운영체제를 살펴보기 위한 몇 가지 관점이 있습니다.
1. 운영체제가 제공하는 서비스를 위주로 보는 관점
2. 운영체제가 사용자와 프로그래머에게 제공하는 인터페이스 위주의 관점
3. 시스템의 구성요소과 그들의 상호 연결을 위주로 보는 관점Chapter 2에서는 사용자, 프로그래머, 운영체제 설계자의 입장에서 바라본 운영체제의 위의 세 가지 측면(서비스, 인터페이스, 구성요소)을 살펴보고자 합니다.
운영체제 서비스
운영체제는 프로그램의 실행 환경과 프로그램, 프로그램 사용자에게 특정 서비스를 제공합니다.
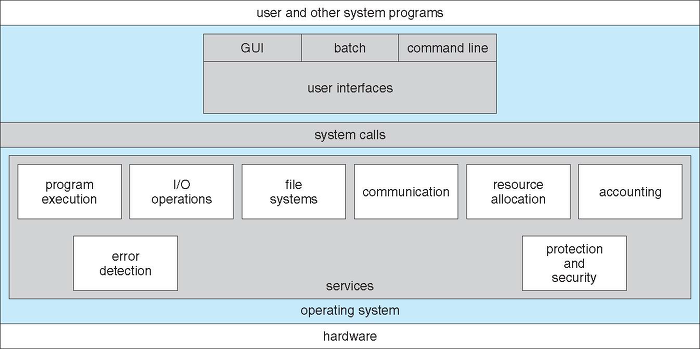
위의 사진은 운영체제 서비스를 중심으로 전체적인 컴퓨터 시스템의 구조를 나타낸 것입니다.
운영체제의 서비스는 사용자에게 도움을 주는 것이 목적인 서비스 들과 시스템의 효율성을 보장하는 것이 목적인 시스템이 있습니다.
사용자에게 도움을 주는 것이 목적인 서비스
1. 사용자 인터페이스(User Interface)
거의 모든 운영체제는 UI를 제공합니다. UI는 여러 가지 형태로 제공될 수 있는데 그 중 대표적인 예시가 GUI(Graphic User Interface)입니다. 인터페이스는 윈도 시스템으로(Window OS가 아님) 입출력을 지시하고, 메뉴에서 선택하고, 화면을 선택하는 포인팅 장치인 마우스와 텍스트를 입력할 수 있는 키보드를 가지고 있습니다. 핸드폰과 태블릿같은 모바일 시스템은 터치스크린 인터페이스를 제공합니다.
UI의 또 다른 옵션으로는 CLI(Command Line Interface)가 있습니다. CLI는 명령어를 사용하며 이를 입력할 방법(예 : 키보드)이 사용됩니다.
2. 프로그램 수행(Program Execution)
운영체제는 프로그램을 메모리에 적재해 실행하거나 정상적이든 비정상적이든 실행을 끝낼 수 있어야 합니다.
3. 입출력 연산(I/O operation)
수행되고 있는 프로그램은 파일 혹은 입출력 장치에 연관된 입출력을 요구할 수 있습니다. 효율성과 보호를 위해서 사용자들은 입출력 장치를 직접 제어할 수 없습니다. 따라서 운영체제는 사용자에게 입출력 수행의 수단을 제공해야 합니다.
4. 파일 시스템 조작(File System manipulation)
운영체제의 서비스 중에서 파일 시스템은 특히 중요한 부분입니다. 프로그램은 파일을 읽고, 쓰고, 생성하고, 삭제하고, 특정 파일을 찾고, 파일의 정보를 열거할 수 있어야 합니다. 또한 몇몇 프로그램은 파일 소유권에 기반을 둔 권한관리를 이용하여 파일이나 디렉토리의 접근 허가, 거부할 수 있게 합니다. 많은 운영체제들은 때로 개인의 선택, 특정 특성과 특성을 제공하기 위하여 다양한 파일 시스템을 제공합니다.
5. 통신(Communication)
IPC(Inter Process Communication, 프로세스간 통신)를 수행하는 두 가지 방법이 있습니다. 첫 번째는 동일한 컴퓨터에서 수행되고 있는 프로세스들 사이에서 일어나고, 두 번째는 네트워크에 의해 함께 묶여 있는 서로 다른 컴퓨터 시스템상에서 수행되는 프로세스들 사이에서 일어납니다. 공유 메모리, 메시지 전달(Message Passing) 기법을 사용하여 구현될 수 있는데 후자의 경우 정보의 패킷들이 운영체제에 의해 프로세스들 사이를 이동합니다.
6. 오류 탐지(Error detection)
운영체제는 모든 가능한 오류를 항상 의식하고 있어야 합니다. 오류는 CPU, 메모리 하드웨어(메모리 오류, 정전 등), 입출력 장치(테이프의 패리티 오류, 네트워크의 접속 실패, 또는 프린터의 종이 부족), 또는 사용자 프로그램(연산의 overflow 또는 불법적인 메모리 위치에의 접근 시도)에서 일어날 수 있습니다.
시스템의 효율성을 보장하는 것이 목적인 서비스
1. 자원 할당(Resource Allocation)
운영체제는 다수의 프로세스 작업이 동시에 실행될 때, 할당해 줄 자원을 관리합니다. CPU를 예로 들면, 운영체제는 CPU를 최대한 효율적으로 사용하기 위해 CPU스케줄링 루틴이 CPU의 속도, 반드시 실행해야 할 프로세스들, CPU의 처리 코어의 개수와 다른 요인들을 고려하도록 해야 합니다. 또한 이에 영향을 줄 수 있는 다른 주변 장치를 할당하는 루틴도 고려해야 합니다.
2. 기록 작성(Logging)
사용자는 어떤 프로그램이 어떤 자원을 얼마나 사용하는지 추적하길 원합니다. 이 데이터들은 컴퓨팅 서비스를 효율적으로 개선하고 시스템을 재구성하고자 하는 관리자에게 귀중한 자료가 될 수 있습니다.
3. 보호(Protection)와 보안(Security)
여러 프로세스가 병행하게 수행될 때, 한 프로세스가 다른 프로세스나 운영체제 자체를 방해해서는 안 됩니다. 보호는 시스템 자원에 대한 모든 접근이 통제되도록 보장하는 것을 필요로 합니다. 외부로부터의 시스템 보안 또한 중요하다. 보안은 네트워크 어댑터 등과 같은 외부 입출력 장치들을 부적합한 접근 시도로부터 지키고, 침입의 탐지를 위해 모든 접속을 기록하는 것으로 범위를 넓힙니다. 만약 시스템이 보호되고 보안이 유지되려면, 시스템 전체에 걸쳐 예방책(precaution)이 제정되어야 한다. 하나의 사슬은 가장 약한 연결 고리만큼만 강한 법입니다.
2. 운영체제 인터페이스
사용자가 운영체제와 접촉하는 기본적인 3가지 방법이 있습니다. 첫 번째는 CLI(Command Line Interface) 또는 명령 인터프리터(Command Interpreter)이다. 명령 인터프리터는 CLI를 사용하여 사용자가 입력한 명령어를 이해하고, 실행 가능한 명령으로 변환하여 실행하는 프로그램을 말합니다. 즉, 사용자가 CLI를 통해 입력한 명령어를 해석하고 실행하기 위한 프로그램이라고 할 수 있습니다. 다른 두 가지 방식은 사용자가 그래픽 기반 사용자 인터페이스를 통하여 운영체제와 접촉하는 것입니다.
1. 명령 인터프리터(Command Interpreter)
CLI는 사용자가 텍스트 기반의 인터페이스를 통해 운영체제와 상호작용할 수 있도록 하는 방법을 말합니다. 예를 들어, 터미널에서 명령어를 입력하여 운영체제에서 제공하는 기능을 실행하는 것이 CLI의 한 예입니다. CLI는 운영체제의 Shell이나 터미널 프로그램 등을 통해 구현될 수 있습니다.
반면에 Command Interpreter는 CLI를 사용하여 사용자가 입력한 명령어를 이해하고, 실행 가능한 명령으로 변환하여 실행하는 프로그램을 말합니다. 즉, 사용자가 CLI를 통해 입력한 명령어를 해석하고 실행하기 위한 프로그램이라고 할 수 있습니다. 대표적인 Command Interpreter로는 Unix/Linux 계열에서 사용되는 bash, csh, zsh 등이 있습니다.
명령 인터프리터의 중요한 기능은 사용자가 지정한 명령을 가져와서 그것을 수행하는 것입니다. 이 수준에서 제공된 많은 명령은 파일을 조작하는데 이 명령어들은 두 가지 일반적인 방식으로 구현될 수 있습니다.
- 명령 인터프리터 자체가 명령을 실행할 코드를 가지는 방법
예를 들어 한 파일을 삭제하기 위한 명령은 명령 인터프리터가 자신의 코드의 한 부분으로 분기하고, 그 코드 부분이 매개변수를 설정하고 적절한 시스템 콜을 합니다. 이 경우 제공될 수 있는 명령의 수가 명령 인터프리터의 크기를 결정하는데, 그 이유는 각 명령이 자신의 구현 코드를 요구하기 때문입니다.
- 시스템 프로그램에 의해 대부분의 명령을 구현하는 방법
이 방법의 경우 인터프리터는 전혀 명령을 알지 못합니다. 단지 메모리에 적재되어 실행될 파일을 식별하기 위해 명령을 사용합니다. rm 이라는 명령어가 파일 내의 코드로 정의되어 있고 다른 어떤 파일을 삭제하기 위해rm 아무개.txt이라는 명령어를 입력하면 rm 파일은 아무개.txt라는 파일을 매개변수로 받아 코드로 정의된 로직을 실행하게 됩니다. 이러한 방법으로 프로그래머는 적합한 프로그램 로직을 가진 새로운 파일을 생성함으로써 시스템에 새로운 명령을 쉽게 추가할 수 있습니다. 명령 인터프리터 프로그램은 이제 아주 작아질 수 있으며, 새로운 명령을 추가하기 위해 변경될 필요가 없어집니다.
2. 그래픽 기반 사용자 인터페이스(Graphical User Interface)
사용자는 데스크톱이라고 특정어지는 마우스를 기반으로 하는 윈도 메뉴 시스템을 사용한다. 마우스 뿐만 아니라 키보드, 터치 스크린 등을 사용하여 그래픽 화면에서 운영체제와 상호작용합니다. 거의 대부분의 운영체제에서 GUI를 사용합니다.
3. 터치스크린 인터페이스
모바일 시스템에서는 CLI, 마우스 및 키보드가 실용적이지 않기 때문에 스마트폰이나 태블릿 컴퓨터는 일반적으로 터치스크린 인터페이스를 사용합니다. 사용자는 제스쳐(Gesture) 통해 운영체제와 상호 작용합니다.
4. 인터페이스의 선택
위의 방법들은 각각 사용되기에 적절한 시스템이 다를 수 있습니다. 심지어 사용자마다도 다를 수 있습니다. 따라서 유용하고 친밀한 UI를 설계하는 것이 운영체제의 직접적인 기능은 아닙니다. 운영체제의 관점에서, 우리는 사용자 프로그램과 시스템 프로그램을 구별하지 않습니다.
3. 시스템 콜(System Call)
시스템 콜은 운영체제에 의해 사용 가능하게 된 서비스에 대한 인터페이스를 제공한다.
1. 연속된 시스템 콜의 예시
- 입력 파일 이름 획득
- 화면에 프롬프트 출력
- 입력 받아들임
- 출력 파일 이름 획득
- 화면에 프롬프트 출력
- 입력 받아들임
- 입력 파일 열기
- 파일이 존재하지 않을 경우, 비정상적으로 종료
- 출력 파일 생성
- 파일이 존재할 경우, 비정상적으로 종료
- 루프
- 입력 파일로부터 읽어 들임
- 읽기가 실패할 때까지
- 출력 파일 닫기
- 화면에 완료 메시지 출력
- 정상적으로 종료
- 프롬프트 : 사용자와 시스템 간의 상호작용을 도와주는 중요한 요소입니다. 컴퓨터 시스템에서 사용자에게 명령어 입력을 기다리는 상태를 나타내는 문자열입니다. 쉘(Shell)이나 터미널 프로그램에서 사용자가 명령어를 입력할 수 있도록 대기 상태에서 명령어를 입력할 수 있도록 안내해주는 문자열이라고 할 수 있습니다. 프롬프트는 사용자가 시스템과 대화할 수 있는 창구 역할을 하며, 명령어를 입력하면 시스템이 해당 명령어를 처리하고 결과를 출력합니다.
2. 응용 프로그래밍 인터페이스(API : Application Programming Interface)
대부분의 응용 프로래머들은 응용 프로그래밍 인터페이스에 따라 프로그램을 설계합니다. API를 구성하는 함수들은 통상 응용 프로그래머를 대신하여 실제 시스템 콜을 호출합니다.
왜 응용 프로래머들은 실제 시스템 콜을 부르는 것보다 API에 따라 프로그래밍 하는 것을 선호하는가? 가장 중요한 이유는 프로그래밍의 호환성과 관련 있습니다. API에 따라 프로그램을 설계하는 응용 프로그래머는 자신의 프로그램이 같은 API를 지원하는 어느 시스템에서건 컴파일되고 실행된다는 것을 기대할 수 있습니다. 또한, 실제 시스템 콜은 종종 좀 더 자세한 명세가 필요하고 프로그램상에서 작업하기가 API보다 어렵습니다.
시스템 콜을 처리하는 데 있어 또 다른 중요한 요소는 실행시간 환경(RTE : Run Time Environment)입니다. RTE 중 대표적인 예시가 Java의 JVM입니다. RTE는 운영체제가 제공하는 시스템 콜에 대한 연결고리 역할을 하는 시스템 콜 인터페이스를 제공합니다. 이 시스템 콜 인터페이스는 API 함수의 호출을 가로채어 필요한 운영체제 시스템 콜을 부릅니다.시스템 콜 인터페이스는 의도하는 시스템 콜을 부르고 시스템 콜의 상태와 반환 값을 돌려줍니다.
운영체제에 매개변수를전달하기 위해서 세 가지 일반적인 방법을 사용합니다.
- 가장 간단한 방법으로 매개변수를 레지스터 내에 전달하는 방법
- 레지스터보다 더 많은 매개변수가 있을 때, 매개변수는 메모리 내의 블록이나 테이블에 저장되고, 블록의 주소가 레지스터 내에 매개변수로 전달
- 위의 방법들을 조합 -> Linux
통상적으로 매개변수가 5개 이하면 레지스터가 사용되고 넘어가면 블록 방법이 사용됩니다.
매개변수는 프로그램에 의해 스택(Stack)에 넣어질(Push) 수 있고, 운영체제에 의해 꺼내집니다(pop off).
2번의 방법이 매개변수들의 개수나 길이를 제한하지 않기 때문에 일부 운영체제에서 선호되어 집니다.
- 책에서 해당 부분을 읽을 때 제가 착각했던 것이 Java Reflection같은 Java API가 시스템 콜의 일종이라는 줄 알았던 것이었습니다. 터무니 없는 착각이었지만 이는 자바코드가 JVM을 통해 OS의 시스템 콜까지 도달하는 과정에 대한 지식이 없어서 생겼던 것 같습니다. 그래서 그 과정을 간단하게 정리해보았습니다.
Java 어플리케이션은 Java Virtual Machine (JVM)에서 실행됩니다(JVM은 RTE). JVM은 운영 체제에서 실행되는 프로그램이며, Java 어플리케이션을 해석하고 실행하는 데 필요한 기능을 제공합니다.
JNI(Java Native Interface)은 Java 어플리케이션과 네이티브 코드(C, C++ 등)를 상호작용할 수 있는 인터페이스입니다. JNI를 사용하면 Java 어플리케이션에서 네이티브 코드를 호출하거나 네이티브 코드에서 Java 객체를 사용할 수 있습니다.
Java 어플리케이션이 네이티브 코드를 호출하면, JNI는 해당 함수를 찾아 호출합니다. 이때 네이티브 함수는 C/C++ 형식으로 작성되며, 호출되는 시스템 콜은 운영 체제에서 제공하는 것입니다.
운영 체제에서 시스템 콜을 처리하면, 해당 함수는 커널 모드로 전환됩니다. 이때, 사용자 모드에서 커널 모드로 전환됩니다. 사용자 모드는 애플리케이션 코드가 실행되는 모드이며, 커널 모드는 운영 체제 코드가 실행되는 모드입니다.
시스템 콜이 완료되면, 운영 체제는 결과를 반환합니다. JNI는 반환된 결과를 Java 어플리케이션으로 다시 전달합니다.
따라서, Java 어플리케이션에서 시스템 콜을 호출하면, JNI가 해당 함수를 호출하고, 네이티브 함수는 C/C++ 형식으로 작성되며, 해당 시스템 콜은 운영 체제에서 처리되며 결과는 Java 어플리케이션으로 반환됩니다.
3. 시스템 콜의 유형(Types of System Calls)
시스템 콜은 다섯 가지의 중요한 범주로 묶을 수 있습니다.
- 프로세스 제어
- 파일 조작
- 장치 조작
- 정보 유지 보수
- 통신과 보호
각 범주에 대한 시스템 콜은 아래와 같습니다.
- 프로세스 제어(Process Control)
fork() : 현재 프로세스를 복제하여 새로운 프로세스를 생성합니다.
exec() : 새로운 프로세스를 실행하며, 현재 프로세스를 종료합니다.
wait() : 자식 프로세스가 종료될 때까지 기다리며, 자식 프로세스의 종료 상태를 반환합니다.
exit() : 현재 프로세스를 종료합니다.
- 파일 제어(File Control)
open() : 파일을 열고 파일 디스크립터를 반환합니다.
close() : 파일 디스크립터를 닫습니다.
read() : 파일에서 데이터를 읽어옵니다.
write() : 파일에 데이터를 씁니다.
- 장치 제어(Device Control)
ioctl() : 장치의 동작을 제어합니다.
- 정보 유지(Information Maintenance)
getpid() : 현재 프로세스의 ID를 반환합니다.
getppid() : 현재 프로세스의 부모 프로세스 ID를 반환합니다.
getuid() : 현재 사용자의 ID를 반환합니다.
getgid() : 현재 그룹의 ID를 반환합니다.
- 통신(Communication)
socket() : 소켓을 생성합니다.
connect() : 소켓을 연결합니다.
send() : 데이터를 송신합니다.
recv() : 데이터를 수신합니다.
4. 시스템 서비스
시스템 서비스는 시스템 유틸리티(System Utility)로도 알려진 프로그램 개발과 실행을 위해 더 편리한 환경을 제공합니다. 이들은 다음 몇 가지 범주로 분류할 수 있습니다.
- 파일 관리 : 파일과 디렉토리를 생성, 삭제, 복사, 개명(rename), 인쇄, 열거, 조작합니다.
- 상태 정보 : 어떤 프로그램들은 단순히 시스템에게 날짜, 시간, 사용 가능한 메모리와 디스크 공간의 양, 사용자 수, 혹은 이와 비슷한 상태 정보를 묻습니다. 또 어떤 프로그램들은 더 복잡하여 상세한 성능, 로깅 및 디버깅 정보를 제공합니다. 몇몇 시스템은 환경 설정 정보를 저장하고 검색할 수 있는 등록기능을 지원하기도 합니다.
- 파일 관리 : 디스크나 다른 저장 장치에 저장된 파일의 내용을 생성하고 변경하기 위해 다순의 문장 편집기(text editor)를 사용할 수 있습니다. 파일의 내용을 검색하거나 변환하기 위한 특수 명령어가 제공되고 합니다.
- 프로그래밍언어지원 : 일반적인 프로그래밍 언어들(C, Python, Java)에 대한 컴파일러, 어셈블러, 디버거 및 해석기가 종종 운영체제와 함께 사용자에게 제공되거나 별도로 다운받을 수 있습니다.
- 프로그램 적재와 수행 : 시스템은 어셈블 혹은 컴파일된 프로그램을 메모리에 적재하기 위한 절대 로더(absolute loader), 재배치 가능 로더(relocatable loader), 링키지 에디터(linkage editor)와 중첩 로더(overlay loader) 등을 제공할 수 있습니다.
- 통신 : 프로세스, 사용자, 다른 컴퓨터 시스템들 사이에 가상 접속을 이루기 위한 기법을 제공합니다.
- 백그라운드 서비스 : 항상 실행되는 시스템 프로그램 프로세느는 서비스, 서브시스템, 또는 디먼(Daemon)으로 알려져 있습니다. 이 서비스가 사용되는 예로는 운영체제가 중요한 활동을 커널 모드가 아니라 유저 모드에서 실행해야 하는 경우, 디먼을 이용해서 이 작업을 수행할 수 있습니다.
대부분의 운영체제는 시스템 프로그램과 함께 일반적인 문제를 해결하거나 연산을 수행하는 데 유용한 응용 프로그램들을 제공합니다. 이러한 응용 프로그램에는 웹브라우저, 워드프로세서와 텍스트 포맷터(text formatter), 스프레드시트, 데이터베이스 시스템, 컴파일러, 도면 제작 그리고 통계분석 패키지, 그리고 게임 등이 포함됩니다.
5. 링커와 로더(Linkers and Loaders)
프로그램은 디스크에 이진 파일(ex : a.out, prog.exe, 소스 파일이 컴파일러에 의해 변환된 형태)로 존재합니다. CPU에서 해당 프로그램을 실행하려면 메로리로 가져와 프로세스 형태로 배치되어야 합니다. 소스 파일은 임의의 물리 메모리 위치에 적재되도록 설계된 오브젝트 파일로 컴파일 됩니다. 이러한 형식을 재배치 가능 오브젝트 파일이라고 합니다. 링커는 이러한 재배치 가능 오브젝트 파일을 하나의 이진 실행 파일로 결합합니다. 로더는 이진 실행 파일을 메모리에 적재하는데 사용되며, 이 파일은 CPU 코어에서 실행할 수 있는 상태가 됩니다. 링크 및 로드와 관련된 활동은 재배치로, 프로그램에 최종 주소를 할당하고 프로그램 코드와 데이터를 해당 주소와 일치하도록 조정하여 프로그램이 실행될 때 코드가 라이브러리 함수를 호출하고 변수에 접근할 수 있게 합니다.
링커
링커는 컴파일된 여러 소스 코드 파일을 하나의 실행 가능한 프로그램으로 결합하는 데 사용됩니다. 보통, 하나 이상의 소스 코드 파일을 컴파일한 후에, 그 파일들은 개별적인 오브젝트 파일로 생성됩니다. 이 때, 링커는 이러한 오브젝트 파일들을 하나의 실행 가능한 파일로 결합하는데 필요한 링크 작업을 수행합니다. 링크 작업은 코드, 데이터, 라이브러리 및 기타 리소스를 함께 결합하고, 각각의 메모리 주소를 결정하며, 실행 파일을 생성합니다.
로더
로더는 실행 파일을 메모리에 로드하고 실행하는 데 사용됩니다. 실행 파일은 디스크에 저장되어 있으며, 실행되기 전에 메모리에 로드되어야 합니다. 로더는 실행 파일을 디스크에서 읽어 메모리에 로드하고, 필요한 초기화 작업을 수행한 후에 프로그램의 실행을 시작합니다. 또한, 로더는 동적 연결 라이브러리(Dynamic Link Libraries, DLL)와 같은 외부 라이브러리를 로드하여 사용할 수 있습니다. 이를 통해, 다른 프로그램에서 공유하거나, 재사용 가능한 코드나 리소스를 공유할 수 있습니다.
링커와 로더는 소스 코드 파일과 실행 파일 사이의 다리 역할을 합니다. 링커는 여러 소스 코드 파일을 하나의 실행 가능한 파일로 결합하는데 사용되며, 로더는 실행 파일을 메모리에 로드하여 프로그램의 실행을 시작합니다.
명령어 라인에 실행 파일의 이름을 입력하기만 하면 로더가 실행된다.
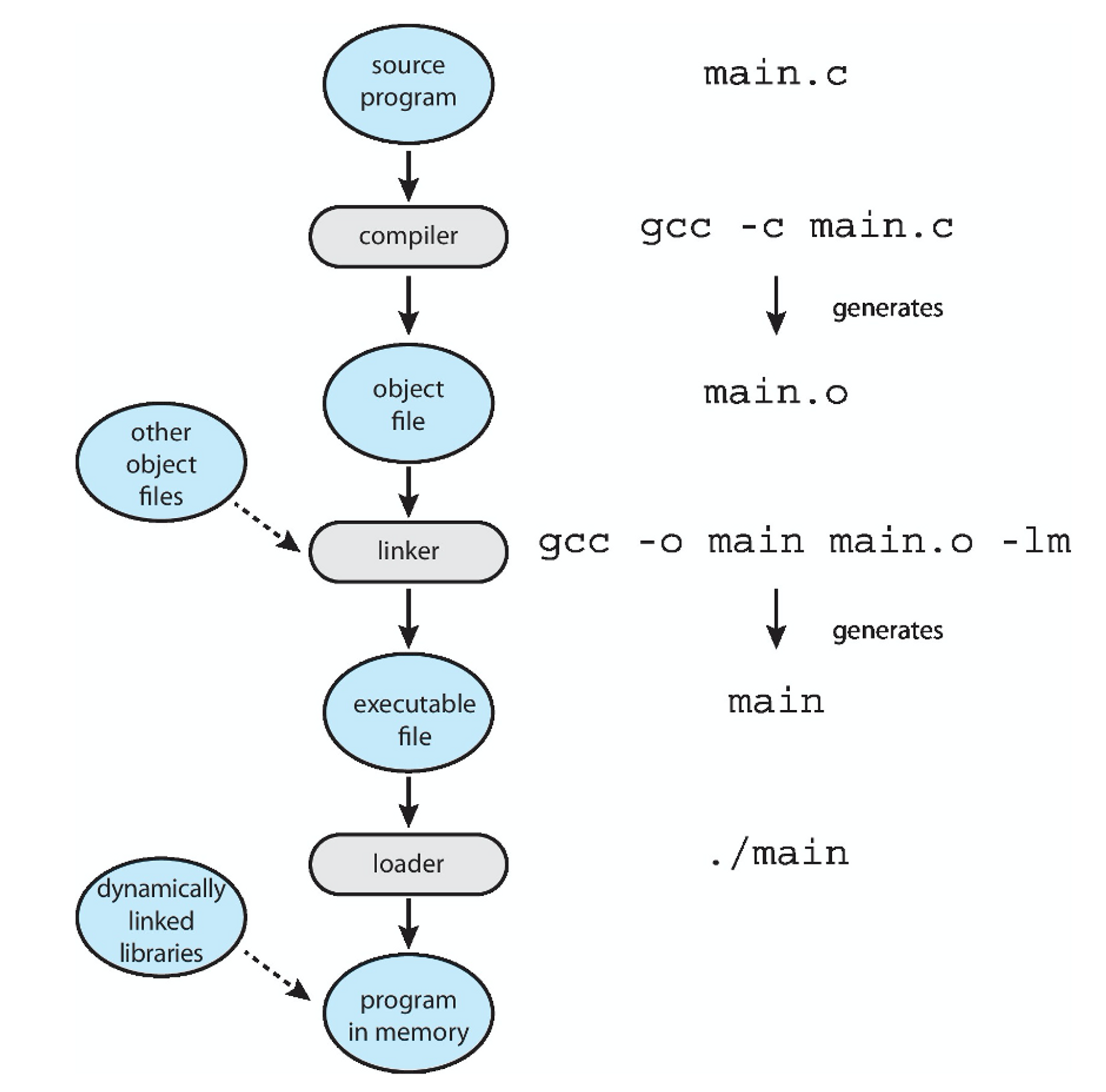
UNIX 시스템에서의 과정
1. Shell은 fork() 시스템 콜을 사용하여 프로그램을 실행하기 위한 새 프로세스를 생성합니다.
2. Shell은 exec() 시스템 콜로 로더를 호출하고 exec()에 실행 파일 이름을 전달합니다.
3. 로더는 새로 생성된 프로세스의 주소 공간을 사용하여 지정된 프로그램을 메모리에 적재합니다.
- GUI 인터페이스를 사용하는 경우 실행 파일과 연관된 아이콘을 더블 클릭하면 유사한 메커니즘을 통해 로더가 호출됩니다.
표준 형식이란 컴파일된 기계 코드 및 프로그램에서 참조되는 함수 및 변수에 대한 메타데이터(데이터에 대한 정보를 설명하는 데이터, 데이터의 속성, 구조, 관계를 기술하는 데이터)를 포함하는 기호 테이블을 포함하는 개념입니다. 오브젝트 파일 및 실행 파일은 일반적으로 표준 형식을 가집니다. UNIX 및 Linux 시스템의 경우 이 표준 형식을 ELF(Executable and Linkable Format)라고 합니다. 재배치 가능 파일과 실행 파일 각각을 위한 별도의 ELF형식이 사용됩니다. 실행 가능 파일의 ELF 파일의 정보 중 하나는 프로그램의 시작접이며, 프로그램을 실행할 때 실행할 첫 번째 명령어의 주소가 저장되어 있습니다. Windows 시스템은 PE(Portable Executable) 형식이고 macOS는 Mach-O 형식을 사용합니다.
6. 응용 프로그램이 운영체제마다 다른 이유
각 운영체제는 고유한 시스템 콜 집합을 제공합니다. 시스템 콜은 응용 프로그램이 사용할 수 있도록 운영체제가 제공하는 서비스 집합의 일부입니다. 운영체제마다 시스템 콜이 완전히 같지 않을 뿐더러 다른 장벽으로 인해 응용 프로그램을 다른 운영체제에서 실행하기 어렵습니다. 그러나 동일한 응용 프로그램을 서로 다른 운영체제서 사용한 경험이 있을 것입니다. 이는 흔히 크로스 플랫폼이라 불립니다. 다음과 세 가지 방법 중 하나로 가능합니다.
1. 플랫폼으로 부터 독립적인 언어나 프레임워크 사용
가장 일반적인 방법 중 하나는 플랫폼 독립적인 언어나 프레임워크를 사용하는 것입니다. 이 방법을 사용하면 응용 프로그램의 소스 코드를 한 번 작성하고, 다양한 운영체제에서 실행할 수 있습니다.
예를 들어, 자바 언어는 플랫폼 독립적인 언어입니다. 자바로 작성된 응용 프로그램은 자바 가상 머신(JVM)을 통해 다양한 운영체제에서 실행될 수 있습니다. 또한, .NET 프레임워크는 Windows 운영체제에서 실행되는 응용 프로그램을 작성하기 위한 플랫폼 독립적인 프레임워크입니다.
플랫폼 독립적인 언어나 프레임워크를 사용하는 경우, 응용 프로그램의 실행 속도가 느릴 수 있고, 언어나 프레임워크에 의존성이 있을 수 있습니다.
2. 운영체제별로 컴파일하여 배포
두 번째 방법은 각 운영체제별로 응용 프로그램을 컴파일하여 배포하는 것입니다. 이 방법은 각 운영체제에 맞는 실행 파일을 별도로 생성하여 배포하므로, 운영체제에 대한 의존성을 줄일 수 있습니다.
예를 들어, C++ 언어는 운영체제에 따라 컴파일되는 라이브러리를 사용하여 응용 프로그램을 작성할 수 있습니다. 이 방법을 사용하면 응용 프로그램을 각 운영체제별로 컴파일하여 배포할 수 있으며, 각 운영체제에 맞게 최적화된 실행 파일을 제공할 수 있습니다.
운영체제별로 컴파일하여 배포하는 경우, 각 운영체제별로 별도의 실행 파일을 생성해야 하므로, 유지보수 비용이 증가할 수 있습니다.
3. 가상화 기술 사용
세 번째 방법은 가상화 기술을 사용하는 것입니다. 가상화 기술은 하나의 시스템에서 여러 개의 가상 시스템을 생성하여 각각 다른 운영체제를 설치하고 실행할 수 있게 해줍니다.
예를 들어, VirtualBox나 VMware와 같은 가상화 소프트웨어를 사용하면 Windows 운영체제에서 Linux나 macOS와 같은 다른 운영체제를 가상으로 실행할 수 있습니다. 이 방법을 사용하면 응용 프로그램이 다른 운영체제에서 실행되는 것처럼 보일 수 있습니다.
가상화 기술을 사용하는 경우, 하드웨어 자원을 공유하므로, 응용 프로그램의 실행 속도가 느려질 수 있습니다. 또한, 가상화 소프트웨어를 사용하는 경우 추가적인 비용이 들 수 있습니다.
각각의 방법은 장단점을 가지고 있습니다. 그러나 이러한 방법들이 있더라도 여전히 크로스 플랫폼 응용 프로그램을 개발하는 것은 어려운 작업입니다. 아이폰의 iOS와 Android가 제공하는 API가 달라 호환이 되지 않는 경우가 있습니다. 이 뿐만 아니라 시스템의 Low level에서 다른 어려운 점들도 존재합니다.
- 각 운영체제는 헤더, 명령어 및 변수의 배치를 강제하는 응용 프로그램 이진 형식이 있습니다. 이러한 구성요소는 명시된 구조 형태로 실행 파일 내의 특정 위치에 있어야 운영체제가 파일을 열고 응용 프로그램을 적재하여 올바르게 실행할 수 있습니다.
- CPU는 다양한 명령어 집합을 가지며 해당 명령어가 포함된 응용 프로그램만 올바르게 실행할 수 있습니다.
- 운영체제는 응용 프로그램이 다양한 활등을 요청할 수 있는 시스템 콜을 제공합니다. 이러한 시스템 콜은 여러 측면에서 운영체제마다 다릅니다.
위의 세 가지 구조적 문제점을 완벽히 해결하지는 못했지만 도움이 되는 몇 가지 방법들이 있습니다.
그 중 하나가 위에서 설명했던 ELF형식(UNIX, Linux의 표준 형식)입니다. ELF는 플랫폼에 독립적인 기계어 코드를 지원하며, 이식성이 높은 이진 파일을 생성할 수 있습니다. 이러한 이진 파일은 운영체제별로 별도의 컴파일이 필요하지 않고, 여러 운영체제에서 실행할 수 있습니다. 또한 ELF는 코드, 데이터, 심볼, 리눅스 커널에서 필요로 하는 다양한 섹션 정보 등 다양한 메타데이터를 포함하고 있습니다. 이러한 메타데이터는 응용 프로그램의 실행 환경과 상호작용하는데 필요한 정보를 포함하고 있습니다.
또 다른 방법으로는 ABI(Application Binary Interface)가 있습니다. ABI(Application Binary Interface)는 응용 프로그램과 운영체제 간의 이식성을 보장하기 위한 인터페이스 규격입니다. ABI는 응용 프로그램과 운영체제 간의 인터페이스를 규정하여, 응용 프로그램이 여러 운영체제에서 실행될 때 발생할 수 있는 구조적인 차이점을 최소화합니다. ABI는 하드웨어 아키텍처, 시스템 호출 규약, 데이터 타입 등 다양한 요소를 포함하고 있습니다.ABI를 사용하면 응용 프로그램이 여러 운영체제에서 실행될 때 발생할 수 있는 구조적 문제점을 어느 정도 해결할 수 있습니다. 하지만, ABI는 운영체제마다 다르게 적용되며, 이식성을 보장하지는 않습니다. 또한, ABI 규격에 따라 작성된 코드는 해당 운영체제에서만 실행될 수 있으므로, 이식성을 확보하려면 다른 운영체제에서도 실행될 수 있는 코드를 작성해야 합니다. 따라서, ABI는 하나의 응용 프로그램이 여러 운영체제에서 실행할 때 발생할 수 있는 구조적 문제점을 일부 해결할 수 있지만, 완벽한 해결책은 아닙니다.
7. 운영체제 설계 및 구현
1. 설계 목표
- 사용자 목적으로서 충족해야 하는 요구사항
-
쉬운 사용성: 사용자는 운영체제를 쉽게 사용할 수 있어야 합니다. 이를 위해 운영체제는 직관적이고 간편한 사용자 인터페이스를 제공해야 합니다.
-
높은 신뢰성: 사용자는 운영체제가 안정적이고 오류없이 동작하는 것을 기대합니다. 따라서 운영체제는 고장나지 않고 안정적으로 동작해야 합니다.
-
높은 보안성: 사용자의 개인정보나 시스템 자원에 대한 보호가 필요합니다. 운영체제는 불법적인 접근을 차단하고, 데이터 무결성과 기밀성을 보장해야 합니다.
- 시스템 목적으로서 충족해야 하는 요구사항
자원 할당: 운영체제는 하드웨어 자원을 효율적으로 관리하여 여러 응용 프로그램이 동시에 실행될 수 있도록 자원을 할당합니다. 이를 위해 운영체제는 CPU, 메모리, 입출력장치 등의 자원을 관리하고 할당하는 기능이 필요합니다.
-
자원 보호: 시스템 자원은 여러 응용 프로그램에서 공유되므로, 한 응용 프로그램에서 잘못된 조작으로 인해 시스템 전체에 영향을 미칠 수 있습니다. 따라서 운영체제는 자원의 보호 기능을 제공하여, 응용 프로그램이 시스템 전체를 손상시키는 것을 막습니다.
-
자원 공유: 운영체제는 여러 응용 프로그램이 하나의 자원을 공유할 수 있도록 지원합니다. 이를 위해 운영체제는 자원의 공유 기능을 제공하며, 자원을 효율적으로 사용할 수 있도록 합니다.
-
시스템 성능 향상: 운영체제는 시스템의 성능을 최대화하기 위해 여러 기능을 제공합니다. 예를 들어, 프로세스 스케줄링, 메모리 관리, 입출력 제어 등의 기능을 제공하여 시스템의 성능을 향상시킵니다.
운영체제는 사용자와 시스템 모두에게 중요한 역할을 수행하며, 이를 위해 운영체제는 사용자 목적과 시스템 목적 모두를 고려한 설계를 필요로 합니다. 사용자와 시스템 간의 상충하는 요구사항이 있기 때문에, 운영체제 설계는 항상 타협의 과정을 거쳐야 합니다.
예를 들어, 사용자는 쉬운 사용성과 높은 신뢰성을 요구하지만, 이를 위해 시스템 자원을 과도하게 사용하면 시스템 성능이 저하됩니다. 따라서 운영체제는 쉬운 사용성과 높은 신뢰성을 보장하면서도, 시스템 자원의 효율적인 사용을 지원해야 합니다.
또한, 운영체제는 하드웨어의 발전과 함께 지속적으로 발전해야 합니다. 새로운 기술이나 하드웨어가 도입될 때마다 운영체제는 이를 지원하도록 업데이트되어야 합니다.
마지막으로, 운영체제는 다양한 응용 분야에 대해 지원이 가능해야 합니다. 예를 들어, 데스크톱 운영체제는 일반 사용자를 대상으로 하며, 서버 운영체제는 서버 시스템에서 사용됩니다. 따라서 운영체제는 여러 분야에서 사용될 수 있도록 다양한 기능을 제공해야 합니다.
2. 기법과 정책
운영체제를 설계하는데 있어서 가장 중요한 원칙은 기법(mechanisms)과 정책(policies)을 분리하는 것입니다. 기법과 정책을 분리하는 것은 시스템의 유연성을 높이고, 재사용성을 높이기 위해 중요합니다. 이를 통해 시스템의 기술적인 세부 사항과 비즈니스 규칙을 분리함으로써 기술적인 변경이 비즈니스 규칙에 미치는 영향을 최소화 할 수 있습니다. 즉, 기술적인 문제가 발생하더라도 비즈니스 규칙이 변경되지 않도록 보장할 수 있습니다.
-
기법(mechanisms)
영체제에서 사용되는 동작 방식에 대한 구체적인 구현을 의미합니다. 이는 하드웨어의 세부 구조와 관련이 있으며, 시스템 자원을 관리하고 보호하는 데 사용됩니다. 예를 들어, 메모리 관리와 같은 기본적인 자원 관리 기능, 프로세스 스케줄링, 인터럽트 처리, 동기화 등의 기능이 메커니즘으로 구현됩니다. 이러한 메커니즘은 운영체제의 동작 방식을 결정하며, 정확하고 안정적인 동작을 보장합니다. -
정책(policies)
정책은 운영체제에서 메커니즘을 사용하여 제공되는 서비스를 사용하는 방법을 결정하는 일련의 규칙을 의미합니다. 정책은 일반적으로 사용자나 응용 프로그램의 요구 사항에 따라 결정됩니다. 예를 들어, 프로세스 스케줄링에서 우선순위 결정, 메모리 할당 정책, 파일 시스템에서의 캐싱 방식 등이 있습니다. 이러한 정책은 운영체제의 성능, 사용성 및 신뢰성에 직접적인 영향을 미치며, 사용자 및 응용 프로그램의 요구에 따라 적절하게 조정되어야 합니다.
하지만, 이 둘을 완전히 분리하는 것은 불가능합니다. 기술적인 기법은 비즈니스 정책을 구현하고, 정책은 기술적인 기법의 사용을 결정합니다. 따라서 기술적인 기법과 비즈니스 정책은 결합되어 있습니다.
그러나 기술적인 기법과 비즈니스 정책을 분리함으로써 시스템을 더욱 유연하고 재사용 가능하게 만들 수 있습니다. 정책과 기법을 분리하면 기술적인 문제가 발생하더라도 비즈니스 규칙에 미치는 영향을 최소화할 수 있으며, 새로운 정책을 구현하기 위해 기술적인 기법을 쉽게 교체할 수 있습니다. 이러한 이점으로 인해, 기술적인 기법과 비즈니스 정책을 분리하는 것이 중요하다고 할 수 있습니다.
3. 구현
운영체제의 구현은 크게 두 가지 방법이 있습니다. 첫 번째는 운영체제를 하드웨어에 직접 구현하는 것이고, 두 번째는 운영체제를 가상화 기술을 사용하여 호스트 운영체제 위에 실행하는 것입니다.
하드웨어 자체에 구현하는 방법
이 경우에는 하드웨어에 운영체제가 탑재되어 있기 때문에 성능이 뛰어나고, 안정적입니다. 하지만 하드웨어에 직접 구현하는 방식은 하드웨어의 종류에 따라 운영체제도 종류별로 따로 개발해야 하기 때문에 유연성이 떨어집니다. 또한, 운영체제를 하드웨어에 직접 구현하는 경우 유지보수 및 업그레이드 작업이 매우 어려울 수 있습니다.
가상화 기술을 사용하여 운영체제를 호스트 운영체제 위에서 실행하는 방법
이 경우에는 호스트 운영체제가 하드웨어에 직접 구현되어 있으므로, 호스트 운영체제를 바꾸지 않는 이상 운영체제를 개발하는데 있어서는 더욱 유연하게 작업할 수 있습니다. 또한, 가상화 기술을 이용하여 여러 운영체제를 실행할 수 있기 때문에 하나의 시스템에서 다양한 운영체제를 사용할 수 있습니다. 하지만, 가상화 기술을 사용하는 경우에는 성능이 떨어질 수 있고, 가상화 소프트웨어와 호스트 운영체제 간의 호환성 문제가 발생할 수 있습니다.
운영체제 구현에는 여러 구성 요소가 포함됩니다. 가장 기본적인 구성 요소는 커널(kernel)이며, 커널은 시스템의 핵심 부분으로, 프로세스 관리, 메모리 관리, 파일 시스템 관리 등의 기능을 수행합니다. 또한, 시스템 콜(System Call)이나 장치 드라이버(Device Driver) 등의 하위 시스템이 포함될 수 있습니다. 이러한 구성 요소는 운영체제의 목적에 따라 다르게 구현될 수 있습니다.
운영체제 구현은 사용하는 프로그래밍 언어에 따라 달라질 수 있습니다. 운영체제를 구현하는 언어는 다양한데, 저 수준 언어인 어셈블리어나 C와 같은 언어로 구현하는 방식과 고수준 언어인 C++ 또는 Java와 같은 언어로 구현하는 방식이 있습니다.
저 수준 언어로 구현할 때 장단점
장점
- 하드웨어를 직접 다룰 수 있기 때문에 성능이 높아질 수 있습니다.
- 코드 크기가 작아져 메모리 사용량이 줄어들어 성능에 이점이 있습니다.
- 어셈블리어로 구현할 경우, 컴파일러가 필요하지 않기 때문에 운영체제를 구동하는데 필요한 부트로더(bootloader)의 크기를 줄일 수 있습니다.
단점
- 하드웨어를 직접 다루기 때문에 구현이 복잡해지고 디버깅이 어렵습니다.
- 새로운 하드웨어를 지원하기 위해서는 많은 수정 작업이 필요합니다.
- 소스 코드의 이식성이 떨어지기 때문에 특정 플랫폼에서만 동작하도록 만들어져야 합니다.
고 수준 언어로 구현할 때 장단점
장점
- 개발 속도가 빠르고 코드의 가독성이 높아져 유지보수가 쉽습니다.
- 운영체제의 구현 과정에서 발생하는 버그가 줄어들기 때문에 안정성이 높아집니다.
- 하드웨어를 직접 다룰 수 없기 때문에 특정 플랫폼에서만 동작하는 문제가 발생하지 않습니다.
단점
- 하드웨어를 직접 다룰 수 없기 때문에 성능이 떨어질 수 있습니다.
- 코드 크기가 커져서 메모리 사용량이 늘어납니다.
- 언어나 컴파일러 자체에 버그가 있을 수 있습니다.
8. 운영체제 구조
운영체제의 구성요소들이 어떤 방법으로 상호 연결되고 하나의 커널로 결합되는지는 운영체제의 구조에 따라 다를 수 있습니다.
1. 모놀리식 구조(Monolithic Structure)
모놀리식 구조는 운영체제를 설계하는 일반적인 기술입니다. 커널의 모든 기능을 단일 주소 공간에서 실행되는 단일 정적 이진 파일에 넣는 것입니다. 운영체제의 전체 기능을 하나의 단일한 모듈로 구현하는 구조입니다. 이는 전통적인 운영체제 구조 중 가장 간단하고 직관적인 방법 중 하나이며, 초기에는 주로 사용되었습니다.
모놀리식 구조에서는 모든 서비스와 기능이 하나의 실행 파일로 구현되며, 이 실행 파일은 시스템의 최초 부팅 시에 메모리에 적재됩니다. 이후에는 이 실행 파일이 운영체제의 모든 기능을 담당하며, 사용자와 하드웨어 간의 인터페이스를 담당합니다.
모놀리식 구조의 가장 큰 장점은 구현이 간단하다는 것입니다. 모든 기능이 하나의 모듈에 구현되어 있기 때문에, 각각의 모듈 사이의 인터페이스나 호출에 대한 오버헤드가 적습니다. 또한, 운영체제의 크기와 복잡도가 작기 때문에 메모리 사용량이 적고, 작은 시스템에서도 운영체제를 구현할 수 있습니다.
하지만 모놀리식 구조의 단점도 있습니다. 모놀리식 구조에서는 모든 기능이 하나의 모듈에 구현되어 있기 때문에, 한 부분에서 오류가 발생하면 전체 시스템이 영향을 받을 수 있습니다. 또한, 운영체제의 기능이 복잡해지고 크기가 커질수록 관리가 어려워지고 유지보수 비용이 증가합니다.
따라서 현재는 모놀리식 구조보다는 마이크로커널 구조나 모듈화 구조와 같은 다른 구조가 주로 사용됩니다.
2. 계층적 접근(Layerd Approach)
모놀리식 구조는 한 부분에 대한 변경이 광범위하게 영향을 술주 있기 때문에 밀접하게 접근된 시스템으로 불립니다. 그 대안으로는 느슨하게 결합된(Loosely Coupled) 시스템이 있습니다.
운영체제 구조 중 계층적 접근는 기능별로 계층을 나누어 구조화하는 방식을 말합니다. 이 방식은 모놀리식 구조와는 다르게 각 계층이 서로 분리되어 있어서 유지보수와 확장성이 용이하다는 장점을 가지고 있습니다.
보통 계층적 접근에서는 각 계층이 하나의 모듈로 구현되며, 상위 계층이 하위 계층에 정의된 서비스를 호출하는 방식으로 동작합니다. 이렇게 각 계층이 독립적인 모듈로 분리되어 있기 때문에, 한 계층에서 변경이 발생해도 다른 계층에는 영향을 미치지 않아 전체 시스템의 안정성을 유지할 수 있습니다.
계층적 접근의 각 계층은 기능에 따라 분리되어 있으며, 보통 가장 하위 계층에는 하드웨어와 직접적으로 상호작용하는 모듈이 위치합니다. 상위 계층으로 올라갈수록 추상화 수준이 높아지며, 각 계층에서는 이전 계층에서 제공한 서비스를 기반으로 자체적으로 기능을 구현합니다. 각 계층의 역할은 아래와 같습니다.
-
하드웨어 추상화 계층: 시스템의 하드웨어 자원에 직접적으로 접근하여 하드웨어를 추상화한 모듈입니다. 하드웨어 추상화 계층은 하드웨어와 소프트웨어 간의 인터페이스 역할을 수행합니다.
-
기본 서비스 계층: 하드웨어 추상화 계층에서 제공한 하드웨어 기능을 사용하여 프로세스 관리, 메모리 관리, 파일 시스템 등의 기본적인 서비스를 제공하는 모듈입니다.
-
유틸리티 계층: 기본 서비스 계층에서 제공하는 서비스를 기반으로, 사용자와 관리자가 시스템을 효율적으로 관리할 수 있는 유틸리티를 제공하는 모듈입니다.
-
응용 프로그램 계층: 사용자가 직접 사용하는 응용 프로그램을 위한 계층입니다. 응용 프로그램은 유틸리티 계층에서 제공하는 서비스를 사용하여 동작합니다.
계층적 접근의 장점은 다음과 같습니다.
-
모듈화: 레이어 구조에서는 각 레이어가 서로 독립적으로 작동하므로, 시스템의 특정 부분을 수정하거나 대체하는 작업이 용이합니다. 이는 유지 보수 및 확장성 측면에서 중요한 이점을 제공합니다.
-
추상화: 각 레이어는 하위 레이어에서 제공되는 서비스를 기반으로 작동하므로, 레이어 간의 인터페이스를 통해 서로 다른 기술을 쉽게 통합할 수 있습니다. 이는 시스템의 모듈화와 확장성을 높이는데 도움을 줍니다.
-
유연성: 레이어 구조는 필요에 따라 새로운 레이어를 추가하거나 기존 레이어를 삭제할 수 있으므로, 시스템을 쉽게 수정하거나 재구성할 수 있습니다. 이는 시스템의 요구 사항이나 환경의 변화에 대응할 수 있는 유연성을 제공합니다.
-
안정성: 각 레이어는 독립적으로 작동하므로, 하위 레이어에서 오류가 발생해도 상위 레이어는 영향을 받지 않습니다. 이는 시스템의 안정성을 높이는데 도움을 줍니다.
그러나 레이어드 구조 또한 높은 오버헤드와 느린 처리 속도, 복잡성과 새로운 기술 도입에 대한 제약 등의 단점으로 인해 최근에는 사용되지 않습니다.
3. 마이크로커널(Microkernels)
초기 UNIX는 모놀리식 구조를 가지고 있었습니다. 그러나 UNIX가 확장함에 따라, 커널이 커지고 관리하기 힘들어졌습니다. 1980년대 중반에, Carnegie-Mellon대학교의 연구자들이 마이크로커널 접근 방식을 사용하여 커널을 모듈화한 Mach라 불리는 운영체제를 개발했습니다. 이 방법은 모든 중요하지 않은 구성요소를 커널로부터 제거하고, 그들을 별도의 주소 공간에 조재하는 사용자 수준 프로그램으로 구현하여 운영체제를 구성하는 것입니다.
마이크로커널의 구조는 다음과 같습니다.
-
커널 모듈 (Kernel Module): 핵심 기능만을 담당하는 최소한의 기능을 제공하는 모듈입니다. 주로 프로세스 관리, 메모리 관리, 입출력 관리 등의 핵심 기능을 수행합니다.
-
서버 모듈 (Server Module): 커널 모듈에서 제공하지 않는 기능들을 제공하는 서버 모듈입니다. 주로 파일 시스템, 네트워크 서비스, 유저 인터페이스 등의 기능을 수행합니다.
-
유저 모듈 (User Module): 마이크로커널의 기능 외에 추가적인 서비스를 제공하는 유저 모듈입니다. 주로 응용 프로그램이나 시스템 유틸리티 등을 수행합니다.
마이크로커널의 장점은 다음과 같습니다.
-
안정성: 마이크로커널은 커널 모듈의 크기를 최소화하여 안정성을 높이고, 유저레벨의 서버 모듈에서 다양한 기능들을 제공합니다. 이로 인해 커널의 오류나 충돌 등이 발생해도, 시스템 전체가 영향을 받는 것을 막을 수 있습니다.
-
확장성: 마이크로커널은 서버 모듈이나 유저 모듈을 추가하거나 교체하여 시스템의 기능을 확장하거나 변경할 수 있습니다. 이로 인해 새로운 기능이 추가되거나 기존의 기능이 수정될 때, 커널 자체를 수정할 필요가 없어집니다.
-
유지보수성: 마이크로커널은 기능을 분리하여 유지보수를 용이하게 할 수 있습니다. 또한, 서버 모듈이나 유저 모듈에서 오류가 발생해도, 커널 자체가 영향을 받지 않기 때문에 유지보수가 쉽습니다.
하지만, 마이크로커널은 커널 모듈과 서버 모듈, 유저 모듈 간의 통신 오버헤드가 발생하여 성능이 저하될 수 있습니다. 또한, 마이크로커널은 구현이 복잡하고 디버깅이 어렵다는 단점이 있습니다. 커널 모듈, 서버 모듈, 유저 모듈 간의 통신 방식을 정확하게 구현해야 하며, 이로 인해 코드의 복잡성이 증가합니다. 또한, 여러 모듈 간의 상호작용으로 인한 디버깅이 어렵고 오류가 발생할 가능성이 높아집니다.
마이크로커널의 구현이 복잡하다는 문제를 해결하기 위해 많은 연구가 진행되고 있습니다. 예를 들어, 커널 모듈, 서버 모듈, 유저 모듈의 통신 방식을 단순화하거나, 통신 방식 대신 메모리 공유 등 다른 방법을 사용하는 것 등이 그 예입니다. 또한, 하이브리드 마이크로커널이나 링크드 아키텍처 등 새로운 아키텍처가 제안되어 이를 기반으로한 마이크로커널 구현도 연구되고 있습니다.
마이크로커널의 장점과 단점을 고려하여, 최근에는 하이브리드 구조를 채용한 운영체제가 많이 개발되고 있습니다. 하이브리드 구조는 마이크로커널과 모놀리식 구조를 결합한 구조로, 마이크로커널의 장점과 모놀리식 구조의 성능을 결합하여 높은 성능과 안정성을 제공합니다. 예를 들어, Windows 운영체제는 하이브리드 구조를 채용하고 있습니다.
4. 하이브리드 시스템(Hybrid Systems)
하이브리드 시스템(Hybrid System)은 모놀리식과 마이크로커널 구조의 장단점을 결합한 구조로, 운영체제의 핵심 부분은 마이크로커널로 작성하고, 시스템의 다른 부분은 모놀리식 커널로 작성하여 최적화된 성능을 보장하는 구조입니다.
하이브리드 시스템의 핵심 부분인 마이크로커널은 최소한의 기능만을 갖추고 있으며, 다른 기능들은 모놀리식 커널의 형태로 제공됩니다. 이렇게 구성된 시스템에서는 마이크로커널에서 필요한 최소한의 서비스만을 제공하고, 나머지 기능은 모놀리식 커널에서 제공되므로, 성능과 안정성을 모두 충족시킬 수 있습니다.
또한, 하이브리드 시스템은 모놀리식 커널과 마이크로커널의 구성 요소를 유연하게 조합할 수 있으므로, 시스템 구성 요소의 변경에 대한 대응이 쉽습니다. 이는 시스템의 확장성과 유연성을 높여줍니다.
하지만, 하이브리드 시스템의 구현이 복잡하며, 모놀리식 커널과 마이크로커널 간의 인터페이스를 구현하기 위해 많은 작업이 필요합니다. 또한, 이 구조는 마이크로커널의 안전성을 유지하기 위해, 시스템의 일부 기능을 모놀리식 커널로 이전해야 할 수도 있습니다. 이는 시스템 전체적인 복잡도를 높일 수 있습니다.
macOS와 iOS
macOS는 하이브리드 시스템이 아닙니다. macOS는 전통적인 모놀리식 커널 구조를 채택하고 있습니다. 바념ㄴ에 iOS는 macOS의 하이브리드 시스템인 Darwin 커널을 기반으로 하고 있지만, iOS는 보안성을 강화하기 위해 사용자 모드에서 실행되는 앱과 커널 모드에서 실행되는 OS 사이에 경계를 두어 마이크로커널과 유사한 구조를 가지고 있습니다. 따라서 iOS도 완전한 하이브리드 시스템이라 하기에는 무리가 있습니다.
Android
Android는 리눅스 기반의 운영체제로서, 리눅스 커널을 기반으로 하는 하이브리드 시스템입니다. Android는 리눅스 커널 위에 Dalvik 가상 머신과 안드로이드 프레임워크가 추가되어 하이브리드 시스템을 형성하고 있습니다.
iOS와 Android의 차이점 중 하나가 iOS는 소스가 공개되지 않은 데 반해, 안드로이드는 공개 소스로서 다양한 모바일 플랫폼에서 실행됩니다. 이 차이가 안드로이드가 빠르게 인기가 높아졌던 이유입니다.
안드로이드 장치의 소프트웨어 설계자는 Java로 응용 프로그램을 개발하지만 일반적으로 표준 Java API를 사용하지 않습니다. Google은 이를 대체하기 위해 별도의 Android API를 설계했습니다. Java 응용 프로그램은 ART(Android RunTime)에서 실행될 수 있는 형식으로 컴파일됩니다. JVM은 응용 프로그램의 효율성을 향상시키기 위해 JIT(Just-In-Time) 컴파일을 수행하는 반면, ART는 AOT(Ahead-Of-Time) 컴파일을 수행합니다. AOT 컴파일은 모바일 시스템에 중요한 기능인 전력 소비를 줄이면서 더 효율적인 응용 프로그램 실행을 가능하게 합니다.
Windows
Windows 운영체제는 초기에는 모놀리식 구조였지만, 이후에 하이브리드 구조로 발전하였습니다. Windows NT 3.1부터는 유저 모드와 커널 모드를 분리하였고, 이후의 버전에서는 하이브리드 구조로 전환하였습니다. Windows 운영체제는 커널 모드에서 하드웨어와 직접적으로 상호작용하며, 유저 모드에서는 응용 프로그램 등을 실행합니다. 또한, Windows 운영체제는 플러그인 모듈과 드라이버 등의 기능을 가진 모듈을 로드하여 사용할 수 있는 구조를 가지고 있습니다. 이러한 구조로 Windows 운영체제는 하이브리드 구조로 분류됩니다.
5. 모듈(Modules)
책의 순서상으로는 모듈이 하이브리드 시스템보다 먼저 기술되지만 편의상 순서를 바꿨습니다.
운영체제를 설계하는 데 이용되는 최근 기술 중 최선책은 적재가능 커널 모듈(LKM : Loadable kernel modules)입니다. 이러한 유형의 설계는 Linux, macOS X, Solaris, Windows 등의 현대 UNIX를 구현하는 일반적인 추세입니다.
모듈 구조는 운영 체제의 커널에 부가 기능을 추가할 수 있는 유연성을 제공하기 위한 방법 중 하나입니다. 모듈 구조에서는 운영 체제의 커널에 대한 변경 없이도 추가적인 기능을 수행할 수 있는 코드를 로드 및 언로드할 수 있습니다. 이는 운영 체제의 유연성을 향상시키면서도 안정성을 유지할 수 있는 장점을 제공합니다.
모듈 구조는 커널의 메모리 공간에 독립적으로 로드되고 언로드되는 코드 단위를 말합니다. 이를 통해 운영 체제는 필요할 때마다 추가적인 모듈을 로드하거나 불필요한 모듈을 언로드함으로써 자원을 효율적으로 사용할 수 있습니다.
모듈은 운영 체제의 커널과 밀접한 관계가 있으므로, 커널의 데이터 및 함수에 대한 액세스 권한을 가지고 있습니다. 따라서 모듈은 보안적으로 신뢰할 수 있는 소스에서 제공되어야 하며, 잘못된 모듈은 시스템의 안정성에 영향을 미칠 수 있습니다.
이해하기 어려운 부분이 "모듈과 하이브리드 시스템이 완전히 다른 것인가?" 였다.
이에 대해 좀 더 알아보고 정리하자면 다음과 같다.LKM(Loadable Kernel Modules)은 커널에 동적으로 로드 및 언로드가 가능한 기능 모듈을 의미합니다. LKM은 모놀리식 커널에서 사용되며, 운영체제의 기능을 확장하거나 커널의 특정 기능을 수정하기 위해 사용됩니다.
반면, 하이브리드 시스템은 커널 자체는 모놀리식으로 구현하되, 사용자 공간에서 동작하는 서비스와 드라이버는 유저 모드에서 실행됩니다. 이 방식은 LKM과는 다릅니다. 하이브리드 시스템에서는 서비스 및 드라이버가 유저 모드에서 실행되기 때문에, 커널과의 상호작용을 위한 인터페이스로서 시스템 콜을 사용합니다. 이로 인해, 모듈 구조가 LKM과는 다르게 설계되어 있습니다.
실제로는 많은 운영체제들이 모듈화된 커널과 함께 하이브리드 시스템을 사용하고 있습니다. 예를 들면, Linux 커널은 LKM을 사용하여 커널 기능을 확장하면서, 동시에 레이어드 구조와 같은 하이브리드 시스템 구조를 사용하여 다양한 기능을 제공합니다. 비슷하게, macOS와 iOS도 XNU 커널에 LKM을 사용하여 커널을 확장하고, 동시에 레이어드 구조를 사용하여 하드웨어 추상화와 같은 다른 기능을 제공합니다. 따라서, 현대 운영체제는 다양한 기술을 조합하여 하이브리드 시스템을 만들어 사용하고 있습니다.
연습문제
1. 시스템 콜의 목적은 무엇인가?
시스템 콜(System call)은 컴퓨터 운영 체제(OS)에서 제공하는 프로그래밍 인터페이스입니다. 시스템 콜은 사용자 프로그램이 운영 체제의 기능을 사용할 수 있도록 하는 중요한 메커니즘입니다.
운영 체제는 하드웨어 자원을 관리하고 사용자 프로그램이 실행될 때 필요한 다양한 서비스를 제공합니다. 이러한 서비스는 파일 입출력, 메모리 관리, 프로세스 관리, 네트워크 통신 등 다양합니다.
사용자 프로그램이 운영 체제의 기능을 사용하려면, 시스템 콜을 사용하여 운영 체제에 요청해야 합니다. 시스템 콜은 일반적으로 커널(Kernel)이라는 운영 체제의 핵심 부분에서 처리됩니다.
시스템 콜을 통해 사용자 프로그램은 운영 체제에 다양한 요청을 보낼 수 있습니다. 이러한 요청은 커널에서 처리되며, 처리 결과는 시스템 콜을 호출한 사용자 프로그램에 반환됩니다.
따라서 시스템 콜의 목적은 사용자 프로그램이 운영 체제의 기능을 사용할 수 있도록 하는 것입니다. 이를 통해 사용자 프로그램은 운영 체제의 다양한 기능을 활용하여 보다 다양하고 안정적인 기능을 제공할 수 있습니다.
2. 명령 인터프리터의 목적은 무엇인가? 통상 커널에 포함되지 않는 이유는 무엇인가?
명령 인터프리터(Command Interpreter)는 사용자가 명령어를 입력하면 해당 명령어를 해석하고 실행하는 프로그램입니다. 명령 인터프리터의 목적은 사용자가 운영 체제의 기능을 쉽게 사용할 수 있도록 하는 것입니다.
명령 인터프리터는 사용자가 입력한 명령어를 해석하여 해당 기능을 수행합니다. 예를 들어, "ls" 명령어를 입력하면 명령 인터프리터는 현재 디렉토리의 파일 목록을 출력합니다. 이와 같이 명령 인터프리터는 사용자가 운영 체제의 다양한 기능을 사용할 수 있도록 도와줍니다.
하지만 명령 인터프리터는 일반적으로 커널(Kernel)에 포함되지 않습니다. 이는 명령 인터프리터가 운영 체제의 일부가 아니라 독립적인 프로그램으로 동작하기 때문입니다.
또한 명령 인터프리터는 사용자와 상호작용하면서 명령어를 처리하기 때문에, 사용자와의 인터페이스와 관련된 부분을 처리해야 하며, 이는 일반적으로 운영 체제의 다른 부분과는 별개로 개발되고 유지보수되는 것이 좋습니다.
따라서 명령 인터프리터는 운영 체제와는 별개로 개발 및 유지보수되며, 일반적으로 운영 체제의 사용자 공간(User space)에서 실행됩니다.
3. UNIX 시스템에서 새 프로세스를 시작하기 위해 명령 인터프리터나 shell에서 어떤 시스템 콜이 실행되어야 하는가?
UNIX 시스템에서 새 프로세스를 시작하기 위해서는 "fork()" 시스템 콜을 실행해야 합니다. "fork()" 시스템 콜은 현재 프로세스의 복사본인 자식 프로세스(child process)를 생성합니다.
명령 인터프리터나 shell에서는 사용자가 입력한 명령어를 처리하기 위해 새로운 프로세스를 시작해야 할 때 "fork()" 시스템 콜을 호출합니다. 이때 "fork()" 시스템 콜을 호출한 프로세스는 부모 프로세스(parent process)가 되고, 새로 생성된 프로세스는 자식 프로세스(child process)가 됩니다.
부모 프로세스는 "fork()" 시스템 콜 이후에 자식 프로세스가 시작될 때까지 기다리며, 자식 프로세스는 부모 프로세스의 복사본이기 때문에 부모 프로세스와 동일한 메모리 이미지를 가지게 됩니다.
자식 프로세스는 "fork()" 시스템 콜 이후에 실행되는 코드부터 시작하며, 이를 위해 "exec()" 시스템 콜을 사용하여 새로운 프로그램을 실행할 수 있습니다. 따라서 명령 인터프리터나 shell에서는 "fork()" 시스템 콜과 "exec()" 시스템 콜을 순서대로 호출하여 새로운 프로세스를 시작합니다.
4. 시스템 프로그램의 목적은 무엇인가?
시스템 프로그램(System Program)의 목적은 컴퓨터 시스템의 자원을 관리하고, 사용자와 컴퓨터 간의 상호작용을 지원하는 것입니다. 시스템 프로그램은 운영 체제의 일부분이며, 운영 체제와 함께 설치되어 사용됩니다.
시스템 프로그램은 다양한 기능을 수행할 수 있습니다. 예를 들어, 파일 시스템을 관리하고, 디스크 공간을 할당하고, 네트워크 연결을 설정하고, 프로세스를 생성하고, 입출력 장치를 제어할 수 있습니다. 또한 시스템 프로그램은 사용자와 컴퓨터 간의 상호작용을 지원하기 위해 명령 인터프리터나 셸(Shell)을 제공하기도 합니다.
시스템 프로그램은 운영 체제의 다른 부분과 밀접하게 연관되어 있으며, 운영 체제의 자원을 효율적으로 사용하기 위해 작성됩니다. 따라서 시스템 프로그램은 다른 프로그램과는 달리 운영 체제의 권한을 가지고 실행되며, 운영 체제와 밀접한 상호작용을 수행합니다.
또한 시스템 프로그램은 컴퓨터 시스템의 안정성과 보안성을 유지하기 위해 필요합니다. 운영 체제는 다양한 프로세스와 자원을 관리하고, 다른 프로그램들이 올바르게 동작하도록 지원해야 합니다. 이를 위해 운영 체제는 시스템 프로그램을 사용하여 다양한 기능을 수행하며, 이를 통해 안정성과 보안성을 유지합니다.
5. 시스템 설계 시 계층화된 접근 방식의 주요 장점은 무엇인가? 계층화된 접근 방식의 단점은 무엇인가?
계층화된 접근 방식은 시스템을 여러 계층으로 분할하여 각 계층이 서로 분리된 기능을 수행하도록 설계하는 방식입니다.
- 장점
- 모듈성: 각 계층은 서로 독립적인 기능을 수행하므로, 시스템의 개발 및 유지보수가 쉬워집니다. 또한, 각 계층의 변경이 다른 계층에 영향을 미치지 않으므로 시스템 전체의 안정성과 신뢰성이 향상됩니다.
- 이식성: 각 계층은 서로 독립적인 인터페이스를 제공하므로, 시스템의 이식성이 높아집니다. 즉, 시스템의 일부분을 다른 시스템으로 이식할 때, 해당 계층만 수정하면 되므로 전체 시스템을 다시 작성할 필요가 없습니다.
3.유지보수성: 각 계층은 서로 독립적인 기능을 수행하므로, 시스템의 유지보수가 쉬워집니다. 즉, 각 계층의 수정이 다른 계층에 영향을 미치지 않으므로, 수정된 부분만 변경하면 됩니다.
- 단점
- 오버헤드: 각 계층은 서로 독립적인 인터페이스를 제공하므로, 각 계층 간의 통신에 대한 오버헤드가 발생할 수 있습니다.
- 복잡성: 시스템의 기능이 복잡해질수록, 계층의 수와 복잡성도 증가할 수 있습니다. 이 경우, 계층 간의 통신이 더 복잡해지며, 시스템의 전체적인 복잡도도 증가할 수 있습니다.
- 성능 저하: 계층화된 접근 방식은 각 계층 간의 통신에 대한 오버헤드가 발생할 수 있으며, 이는 시스템의 전체적인 성능을 저하시킬 수 있습니다. 특히, 대규모 시스템에서는 성능 저하가 더 심각할 수 있습니다.
6. 운영체제에서 제공하는 5가지 서비스를 나열하고 각 서비스가 사용자에게 편의를 제공하는 방법을 설명하라. 사용자 수준 프로그램이 이러한 서비스를 제공할 수 없는 경우는 언제인가?
운영체제에서 제공하는 5가지 서비스와 각 서비스가 사용자에게 제공하는 편의는 다음과 같습니다.
프로세스 관리(Process management): 운영체제는 프로세스 생성, 제거, 일시 중단, 재개 등을 관리합니다. 이를 통해 사용자는 여러 프로그램을 동시에 실행하고, 자원을 효율적으로 사용할 수 있습니다.
메모리 관리(Memory management): 운영체제는 메모리 공간을 할당하고, 프로세스 간에 메모리를 공유하는 등의 관리를 수행합니다. 이를 통해 사용자는 프로그램이 필요로 하는 메모리 공간을 확보하고, 메모리 사용량을 최적화할 수 있습니다.
파일 시스템 관리(File system management): 운영체제는 파일의 생성, 복사, 이동, 삭제 등을 관리합니다. 이를 통해 사용자는 파일을 효율적으로 관리하고, 저장된 데이터를 쉽게 찾을 수 있습니다.
입출력 장치 관리(I/O device management): 운영체제는 입출력 장치(키보드, 마우스, 프린터 등)를 관리하고, 장치 드라이버를 제공합니다. 이를 통해 사용자는 입출력 장치를 쉽게 사용할 수 있습니다.
보안 및 권한 관리(Security and permission management): 운영체제는 사용자의 로그인 및 권한 설정, 프로세스 간 권한 분리 등을 관리합니다. 이를 통해 사용자는 자신의 데이터 및 시스템 자원을 안전하게 보호할 수 있습니다.
사용자 수준 프로그램이 이러한 서비스를 제공할 수 없는 경우는, 운영체제는 커널(Kernel)이라는 특수한 프로그램으로 실행되기 때문입니다. 커널은 운영체제의 핵심 부분으로, 시스템 자원을 직접적으로 제어하고 관리합니다. 이를 통해 운영체제는 보다 안정적이고 안전한 서비스를 제공할 수 있습니다. 따라서 사용자 수준 프로그램은 운영체제의 서비스를 직접적으로 제공할 수 없으며, 운영체제의 기능을 활용하기 위해서는 시스템 콜(System call)을 사용해야 합니다.
7.일부 시스템은 운영체제를 펌웨어에 저장하고 다른 시스템은 디스크에 저장하는 이유는 무엇인가?
- 펌웨어(firmware)는 하드웨어를 제어하고 작동시키기 위한 소프트웨어의 한 종류입니다. 일반적으로 펌웨어는 ROM, EPROM, EEPROM, 플래시 메모리 등의 비휘발성 저장장치에 저장됩니다.
펌웨어는 보통 하드웨어와 소프트웨어 사이의 인터페이스 역할을 하며, 하드웨어를 초기화하고 자원을 할당하는 등의 기능을 수행합니다. 또한, 펌웨어는 운영체제를 실행시키기 위한 부트로더(bootloader)와 같은 프로그램을 포함할 수도 있습니다.
펌웨어는 하드웨어에 밀접하게 연관되어 있기 때문에 일반적으로 하드웨어 제조사가 제공합니다. 제조사는 제품의 특성에 맞게 펌웨어를 개발하고 유지보수할 수 있습니다. 펌웨어는 임베디드 시스템, 네트워크 장비, 스마트폰, 가전제품 등 다양한 분야에서 사용됩니다.
시스템이 운영체제를 펌웨어에 저장하는 주요한 이유는 다음과 같습니다.
- 성능: 펌웨어에 운영체제를 저장하면 부팅 속도가 매우 빨라집니다. 펌웨어는 컴퓨터의 전원이 켜짐과 동시에 실행되기 때문에, 디스크를 읽어오는 시간이나 다른 초기화 작업이 필요하지 않습니다. 반면, 디스크에 운영체제를 저장하면 부팅 속도가 상대적으로 느려질 수 있습니다.
- 유연성: 디스크에 운영체제를 저장하면 사용자가 필요한 만큼 운영체제를 업그레이드하거나 수정할 수 있습니다. 반면, 펌웨어에 운영체제를 저장하면 업그레이드나 수정이 더 어려울 수 있습니다.
- 보안: 펌웨어는 일반적으로 읽기 전용으로 설정됩니다. 따라서, 펌웨어에 저장된 운영체제는 외부 공격자로부터 보다 안전합니다. 반면, 디스크에 저장된 운영체제는 외부 공격자에 의해 변조될 수 있습니다.
디스크에 운영체제를 저장하는 저장하는 이유는 다음과 같습니다.
- 안정성: 펌웨어는 일반적으로 매우 안정적이며, 디스크보다 장애 발생 가능성이 낮습니다. 따라서, 펌웨어에 운영체제를 저장하면 시스템의 안정성이 더 높아질 수 있습니다.
그러나, 이러한 장단점을 고려하더라도 시스템마다 저장 장소를 결정하는 것은 그 시스템의 목적과 요구사항에 따라 달라질 수 있습니다. 예를 들어, 초소형 임베디드 시스템은 용량이 매우 작기 때문에 운영체제를 펌웨어에 저장하는 것이 적합할 수 있습니다. 반면, 서버 시스템은 대규모 데이터를 처리해야 하기 때문에 디스크에 운영체제를 저장하는 것이 더 적합할 수 있습니다.
8. 부팅할 운영체제를 선택할 수 있도록 시스템을 설계하는 방법은 무엇인가? 부트스트랩 프로그램이 해야 할 일은 무엇인가?
부팅할 운영체제를 선택할 수 있도록 시스템을 설계하기 위해서는 부트로더(Bootloader) 또는 부트매니저(Boot Manager)를 사용해야 합니다.
부트스트랩은 컴퓨터가 부팅될 때 가장 먼저 실행되는 소프트웨어로, 하드웨어를 초기화하고 부팅 가능한 장치를 검색하며, 부트로더를 실행시키기 위한 최소한의 환경을 구성합니다.
부트로더는 부트스트랩에 의해 호출되며, 하드디스크나 CD-ROM과 같은 부트 가능한 장치에서 부팅 가능한 운영체제의 커널을 로드하고 실행시킵니다. 일반적으로 부트로더는 하드디스크의 MBR(Master Boot Record)에 위치해 있습니다.
부트매니저는 다중 부팅 환경에서 사용되며, 여러 개의 운영체제 중 사용자가 원하는 운영체제를 선택하고 부팅할 수 있도록 합니다. 부트매니저는 부팅 가능한 모든 운영체제와 그에 대한 부트로더를 감지하고 선택할 수 있도록 하는 인터페이스를 제공합니다.
부트로더가 선택된 운영체제를 로드하기 위해서는 부트로더가 해당 운영체제의 부트 로더(Boot Loader)를 로드해야 합니다. 부트로더가 부트 로더를 로드한 후, 부트 로더는 운영체제 커널을 로드하고 초기화합니다.
요약하면, 부트스트랩은 컴퓨터 부팅 시 가장 먼저 실행되는 소프트웨어로, 부트로더는 부트 가능한 장치에서 운영체제를 로드하고 실행시키는 역할을 합니다. 부트매니저는 다중 부팅 환경에서 여러 운영체제를 선택하고 부팅할 수 있도록 하는 프로그램입니다. 이 세 가지 프로그램들은 서로 밀접하게 연관되어 있으며, 컴퓨터가 부팅되는 과정에서 연속적으로 실행됩니다.
부트로더의 기능은 시스템에 따라 다를 수 있지만, 보통 다음과 같은 작업을 수행합니다.
- 하드웨어 초기화: 부트로더는 하드웨어를 초기화해야 합니다. 이 과정에서, 부트로더는 하드웨어에 대한 정보를 수집하고, 하드웨어가 부팅 가능한지 확인합니다.
- 운영체제 선택: 부트로더는 사용자에게 운영체제를 선택하도록 메뉴를 제공합니다.
- 부트 로더 로드: 부트로더는 사용자가 선택한 운영체제의 부트 로더를 로드합니다.
- 운영체제 커널 로드: 부트 로더는 운영체제 커널을 로드합니다.
- 운영체제 커널 초기화: 부트 로더는 운영체제 커널을 초기화합니다.
시스템에 따라 부트로더의 기능이나 구조는 다르지만, 일반적으로 위와 같은 방식으로 동작합니다.
