Process & Thread
-
프로세스(공장, 작업환경) : 실행 중인 프로그램. 자원(메모리, CPU...)과 쓰레드로 구성 됨.
-
쓰레드(일꾼) : 프로세스 내에서 실제 작업을 수행. 모든 프로세스는 최소 하나 이상의 쓰레드를 가지고있다.
-
싱글 쓰레드 프로세스 == 자원 + 쓰레드
-
멀티 쓰레드 프로세스 == 자원 + 쓰레드 + ... + 쓰레드 (여러 작업을 나눠서 동시 수행. 작업을 보다 효율적으로 수행할 수 있음)
하나의 새로운 프로세스를 생성하는 것 보다, 하나의 새로운 쓰레드를 생성하는 것이 더 적은 비용이 든다.
- 멀티쓰레드의 장단점
-
장점
- 시스템 자원을 보다 효율적으로 사용할 수 있음.
- 사용자에 대한 응답성(responseness)이 향상됨.
- 작업이 분리되어 코드가 간결해짐
- "여러 모로 좋음"
-
단점
- 동기화(synchronization)에 주의해야 함.
- 교착 상태(dead-lock)가 발생하지 않도록 주의해야 함.
- 기아 상태가 발생하지 않도록 주의해야 함. (특정 쓰레드에 실행할 기회가 주어지지 않음)
- 각 쓰레드가 효율적으로 고르게 실행될 수 있게 해야 함.
- "프로그래밍 할 때 고려해야 할 사항들이 많음."
-
Thread 구현
-
Thread 클래스 상속
-
Runnable 인터페이스 구현 (추천. 다른 클래스를 상속받을 수 있기 때문)
// Thread 클래스 상속
class MyThread extends Thread {
public void run() {
// 작업 내용을 넣어준다. main에 넣어주듯이!
}
}
// Thread 클래스 사용
MyThread t1 = new MyThread(); // 쓰레드 생성
t1.start(); // 쓰레드 실행
// Runnable 인터페이스 구현
public interface Runnable {
public abstract void run();
}
class MyThread implements Runnable {
public void run() {
// 작업 내용을 넣어준다. main에 넣어주듯이!
}
}
// Runnable 사용
Runnable r = new MyThread();
Thread t1 = new Thread(r); // run() {}을 외부에서 매개변수로 받음
// Thread()가 run()호출
// Thread t1 = new Thread(new MyThread());
t1.start();Thread 실행
-
Thread를 생성한 후에 start()를 호출해야 쓰레드가 작업을 시작함.
-
start()했다고 바로 쓰레드가 실행되는 것이 아니며, 어느게 먼저 실행될 지 모름.
-
쓰레드를 start()하면 "실행 가능한 상태"가 되는것이다.
-
언제 실행될 지는 "OS 스케줄러가 실행순서를 결정함."
-
"쓰레드는 OS에 의존적/종속적이다."
start()와 run()
-
Call stack 모식도
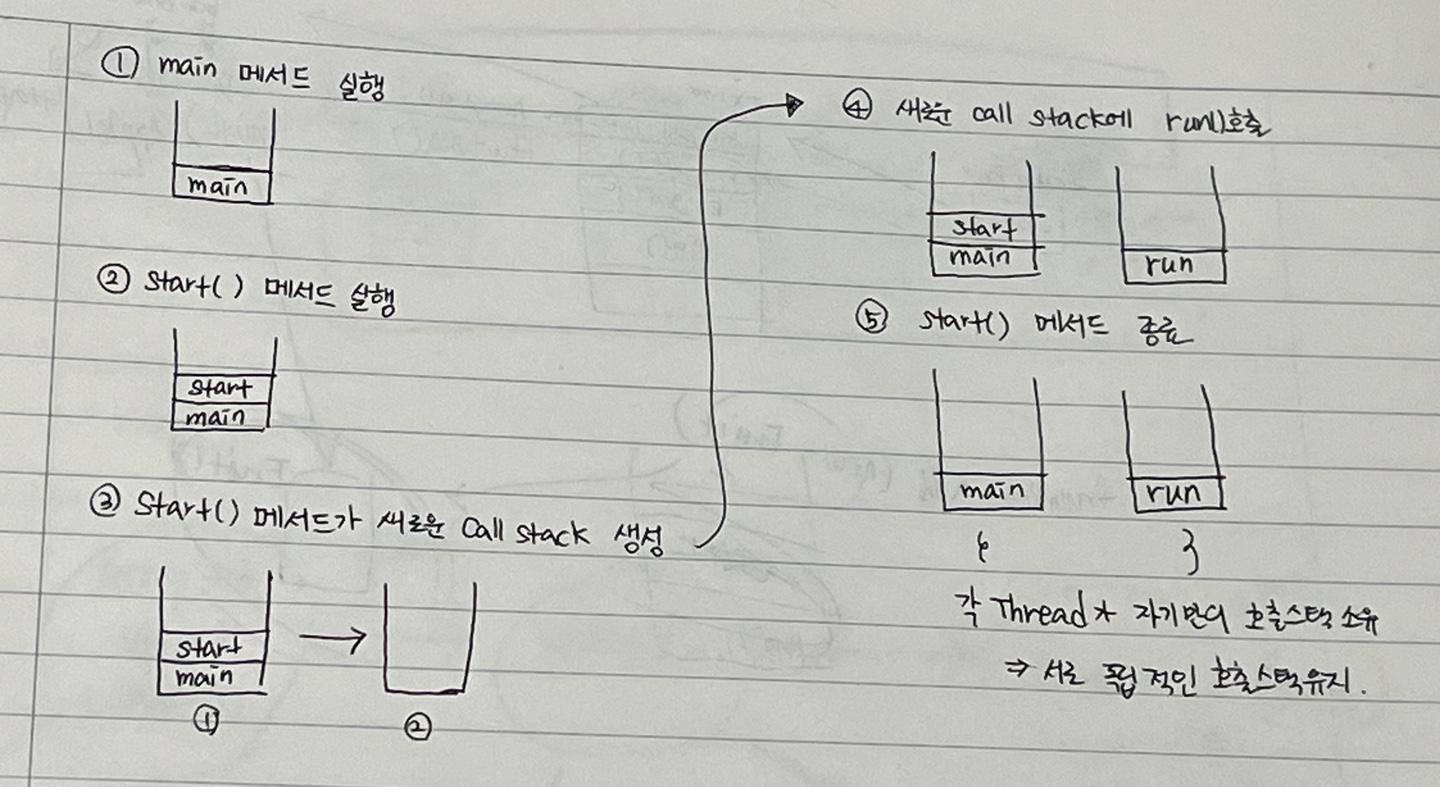
-
run()을 먼저 호출하면 안되는 이유 : start()를 먼저 호출하고 새로운 Call stack을 만들어야, 각각 다른 쓰레드에서 독립적으로 실행된다.
-
run()을 호출한다면, 새로운 호출 스택이 만들어지지 않고 싱글 쓰레드로 실행될 것이다.
main 쓰레드
-
main 메서드의 코드를 수행하는 쓰레드
-
쓰레드 : 사용자 쓰레드, 데몬 쓰레드(보조) 두 종류가 있음.
-
프로그램은 실행 중인 "사용자 쓰레드"가 하나도 없을 때 프로그램은 종료된다.
-> 실행 중인 사용자 쓰레드가 하나라도 있으면, 프로그램은 종료되지 않음.
싱글 쓰레드 vs 멀티 쓰레드
- 멀티 쓰레드의 실행 순서는 OS의 스케줄러가 결정한다.
- 매번 실행 순서가 달라짐!!
- context switching에 시간이 걸리기 때문에, 한 작업을 싱글 스레드로 하는 것 보다 시간이 좀 더 걸릴 수 있다.
쓰레드의 I/O 블락킹
-
I/O == Input/Output
-
싱글쓰레드는 사용자 입력 구간에서, 아무것도 입력 되지 않으면 다음으로 넘어가지 않음.
-
반면에, 멀티쓰레드는 사용자 입력 구간에서, 아무것도 입력하지 않아도, 그 동안 다른 쓰레드가 실행 됨. 이런 경우, 싱글 쓰레드보다 멀티 쓰레드가 작업이 더 먼저 끝난다.
쓰레드의 우선순위
-
작업의 중요도에 따라, 쓰레드의 우선순위를 다르게 하여 특정 쓰레드가 더 많은 작업 시간을 갖게할 수 있다.
-
자바에서는 쓰레드의 우선순위를 1~10까지 부여할 수 있다. (default = 5)
- 우선순위가 같은 경우, 비슷한 시간을 할당받음
- 우선순위가 높은 경우, 쓰레드에 먼저 주어지는 시간이 더 길어짐 (먼저 끝나도록 수행) -> 이론 상! 희망사항임ㅋ
-
WinOS에서는 우선순위가 32단계이다. 자바에서 정해줘봤자 희망사항에 불과함..!
-
OS의 스케줄러는 모든 프로세스와 프로그램에 공평하며, 참고만 하는 수준임.
-
급한것들이 우선순위가 높아야 한다. OS는 마우스 포인터가 가장 높은 순위이다.
void setPriority(int newPriority) // 쓰레드의 우선순위를 지정한 값으로 변경 (1~10)
int getPriority() // 쓰레드의 우선순위 반환쓰레드 그룹
-
서로 관련된 쓰레드를 그룹으로 묶어서 다루기 위한 것. (기본적으로 그룹화되어 다뤄진다.)
-
모든 쓰레드는 반드시 하나의 쓰레드 그룹에 포함되어 있어야 한다.
-
쓰레드 그룹을 지정하지 않고 생성한 쓰레드는 "main 쓰레드 그룹"에 속한다.
-
자신을 생성한 쓰레드(부모 쓰레드)의 그룹과 우선순위(dafault = 5)를 상속받는다.
// Thread의 생성자
Thread(ThreadGroup group, String name)
Thread(ThreadGroup group, Runnable target)
Thread(ThreadGroup group, Runnable target, String name)
Thread(ThreadGroup group, Runnable target, String name, long stackSize)
// 관련 메서드
ThreadGroup getThreadGroup() // 쓰레드 자신이 속한 쓰레드 그룹을 반환
void uncaughtException(Thread t, Throwable e) // 처리되지 않은 예외에 의해, 쓰레드 그룹의 쓰레드가 실행이 종료되었을 때, JVM에 의해 이 메서드가 자동적으로 호출된다.데몬 쓰레드 (Daemon Thread)
-
일반 쓰레드의 작업을 돕는 보조적 역할 수행
-
일반 쓰레드가 모두 종료되면 자동적으로 종료 됨.
-
가비지 컬렉터(GC), 자동 저장, 화면 자동 갱신 등에 사용된다.
-
무한 루프와 조건문을 이용해서 실행 후, 대기하다가 특정 조건이 만족되면 작업을 수행하고 다시 대기하도록 작성.
boolean isDaemon() // 쓰레드가 데몬 쓰레드인지 확인.
void setDaemon(boolean on) // 쓰레드를 데몬 쓰레드, 또는 사용자 쓰레드로 변경. true - 데몬쓰레드
// setDaemon(boolean on)은 반드시 start()를 호출하기 전에 실행되어야 한다.
// 그렇지 않으면 IllegalThreadStateException 발생쓰레드 상태
-
NEW
: 쓰레드가 생성되고, 아직 start()가 호출되지 않은 상태 -
RUNNABLE
: 실행 중, 또는 실행 가능한 상태 -
BLOCKED
: 동기화 블럭에 의해서 일시정지된 상태(lock이 풀릴 때 까지 기다리는 상태)
suspend() 일시정지, sleep() 몇 초간 쉼, wait() 기다림, join() 다른 쓰레드 기다리기, I/O block 입출력대기
time-out->sleep()이 시간이 지나 풀림, resume() <-> suspend(), wait() <-> notify(), interrupt() 시간이 지나기 전에 sleep()을 깨움 -
WAITING, TIMED_WAITING
: 쓰레드의 작업이 종료되지는 않았지만 실행가능하지 않은(unrunnable) 일시정지 상태. TIMED_WAITING은 일시정지 시간이 지정된 경우를 의미 -
TERMINATED
: 쓰레드의 작업이 종료된 상태
쓰레드의 실행 제어
-
쓰레드의 실행을 제어할 수 있는 메서드가 제공된다.
-
이 들을 활용하면, 보다 효율적인 프로그램을 작성할 수 있다.
-
*sleep(), join(), interrupt(), stop(), suspend(), resume(), *yield()
* : static method. sleep()과 yield()는 자기 자신에게만 호출 가능하다. 다른 쓰레드에 적용 불가!
sleep()
-
현재 쓰레드를 지정된 시간 동안 멈추게 한다.
-
예외 처리를 해주어야 한다. (InterruptedException이 발생하면 깨어날 수 있게 만들어줌.) -> 매번 사용하면 코드가 길어지기 때문에, 미리 메서드로 만들어둔다.
-
Time-up, 시간 종료가 되면 끝난다.
-
특정 쓰레드를 지정해서 멈추게 하는 것은 불가능하다. 반드시 Thread.sleep()으로 사용!
interrupt()
-
대기상태(WAITING)인 쓰레드를 실행대기 상태(RUNNABLE)로 만든다.
sleep(), join(), wait() -> interrupt() -> RUNNABLE -
interrupt() : 쓰레드의 interrupted 상태를 false에서 true로 변경
-
boolean isInterrupted() : 쓰레드의 interrupted 상태를 반환 (interrupt 되었는지 알려줌. 중간에 방해된건지, 완료로 인한 종료인지 확인)
-
static boolean interrupted() : 현재 쓰레드의 interrupted 상태를 알려주고, false로 초기화 (상태 변수를 false로 초기화)
// interrupt 수행 모식도 //
// ↓ 아래 변수는, interrupted()가 호출되면 false로 초기화된다.
boolean interrupted = false; // 3. true로 변함
boolean isInterrupted() { // 4. isInterrupted를 호출하면
return interrupted; // 5. true를 반환
}
boolean interrupt() { // 1. interrupt를 호출하면
interrupted = true; // 2. interrupted가 true가 됨
}suspend(), resume(), stop()
-
쓰레드 실행을 일시정지, 재개(RUNNABLE 상태로 만듦), 완전 정지 시킨다.
-
해당 메서드는 deprecated 되었다. -> dead-lock(교착상태)에 빠질 가능성이 있으므로, 사용하지 마셈!!!
-
직접 구현해서 사용할 수 있음.
join()
-
지정된 시간 동안, 특정 쓰레드가 작업하는 것을 기다린다.
-
예외 처리를 해주어야 한다. (InterruptedException이 발생하면 작업 재개)
void join() // 작업이 모두 끝날 때 까지 기다림
void join(long millis) // 입력된 millisecond 만큼 기다림
void join(long millis, int nanos) // millisecond + nanosecond 동안 기다림yield()
-
남은 시간을 다음 쓰레드에게 양보하고, 자신(현재 쓰레드)는 실행 대기한다.
-
yield()와 interrupt()를 적절히 사용하면, 응답성과 효율을 높일 수 있다.
-
busy-waiting 최소화 (하는 일 없이 반복만 하고있음..!)
-
OS 스케줄러에게 통보를 해주는 것이며, 반드시 동작한다는 보장은 없음
쓰레드의 동기화(Synchronization)
-
멀티 쓰레드 프로세스에서는 다른 쓰레드 작업에 영향을 미칠 수 있다.
-
진행 중인 작업이 다른 쓰레드에게 간섭받지 않게 하려면 '동기화' 필요.
-
쓰레드의 동기화 : 한 쓰레드가 진행중인 작업을, 다른 쓰레드가 간섭하지 못하게 막는 것.
-
동기화 하려면, 간섭받지 않아야 하는 문장들을 "임계 영역"으로 설정.
-
임계 영역은, 락(lock)을 얻은 단 하나의 쓰레드만 출입이 가능하다. (객체 1개에 락 1개)
-
임계 영역은, 1번에 접근 가능한 쓰레드가 1개이기 때문에, 최소화 해야 한다.
-
synchronized를 이용한 동기화
synchronized로 임계 영역(lock이 걸리는 영역)을 설정하는 방법 2가지
// 1. 메서드 전체를 임계 영역으로 지정
public synchronized void calcSum() { // |
... // 임계 영역 (Critical section)
} // |
// 2. 특정한 영역을 임계 영역으로 지정
synchronized(객체의 참조변수) { // |
... // 임계 영역 (Critical section)
} // |wait() & notify()
-
동기화를 하면, 한번에 한 쓰레드만 작업이 가능하여 효율이 떨어짐.
-
동기화의 효율을 높이기 위해 wait(), notify() 사용.
-
Object 클래스에 정의되어 있으며, 동기화 블록 내에서만 사용할 수 있다.
- wait() : 객체의 lock을 풀고, 쓰레드를 해당 객체의 waiting pool에 넣는다.
- notify() : waiting pool에서 대기중인 쓰레드 중에 하나를 깨운다.(랜덤)
- notifyAll() : waiting pool에서 대기중인 모든 쓰레드를 깨운다.(공평)
-
요리사는 Table에 음식을 추가. 손님은 Table의 음식을 소비.
-> 요리사와 손님이 같은 객체(Table)을 공유하므로, 동기화가 필요함.
-
wait()과 notify()는 그 대상이 불분명함. -> Lock & condition이 해결 (구별 가능)
