Index란?
-
Table에서 Index로 지정한 칼럼을 기준으로 메모리 영역에 일종의 목차를 만드는 것
-
Index를 사용한다면, Insert, update, delete 시에 Index를 갱신하는 과정이 추가되므로 저장 속도를 희생
-
단, Select 시에는 Index를 통해 해당 데이터에 빠르게 접근할 수 있음
-
따라서, 데이터 저장 작업을 얼마나 희생하여 읽기 작업의 속도를 높일 것인지에 따라 인덱스를 추가할지에 대해 결정해야 함
-
칼럼의 값을 Key로, 해당 레코드가 저장된 주소를 Value로 저장하며, Key를 기준으로 정렬하여 보관
-
RDBMS에서 Index를 구성하는 알고리즘은 대표적으로 B-Tree 인덱스와 Hash 인덱스로 구분
-
B-Tree 알고리즘은 칼럼의 값을 변경하지 않고 원래의 값을 이용해 인덱싱
-
Hash 알고리즘은 해시값을 계산해서 인덱싱, 하지만 값을 변형하여 인덱싱 하므로 범위 검색에는 취약
-
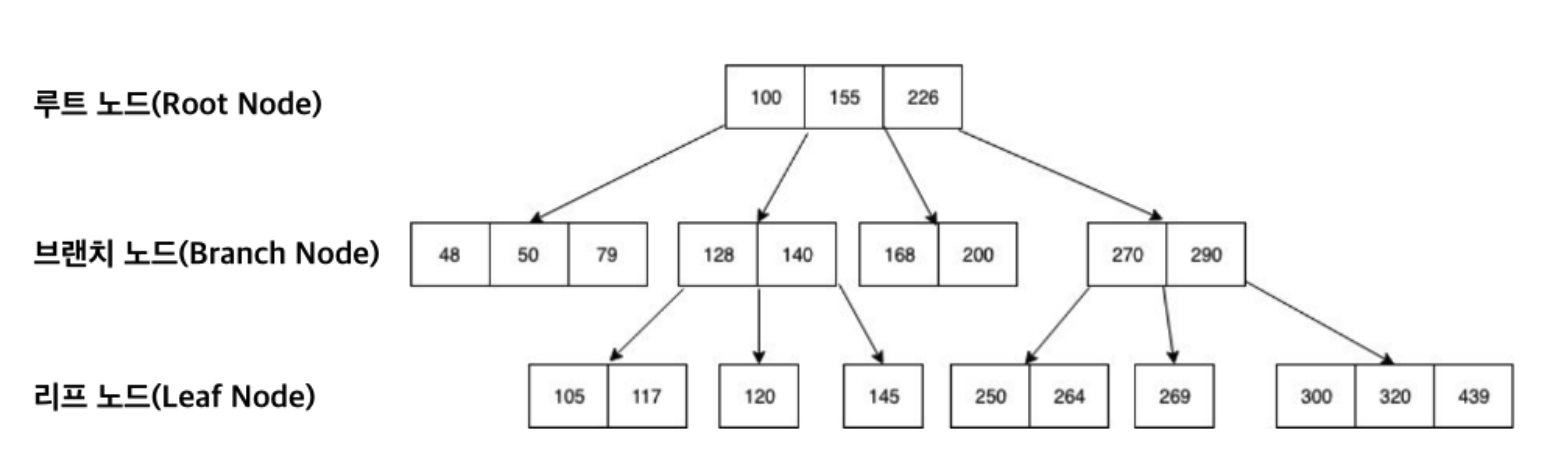
B-Tree 인덱스란?
-
B-Tree(Balanced Tree, Not Binary)
-
B-Tree는 부모 노드가 2개의 자식 노드를 갖는 이진트리를 확장하여 N개의 자식 노드를 갖도록 고안된 것
-
특징
- 노드에는 2개 이상의 데이터(Key)가 들어갈 수 있고, 항상 정렬된 상태를 유지
- 내부 노드는 최대 M개의 자식을 가질 수 있으며, 이를 M차 B-Tree라고 함
- 특정 노드의 데이터가 K개라면, 자식 노드의 갯수는 K+1개여야 함
- 특정 노드의 왼쪽 Sub-Tree는 부모 노드의 키보다 작아야 하며, 오른쪽 Sub-Tree는 부모 노드의 키보다 커야 함
- 범위 스캔을 위함
- 노드 내의 데이터는 floor(M/2)-1 개부터 M-1개까지 포함 될 수 있음
- 모든 리프 노드들은 같은 레벨에 존재해야 함
-
이 때 주의해야 할 사항은 인덱스는 순차로 정렬되어 있지만, 데이터 파일의 레코드는 정렬되어 있지 않을 수 있다는 것
-
이유는 Insert 순으로 저장된다고 하더라도, 데이터가 삭제되어 빈 공간이 생긴다면 그 다음 Insert에서 빈 공간을 재활용하기 때문
-
여기서 LeafNode에 있는 데이터 == 실질적으로 데이터가 저장되어 있는 위치일까?
- 인덱스에 따라 다를 수 있음, 뒤에서 설명
-
Page란?
- 디스크와 메모리에 데이터를 저장하는 최소 단위의 작업
- 즉 인덱스와 테이블은 모두 페이지 단위로 관리되며, 단 하나의 레코드를 읽더라도 적어도 하나의 페이지를 읽어야 한다는 의미
- 따라서 페이지에 저장되는 개별 데이터의 크기를 최대한 작게 만들어, 한 개의 페이지에 최대한 많은 데이터를 저장하는 것이 중요하게 됨(디스크 I/O를 줄이고 메모리에 캐싱하는 페이지 수를 늘리기 위해)
- MySQL의 페이지는 16KB로 고정되어 있음
- 예를 들어, 인덱스 키의 크기가 16Byte, 자식노드의 주소(Branch, Leaf)의 주소가 담긴 크기가 12Byte라고 하면 17*1024/(16+12), 585 개의 데이터를 하나의 페이지에 저장할 수 있다는 의미이며, 600개의 row를 읽으려면 두 개의 페이지를 읽어야 한다는 의미
Cardinality
- 인덱스를 걸 칼럼을 선택하는 데 있어서 중요한 기준
- Cardinality란 즉, 중복된 값이 얼마나 들어가 있는지를 나타냄
- 남녀 성별이라면 카디널리티가 낮은 값이고, 계좌번호라면 카디널리티가 높다고 말할 수 있음
- 즉, 해당 인덱스를 통해 최대한 많은 값들을 분류하는 것이 인덱스의 효율을 최대로 높일 수 있으므로 카디널리티가 높은 칼럼을 기준으로 인덱스를 구성하는 것이 좋음
- 인덱스를 여러 칼럼으로 걸어야 하는 상황이라면, 카티널리티가 높은 칼럼들을 앞에 두는 것이 좋음
Index의 성능
- 보통 인덱스를 통해 1 개의 레코드를 읽는 것이 테이블을 통해 직접 읽는 것보다 4~5배의 비용이 더 드는 것으로 봄
- 따라서 읽어야 할 레코드가 전체 테이블의 20~25%가 넘어서면 인덱스를 사용하지 않는 것이 효율적이며, 이런 경우 옵티마이저는 인덱스를 사용하지 않고 테이블 전체를 읽어서 처리하도록 설계되어 있음
Index의 종류
-
Clustered Index
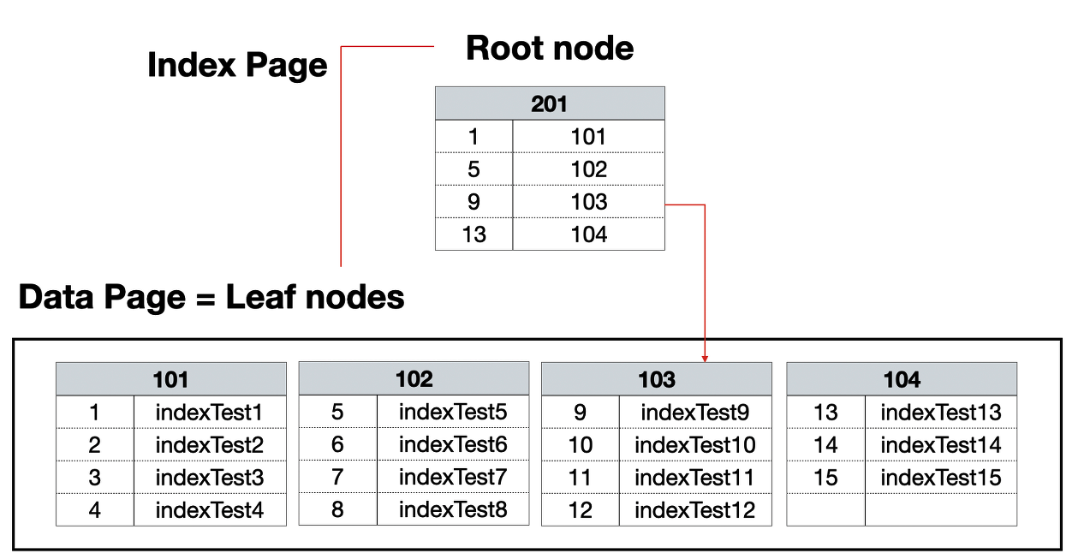
- 테이블 당 1개 씩만 허용
- 물리적으로 행을 재배열함
- PK 설정 시, 그 칼럼은 자동으로 클러스터드 인덱스로 설정됨
- 인덱스 자체의 리프 페이지가 곧 데이터임. 즉, 테이블 자체가 인덱스가 됨
- Insert, Update, Delete 시, 항상 정렬된 상태를 유지
- Non-Clustered Index보다 검색 속도는 더 빠르지만, Insert, Update, Delete는 느림
-
Non-Clustered Index

- 테이블 당 약 240 개의 인덱스 생성 가능
- 인덱스 페이지는 로그 파일에 저장됨
- 인덱스 자체의 리프 페이지는 데이터가 아니라 데이터가 위치하는 포인터(ROWID)
- 따라서, 검색 속도는 Clustered Index보다 느리지만, 입력, 수정, 삭제는 더 빠름
- 인덱스 생성시 별도의 인덱스 페이지를 만드므로 용량을 더 많이 차지 함
Index는 모든 검색에 효율적일까?
-
앞서 이야기 한 것처럼, 전체 테이블의 20~25% 이상의 레코드를 조회해야 하는 Query라면, Index를 이용하기 보다 Full Scan 방식이 더 효율적일 수 있음
-
Index를 통한 검색 Query는 데이터베이스에 Single Block I/O 기반으로 처리하기 때문
-
Single Block I/O는 하나의 block을 I/O로 담아서 나른다고 이해할 수 있음
-
즉, 소량의 데이터를 읽을 때 효과적임
-
반대로 Table FULL scan의 경우에는 Multi Block I/O기반으로 처리함
-
Multi Block I/O는 여러 개의 block을 한번에 I/O로 담아서 나른다고 이해할 수 있음
-
즉, 대량의 데이터를 읽을 때 효과적임
