DAO / DTO 는 많이 들었는데, JPA 관점에서 왜 사용해야하는가?에 대한 내용을 다루려고 한다.
Entity
일단 JPA에서 주로 사용되는 개념인 Entity에 대해서 알아보자.
Entity는 DB의 테이블에 존재하는 Column들을 필드로 가지는 객체를 뜻한다.
Entity class 는 실제 데이터베이스이 테이블과 1:1 매칭되는 클래스를 뜻한다.
=> Entity class를 보면 해당 DB Table의 정보를 거의 알 수 있다.
Entity는 DB table에 존재하는 컬럼만을 속성(필드)로 가져야 한다. 또한 테이블에 존재하지 않는 컬럼을 가져서도 안되며, 상속이나, 구현체여서도 안된다.
DAO
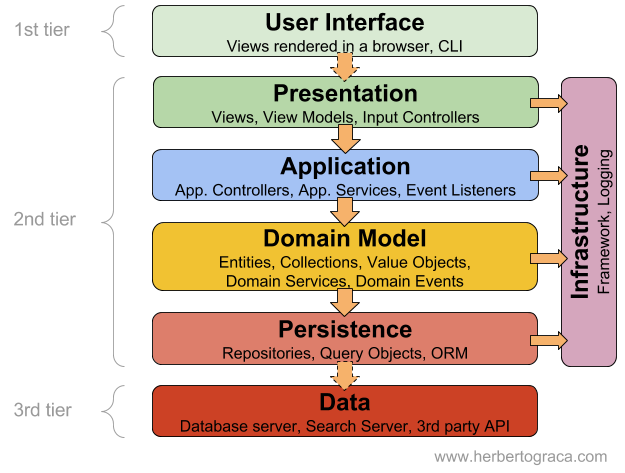
DAO는 Data Access Object로 실제로 DB에 접근하는 객체이다.
![]
)
Service와 실제 데이터베이스를 연결하는 역할로, Persistence Layer(DB에 data를 CRUD하는 계층)이다.
JPA의 경우, Repository가 DAO의 역할을 한다고 볼 수 있다.
DAO의 사용이유
음음 DAO는 실제 DB에 접근하는 놈이구만.. 근데 이놈이 왜 필요할까?
1. 효율적인 커넥션 관리
웹서버는 DB와 연결하기 위해서 매번 커넥션 객체를 생성하는데, 이것을 해결하기 위해 나온것이 커넥션 풀이다.
ConnectionPool 이란 connection 객체를 미리 만들어 놓고 가져다 쓰는것이다. 또 다쓰고 난 후에는 반환해 놓는다.
하지만 유저 한명이 접속해서 한번에 하나의 커넥션만 일으킬까?
게시판 하나만 봐도 목록볼때 한번, 글읽을때마다 한번, 글쓸때 한번 등등… 엄청나게 많은 커넥션이 일어난다. 커넥션풀은 커넥션을 또 만드는 오버헤드를 효율적으로 하기 위해 DB에 접속하는 객체를 전용으로 하나만 만들고, 모든 페이지에서 그 객체를 호출해다 사용하면서 부담을 줄이는 것이다.
이렇게 커넥션을 하나만 가져오고 그 커넥션을 가져온 객체가 모든 DB와의 연결을 하는것이 바로 DAO객체이다.
DB에 대한 접근을 DAO가 담당하도록 하여 데이터베이스 엑세스를 DAO에서만 하게 되면 다수의 원격호출을 통한 오버헤드를 VO나 DTO를 통해 줄일 수 있고 다수의 DB 호출문제를 해결할 수 있다.
2. JPA가 DAO를 사용해야할 때
위는 기본적인 DAO가 사용되어야하는지의 이유였고, 이번에 JPA관점에서 왜 DAO를 사용해야하는지 설명한다.
일단 이 질문에 답하려면 DAO 와 Repository의 미묘한 차이를 알아야 한다.
이 둘은 Data Access를 한다는 점에서 보통 거의 같다고 간주되어 실제 개발할때에는 비슷하게 사용되지만, 깊이있게 알아보면 차이가 있다는 걸 볼 수 있다.
-
DAO Pattern은 Data Persistence의 추상화이며, 데이터에 접근하도록 DB접근 관련 로직을 모아둔 데이터 저장소에 더 가깝다고 할 수 있다.
-
반면에 Repository는 엔티티 객체를 보관하고 관리하는 저장소로써, 인터페이스를 제공한다는 점에서 DB 보다는 객체 중심의 Layer라고 할 수 있다.
-
DAO는 데이터 맵핑/접근 계층으로 쿼리를 숨기지만, Repository는 Domain과 DAL사이의 계층으로 데이터를 대조하고 Domain객체로 Mapping하는 로직을 숨긴다.
🤷♂️ 그럼 JPA에서 언제 DAO를 사용해야할까?
Repository는 주로 CRUD 작업을 다룬다. 그러나 특정 비즈니스 로직이 복잡한 쿼리나 연산을 필요로 하는 경우, 이를 Repository 인터페이스에 단순히 추가하는 것은 어려울 수 있다. 이 경우 DAO 패턴을 사용하여 비즈니스 로직에 집중할 수 있다.
특정 비즈니스 로직이 여러 도메인 객체 간의 관계를 다루는 경우, Repository 패턴만으로는 이러한 복잡성을 충분히 다루기 어려울 수 있다.
이때, DAO를 사용하여 객체 여러 개의 Repository를 조합하거나 복합 쿼리를 실행할 수 있다.
DTO
DTO(Data Transfer Object)는 말 그대로 데이터를 transfer하기 위한 객체이다.
Client가 Controller에 요청을 보낼 때도 RequestDto의 형식으로 데이터가 이동하고, Controller가 Client에게 응답을 보낼 때도 ResponseDto의 형태로 데이터를 보내게 된다.
닉값 그대로 데이터를 교환하는 목적을 갖는 객체이기 때문에, 서비스 로직을 갖고 있지 않다.
순수한 Data 객체이며 일반적으로 getter/setter 메서드만을 가진다. 하지만 교환만 할건디 setter로 굳이 값을 수정할 필요가 없다. 생성자만을 사용하여 값을 할당하는 방식이 권장된다.
VO(Value Object) vs DTO
VO는 DTO와 동일한 개념이지만 read only 속성을 갖는다.(사용하는 도중에 변경 불가능하며 오직 읽기만 가능하다.)
VO는 특정한 비즈니스 값을 담는 객체이고, DTO는 Layer간의 통신 용도로 오고가는 객체를 말한다.
DTO의 사용이유
🤷♂️근데 왜 Entity를 직접 쓰지 않고 DTO를 사용하는 걸까?
1. 관심사의 분리(Separation of Concerns, SoC)
Entity는 Data Access layer 에서 데이터가 저장되는 DB와 직접적으로 관련되어 있는 객체다.
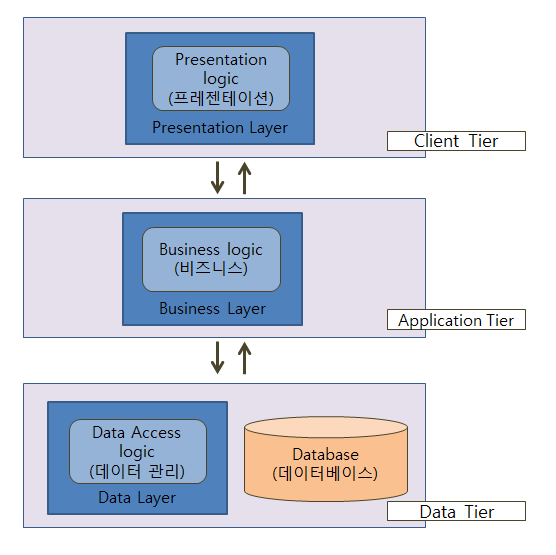
테이블과 1:1대응되는 설계되는 Entity는 되도록 최대한 수정되지 않는 것이 안정적인 도메인 모델이다.
하지만 Presentation layer 에서는 Client(View)의 요구사항에 따라 전달되는 데이터의 구조가 빈번하게 바뀔 수 있다.
또한 비밀번호나 개인정보 같은 민감한 정보들은 굳이 View에 전달할 필요가 없다. 물론 노출되어서도 안됨.
이러한 layer의 차이는 각 layer의 관심사가 달라서 생긴다.
관심사에 맞게 데이터를 담는 객체도 구분되어야하는 것이다. 이를 객체 지향에서는 관심사의 분리(SoC) 라고 한다.
DTO의 관심사는 닉만 봐도 알수있다. 데이터의 전달이다. 다른 계층에 데이터를 전달하는 것이 이놈의 역할이기 때문에 Presentation layer에 속한다.
반면에 Entity는 핵심 비지니스 로직을 담는 도메인의 영역이다. 즉, Entity는 Business 계층에 속하며, 다른 계층 사이에서 전달을 위해 사용되는 객체가 아니다.
이와 같이 DTO와 Entity는 엄연히 서로 다른 관심사를 가지고 있기때문에, 분리해서 사용하는 것이 합리적이다. 이로 인해 의도치 않은 데이터의 변경이나 노출, 오류를 예방 할 수 있다.
2. 안정적인 도메인 설계
그럼 도메인을 겁나 잘 설계해서 View단에 넘겨주면 안되나?? 싶겠지만 Entity의 Getter 만을 이용해서 원하는 정보를 표시하기가 쉽지 않다.
그럼 이런 경우에 Presentation layer를 위한 필드나 로직을 Entity class에 추가해야 하는데, 이렇게 되면 객체 설계를 망가뜨릴 수 있다.
ex) 이메일주소를 변경하는 요청을 고려한다면, originEmail, afterEmail값을 받아야 할 것인데, 이를 Entity에 갖게하는 것은 동일 속성값(이메일)을 두개 갖게 되는 것이다.
따라서 DTO에 표현을 위한 로직을 추가해서 사용하는 것이 Entity의 도메인 모델링을 지킬 수 있다.
