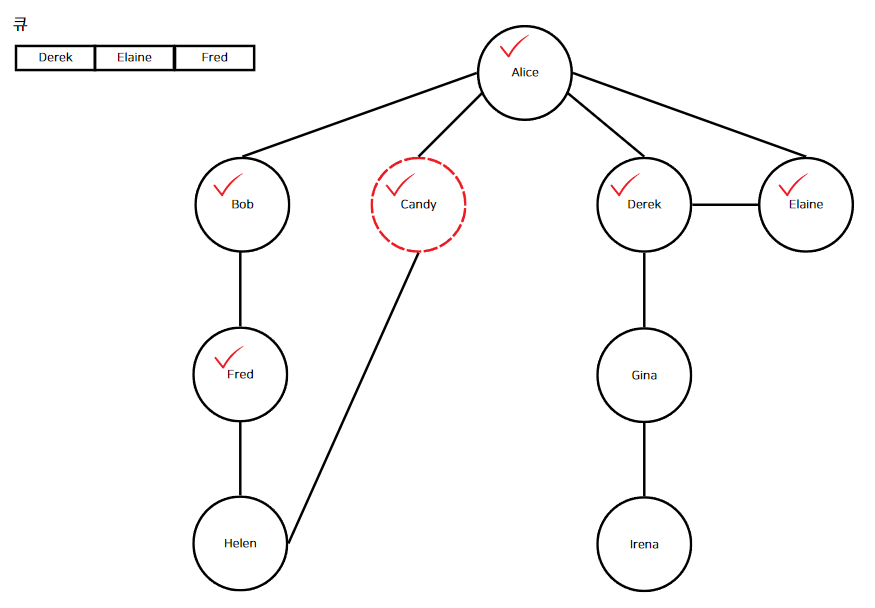
"Bob"의 인접 정점을 모두 순회한다. "Alice"는 해시 맵에 존재하므로 "Alice"는 무시하고 "Fred"를 큐와 해시 맵에 추가한다. "Bob"의 인접 정점이 더 이상 없으므로 이어서 큐의 맨 앞 항목인 "Candy"를 디큐해 현재 정점으로 만든다.
"Candy"의 인접 정점을 모두 순회한다. "Alice"는 해시 맵에 존재하므로 "Alice"는 무시하고 "Helen"를 큐와 해시 맵에 추가한다. "Candy"의 인접 정점이 더 이상 없으므로 이어서 큐의 맨 앞 항목인 "Derek"를 디큐해 현재 정점으로 만든다.
이런 식으로 나머지 정점에 대해서 너비 우선 순회를 호출한다. 항상 큐의 맨 앞의 정점을 디큐하고 해당 정점을 현재 정점으로 만든다. 그리고 현재 정점의 인접 정점을 순회한다. 반복하면 그래프의 모든 정점에 도달할 수 있다.
너비 우선 탐색 - 코드 구현
다음은 자바로 구현한 너비 우선 순회이다. Vertex 클래스에 추가했다.
// 너비 우선 탐색
public void bfsTraverse( Vertex startingVertex ){
Queue<Vertex> queue = new LinkedList<>();
Map<String, Boolean> visitedVertices = new HashMap<>();
visitedVertices.put( startingVertex.value, true );
queue.add( startingVertex );
// 큐가 빌 때까지 실행한다.
while( !queue.isEmpty() ){
// 큐에서 첫 번째 정점을 삭제해 현재 정점으로 만든다.
Vertex currentVertex = queue.poll();
// 현재 정점의 값을 출력한다.
System.out.println(currentVertex.getValue());
// 현재 정점의 인접 정점을 순회한다.
for( Vertex v : currentVertex.getAdjacentVertices() ){
// 아직 방문하지 않은 인접 정점이면
if( !visitedVertices.containsKey( v.value ) ){
// 그 인접 정점에 방문했다고 표시한다.
visitedVertices.put( v.value, true );
// 그 인접 정점을 큐에 추가한다.
queue.add( v );
}
} // end for
} // end while
}// end bfsTraverse
}그래프 탐색의 효율성 O(V+E)
그래프 탐색의 효율성을 빅 오로 딱 표현하기 어렵다 왜냐하면 정점의 개수가 같은 그래프여도 간선의 개수가 차이가 난다면 단계 수가 많이 달라지기 때문이다.
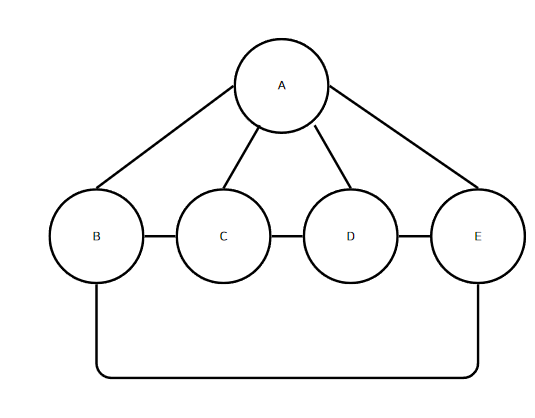
위 이미지의 그래프를 살펴보자. 정점이 총 5개이다. 해당 그래프에 대해서 탐색을 수행했을 때 단계 수는 얼마나 걸릴까? 얼핏 봤을 때 정점의 개수만큼 걸린다고 생각할 수도 있다. 그러나 각 정점은 인접 정점을 모두 순회한다. 이미 해시 맵에 등록되어있는지 확인하는 단계도 포함해야한다.
그러면 다음과 같은 단계가 걸린다.
A: 인접 정점 4개를 순회하는 4단계, B: 인접 정점 3개를 순회하는 3단계, C: 인접 정점 3개를 순회하는 3단계, D: 인접 정점 3개를 순회하는 3단계, E: 인접 정점 3개를 순회하는 3단계
총 16번 순회한다. 정점 5개를 방문하는 것과 합치면 21번이다.
똑같은 정점이 5개인 그래프로 비교해보자.
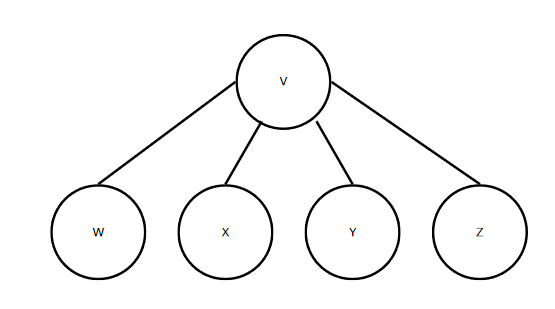
전의 이미지와 달리 간선의 개수가 많이 줄었다. 따라서 인접 정점을 순회하는 단계수 또한 줄어들 것이다.
4개의 간선을 공유하는 V같은 경우 인접 정점을 4번 순회하므로 4단계가 걸리지만 나머지 정점들은 모두 1단계씩 걸린다.
방문할 정점과 합치면 총 13단계이다.
결론은 각 정점과 더불어 인접 정점이 몇 개인지도 고려해야한다. 여러 책에서 해당 표기를 O(V + E)라고 설명한다. V는 정점(Vertex)을 뜻하며 E는 간선(Edge)를 뜻한다.
사실 V-W-X-Y-Z 에서의 효율성은 V + 2E이다. 그리고 간선 수가 많아질 수록 단계 수가 더 늘어난다. 그러나 빅 오는 상수를 포함하지 않으므로 O(V + E)라고 부른다.
둘의 효율성은 일반적으로 똑같지만 경우에 따라 깊이를 우선하는 탐색과 너비를 우선 시하는 탐색을 골라 사용해야한다. 주변을 순회한다면 너비를, 시작 정점에서 빨리 멀어져야한다면 깊이 우선 탐색이 이상적이다.
