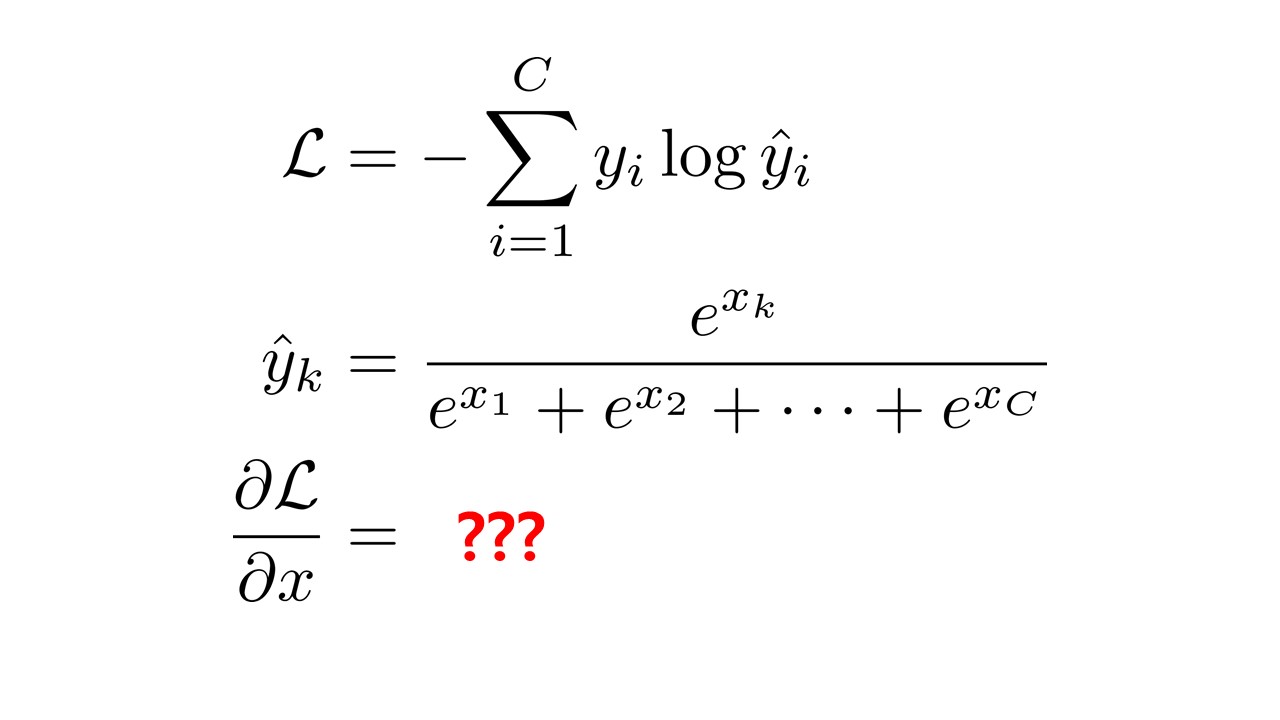사전설명
batch size가 N이고 label의 수가 C일 때, Cross Entropy Loss는 다음과 같이 분류 모델을 평가합니다.
L=−N1i=1∑Nc=1∑Cyiclogy^ic
yic는 i번째 예제의 label이 c라면 1이고, 그렇지 않으면 0입니다.
y^ic는 분류 모델이 i번째 예제의 label을 c일 확률을 구한 값입니다.
Cross Entropy Loss가 왜 저렇게 구해지는지에 대해서는 Maximum Likelyhood Estimation에 대해서 이야기해야 합니다만, 그 이야기는 너무 길어지니 다른 포스팅에서 소개하도록 하겠습니다.
그런데 Cross Entropy Loss만 미분하면 포스팅이 너무 짧아지니 y^ic까지 한 꺼풀 더 벗겨서 미분해보도록 하겠습니다.
분류 모델의 예측 확률 y^ic는 보통 softmax라는 함수를 사용해서 구하게 됩니다. x∈RN×C일 때 그 식은 아래와 같습니다.
y^ij=softmax(x)ij=exi1+exi2+⋯+exiCexij
오늘은 간략히 ∂x∂L의 값을 계산해보도록 하겠습니다.
미분
모델의 손실 함수는 대부분 한번에 미분하기 쉽지 않아서 아래와 같이 Chain rule을 이용하여 미분값을 계산합니다.
∂x∂L=∂y^∂L⋅∂x∂y^
즉, y^에 대한 L의 변화량(∂y^∂L)과 x에 대한 y^의 변화량(∂x∂y^)의 곱을 구해주면 됩니다. 전자부터 구해보겠습니다. 계산의 편의를 위해 N=1이라고 가정하겠습니다. (연산이 행 단위로만 일어나서 이렇게 가정해도 문제가 없습니다.)
label이 i라고 하면, yi=1이고 yj=0(i=j)이므로 아래와 같이 정리할 수 있습니다.
L=−yilogy^i
위 식을 y^i에 대해서 미분하면 아래와 같습니다.
∂y^i∂L∂y^∂L=−y^iyi=−[y^1y1,y^2y2,⋯,y^CyC]=−y^y
이제 softmax 함수를 미분해봅시다. softmax는 분수함수의 미분 공식을 이용하면 쉽게 미분할 수 있습니다.
(g(x)f(x))′=(g(x))2f′(x)g(x)−f(x)g′(x)
이때, yj=0(i=j)이므로 ∂y^i∂L만 고려하면 됩니다. 따라서 y^i에 대한 x1,x2,⋯,xC의 변화량을 구해봅시다.
∂xk∂y^i=(ex1+ex2+⋯+exC)2(exi)′(ex1+ex2+⋯+exC)−exi⋅exk
이때 (exi)′의 값은 k=i라면 exi이며 k=i라면 0입니다. yk의 값이 i=k일 때 1, 아닐 때 0임을 이용해서 간단히 yk⋅exi라고 나타낼 수 있습니다. 이를 이용하여 식을 정리하면 다음과 같습니다.
∂xk∂y^i=(ex1+ex2+⋯+exC)2yk(exi)(ex1+ex2+⋯+exC)−exi⋅exk=yk⋅(ex1+ex2+⋯+exCexi)−(ex1+ex2+⋯+exCexi)(ex1+ex2+⋯+exCexk)=yk⋅y^i−y^i⋅y^k=y^i(yk−y^k)
엄청나게 복잡해보이는 수식이었지만 식을 다 정리하고 나니 굉장히 깔끔해진 것을 확인해볼 수 있습니다.
이제 마지막으로 구한 두 수식을 구해지면 L에 대한 x의 변화량을 구할 수 있습니다.
∂xk∂L∂x∂L=∂y^∂L⋅∂xk∂y^=∂y^i∂L⋅∂xk∂y^i=(−y^i1)(y^i(y^k−yk))=yk−y^k=[y1−y^1,y2−y^2,⋯,yC−y^C]=y−y^
짜잔! x에 대한 손실 함수의 변화량은 y−y^로 아주 간단하게 정리된다는 것을 알 수 있었습니다!
결론
Ly^k∂x∂L=−i=1∑Cyilogy^i=ex1+ex2+⋯+exCexk=y−y^
마치며
수식이 많으니까 벨로그 에디터가 무언가 렉이 걸리는 느낌이 드네요... 수식이 많이 나오는 포스팅은 지양하는 편이 좋겠다는 교훈을 얻었습니다. 근데 포스팅 주제로 생각해둔 것들이 대부분 수식을 많이 써야 할 것 같아서 주제를 더 생각해봐야겠네요.
다음 포스팅의 주제는 일단은 간단하게 chain rule 유도하는 법에 대해서 생각중입니다만 바뀔 수도 있을 것 같습니다.
그럼 다음에 뵙겠습니다. 감사합니다.