Collection
데이터를 모아서 관리할 수 있는 클래스를 컬렉션이라고 한다.
컬렉션은 그 타입에 따라 내부에 데이터를 저장하는 구조와 처리하는 방법이 다르다.
내부에서 처리하는 방법에 따라 데이터의 탐색이 빠른 경우가 있고, 추가/제거가 빠른 경우가 있다. 사용하는 컬렉션의 특성을 잘 알고 사용해야 불필요한 성능 저하를 피할 수 있다.
자바에서 제공하는 컬렉션의 대표적인 예로 List, Map, Set 등이 있다.
오늘 다룰 내용은 HashMap, TreeMap 이기 때문에, Key 값과 Value 값을 관리해주는 컬렉션인 Map에 대해 살짝 설명하겠다.
Map
Map 에서 Key - Value 쌍은 java.util.Map.Entry 클래스로 정의되며 이 Entry 들을 저장, 관리 해주는 컬렉션이 Map이다.
Map<String, String> map = new HashMap<String, String>();
map.put("key1", "value1");
map.put("key2", "value2");
System.out.println(map.get("key1"));"key1"이라는 Key 값과 "value1"이라는 Value 값을 갖는 Entry가 HashMap 내부에 put() 메소드를 통해 저장된다. 나중에 해당 값을 가져올 때에는 Key 값인 "key1"라는 문자열만 넘겨주면 Value 값을 얻어올 수 있는 형태의 컬렉션이다.
여기서 key는 중복될 수 없지만 값인 value는 중복 저장 될 수 있다.
만약 기존에 저장된 키와 동일한 키로 값을 저장하면 기존의 값은 없어지고 새로운 값으로 대치된다.
Map 컬렉션은 그 내부 구현 방식에 따라 'HashMap', 'TreeMap', 'LinkedHashMap' 등으로 나뉜다.
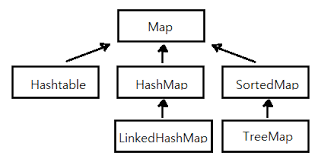
HashMap
자바 개발자가 가장 애용하는 Map컬렉션은 HashMap일 것이다.
HashMap은 Map 인터페이스를 구현한 대표적인 Map 컬렉션이다. Map 인터페이스를 상속하고 있기에 Map의 성질을 그대로 가지고 있다.
HashMap은 이름 그대로 해싱(Hashing)을 사용하기 때문에 많은 양의 데이터를 검색하는 데 있어서 뛰어난 성능을 보인다.
해싱이란?
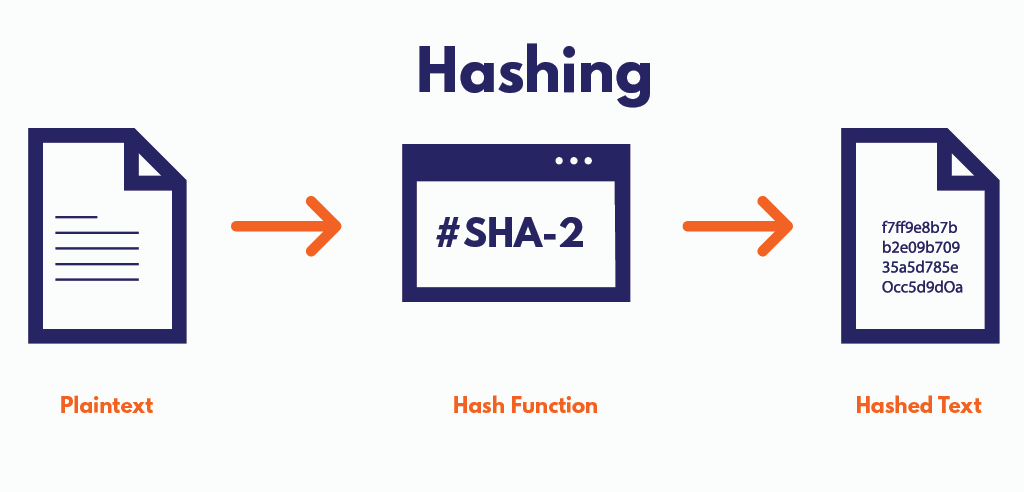
해싱은 해시 함수에 문자열 입력값을 넣어서 특정한 값으로 추출하는 것을 의미한다.
해싱은 키에 산술적인 연산을 적용하여 항목이 저장되어 있는 테이블의 주소를 계산하여 항목에 접근한다.
A -> 해시 함수 -> Alpha
B -> 해시 함수 -> Bravo
C -> 해시 함수 -> Cycle위 예시에서 A라는 값은 해시 함수를 통해서 Alpha라는 값이 나오고, B와 C 각각에 대한 결과값이 따로 있다.
여기서 중요한 건 A는 해시 함수가 바뀌지 않는한 해싱 했을 때 Alpha라는 일정한 값이 나온다는 것 (충돌이 일어나는 특정한 경우를 제외하고)과 어떤 입력값이든 해싱을 통해서 나온 결과값은 모두 5글자의 영문이라는 것이다.
A를 여러 번 해싱 했을 때 Bravo나 Cycle이 나온다면 잘못된 해시 함수를 가졌다고 봐야한다.
해시 함수?
🤷♀️ 해시 함수는 또 뭐지? 간단하게만 짚고 넘어가보자.
해시 함수는 임의의 길이를 갖는 임의의 데이터를 입력받아 고정된 길이의 데이터로 매핑하는 단방향 함수를 말한다.
- 입력값의 길이가 달라도 출력값은 언제나 고정된 길이의 비트열로 반환한다.
- 동일한 값이 입력되면 언제나 동일한 출력값을 보장한다.
또한, 해시함수는 단방향 함수라고 했다. 이 말은, 결과값을 역으로 해시함수를 통해 입력값으로 바꿀 수 없다는 것이다.
자, 다시 돌아와서
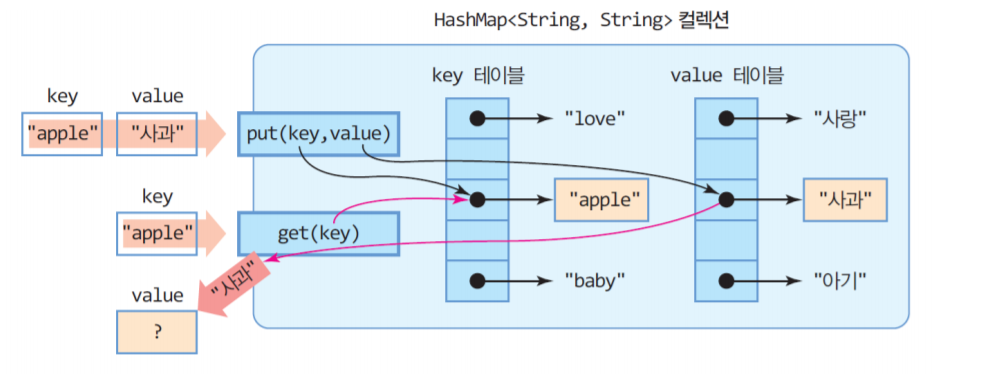
위 그림과 같이 HashMap은 내부에 '키'와 '값'을 저장하는 자료 구조를 가지고 있다. HashMap은 해시 함수를 통해 '키'와 '값'이 저장되는 위치를 결정하므로, 사용자는 그 위치를 알 수 없고, 삽입되는 순서와 들어 있는 위치 또한 관계가 없다. (삽입한 순서에 따라 정렬되지 않는다.)
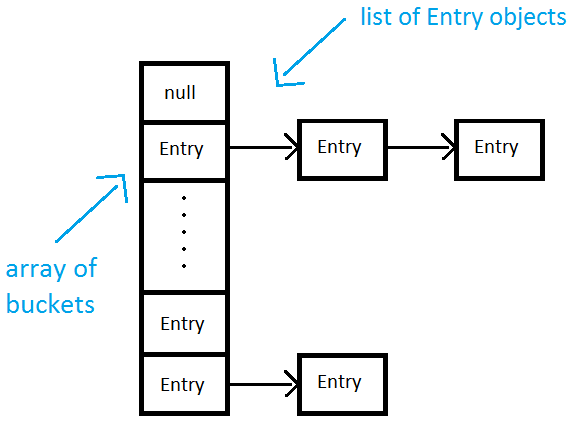
HashMap은 내부적으로 Entry<K,V>[] Entry Array로 구성되어 있다. Array의 index를 hash 함수를 통해 계산한다.
위 그림처럼 Entry로 저장이 되는데, 내부적으로 Hash 값에 의해 어떤 Bucket에 담길지 결정이 된다. 만약 Hash 값이 같다면 같은 Bucket에 List로 연결될 것이다.(마치 LinkedList처럼 Entry 안에 next Entry를 저장하는 변수가 있음)
HashMap 은 Hash 값을 이용하여 저장하기 때문에 순서를 보장하지 않는다고 했다. get() 메서드는 Hash 값으로 해당 Array에 바로 접근이 가능하기 때문에 성능은 O(1)으로 빠르다. 그래서 HashMap 은 입력과 삭제에 대해 시간복잡도가 O(1)인 자료구조를 가지고 있다.
HashMap 선언
HashMap<String,String> map1 = new HashMap<String,String>();//HashMap생성
HashMap<String,String> map2 = new HashMap<>();//new에서 타입 파라미터 생략가능
HashMap<String,String> map3 = new HashMap<>(map1);//map1의 모든 값을 가진 HashMap생성
HashMap<String,String> map4 = new HashMap<>(10);//초기 용량(capacity)지정
HashMap<String,String> map5 = new HashMap<>(10, 0.7f);//초기 capacity,load factor지정
HashMap<String,String> map6 = new HashMap<String,String>(){{//초기값 지정
put("a","b");
}};HashMap을 생성하려면 위와 같이 키 타입과 값 타입을 파라미터로 주고 기본생성자를 호출한다.
HashMap은 저장공간보다 값이 추가로 들어오면 List와 같이 저장공간을 추가로 늘리지만, List와 다르게 한 칸씩 늘리지 않고 약 두배로 늘리기 때문에🤦♀️ 여기서 과부하가 많이 발생한다. 그렇기에 초기에 저장할 데이터 개수를 알고 있다면 Map의 초기 용량을 지정해주는 것이 좋다.
HashMap 값 추가
HashMap<Integer,String> map = new HashMap<>();//new에서 타입 파라미터 생략가능
map.put(1,"사과"); //값 추가
map.put(2,"바나나");
map.put(3,"포도");HashMap에 값을 추가하려면 위와 같이 Key와 Value를 파라미터로 주는 Put 메소드를 사용한다.
HashMap 선언 시에 설정한 타입과 같은 타입의 Key,Value를 넣어야 하며 입력하는 Key 값이 이미 내부에 존재한다면 기존의 Value는 새로 입력되는 Value로 변경된다.
HashMap 값 삭제
HashMap<Integer,String> map = new HashMap<Integer,String>(){{//초기값 지정
put(1,"사과");
put(2,"바나나");
put(3,"포도");
}};
map.remove(1); //key값 1 제거
map.clear(); //모든 값 제거HashMap에서 값을 제거하려면 key를 파라미터로 주는 remove(key) 메소드를 사용한다.
모든 값을 제거하려면 clear() 메소드를 사용하면 된다.
HashMap 값 출력
// HashMap 선언, 초기값 지정
HashMap<Integer,String> hm = new HashMap<Integer,String>(){{
put(1, "One");
put(2, "Two");
put(3, "Three");
put(4, "Four");
}};
System.out.println(hm); // 전체 출력 : {2=Two, 3=Three, 4=Four}
System.out.println(hm.get(3)); // Key 값 3의 Value 가져오기 : Three
//entrySet() 활용
for(Map.Entry<Integer,String> entry : hm.entrySet()) {
System.out.println("Key :" + entry.getKey() + " Value :" + entry.getValue());
}//출력결과
//Key :1 Value :One
//Key :2 Value :Two
//Key :3 Value :Three
//Key :4 Value :Four
//keySet() 활용
for (int i : hm.keySet()) {
System.out.println("Key :" + i + " Value :" + hm.get(i));
}//출력결과
//Key :1 Value :One
//Key :2 Value :Two
//Key :3 Value :Three
//Key :4 Value :Four-
특정 Key의 Value를 가져오고 싶다 : get(key)
get() 메서드는 Hash 값으로 해당 Array에 바로 접근이 가능하기 때문에 성능은 O(1)으로 빠르다.
-
Key와 Value가 모두 필요하다, 전체를 출력하고싶다 : entrySet() 또는 keySet() 메소드를 활용하여 Map의 객체를 반환받은 후 출력할 수 있다.
entrySet()은 Key와 Value로 구성된 Entry의 Set을 받기 때문에 Key와 Value가 모두 필요한 경우 사용한다. -
Key만 필요하다 : keySet() 은 Key의 Set을 반환받기 때문에 Key 값만 필요할 경우 사용하는데, 위의 코드와 같이 get(key) 메소드를 통해 Value까지 받아올 수도 있다.
keySet()을 활용하여 value까지 찾을 경우, key 값을 이용해서 value를 찾는 과정에서 시간이 많이 소모되기 때문에 많은 양의 데이터를 가져와야 한다면 entrySet()이 좋다.
-
HashMap의 전체출력 : 반복문을 사용하지 않고 Iterator를 사용할 수 있다. iterator로 Map안의 전체 요소를 출력하는 방법은 아래와 같다.
Iterator<Integer> keys = map.keySet().iterator();
while(keys.hasNext()){
int key = keys.next();
System.out.println("[Key]:" + key + " [Value]:" + map.get(key));
}
//[Key]:1 [Value]:사과
//[Key]:2 [Value]:바나나
//[Key]:3 [Value]:포도특정의 key value 다루기
HashMap의 put(key,value) 메소드와 get(key) 메소드를 이용해서 특정 key의 value를 순차적으로 증가시킬 수도 있다.
HashMap<String, Integer> hm = new HashMap<String, Integer>() {{
put("사과", 15);
put("바나나", 12);
}};hm.put("사과", hm.get("사과")+1); // "사과" key의 value를 1 증가시킨다.
System.out.println(hm.get("사과")); // 사과 개수 : 16원래 있던 key 값으로 put을 하면 value가 변경되는 것을 이용해서 (원래의 value값 + 1)을 value로 넣는다.
🤷♀️ 그렇다면, 원래 없던 key 값을 위의 코드로 value를 증가시켜본다면?
hm.put("파인애플", hm.get("파인애플")+1);
System.out.println(hm.get("파인애플"));NullPointerException이 발생한다.
hm에는 파인애플이라는 key가 존재하지 않고, get("파인애플") 메소드를 사용하면 Null이 발생하기 때문이다.
이를 방지하기 위해 우리는 getOrDefault(key, defaultValue) 메소드를 사용할 수 있다.
hm.put("파인애플", hm.getOrDefault("파인애플",0)+1);
System.out.println(hm.get("파인애플")); // 출력결과 : 1getOrDefault는 key와 defaultValue를 파라미터로 받는 메소드로, 지정된 key에 매핑된 value가 없거나 null이면 defaultValue를 반환하는 메소드이다. 만약 위의 파인애플처럼 HashMap에 존재하지(매핑돼있지) 않는 key의 value를 가져오려고 시도하면 defaultValue를 기본값으로 HashMap에 key를 새로 만든다.
HashMap 특정 키 포함 여부
// HashMap 선언, 초기값 지정
HashMap<Integer,String> hm = new HashMap<Integer,String>(){{
put(1, "One");
put(2, "Two");
put(3, "Three");
put(4, "Four");
}};
System.out.println(hm.containsKey(4)); // Key 값 4 포함 여부 : true
System.out.println(hm.containsKey(5)); // Key 값 5 포함 여부 : false특정 키가 존재하는지 존재하지 않는지 알고 싶을 때는 containsKey(key) 메소드를 사용한다.
존재한다면 true, 존재하지 않는다면 false를 리턴한다.
비슷한 메소드로, 특정 value가 존재하는지 확인할 수 있는 containsValue(value) 메소드가 있다.
HashMap 비교
두 Map이 같은지 비교하려면 equals() 메소드를 사용한다. 두 Map의 매핑 상태가 같다면 true, 같지 않다면 false를 리턴한다.
// HashMap 선언, 초기값 지정
HashMap<Integer,String> hm1 = new HashMap<Integer,String>(){{
put(1, "One");
put(2, "Two");
}};
HashMap<Integer,String> hm2 = new HashMap<Integer,String>(){{
put(1, "One");
put(2, "Two");
}};
HashMap<Integer,String> hm3 = new HashMap<Integer,String>(){{
put(1, "One");
put(3, "Three");
}};
System.out.println(hm1.equals(hm2)); // 출력결과 : true
System.out.println(hm1.equals(hm3)); // 출력결과 : falseTreeMap
TreeMap은 이진트리를 기반으로 한 Map 컬렉션이다.
TreeMap에 객체를 저장하면 자동으로 정렬되는데, 키는 저장과 동시에 자동 오름차순으로 정렬된다.
- 숫자(Integer, Double) 타입일 경우에는 값으로 정렬하고
- 문자열(String) 타입일 경우에는 유니코드로 정렬한다.
📌 정렬기준 : 숫자 > 알파벳 대문자 > 알파벳 소문자 > 한글
정렬 순서는 기본적으로 부모 키값과 비교해서 키 값이 낮은 것은 왼쪽 자식 노드에, 키값이 높은 것은 오른쪽 자식 노드에 Map.Etnry 객체를 저장한다.
TreeMap은 SortedMap 인터페이스를 구현하고 있어, 데이터를 저장할 때 즉시 정렬하기에 추가나 삭제가 HashMap보다 오래 걸린다. 하지만 정렬된 상태로 Map을 유지해야 하거나 정렬된 데이터를 조회해야 하는 범위 검색이 필요한 경우에는 TreeMap을 사용하는 것이 효율성면에서 좋다.
🤷♀️ 그럼 이놈은 어떻게 key를 정렬할 수 있는 것일까?
👉 TreeMap는 내부에 레드-블랙 트리(Red-Black Tree)의 자료구조를 이용하기 때문이다.
Red Black Tree

레드-블랙 트리는 이진탐색트리의 문제점을 보완한 트리이다.
일반적인 이진 탐색 트리는 트리의 높이만큼 시간이 걸린다.
값이 전체 트리에 잘 분산되어 있다면 효율성에 있어 크게 문제가 없으나, 데이터가 들어올 때 값이 한쪽으로 편향되게 들어올 경우, 한쪽 방면으로 크게 치우쳐진 트리가 되어 굉장히 비효율적이게 되버리는 것이다.(기존의 O(logN)의 탐색속도가 최악의 경우 O(N)으로 되버림 => 시간복잡도가 O(N)이라는 것은 이진탐색 트리의 모든 노드를 한번씩 확인해야한다는 말이다.)
레드 블랙 트리는 스스로 균형을 잡는 트리다. 부모 노드보다 작은 값을 가지는 노드는 왼쪽 자식으로, 큰 값을 가지는 노드는 오른쪽 자식으로 배치하여 데이터의 추가나 삭제 시 트리가 한쪽으로 치우쳐지지 않도록 균형을 맞추어준다.(최악의 경우에도 O(logN)으로 나오게 함)
TreeMap 선언
생성하는 명령어는 HashMap과 크게 다르지 않으나 선언 시 크기를 지정해줄 수 없다.
TreeMap<Integer,String> map1 = new TreeMap<Integer,String>();//TreeMap생성
TreeMap<Integer,String> map2 = new TreeMap<>();//new에서 타입 파라미터 생략가능
TreeMap<Integer,String> map3 = new TreeMap<>(map1);//map1의 모든 값을 가진 TreeMap생성
TreeMap<Integer,String> map6 = new TreeMap<Integer,String>(){{//초기값 설정
put(1,"a");
}};TreeMap 값 추가
TreeMap<Integer,String> map = new TreeMap<Integer,String>();//TreeMap생성
map.put(1, "사과");//값 추가
map.put(2, "복숭아");
map.put(3, "수박");TreeMap은 구조만 HashMap과 다를 뿐 기본적으로 Map 인터페이스를 같이 상속받고 있으므로 기본적인 메소드의 사용법 자체는 HashMap과 동일하다. 입력되는 키 값이 TreeMap 내부에 존재한다면 기존의 값은 새로 입력되는 값으로 대치된다.
TreeMap 단일 값 출력
TreeMap<Integer,String> map = new TreeMap<Integer,String>(){{//초기값 설정
put(1, "사과");//값 추가
put(2, "복숭아");
put(3, "수박");
}};
System.out.println(map); //전체 출력 : {1=사과, 2=복숭아, 3=수박}
System.out.println(map.get(1));//key값 1의 value얻기 : 사과
System.out.println(map.firstEntry());//최소 Entry 출력 : 1=사과
System.out.println(map.firstKey());//최소 Key 출력 : 1
System.out.println(map.lastEntry());//최대 Entry 출력: 3=수박
System.out.println(map.lastKey());//최대 Key 출력 : 3TreeMap을 그냥 print하게 되면 { }로 묶어 Map의 전체 key값, value가 출력된다.
특정 key값의 value를 가져오고 싶다면 get(key) 를 사용하면 된다.
TreeMap은 HashMap과 달리 Tree구조로 이루어져 있기에 항상 정렬이 되어있어 최소값,최대값을 바로 가져오는 메소드를 지원한다.
✔ firstEntry는 최소 Entry값, firstKey는 최소 Key값,
✔ lastEntry는 최대 Entry값, lastKey는 최대 Key값을 리턴한다.
클래스 상속 구조
아까 TreeMap 은 키값에 따라 오름차순으로 자동정렬된다고 했다.
자동? 👩 그럼 우리는 이것을 내림차순으로 정렬해보고 싶은 욕구가 든다.🤸♀️
내림차순으로 정렬하고 싶을때 어떻게 해야할까??
TreeMap 의 클래스 상속 구조를 잠깐 살펴보자.
public class TreeMap<K,V>
extends AbstractMap<K,V>
implements NavigableMap<K,V>, Cloneable, java.io.SerializableTreeMap은 HashMap과 동일하게 AbstractMap을 상속받고 있다.
여기서 다른건 TreeMap은 NavigableMap을 implements 받고 있다. NavigableMap은 정렬된 Map에서 여러가지 방법의 탐색을 제공한다.

위와같이 NavigableMap은 오름차순과 내림차순으로 번갈하며 정렬 순서를 바꾸는 descendingMap() 메소드를 제공한다.
이외에도 firstEntry(), lastEntry(), lowerEntry(), higherEntry(), floorEntry(), ceilingEntry() 이 있당
암튼 TreeMap을 내림차순 하고 싶다면 descendingMap() 메서드를 사용하면 된다. 이 메서드는 리턴 값이 NavigableMap이기 때문에 해당 구조로 다시 한번 감싸 주어야 한다.
public class main {
public static void main(String[] args) {
TreeMap<Integer, String> tMap = new TreeMap<Integer, String>();
tMap.put(5, "fff");
tMap.put(3, "bbb");
tMap.put(2, "ccc");
tMap.put(7, "ddd");
tMap.put(1, "aaa");
NavigableMap<Integer, String> desc = tMap.descendingMap();
Set<Map.Entry<Integer,String>> descS = desc.entrySet();
for(Map.Entry<Integer,String> entry1 : descS) {
System.out.println(entry1.getKey() + " " + entry1.getValue());
}
}
}NavigableMap로 감싸준 TreeMap을 하나씩 출력해주기 위해서 entrySet으로 묶은 후 for문으로 하나씩 뽑아 출력해 본다.
7 ddd
5 fff
3 bbb
2 ccc
1 aaaComparable
키값에 대한 Compartor 구현으로도 정렬 순서를 바꿀수 있다.
TreeMap의 키는 저장과 동시에 자동 오름차순 정렬된다고 했다.
정렬을 위해 java.lang.Comparable을 구현한 객체를 요구하는데... implements Comparable 하라는 말이다.
💁♀️ 우리에게 친숙한 Integer, Double, String은 모두 Comparable 인터페이스를 구현하고 있다.
사용자 정의 클래스도 Comparable을 구현하게 되면 자동 정렬을 할 수 있다.
Comparable에는 compareTo() 가 정의되어 있어서 이 메소드를 사용자 정의 클래스에서 오버라이딩하여 사용할 수 있다.

나이를 기준으로 Person 객체를 오름차순으로 정렬하기 위해 Comparable 인터페이스를 구현한예제를 함 보자.
Person 객체 만들어주고 Comparable 인터페이스를 구현해서 compareTo() 메소드를 재정의해준다.
public class Person implements Comparable<Person> {
public String name;
public int age;
public Person(String name, int age) {
this.name = name;
this.age = age;
}
@Override
//compareTo() 메소드 재정의
public int compareTo(Person o) {
if (age < o.age) return -1; //나이가 적을 경우는 -1
else if (age == o.age) return 0; //동일한 경우는 0
else return 1;// 클 경우는 1을 리턴
}
}import java.util.Iterator;
import java.util.TreeSet;
public class ComparableExample {
public static void main(String[] args) {
TreeSet<Person> treeSet = new TreeSet<Person>();
treeSet.add(new Person("김", 45));
treeSet.add(new Person("이", 25));
treeSet.add(new Person("최", 31));
Iterator<Person> iterator = treeSet.iterator();
while (iterator.hasNext()) {
Person person = iterator.next();
System.out.println(person.name + ": " + person.age);
}
}
}👉 결과
이:25
최:31
김:45TreeSet의 객체와 TreeMap의 키가 Comparable을 구현하고 있지 않을 경우, 저장하는 순간 ClassCastException이 발생한다.
🤷♀️ 아니 그럼 Comparable 비구현객체는 어떻게 정렬할까?
TreeSet 또는 TreeMap 생성자의 매개값으로 정렬자(Comparator)를 제공하면 Comparable 비구현 객체도 정렬 시킬 수 있다.
TreeMap<K ,V> treeMap = new TreeMap<K, V>(new DescendingComparator() );Comparable 비구현 과일객체 하나 만들어보자
public class Fruit {
public String name;
public int price;
public Fruit(String name, int price) {
this.name = name;
this.price = price;
}
}내림차순으로 정렬해주는 정렬자 만들어준다.
import java.util.Comparator;
public class DescendingComparator implements Comparator<Fruit> {
@Override
public int compare(Fruit o1, Fruit o2) {
if (o1.price < o2.price) return 1;
else if (o1.price == o2.price) return 0;
else return -1;
}
}import java.util.Iterator;
import java.util.TreeSet;
public class ComparatorExample {
public static void main(String[] args) {
TreeSet<Fruit> treeSet = new TreeSet<Fruit>(new DescendingComparator()); //내림차순 정렬자 제공
treeSet.add(new Fruit("포도", 3000));
treeSet.add(new Fruit("수박", 10000));
treeSet.add(new Fruit("딸기", 6000));
Iterator<Fruit> iterator = treeSet.iterator();
while (iterator.hasNext()) {
Fruit fruit = iterator.next();
System.out.println(fruit.name + ": " + fruit.price);
}
}
}결과를 보면 가격을 기준으로 내림차순 된 것을 볼 수 있다.
수박: 10000
딸기: 6000
포도: 3000HashMap TreeMap의 차이
아.. 결국 이 포스팅의 주요 쟁점은 이거였는데 🤦♀️ 너무 길어진것 같지만 그래도 할건해야지..
자, 여기까지 HashMap과 TreeMap을 알아봤다. 이 둘의 주요 차이점은 정리하자면 다음과 같다.
-
HashMap은 Hashing을 이용하여 저장하기 때문에 순서를 보장하지 않는다. TreeMap은 데이터(entry)를 Red-Black 트리 형태로 저장하여 저장할 때 키값을 기준으로 자동으로 정렬되어 저장한다.
-
HashMap은 하나의 null 키와 많은 null values를 저장할 수 있다. TreeMap은 null 키를 포함 할 수 없지만 많은 null 값을 포함 할 수 있다.
-
HashMap은 해시를 이용하여 배열(Array)에 접근 가능하므로, O(1)과 같은 get과 put 같은 기본 연산에 대해 일정한 시간 성능을 나타낸다. TreeMap은 트리 구조의 특성상 특정 엔트리에 접근하기 위해서는 get 및 put 메소드에 대한 log (n) 시간 보장 비용을 제공한다.
=> HashMap의 성능 시간은 대부분의 작업에서 TreeMap에 대해 일정하므로 HashMap은 TreeMap보다 훨씬 빠르다.
참고자료:
https://coding-factory.tistory.com/556
https://velog.io/@bbaekddo/cs-3
https://seeminglyjs.tistory.com/227
https://sabarada.tistory.com/139
https://velog.io/@mmy789/Java-컬렉션-프레임워크-5
https://cornswrold.tistory.com/203

c언어만 알고있는 코딩 초보인데 뭐라는건지 하나도 못알아듣겠음