-
컬렉션 : 여러 객체(데이터)를 모아놓은 것
-
프레임웍 : 표준화, 정형화 된 체계적인 프로그래밍 방식
-
라이브러리 : 만들어놓은 기능을 모아놓은 것 (기능만 제공)
컬렉션 프레임웍
- 컬렉션(다수의 객체)을 다루기 위한 표준화된 프로그래밍 방식
- 컬렉션을 쉽고, 편리하게 다룰 수 있는 다양한 클래스 제공
컬렉션 클래스
- 다수의 데이터를 저장할 수 있는 클래스 (ex : Vector, ArrayList, HashSet)
컬렉션 프레임웍의 핵심 인터페이스
List
- 순서가 있는 데이터 집합.
- 중복 허용
- 해당 인터페이스를 구현한 Class : ArrayList, LinkedList, Stack, Vector...
Set
- 순서를 유지하지 않는 데이터 집합.
- 중복 비허용
- 해당 인터페이스를 구현한 Class : HashSet, TreeSet...
Map
- 키(key), 값(value)의 쌍(pair)로 이루어진 데이터 집합.
- 순서를 유지하지 않음
- key는 중복 비허용
- value는 중복 허용
- 해당 인터페이스를 구현한 Class : HashMap(<-LinkedHashMap(순서 있는 HashMap)), TreeMap, Hashtable, Properties...
ArrayList
-
ArrayList는 기존의 Vector를 개선한 것으로, 구현 원리와 기능이 동일함.
-
Vector는 동기화 처리가 되어있고, ArrayList는 동기화 처리가 안되어있음.
-
List interface 구현 -> 저장 순서 유지되고, 중복 허용.
-
데이터의 저장 공간으로써, 배열을 사용함. (배열 기반)
-
Object[] 배열이 형성되어 있어, 모든 종류의 객체를 저장할 수 있다. (다형성)
-
ArrayList에 저장된 객체의 삭제 과정
-
list.remove(2); 호출
-
삭제할 데이터 아래의 데이터(index 3 이상)를 한 칸씩 위로 복사해서 삭제할 데이터를 덮어씀
- System.arraycopy(data, 3, data, 2, 2) : data[3]에서 data[2]로 2개의 data를 복사하라는 의미
- 해당 과정은 번거롭기 때문에, 부담을 주는 작업이다. 왠만하면 이동이 안 일어나도록 하는게 좋다.
-
데이터가 모두 한칸씩 이동했으므로, 마지막 데이터는 null로 변경
- data[size-1] = null;
-
데이터가 삭제되어, 데이터의 갯수가 줄어들었기 때문에 size의 값을 감소시킨다.
- size--;
- 마지막 데이터를 삭제할 경우, 배열의 복사는 필요 없다.
- 삽입은 삭제 과정의 반대로 생각하면 된다. (한칸씩 아래로 복사 후 삽입)
-
-
ArrayList에 저장된 첫 번째 객체부터 삭제하는 경우 : 배열 복사 발생
-
ArrayList에 저장된 마지막 객체부터 삭제하는 경우 : 배열 복사 발생 안함!!! -> 데이터 이동 없음! -> 빠르고, 다 지워짐!
배열의 장단점
- 배열의 장점 : 구조가 간단하고, 데이터를 읽는 데 걸리는 시간(접근 시간)이 짧음
값의 주소 = 배열 주소 + 데이터 타입의 크기(int는 4byte) * index -> 각 요소가 연속적이기 때문에, 주소 계산 시간이 짧음.
접근성이 좋음!
- 배열의 단점
-
크기를 변경할 수 없음. (실행 중에 바꿀 수 없음)
- 크기를 변경해야 하는 경우, 새로운 배열 생성 후 데이터 복사 필요 (더 큰 배열 생성 -> 복사 -> 참조변경)
- 크기 변경을 피하기 위해 너무 큰 배열을 생성할 경우, 메모리가 낭비됨. (충분히 큰 배열의 생성 중요)
-
비순차적인 데이터(중간 자리에)의 추가, 삭제에 시간이 오래 걸림
- 데이터를 추가하거나 삭제하기 위해, 다른 데이터를 옮겨야만 함.
- 순자척인 데이터 추가(끝에 추가)와 삭제(끝부터 삭제)는 빠르다!
-
LinkedList
-
배열의 단점을 보완 (크기 변경 불가, 추가 삭제에 시간이 오래 걸림)
-
배열과 달리, 불연속적으로 존재하는 데이터를 연결함
-
배열은 각 요소가 연속적이나, LinkedList는 불연속적이다.
-
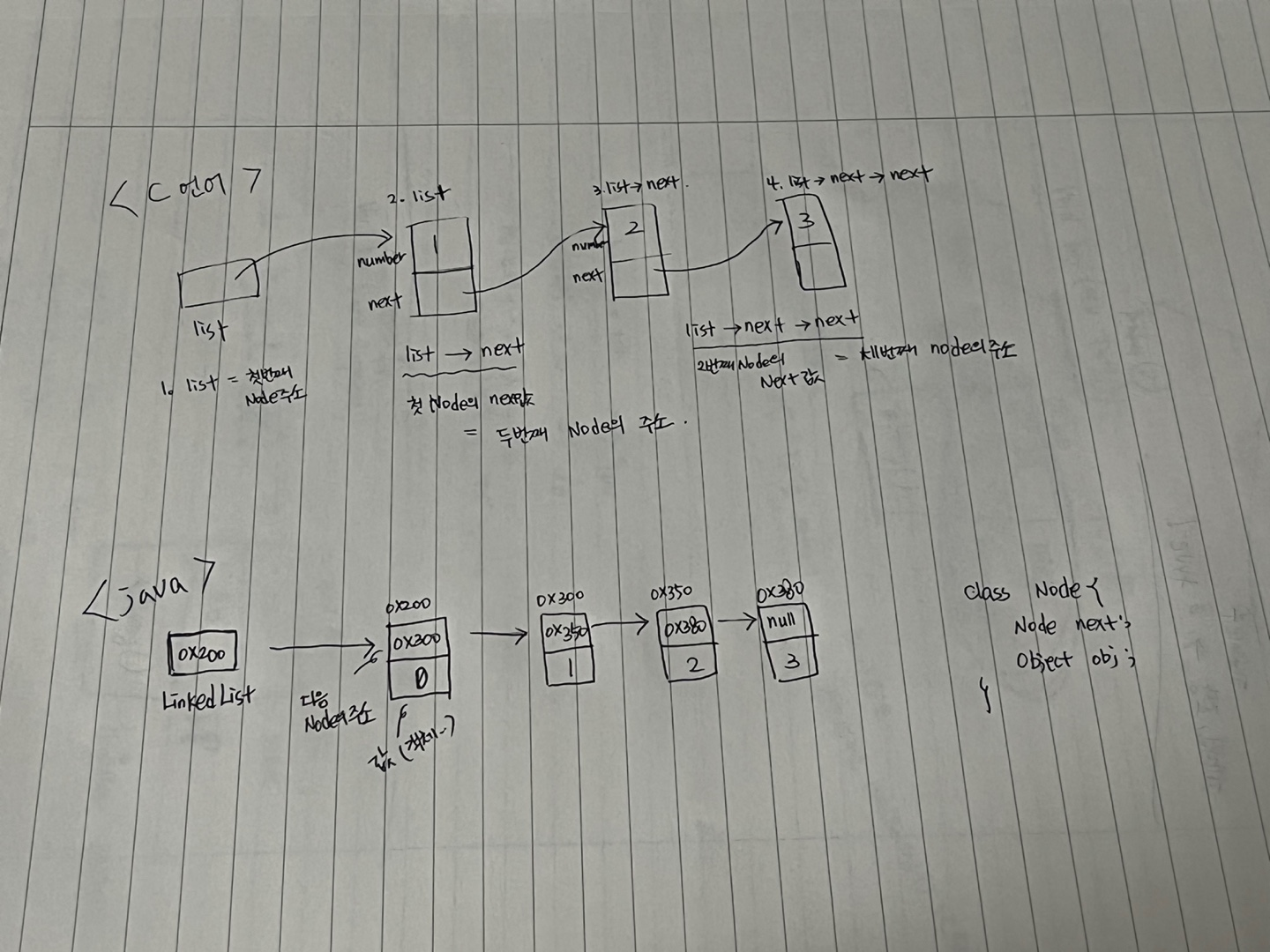
배열과 달리, Data 하나 하나가 연결되어 있는 구조이며, Node라고 한다.
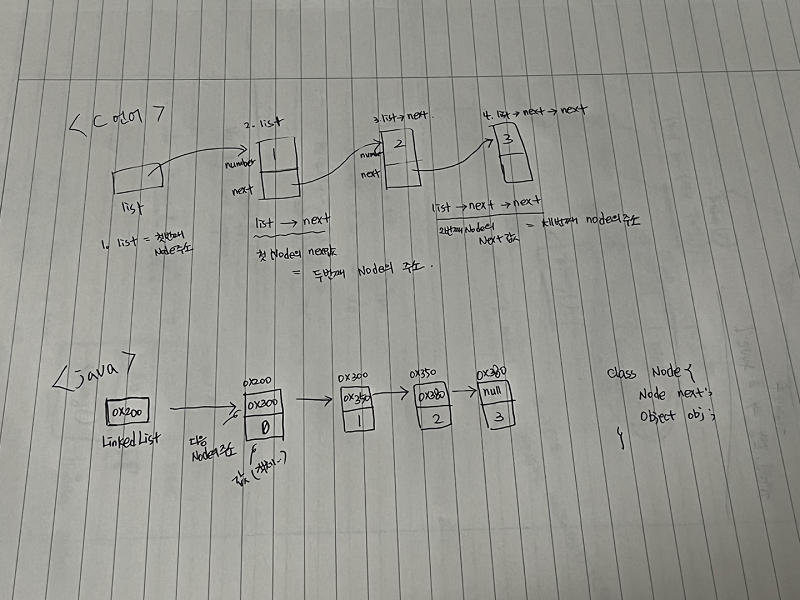
class Node {
Node next; // 다음 노드
Object obj; // 데이터
}
-
데이터 삭제 : 중간에 있는 값 삭제 시, 중간의 참조를 끊고 그 다음 노드로 연결 (단 한번의 참조 변경)
-
데이터 추가 : Node 객체 생성 후, 참조 변경을 하여 연결. (한번의 Node 객체 생성, 두 번의 참조 변경)
-
단점
-
접근성이 안좋다
- 불연속적이기 때문에, Node가 배치된 순서대로, 순차적으로만 접근을 할 수 있다. 한번에 중간에 있는 값으로의 접근이 안됨.
- Doubly linked list로 접근성을 향상!
-
-
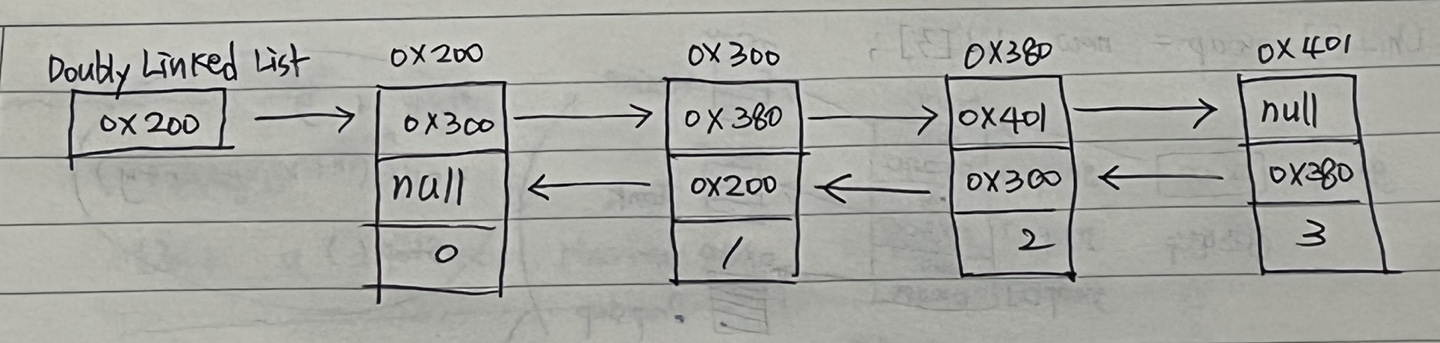
Doubly linked list : 이중 연결리스트. 접근성 up! (데이터의 삭제, 추가는 번거로워짐) 하지만, 아직도 정방향/역방향으로의 순차적 접근만 가능
class Node {
Node next; // 다음 요소
Node previous; // 이전 요소
Object obj; // 데이터
}
-
Doubly circular linked list : 이중 원형 연결리스트
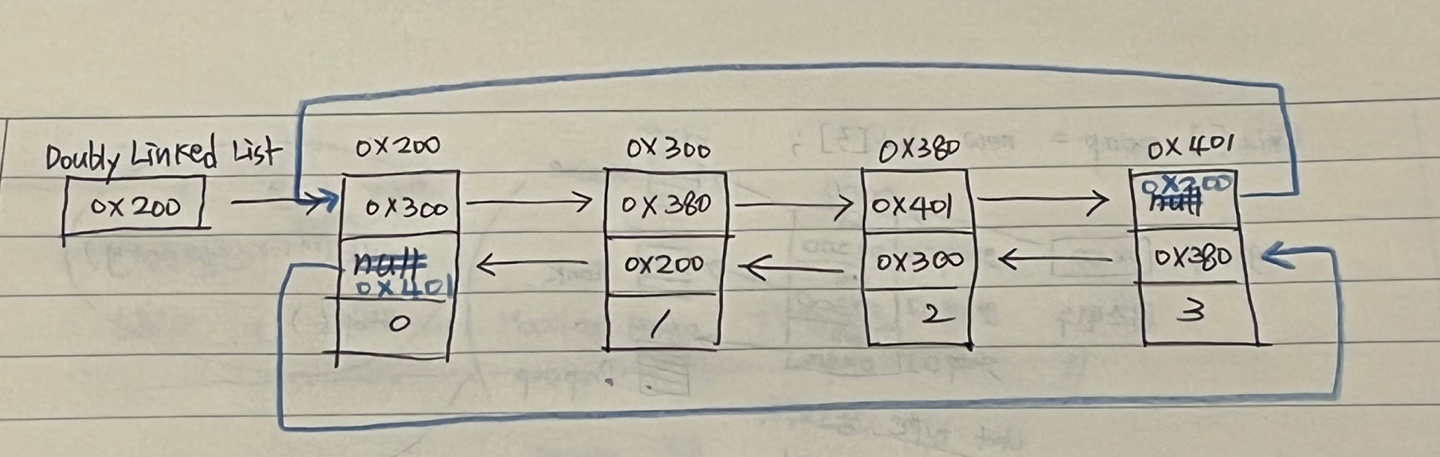
-
ArrayList VS LinkedList
- 순차적으로 데이터 추가/삭제 : ArrayList가 빠름
- 비순차적으로 Data 추가/삭제 : LinkedList가 빠름 (중간에 추가/삭제)
- 읽기 & 접근시간(access time) : ArrayList가 빠름.
-
자료구조(Data Structure)에서,
ArrayList는 "배열 기반 자료구조"로,
LinkedList는 "연결 기반 자료구조"로 분류한다.
-
자료구조는 배열기반과 연결기반으로 분류되어 있다.
-
배열기반 자료구조는 "연속적"이고, 연결기반 자료구조는 "불연속적"이다.
