오늘은 졸업과제를 위해 학내 AI서버를 사용하던 중 발생한 에러에 대해 분석하고 해결방법을 공유하고자 한다.
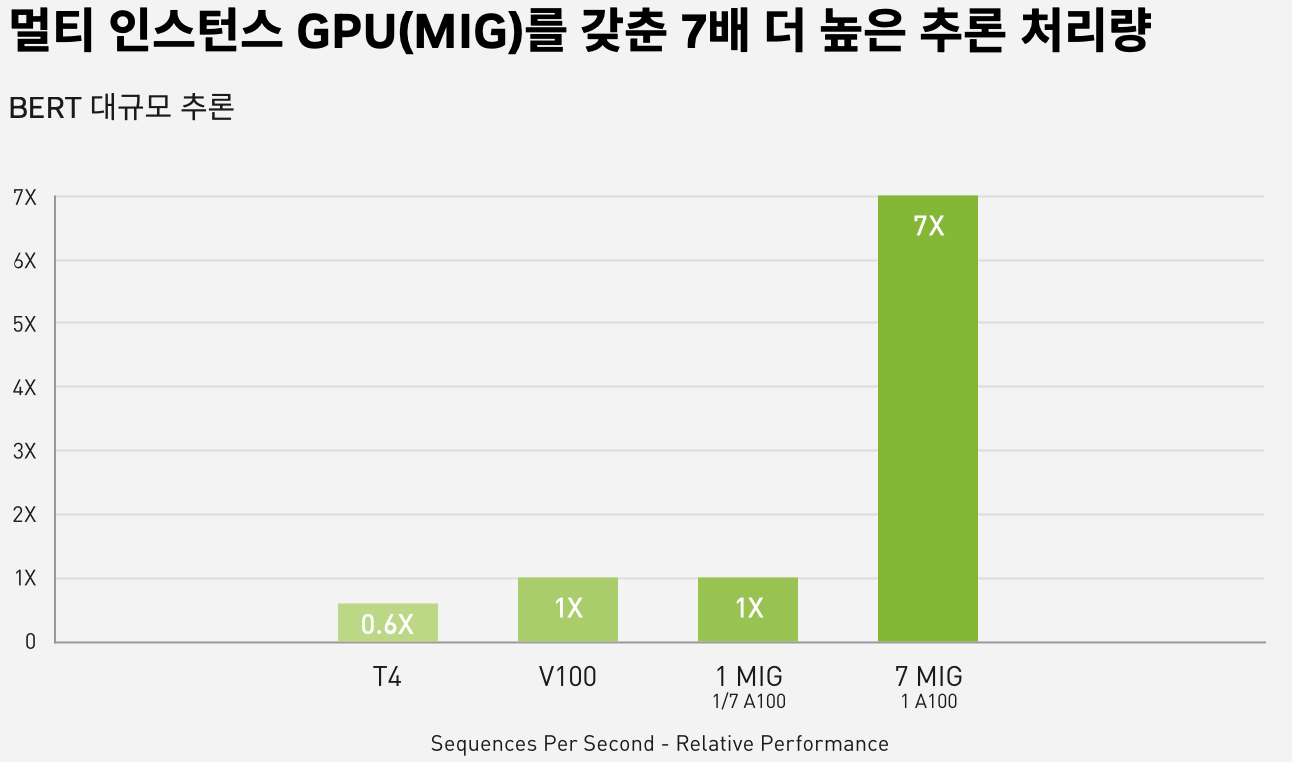
기존 구글코랩 기본제공인 T4로 학습했었다. 하지만 세션종료의 위험으로 epochs를 많이 올릴 수 없었고, 연구실 서버 GPU인 A100 성능우위로 연구실 서버를 사용하기로 했다.
- A100과 T4의 성능은 아키텍쳐부터 다르다. 엔비디아 공식 홈페이지에 따르면 A100이 T4에 비해 다중 컨테이너 환경에서는 월등한 성능 우위를 가진다.
📌 배경
간단하게 사용되는 용어와 목적을 정리해보자.
쿠버네티스(Kubernetes)란, 도커와 같이 컨테이너의 활용을 자동화하고 관리하기 용이하게 도와주는 관리시스템이다.
도커(Docker)란, 앱의 구동환경을 격리하여 하나의 os위에 여러 애플리케이션 구동환경을 띄워 분리하여 사용할 수 있도록 하는 컨테이너 기반의 기술이다.
도커 이미지(Docker Image)란, 도커는 컨테이너(Container)를 만들기 위한 리소스 정보를 가진 이미지를 가지고 있으며, 이는 템플릿과 같은 역할을 한다. 컨테이너는 이 이미지를 통해 생성된 인스턴스라 할 수 있다.
쿠버네티스를 사용하여 엔비디아에서 제공하는 도커이미지인 nvida/cuda 이미지를 통해 개발중인 모델을 학습하고자 했다.
학과 연구실에서 파이썬 형태로 작성된 쿠버네티스 실행파일과 설정을 담은 yaml파일을 제공해주었고, 이 실행파일에는 컨테이너 생성규칙, default 이미지 버전, 실행 옵션 등이 작성되어 있었고, yaml파일에는 작업에 필요한 컨테이너 기본이름, GPU사용갯수 등이 작성되어 있었다.
기본세팅으로 개발중인 모델을 실행해보니 ImagePullBackOff에러가 발생하여 이 문제를 해결하고자 하였고, 그 과정을 담아본다.
문제를 해결하는 과정에서 쿠버네티스와 도커, SSH에 대한 이해를 높일 수 있었고, 이를 기록하고자 작성했다.
📌 서버에 학습할 파일을 올리고 실행하기
파일은 다음 명령어로 로컬에서 서버로 전송할 수 있다.
scp -P [포트번호] [$파일주소및이름] [계정명]@[접속프로토콜]:~서버에 작성한 모델파일을 업로드 하여 연구실 서버의 A100 GPU로 학습할 계획이다.
실행파일인 k8s_create_job.py를 뜯어보니 실행 규칙은 다음과 같았다.
python3 k8s_create_job.py
-i nvidia/cuda:11.4.1-base-ubuntu20.04
-g 2
-n snack-pgan-1
-c "cd /home/snack && defaultpgan.py"⚙️ 옵션설명
-i : 사용할 도커 이미지 지정. 미지정시 기본값은 "nvidia/cuda:11.4.1-base-ubuntu20.04"로 되어 있다.
-g : 사용할 GPU 개수. 미지정시 기본값은 1
-n : 생성할 컨테이너 이름. 컨테이너 이름은 중복될 수 없고, 미지정시 '계정명-autocreate-랜덤숫자'로 작성된다.
-c : 실행할 명령어. 실행할 디렉터리로 이동 후 명령어 작성.
이후 기본이미지로 컨테이너 이름을 "snack-pgan-1"로 지정하여 defaultpgan.ipynb를 실행해보았다. 하지만 실행상태를 확인하니 ImagePullBackOff가 발생했다.

📌 ImagePullBackOff
: 이미지를 불러 올 수 없다는 에러
“kubectl describe pods snack-pgan-1” 명령어로 에러 원인을 분석한 결과

Failed to pull image "nvidia/cuda:11.4.1-base-ubuntu20.04": rpc error: code = Unknown desc = Error response from daemon: manifest for nvidia/cuda:11.4.1-base-ubuntu20.04 not found: manifest unknown: manifest unknown
이미지를 불러올 수 없어 발생하였음을 확인했다. 현재 설치된 도커이미지를 확인해보니 nvidia/cuda:11.4.1-base-ubuntu20.04를 확인할 수 없었고, 다운이 제대로 되지 않은 느낌이었다.
docker pull을 이용하여 nvidia/cuda:11.4.1-base-ubuntu20.04를 받고자 했으나 다운할 수 없다고 하여 최신버전을 받기로 하였다.
snack@master:~$ docker pull nvidia/cuda:11.4.1-base-ubuntu20.04
Error response from daemon: manifest for nvidia/cuda:11.4.1-base-ubuntu20.04 not found: manifest unknown: manifest unknown혹여 현재 OS버전에 호완되지 않는지 파악하기 위해 OS버전을 확인하였고, 현재 서버 OS가 ubuntu 20.04라 OS와의 문제는 아니었다.
Docker Hub에 있는 최신버전인 "nvidia/cuda:12.2.0-base-ubuntu20.04" 버전을 docker pull 명령어로 다운로드했다.
nvidia/cuda:11.4.1-base-ubuntu20.04버전과는 달리 성공적으로 다운로드 되었고 실행해보았다.
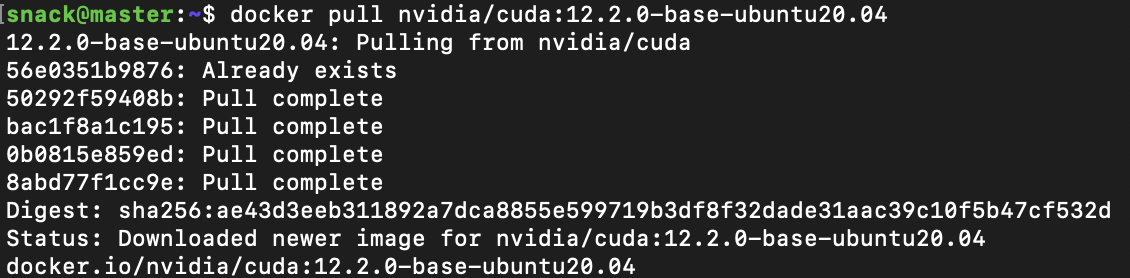
ImagePullBackOff는 성공적으로 해결되었으나, 컨테이너를 생성한 다음단계에서 ContainerCannotRun이라는 에러가 발생하였다.
📌 ContainerCannotRun
: 이미지로부터 생성한 컨테이너를 실행할 수 없다는 에러
Error: failed to start container "gpu-container": Error response from daemon: OCI runtime create failed: container_linux.go:380: starting container process caused: process_linux.go:545: container init caused: Running hook #0:: error running hook: exit status 1, stdout: , stderr: nvidia-container-cli: requirement error: unsatisfied condition: cuda>=12.2, please update your driver to a newer version, or use an earlier cuda container: unknown
해석해보니 nvidia gpu cuda 12.2버전이상의 드라이버가 설치되어 있어야한다고 한다. nvidia.smi로 확인된 현재 cuda 버전은 11.6이고, 드라이버 업데이트에 대한 권한은 나에게 없기 때문에 연구실에 문의하였다.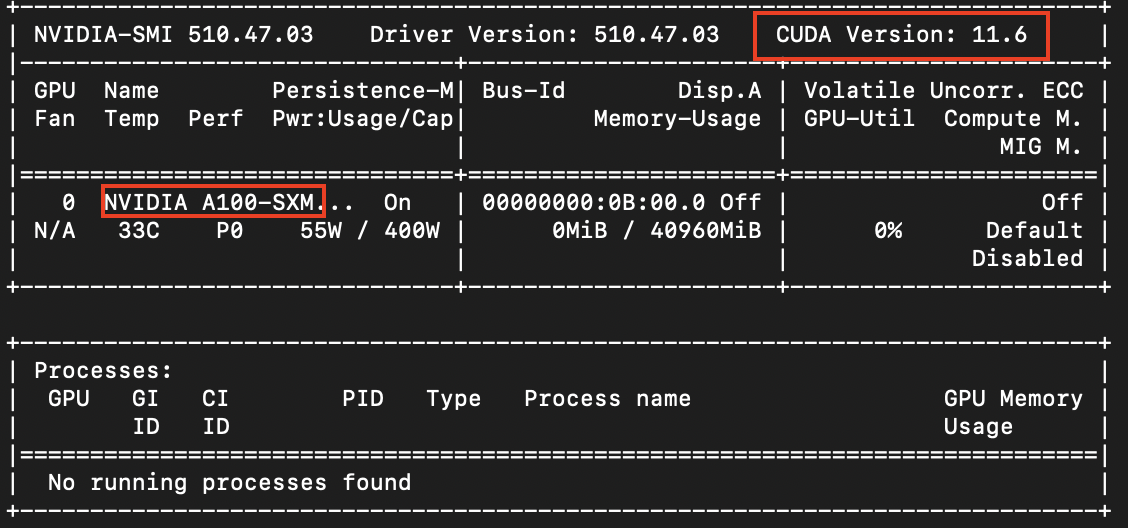
📌 문제해결
그렇다면 nvidia/cuda:11.4.1-base-ubuntu20.04는 왜 설치되지 않았을까?
관련하여 의문을 해소하기 위해 엔비디아 gitlab을 접속하여 관련 문서를 읽어보았다.
해당 gitlab에는 "CUDA Container Support Policy"을 명시하고 있었는데 여기서 현재 지원하는 이미지 목록인 supported-tag를 확인할 수 있었다. 현재 기본 실행옵션인 11.4.1은 지원목록에 없었고, 더이상 온라인으로 배포되지 않아 docker pull 명령어로 다운할 수 없었던 것이다. 11.4.1을 사용하고자 한다면 홈페이지에서 수동으로 다운받아 사용해야한다.
그래서 현재 GPU cuda버전과 호완되고, support-tag에 명시된 11.4.3으로 설치해보니 성공적으로 이미지를 불러 올 수 있었고, 컨테이너를 생성해 실행되었다. 이렇게 ImagePullBackOff와 ContainerCannotRun에러를 해결할 수 있었다.
