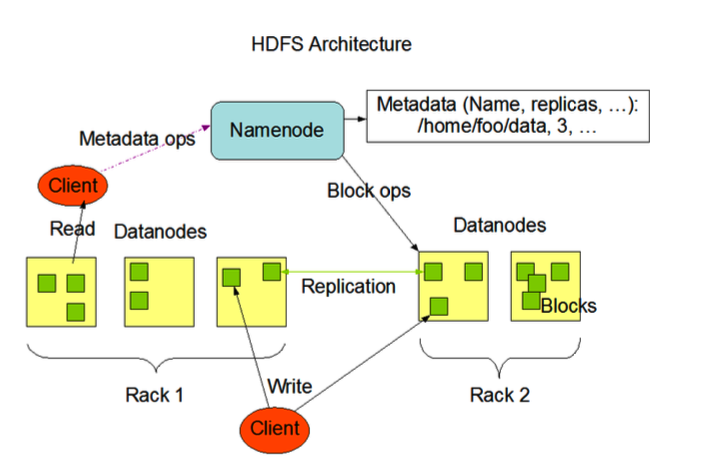
Name Node
-
네임노드는 블록의 위치, 권한 등의 정보를 메모리에 유지
-
Fsimage : File System image. Name Node가 생성된 이후로부터의 HDFS의 namespace 정보
-
Edit log : Fsimage로부터 현재까지의 변경사항 로그
-
-
네임노드의 기능과 역할
-
Metadata Management
-
파일 시스템을 유지하기 위한 메타데이터를 관리
-
파일 시스템 이미지(file name, directory, size, access/auth control)와 파일에 대한 매핑 정보로 구성
-
클라이언트에게 빠르게 응답해야하므로 메모리에서 데이터를 관리
-
-
Data Node Management
- Data Node의 리스트를 관리, 유지, 변경한다. 명시적인 admin 명령 또는 Monitoring 결과에 따라 대상을 변경
-
Data Node Monitoring
-
데이터 노드는 네임 노드에게 3초마다 heart beat를 전송
-
heart beat는 데이터 노드의 상태 정보와 블록의 목록(block report)fh rntjd
-
네임 노드는 heart beat 데이터를 기반으로 데이터 노드의 실행 상태, 용량 등을 관리
-
heart beat를 전송하지 않는 데이터 노드는 장애가 발생한 서버로 판단
-
-
Block Management
- 네임 노드는 블록에 대한 정보를 관리
- 장애가 발생한 데이터 노드를 발견하면, 해당 데이터 노드에 위치한 블록을 새로운 데이터 노드로 복제, 용량이 부족한 데이터 노드가 있다면 용량의 여유가 있는 데이터 노드로 블록을 이동시킴
-
Client request
-
클라이언트가 HDFS에 접근할 때 언제나 네임노드에 먼저 접속
-
파일을 저장하는 경우, 기존 파일의 저장여부, 권한 체크 등을 수행. 파일을 조회하는 경우 실제 블록의 위치정보를 반환
-
-
Data Node
-
Block size, replication factor
-
HDFS는 여러대의 서버로 이루어진 클러스터에 큰 크기의 파일들을 신뢰성 있게 저장하도록 디자인됨
-
각 파일의 내용은 여러개의 block 리스트로 저장함
-
각 블록은 fault tolerance(고장 감내성)을 위해서 복제하며, 각 파일마다 block size와 replication factor가 지정됨
-
하나의 파일의 모든 블록은 마지막 블록을 제외하고는 모두 같은 사이즈임(Default 128MB)
-
애플리케이션은 파일의 replica 수를 지정할 수 있으며 이를 replication-factor라고 함
-
HDFS 파일들은 append, truncate를 제외하면 한 순강에 하나의 writer만 존재할 수 있음
-
-
Replica Placement
-
replica의 위치는 HDFS의 신뢰성과 성능에 큰 영향을 미침
-
replica 위치에 대한 최적화 규칙이 HDFS와 기존 다른 분산파일시스템과의 가장 큰 차이점
-
replica placement와 관련된 정책은 data reliability, availability, network bandwidth utilization을 개선하는 방향으로 이루어짐
-
그 중 가장 대표적인 것이 rack-aware replica placement임
-
-
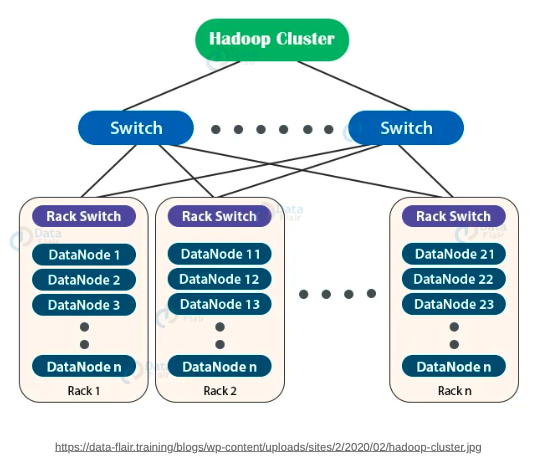
Rack-Awareness
-
대용량 HDFS 클러스터에 존재하는 computing instance들은 통상 많은 서버 랙(rack)에 위치한다.
-
이때 서로 다른 두 개의 랙에 위치한 두 개의 서버는 랙마다 존재하는 switch를 거쳐서 통신함.
-
이 때, network bandwidth는 같은 랙에 있는 다른 서버와 통신할 때보다 더 증가하게 됨
-
Hadoop Rack Awareness를 통해 네임노드는 각 데이터노드의 rack id를 알고 있음
-
replica를 위치시키는 가장 간단한 정책은 하나의 replica는 unique rack에 존재하도록 하는 것. 이것은 하나의 rack이 통째로 장애가 났을 때를 대비해서 데이터의 유실을 방지할 수 있음. 또한 이 정책은 replica들을 전체 랙에 골고루 분산할 수 있기 때문에 부하 분산(load balance)하는 효과도 존재. 그러나 이 정책은 write 시 여러개의 rack에 걸쳐서 block 데이터를 전파해야 하므로 write operation 비용이 증가한다.
-
-
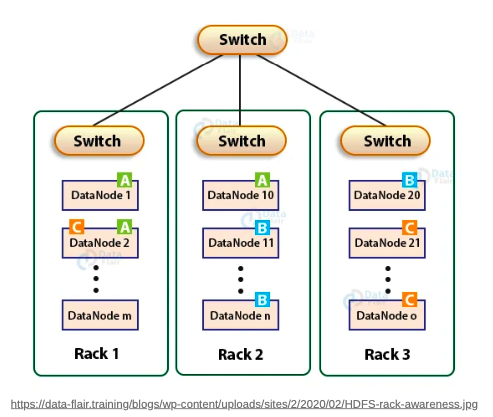
Block Placement Policy Default
-
HDFS의 기본 placement policy(BlockPlacementPolicyDefault)는 다음과 같음
-
하나의 replication은 가능한한 writer와 같은 rack에 있는 datanode에 저장함
-
만약 writer가 데이터노드에 동작한다면, 기본적으로 하나의 replica는 해당 데이터노드의 local에 저장함
-
만약 writer가 데이터노드에 있는 것이 아니라면, writer가 동작하는 노드와 같은 rack에 있는 datanode를 random하게 선택해서 저장함
-
-
나머지 두 개의 replica는 writer와 다른 랙의 서로 다른 두 datanode에 저장되도록 한다. 따라서 총 unique rack의 수는 2이다.
-
장점
-
write 시, rack들간에 발생하는 traffic을 줄여서 write 성능을 높임
-
만약 node failure의 가능성보다 rack failure의 가능성이 낮다면, data reliability와 availability guarantees에 영향을 미치지 않음
-
-
단점
-
총 network bandwidth를 줄이지는 못한다.(replica 별로 unique rack에 위치시키는 것과 비교해서)
-
데이터가 rack들 사이에 골고루 분산되지 못한다.(1:2로 위치하므로)
-
-
추가로 4 종류의 Pluggable policies가 존재함
-
Replica Selection - Read
-
글로벌 bandwidth 소비를 줄이고, read latency를 줄이기 위해 HDFS는 read 요청에 대해 reader와 가까운 곳에 있는 replica로부터 데이터를 읽도록 시도함.
-
reader node와 같은 rack에 replica가 존재하면, 해당 read 요청은 그 replica에서 데이터를 읽는다.
-
만약 HDFS 클러스터가 여러 데이터센터에 걸쳐져 있다면, 같은 데이터센터에 있는 replica를 읽는 것을 선호함
-
-
Safemode
-
네임노드가 최초로 기동될 때 safemode라는 특별한 상태에 들어간다.
-
safemode에서는 replication이 발생하지 않음
-
데이터노드로부터 받은 block report의 내용을 종합해 모든 블럭에 대한 replication이 일정 수준(%)을 넘어서 잘 구성되어있다면, 그 때 이 safemode에서 빠져나온다.
-
Safemode에서 빠져나온 뒤에, 모자란 replication factor가 있는 블록이 있다면 복제를 수행함
-
