복제 지연 문제
-
복제는 내결함성만을 위해 필요한 것이 아님. 확장성과 지연시간은 복제를 구성하는 주요 이유 중 하나
-
리더 기반 복제는 쓰기 요청을 리더가 담당하며, 수 많은 읽기 요청을 팔로워가 담당
-
즉, 대부분이 읽기 요청이고 쓰기 요청이 작은 비율로 구성된 작업부하를 가진 시스템이라면 매우 유용할 수 있음
-
이러한 방식을 읽기 확장(read-saclin) 아키텍처라고 함
-
하지만 읽기 확장 아키텍처는 비동기식 방식에서만 사용할 수 있음
-
복제 지연 문제
-
비동기 방식의 단점 중 하나는 모든 팔로워가 동일한 시점에 동일한 데이터를 가지고 있지 않을 수 있다는 점임
-
네트워크 상황 등에 의해 발생될 수 있는 문제이며, 이는 시간을 두어 기다리면 자동적으로 해소됨(팔로워가 리더를 모두 따라잡으면). 이를 최종적 일관성이라고 함
-
일반적으로 복제 서버가 리더에 비해 얼마나 뒤쳐질 수 있는가에 대한 제한은 없고, 이러한 지연을 복제 지연이라고 함
-
복제 지연의 해결방법
-
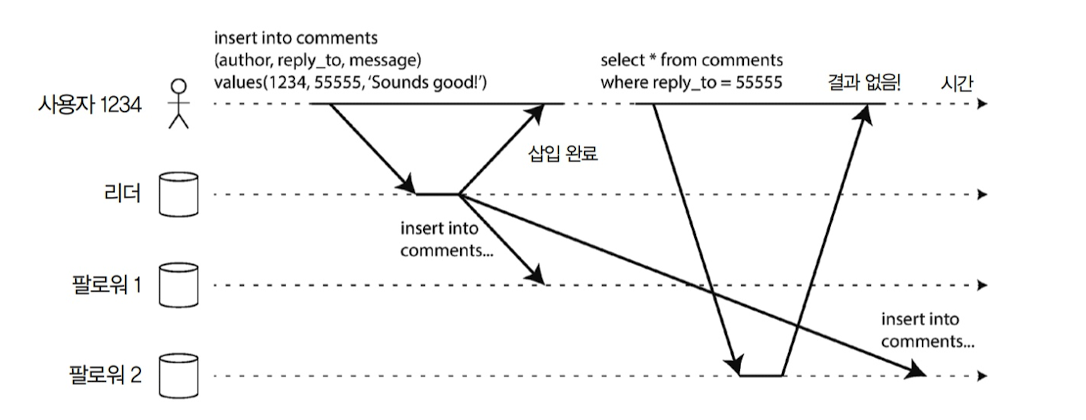
자신이 쓴 내용 읽기
-
사용자가 리더에게 쓰기 요청을 보낸 후, 팔로워에게 읽기 요청을 보냄
-
팔로워가 리더 데이터를 모두 따라잡지 못했다면, 엉뚱한 결과를 보내올 것
-
이런 상황에서 쓰기 후 읽기 일관성을 위해 자신의 쓰기에 대해서는 해당 노드에서 읽기 요청을 실행(이 방식 이외에도 다양한 방식으로 구현할 수 있음)
-
단, 다른 사용자에 대해서는 보장하지 않으며 사용자 자신의 입력이 올바르게 저장됐음을 보장하기 위함임
-
-
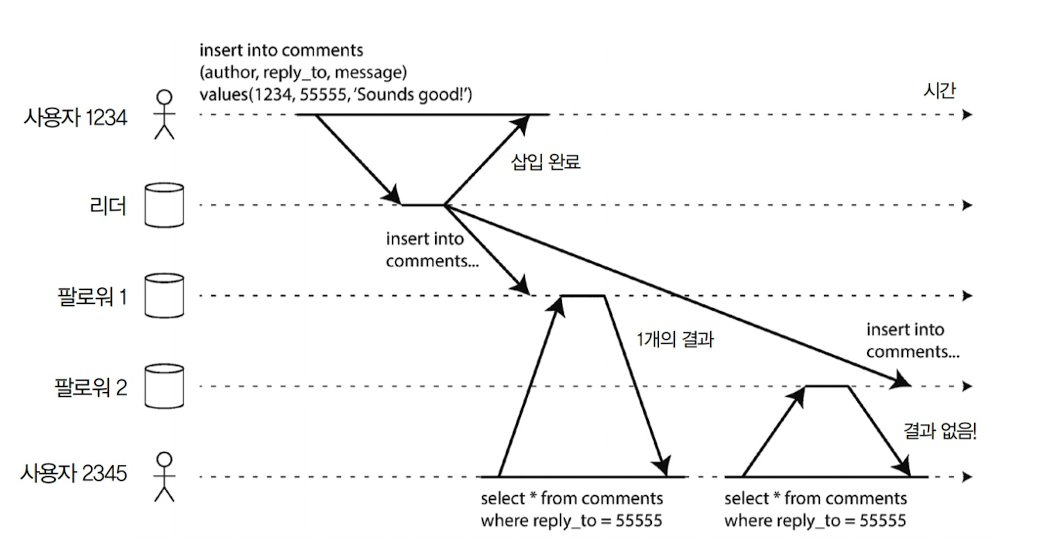
단조 읽기
-
사용자가 각기 다른 복제 서버에서 여러 읽기를 수행할 때 발생
-
사용자 2345가 질의를 같은 질의를 두 번 실행했을 때, 각 질의가 팔로워 1과 팔로워 2에 전달
-
팔로워 1은 해당 데이터가 복제된 상황, 팔로워 2는 복제되지 않은 상황
-
이 경우, 사용자는 팔로워 2의 질의에서 엉뚱한 답을 받을 수 있음
-
단조읽기는 최종적 일관성보다는 강한 보장이며, 강한 일관성보다는 약한 보장
-
즉, 한 사용자가 여러 번에 걸친 읽기 요청을 보낼 때, 동일한 데이터 값의 리턴을 보장한다는 의미
-
단조읽기를 달성하는 방법은 단순히 각 사용자의 읽기가 항상 동일한 복제 서버에서 수행될 수 있게끔 하는 것
-
예를 들어 사용자 ID의 해시 값을 기반으로 복제 서버를 선택하는 로직을 구현하는 것
-
-
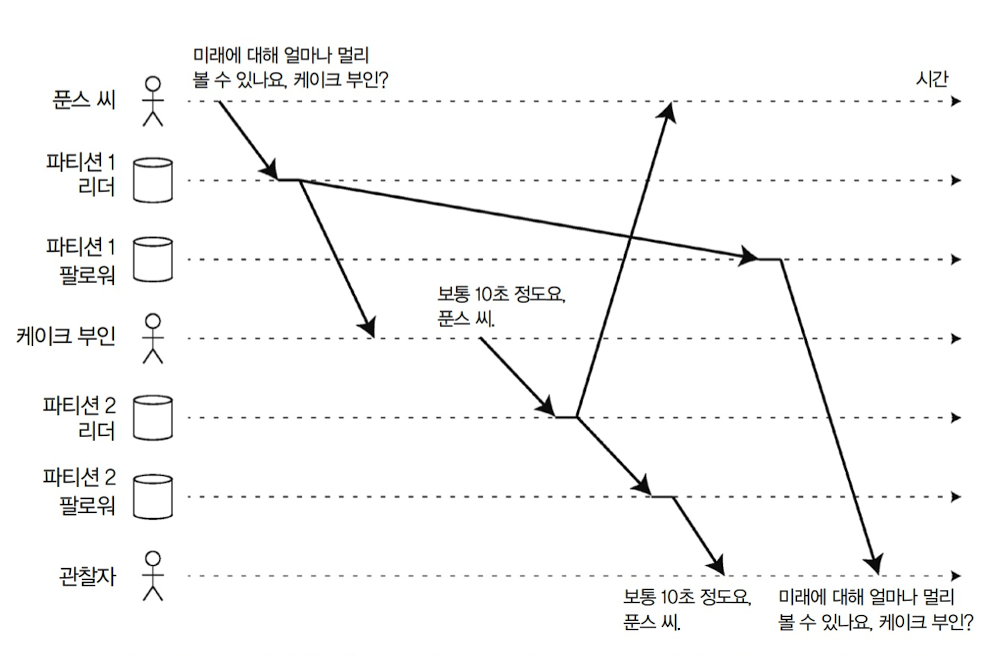
일관된 순서로 읽기
-
두 개의 쓰기 요청이 각 팔로워에 복제될 때 두 쓰기의 복제가 다른 순서로 이루어질 수 있음
-
위 그림의 예시와 같이 엉뚱한 순서로 읽기될 가능성이 존재
-
이를 위해 일관된 순서로 읽기를 보장할 필요가 있음
-
일련의 쓰기가 특정 순서로 발생된다면 이 쓰기를 읽는 모든 사용자는 같은 순서로 쓰여진 내용을 보게 됨을 보장한다는 의미
-
이 같은 현상은 파티셔닝(샤딩)된 데이터베이스에서 주로 발생하는 문제
-
해결책 중 하나는 서로 인과성이 있는 쓰기는 동일한 파티션에서 기록되도록 하는
-
정리
-
최종적 일관성 시스템으로 작업한다면, 복제지연을 고민해봐야 함
-
위 문제에 대한 해결책은 사실 비동기식으로 동작하지만, 동기식으로 동작하는 척하는 것임
-
애플리케이션이 기본 데이터베이스보다 더 강력한 보장을 제공할 수 있지만, 애플리케이션 코드 레벨에서 이 문제를 다루는 것은 매우 복잡해서 잘못되기가 쉬움
-
이러한 문제를 애플리케이션 레벨에서 다루지 않도록 하는 것이 가장 베스트이고, 이를 위한 것이 트랜잭션임
-
오랫동안 단일 노드 트랜잭션이 존재해왔지만, 분산(복제 & 파티셔닝) 데이터베이스로의 전환하는 과정에서 많은 시스템들이 트랜잭션을 포기함
-
그 이유는 트랜잭션이 성능과 가용성 측면에서 너무 비싸고, 확장 가능 시스템에서는 어쩔 수 없이 최종적 일관성을 사용해야 한다는 논리
-
책의 3부에서 이 논리에 대한 대안 메커니즘을 설명할 예정
