순서화
-
단일 리더 복제에서 리더의 주 목적은 복제 로그에서 쓰기의 순서, 즉 팔로워가 쓰기를 적용하는 순서를 결정하는 것
-
직렬성은 트랜잭션들이 마치 어떤 일련 순서에 따라 실행되는 것처럼 동작하도록 보장하는 것
-
분산 시스템에서 타임스탬프와 시계 사용은 무질서한 세상에 질서를 부여하려는 또 다른 시도
-
즉, 순서화, 선형성, 합의 사이에는 깊은 연결 관계가 있음
순서화와 인과성
-
순서화란 인과성을 보존하는 수단으로 작용
-
일관된 순서로 읽기에서 질문과 답에 인과적 의존성이 부여됨
-
동시 쓰기 감지에서도 이전 발생을 파악하는 것은 인과성을 표현하는 또 다른 방식
-
스냅숏 격리에서 트랜잭션은 일관된 스냅숏으로부터 읽음. 맥락적으로 일관된의 의미는 인과성에 일관적이라는 의미
-
-
시스템이 인과성에 의해 부과된 순서를 지키면 그 시스템은 인과적 일관성(causally consistent)을 지닌다고 함
인과적 순서와 전체 순서
-
자연수는 전체 순서를 정할 수 있지만, 인과적 순서가 곧 전체 순서를 의미하지는 않음
-
수학적 집합에서 {a, b}가 {b, c}보다 크다고 말할 수 없음. 비교 불가하며, 부분적으로 순서가 정해짐
-
어떤 집합이 다른 집합의 부분집합이 아니라면, 순서는 비교 불가능함
-
전체 순서와 부분 순서는 다른 방식으로 데이터베이스에 일관성을 반영함
-
선형성
- 선형성 시스템에서는 연산의 전체 순서를 정할 수 있음. 시스템은 데이터 복사본이 하나만 있는 것처럼 동작하고 모든 연산이 원자적이면 어떤 두 연산에 대해 항상 둘 중 하나가 먼저 실행됐다고 말할 수 있음
-
인과성
- 두 연산 중 어떤 것도 다른 것보다 먼저 실행되지 않았다면 두 연산이 동시적이라고 말함. 인과성은 전체 순서가 아닌 부분 순서를 정의할 뿐임
선형성과 인과적 일관성
-
위 개념에 따라, 선형성은 인과적 일관성을 내포함
-
그럼 인과적 일관성을 알아보는 이유가 뭘까?
-
선형성은 선형성의 비용이 존재함. 즉, 네트워크 지연이 크면 성능과 가용성에 방해가 됨. 어떤 분산 데이터 시스템은 선형성을 포기해서 더 좋은 성능을 달성함
-
하지만, 많은 경우에 선형성이 필요한 것처럼 보이는 시스템이 사실은 인과적 일관성을 달성한 것만으로도 충분한 경우가 많음
-
따라서 인과적 일관성을 달성하는 새로운 종류의 데이터베이스를 많은 연구자들이 연구 중임
인과적 일관성의 핵심 아이디어
-
인과성을 유지하기 위해선 어떤 연산이 다른 연산보다 먼저 실행됐는지 알아야 함.
-
즉, 인과적으로 앞서는 모든 연산은 이미 처리됐다고 보장할 수 있어야 함
-
리더 없는 데이터 저장소는 동시 쓰기 감지를 위해 같은 키에 대한 동시 쓰기를 검출함. 인과적 의존성은 여기서 더 나아가 전체 데이터베이스에 대한 인과적 의존성을 추적해야하며, 이를 위해 버전 백터를 일반화 할 수 있음
-
이는 직렬성 스냅숏 격리(SSI)에서 트랜잭션이 커밋을 원할 때 데이터베이스는 읽은 데이터의 버전이 여전히 최신인지 확인하는 과정과 비슷함
일련번호 순서화
-
위와 같은 방식으로 일관성을 구현할 수도 있지만, 읽은 데이터를 모두 명시적으로 추적하는 것은 오버헤드가 큼
-
일련번호나 타임스탬프를 써서 이벤트의 순서를 정할 수 있음. 다만, 꼭 물리적 시계에서 얻을 필요가 없으며, 논리적 시계에서 얻더라도 충분함
- 인과성에 일관적인 일련번호를 생성하는 것도 또 하나의 방법. 단순한 UUID가 아니라, 단일 리더 복제의 데이터베이스에서 복제 로그를 생성하는 것처럼 리더는 연산마다 단조 증가하는 일련번호를 할당할 수 있음. 이렇게 된다면, 리더가 뒤처지더라도 팔로워의 상태는 언제나 인과성에 일관적임
비인과적 일련번호 생성
-
단일 리더가 없다면 어떻게 인과성에 일관적인 일련번호를 생성할 수 있을까?
-
각 노드가 독립적인 일련번호 집합을 생성한다. 두 대라면 한 노드는 홀수만, 한 노드는 짝수만 생성한다면 중복된 일련번호는 존재하지 않게 됨
-
각 연산에 해상도가 충분히 높은 타임스탬프를 붙일 수 있음
-
-
하지만 이러한 방식은 일련번호가 중복되지는 않지만, 인과성에 일관적이지 않을 수 있음
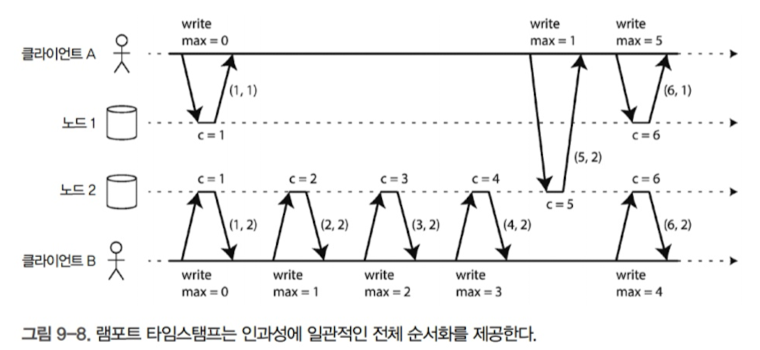
램포드 타임스탬프
-
각 노드는 고유 식별자를 갖고 각 노드는 처리한 연산 개수를 카운터로 유지
-
이 때 램포트 타임스탬프는 그냥 (카운터, 노드 ID)의 쌍임
-
두 노드는 때때로 카운터 값이 같을 수 있지만 타임스탬프에 노드 ID를 포함시켜서 각 타임스탬프는 유일하게 됨
-
램포트 타임 스탬프는 시계와는 아무런 관련이 없지만, 전체 순서화를 제공함
-
두 타임스탬프가 있으면 카운터가 큰 것이 타임스탬프가 됨
-
카운터 값이 같으면 노드 ID가 큰 것이 타임스탬프가 됨
-
모든 노드는 최대 카운터 값을 추적하고 모든 요청에 그 최대값을 포함시킴
-
버전 백터는 두 연산이 동시적인지 인과적인지 구별하는 데 사용된다면, 램포트 타임스탬프는 전체 순서화를 강제하기 위해 사용됨
-
램포트 타임스탬프의 한계
-
램포트 타임스탬프는 인과성에 일관적인 연산의 전체 순서를 정의하지만, 분산 시스템의 다른 문제를 해결하는 데 충분한 것은 아님
-
예를 들어 사용자명으로 사용자 계정을 유일하게 식별할 수 있는 시스템을 고려해보자
-
언뜻 보기에 램포트 타임스탬프로 충분할 것 같지만, 이러한 방법은 사후적으로 성공하는 쪽을 결정하는 데 효과적일 뿐임
-
사용자명 생성 요청을 받고 그 요청이 성공해야 하는지 실패해야 하는지 당장 결정할 때는 부족함
-
즉, 요청을 받은 당시 다른 노드가 동일한 사용자명으로 생성을 처리하고 있는지 알아야 하지만, 이 때 다른 노드 중 하나에 장애가 발생한다면?
-
내결함성이 깨지는 시스템이 되어버릴 수 있음
전체 순서 브로드캐스트
-
전체 순서 브로드캐스트는 보통 노드 사이에 메시지를 교환하는 프로토콜로 기술되며 두 가지 속성을 만족해야 함
-
신뢰성 있는 전달
- 어떤 메시지도 손실되지 않고, 메시지가 한 노드에 전달되면 모든 노드에도 전달됨
-
전체 순서가 정해진 전달
- 메시지는 모든 노드에 같은 순서로 전달됨
-
전체 순서 브로드캐스트는 주키퍼나 etcd와 같은 합의 서비스를 이용해 구현됨
-
즉, 모든 메시지가 데이터베이스에 쓰기를 나타내고 모든 복제 서버가 같은 쓰기 연산을 같은 순서로 처리하면 복제 서버들은 서로 일관성 있는 상태를 유지할 수 있음
-
전체 순서 브로드캐스트는 팬싱 토큰을 제공하는 잠금 서비스를 구현하는 데에 사용될 수 있으며(단조 증가하므로) 주키퍼에서는 이 일련번호를 zxid라고 함
선형성과 전체 순서 브로드캐스트
-
전체 순서 브로드캐스트는 비동기식임 즉, 메시지는 고정된 순서로 신뢰성 있게 전달되도록 보장되지만, 언제 메시지가 전달될지는 보장하지 않음
-
반대로 선형성은 최신성을 보장함
-
다행인 점은 전체 순서 브로드캐스트가 구현되어 있다면, 이를 기반으로 한 선형성 데이터베이스를 구현할 수 있음
-
사용 가능한 모든 사용자명마다 원자적 compare-and-set 연산이 구현된 선형성 저장소를 가질 수 있다고 가정해보자
-
메시지를 로그에 추가해서 점유하기 원하는 사용자명을 시험적으로 가리킴
-
로그를 읽고 추가한 메시지가 되돌아오기를 기다림
-
원하는 사용자명을 점유하려고 하는 메시지가 있는지 확인함
-
원하는 사용자명에 해당하는 첫 번째 메시지가 자신의 메시지라면 성공한 것이며, 사용자명 획득을 커밋하고 클라이언트에게 확인 응답을 보냄
-
첫 번째 메시지가 자신의 메시지가 아니라면 어보트 시킴
-
-
이런 방식의 구현은 선형성 쓰기를 보장할 수 있지만, 선형성 읽기를 보장해주지는 못함(순차적 일관성, 타임라인 일관성으로 알려진, 선형성보다 조금 약한 보장임)
-
로그로부터 비동기로 갱신된 저장소를 읽으면 오래된 값이 읽힐 수 있음
-
선형성 읽기를 보장하려면 몇 가지 선택지가 있음
-
로그를 통해 순차 읽기를 할 수 있음. 로그에 메시지를 추가하고 로그를 읽어서 메시지가 되돌아왔을 때 실제 읽기를 수행하면 됨. 로그 상의 메시지 위치는 읽기가 실행된 시점을 나타냄
-
로그에서 최신 로그 메시지 위치를 선형적 방법으로 얻을 수 있다면, 그 위치를 질의하고 그 위치까지의 모든 항목이 전달되기를 기다린 후 읽기를 수행할 수 있음(주키퍼의 sync() 연산의 기반이 되는 아이디어)
-
쓰기를 실행할 때 동기식으로 갱신돼서 최신성이 보장되는 복제서버에서 읽을 수 있음
-
