
연결 리스트
연결 리스트는 배열과 마찬가지로 데이터의 나열을 표현하는 자료 구조이다.
연결 리스트와 배열은 비슷하게 작동하지만 내부적으로는 크게 다르다.
배열은 메모리 내에 연속적으로 존재하는 빈 메모리 공간 그룹을 찾아 데이터를 저장할 수 있도록 할당된다.
배열과 달리 연결 리스트는 연속된 메모리 공간이 아니라 곳곳에 퍼져 있을 수 있다.
이때, 메모리 곳곳에 흩어진 연결된 데이터를 노드라고 부르고, 이 노드는 배열 내 한 항목을 나타낸다. 노드는 메모리 곳곳에 흩어졌다고 하였는데, 컴퓨터는 노드들이 같은 연결 리스트에 속해있는지 어떻게 알 수 있을까?
각 노드는 저장해야할 데이터 외에 다음 노드의 메모리 주소도 포함한다.
이 다음 노드의 메모리 주소를 가리키는 것을 링크(link)라 부른다.
연결 리스트를 그림으로 표현하면 아래 이미지와 같다.
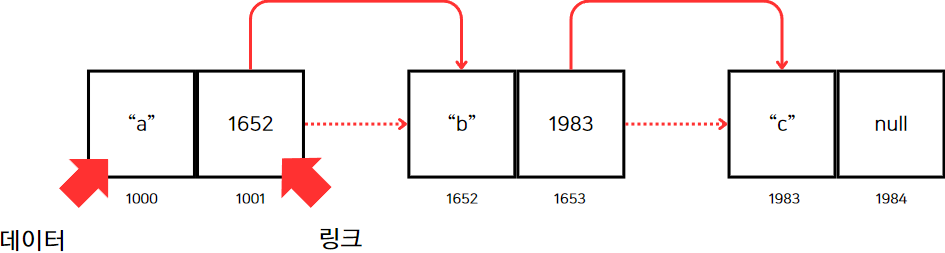
이미지를 잘 보면 각 노드는 데이터를 저장하는 공간과 다음 노드의 메모리 주소를 가리키는 공간으로 메모리 공간을 총 두 개씩 갖는다.
마지막 노드는 연결 리스트가 끝나므로 null을 갖는다.
연결 리스트의 첫 번째 노드를 헤드(head), 마지막 노드를 테일(tail)이라고도 부른다.
연결 리스트 구현
다음은 java로 구현해본 연결 리스트이다. 두 개의 클래스로 구현했다.
먼저 node 역할을 하는 Node_ 클래스이다.
public class Node_ {
private String data;
private Node_ nextNode;
public Node_(String data) {
this.data = data;
}
public String getData() {
return data;
}
public void setData(String data) {
this.data = data;
}
public Node_ getNextNode() {
return nextNode;
}
public void setNextNode(Node_ nextNode) {
this.nextNode = nextNode;
}
}
Node_ 클래스의 필드는 data와 다음 노드로의 링크인 nextNode를 갖는다.
Node_ node1 = new Node_("once");
Node_ node2 = new Node_("upon");
Node_ node3 = new Node_("a");
Node_ node4 = new Node_("time");
node1.setNextNode(node2);
node2.setNextNode(node3);
node3.setNextNode(node4);위의 코드는 "once" , "upon" , "a" , "time" 문자열을 포함하는 네 개의 노드로 이루어진 리스트를 만드는 코드이다.
생성된 리스트는 아래의 이미지와 같이 나타낼 수 있다.

getData() 메서드는 노드의 데이터를 반환하고, getNextNode()는 다음 노드를 반환한다.
node1.setNextNode(node2);
node2.setNextNode(node3);
node3.setNextNode(node4);위의 코드는 위에 작성된 연결 리스트를 생성한 코드이다. 자세히 보면 node1의 링크는 node2로 set 되어있다. 마찬가지로 node2와 node4도 set이 잘 되어있다. 이와 같이 node1의 링크또한 명시해줄 필요가 있다.
Node_ 클래스만 있어도 연결 리스트를 생성할 수 있지만, 연결 리스트가 어디서부터 시작하는지 쉽게 알려줄 방법이 필요하다.
public class LinkedList {
private Node_ node;
public LinkedList(Node_ node) {
this.node = node;
}
public Node_ getNode() {
return node;
}
public void setNode(Node_ node) {
this.node = node;
}LinkedList list = new LinkedList( node1 )방법은 위의 코드와 같다. LinkedList 클래스는 리스트의 첫 번째 노드를 알려주는 역할을 한다.
연결 리스트의 각 연산으로 알아보는 효율성
읽기
컴퓨터는 O(1)만에 배열에서 값을 찾는다.
하지만 연결 리스트의 값을 읽을 때, 컴퓨터는 노드의 주소를 바로 알 수 없기에 O(1) 만에 찾아낼 수 없다.
따라서 최악의 케이스( 연결 리스트의 마지막 노드를 읽을 때 )에서 노드가 N개일 때 N단계가 걸린다. 이는 배열에 비해 큰 단점이라 할 수 있다.
연결 리스트: 읽기 메소드 구현
다음은 연결 리스트의 노드에서 값을 읽을 수 있는 read() 메서드의 코드이다. 위에서 구현한 LinkedList에 추가하였다.
// linkedList 검색은 배열과 달리 O(N)단계가 걸린다.
public Object read(int index) {
// 리스트의 첫 번째 노드에서 시작한다.
Node_ currentNode = node;
int currentIndex = 0;
while (currentIndex < index) {
// 찾고 있는 인덱스에 도착할 때까지 각 노드의 링크를 계속 따라간다.
currentNode = currentNode.getNextNode();
currentIndex += 1;
// 리스트 끝에 도착했다면 찾고 있는 값이 리스트에 없다는 뜻이므로
// 널을 반환한다.
if (currentNode == null) {
return null;
}
}
return currentNode.getData();
}연결 리스트의 세 번째 노드를 읽으려면 다음과 같이 노드의 인덱스를 넣어 메서드를 호출한다.
list.read(2)
검색
배열을 선형 검색할 때 O(N)이 걸린다.
연결 리스트의 검색도 마찬가지로 O(N)이다.
배열의 검색과 위에서 구현한 read() 메소드와 유사하게 첫번째 노드에서 시작해서 원하는 값을 찾을 때까지 노드를 계속 거쳐야한다.
연결 리스트: 검색 메소드 구현
다음과 같이 검색 연산을 구현할 수 있다. LinkedList 클래스에 indexOf()를 추가했다. 그리고 검색할 값을 전달하며 호출한다.
public Object indexOf( String value ) {
// 리스트의 첫 번째 노드에서 시작한다.
Node_ currentNode = node;
int currentIndex = 0;
while( currentNode != null) {
// 찾고 있던 데이터를 찾았으면 반환한다.
if( currentNode.getData().equals(value))
return currentIndex;
// 그렇지 않으면 다음 노드로 이동한다.
else {
currentNode = currentNode.getNextNode();
currentIndex++;
}
}
//데이터를 찾지 못한 채 전체 리스트를 순회했으면 널을 반환한다
return null;
}다음 코드로 원하는 값을 검색할 수 있다.
list.indexOf("a")
삽입
연결 리스트의 읽기와 검색 메소드는 배열의 연산에 비해 성능면에서 더 나은 모습을 보이지 못했다.
하지만 연결 리스트의 삽입 연산은 배열에 비해 좋은 성능을 보인다.
배열 삽입에서 최악의 케이스는 인덱스 0에 원소를 삽입할 때이다. 데이터를 한 칸씩 오른쪽으로 옮겨 빈 메모리를 만든 후 삽입하여야 하기 때문에 효율성은 O(N)이다.
반면 연결 리스트는 리스트 앞에 삽입하는데에 한 단계만 걸린다.

위의 이미지처럼 새로운 문자열 "yellow"를 연결 리스트 앞에 삽입하려면 "yellow" 새 노드를 생성하고 "blue"의 노드를 링크하면 된다.
이러면 O(1)만 걸린다.
그렇다면 노드를 중간에 삽입한다면 어떨까?
새로운 문자열 "purple"을 인덱스 1 뒤에 추가하고 싶다고 가정했을 때, 연결 리스트에서는 첫 번째 노드부터 시작해서 인덱스 1까지 가야한다.
위의 이미지에서 인덱스 1 뒤는 "blue"의 뒤다. "yellow", "blue"를 지나 "green" 바로 앞에 삽입할 것이다.
삽입은 똑같이 문자열 "purple"이 담긴 새 노드의 링크를 "green"으로 하고 "blue" 노드의 링크를 삽입할 "purple" 노드로 하면 된다.
이때 "purple" 노드를 추가하는 데 3단계가 걸렸다.
삽입은 원하는 인덱스를 찾는데에 N단계와 삽입하는 1단계, 즉, N+1 단계가 걸린다.
정리하면 연결 리스트에서 삽입은 최선의 케이스에서 O(1), 최악의 케이스에서 O(N)이 걸린다.
이를 배열과 비교했을 때 최선 최악의 케이스가 서로 정반대인 것을 알 수 있다.
아래 표는 상황별로 정리한 표이다.
| 케이스 | 배열 | 연결 리스트 |
|---|---|---|
| 앞에 삽입 | 최악의 경우 | 최선의 경우 |
| 중간 삽입 | 평균적인 경우 | 평균적인 경우 |
| 맨 끝에 삽입 | 최선의 경우 | 최악의 경우 |
연결 리스트: 삽입 메소드 구현
다음은 자바로 구현해본 삽입 메소드이다. LinkedList 클래스에 추가했다.
// 노드에서의 삽입은 매우 빠르다.
public void insertAtIndex(int index , String value) {
// 전달받은 value로 새 노드를 생성한다.
Node_ newNode = new Node_(value);
// 리스트 앞에 삽입하는 경우
if( index == 0) {
// 새 노드의 링크가 첫 번째 노드를 가리키게 한다.
newNode.setNextNode(node);
this.node = newNode;
return;
}
//앞이 아닌 다른 위치에 삽입하는 경우
Node_ currentNode = node;
int currentIndex = 0;
// 먼저, 삽입하려는 새 노드의 바로 앞 노드에 접근한다.
while( currentIndex < index - 1) {
currentNode = currentNode.getNextNode();
currentIndex++;
}
// 새 노드의 링크가 다음 노드를 가리키게 한다.
newNode.setNextNode(currentNode.getNextNode());
// 새 노드를 가리키도록 앞 노드의 링크를 수정한다.
currentNode.setNextNode(newNode);
}삭제
연결 리스트는 삭제 또한 매우 빠르다.
삽입과 마찬가지로 리스트 앞에서 삭제가 이루어질 때 빠르다.

위의 이미지에서 "once"를 삭제해보자.
위에서 구현한 LinkedList의 setNode() 메소드를 사용하여 첫번째 노드를 "upon"으로 해주면 된다. 그러면 "once" 노드의 참조는 없어진다. 연결 고리를 끊어냄으로써 리스트에서 제거하는 것이다.
마지막 노드를 삭제하는 경우도 한 단계로 가능하다. 끝에서 두 번째 노드를 가져와 링크를 null로 바꾸면 된다. 위의 이미지에선 "a" 노드를 가져와 링크를 "time" 노드가 아닌 null로 바꾸는 것과 같다.
연결 리스트 중간 삭제는 먼저 삭제하려는 앞 노드에 접근하고, 그 노드의 링크를 삭제하려는 뒤 노드로 바꾸면 된다.
예를 들어 위의 이미지의 "a"를 삭제하고 싶을 때, "a"의 바로 앞 노드인 "upon"에 접근한다. 이어서 "upon"의 링크를 "a"가 아닌 "time"으로 바꾼다. 이렇게 하면 "a" 노드를 리스트에서 제거할 수 있다.
연결 리스트: 삭제 메소드 구현
다음은 자바로 구현한 삭제 메소드이다. LinkedList 클래스에 추가했다.
// 삭제 또한 빠르다.
public void deleteAtIndex(int index) {
//첫 번째 노드를 삭제하는 경우
if(index == 0) {
// 단순히 현재 두 번째 노드를 첫 번째 노드에 할당한다.
this.node = node.getNextNode();
return;
}
Node_ currentNode = node;
int currentIndex = 0;
// 먼저 삭제하려는 노드의 바로 앞 노드를 찾아 currentNode에 할당한다.
while( currentIndex < index - 1) {
currentNode = currentNode.getNextNode();
currentIndex++;
}
// 삭제하려는 노드의 바로 뒤 노드를 찾는다.
Node_ afterDeleteNode = currentNode.getNextNode().getNextNode();
// currentNode의 링크가 afterDeleteNode를 가리키도록 수정한다.
// 이렇게 하면 삭제하면 노드가 리스트에서 제외된다.
currentNode.setNextNode(afterDeleteNode);
}연결 리스트 효율성
아래 표는 연결 리스트와 배열을 비교한 표이다.
| 연산 | 배열 | 연결 리스트 |
|---|---|---|
| 읽기 | O(1) | O(N) |
| 검색 | O(N) | O(N) |
| 삽입 | O(N)(끝에서 하면 O(1)) | O(N)(앞에서 하면 O(1)) |
| 삭제 | O(N)(끝에서 하면 O(1)) | O(N)(앞에서 하면 O(1)) |
전체적으로 시간 복잡도 측면에서 봤을 때 연결 리스트의 효율성은 그다지 효과적이지 않다.
연결 리스트가 효과적이려면 삽입과 삭제 단계가 O(1)이라는 점을 활용해야 하는데, 이 또한 리스트의 앞에서 삽입하거나 삭제할 때만 그렇다.
그러나, 바로 아래에 작성할 예시를 보면 연결 리스트가 매우 효과적일 수 있음을 알 수 있다.
전화번호부를 검사하여 유효하지 않은 전화번호를 삭제하려는 기능을 만든다고 생각해보자. 배열과 연결 리스트는 리스트를 검사하며 삭제해야 하므로 N단계가 걸린다. 하지만 배열은 추가로 또 다른 O(N) 단계가 필요하다. 빈 공간을 메꾸기 위해 나머지 원소들을 왼쪽으로 옮겨야 하기 때문이다.
하지만 연결 리스트는 삭제 시 해당 노드의 앞 노드의 링크를 적절한 노드로 바꾸면 되니 각 삭제마다 한 단계가 걸린다.
천 개의 전화번호 리스트 중 100개가 유효하지 않는다고 가정했을 때, 1000개 원소를 읽는데 1000단계가 걸리고, 100개를 삭제하는데 더불어 1000개의 원소를 옮겨야하니 추가로 100,000 단계가 걸린다.
연결 리스트는 단지 읽기 1000단계와 삭제 100단계, 1100단계면 된다.
즉, 연결 리스트는 삽입이나 삭제를 연산할 때 매우 적절한 자료 구조다.
