[논문리뷰] X-Mesh: Towards Fast and Accurate Text-driven 3D Stylization via Dynamic Textual Guidance (CVPR 2023)
3D Mesh Stylization
Abstract
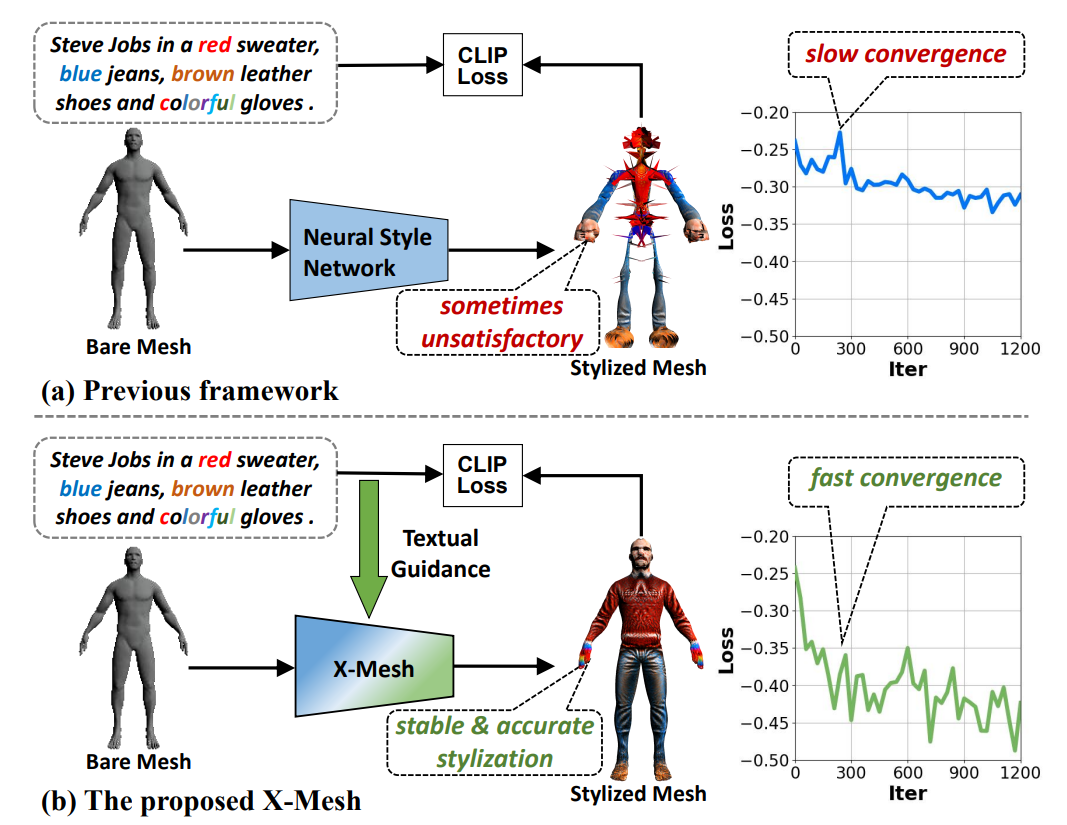
텍스트 기반 3D Stylization은 컴퓨터 비전에서 중요한 과제입니다. 이 Task는 Mesh에 목표 Text에 맞는 스타일을 입히는 것입니다. 기존 방법들은 텍스트와 독립적인 MLP 구조를 사용해 CLIP Loss 기반으로 Mesh의 속성을 예측합니다. 다만, 이러한 구조는 Text의 지도가 부족하여 만족스럽지 못한 스타일과 느린 학습을 초래합니다. 이러한 한계의 해결을 위해 저자는 X-Mesh라는 프레임워크를 제안합니다. X-Mesh는 Attention기반의 모듈인 Text-guided Dynamic Attention Module (TDAM)을 제안하여 더 정확한 예측과 빠른 수렴을 제공합니다. 또한, 기존 연구는 표준 벤치마크와 자동화된 평가 지표가 없어, 주관적인 User Study에 의존합니다. 이러한 제한의 극복을 위해 표준 텍스트-Mesh 벤치마크인 MIT-30을 제안하며, 자동화된 두가지 지표를 제안합니다.
1. Introduction
최근 몇 년간, 텍스트 및 이미지에 맞게 Mesh 스타일을 변형하는 Task는 컴퓨터 비전 분야에서 많은 주목을 받았습니다. 이렇게 스타일화된 3D Asset은 게임, 가상현실, 영화 등 다양한 실용적인 응용이 가능합니다. 특히, Text 기반의 스타일화는 이미지나 3D 형태기반 보다 더 쉽게 사용이 가능하기에 사용자 친화적입니다.
CLIP의 등장으로 Text 기반의 3D Stylization의 실현이 가능하게 되었습니다. Text2Mesh와 TANGO는 CLIP 손실의 기반으로 Mesh Vertex의 파라미터를 예측하여 이를 달성했습니다. 하지만, 기존의 방법들은 그 효과와 효율성을 저해하는 한계를 가지고 있습니다. 주요 단점 중 하나는 입력 텍스트의 의미를 완전히 고려하지 못한다는 것입니다. 파라미터 예측 단계에서 추가적인 텍스트 의미의 지도를 제공하지 않기 때문에, 예측된 정점 속성이 목표 텍스트 프롬프트의 의미적 맥락과 일치하지 않아 일관성 없는 스타일 생성을 초래합니다. 또한, 이전 방법들은 이러한 단점 때문에 수렴 속도에도 큰 영향을 미칩니다.
이러한 점을 개선하기 위해 우리는 X-Mesh 프레임워크를 제안합니다. TDAM 모듈을 제안하여 목표 텍스트와 일치하는 고품질의 스타일화된 3D Asset을 더욱 빠르게 생성할 수 있습니다.
또한, 기존의 방법들은 평가를 위해 인간의 주관적 평가에 의존하는 User Study를 진행했습니다. 이를 극복하기 위해, 새로운 Text-Mesh 벤치마크인 MIT-30을 제안합니다. 30개의 기본 Mesh 카테고리를 포함하며, 각 카테고리는 다양한 스타일화를 위해 5개의 다른 텍스트 프롬프트 주석이 달려 있습니다. 이 벤치마크 데이터셋을 통해 두 가지 평가지표를 제안합니다. 먼저, 고정된 고도와 방위각에서 스타일화된 3D Mesh의 24개의 이미지를 렌더링합니다. 이를 통해 Multi-view Expert Score (MES)를 평가하고, 목표 점수까지의 반복 횟수를 나타내는 ITS 지표또한 평가하게 됩니다.
이 논문은 두가지 주요 기여를 제시합니다:
- 우리는 3D 스타일화의 정확도와 수렴 속도를 개선하기 위해 새로운 텍스트 가이드 동적 주의 모듈(TDAM)을 포함하는 X-Mesh를 제안합니다.
- 우리는 표준 벤치마크를 구성하고 두 가지 자동 평가 지표를 제안하여 텍스트 기반 3D 스타일화 기술의 객관적이고 재현 가능한 평가를 가능하게 하고, 이 연구 분야의 발전에 기여할 수 있습니다.
2. Related Works
2-1. Text-to-Image Manipulation/Generation
여러 이전 연구들은 GAN과 CLIP을 결합하여 텍스트-이미지 생성을 시도했습니다. 구체적으로, StyleGAN은 잠재 공간을 중점적으로 다루어 생성된 이미지에 대한 더 나은 제어를 가능하게 합니다. StyleGAN을 기반으로 한 StyleCLIP은 CLIP의 지도를 활용하여 텍스트-이미지 생성을 실현합니다.
한편, Diffusion 모델은 이미지 생성에 큰 기여를 했습니다. DALL-E와 CogView는 변압기 및 병렬 자회귀 아키텍처를 기반으로 합니다. GLIDE는 미세 조정 후 이미지 생성 및 복원을 위해 분류기 없는 지도를 활용합니다. DALL-E2는 텍스트 프롬프트를 주어 텍스트 특성에 따라 이미지 특성을 인코딩한 후, 확산 모델을 통해 이를 디코딩하여 원본 및 현실적인 이미지를 생성합니다.
2-2. Text-to-3D Manipulation/Generation
텍스트-이미지 기술의 발전으로 텍스트-3D 생성 분야도 큰 진전을 이루었습니다. 이 중 NeRF 기반 방법들은 CLIP과 결합할 때 특히 좋은 성능을 보였습니다. 이러한 방법의 몇 가지 주목할 만한 예로는 CLIP-NeRF, PureCLIPNeRF, DreamFields 등이 있습니다. 또한, 최근 연구들은 CLIP과 다른 알고리즘의 융합을 탐구했으며, ISS와 SVR, CLIP-Forge는 정규화 흐름 네트워크를 사용하고, AvatarCLIP은 SMLP를 활용합니다. 최근에는 확산 모델이 텍스트-이미지 생성에서 인상적인 결과를 보여 텍스트-3D 생성 과정에 통합되었습니다. DreamFusion, Magic3D, Dream3D와 같은 연구들이 확산 모델을 생성 과정에 통합한 예입니다.
또한, 메시 기반 스타일화도 그 광범위한 적용 가능성 때문에 널리 연구되고 있습니다. 전통적으로, 컴퓨터 그래픽스에서 기본 메시를 스타일화하려면 빛의 밝기, 반사 등 그래픽스 분야의 전반적인 전문 지식이 필요했습니다. 그러나 최근 연구들은 텍스트 프롬프트를 사용하여 3D 표현을 스타일화하는 자동화 방법에서 진전을 이루었습니다. 예를 들어, CLIP-Mesh는 CLIP을 사용해 3D Asset 생성을 실현합니다. TANGO는 빛의 반사 관련 파라미터를 통합하지만 형태 조작에서는 한계를 보였습니다. 반면 Text2Mesh는 각 정점의 색상과 변위를 예측하여 강력한 스타일화를 실현합니다. 저자는 정점 속성 예측 단계에서 TDAM을 제안하여 더 나은 스타일링 효과를 제공할 뿐만 아니라 빠른 수렴 속도를 달성하였습니다.
2-3. Attention Mechanism
Attention 매커니즘은 딥러닝에서 널리 사용되는 기술로, CV, NLP, Multimodal 분야 등 다양한 작업에 적용되었습니다. 이 개념은 기계 번역 분야에서 디코딩 단계마다 Source Text의 다른 부분에 집중하는 모델을 제안하며 처음 도입되었습니다. 이후, 다양한 매커니즘이 추가적으로 제안되어 모델의 성능을 향상 시켰습니다. 본 논문에서는 Text Guidance를 위한 Attention 매커니즘의 사용을 제안하여 입력 메시의 정점 및 정보를 목표 Text Prompt에 맞게 동적으로 집중하게 합니다.
3. Approach
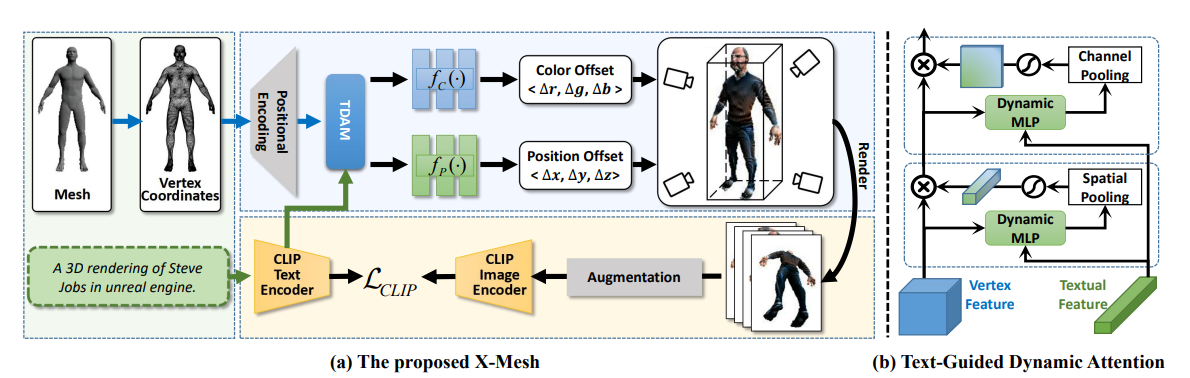
3-1. Architecture
X-Mesh는 입력된 텍스트에 맞춰 3D 메시의 외형과 형태를 변형시키는 혁신적인 시스템입니다. 간단히 말해, 입력된 텍스트 설명에 따라 3D 모델의 색상과 모양을 바꿔주는 기술입니다. 예를 들어, "붉은 스웨터를 입은 스티브 잡스"라는 텍스트가 주어지면, X-Mesh는 이를 반영한 3D 모델을 생성합니다.
먼저, 모든 정점의 색상을 중간 회색으로 초기화하고, 각 정점의 좌표를 단위 크기로 맞춥니다. 그런 다음, 고주파 세부사항을 추가하기 위해 푸리에 변환을 사용하여 각 정점의 위치를 인코딩합니다. 이 인코딩된 위치 정보는 두 개의 인공지능 모델(MLP)을 통해 처리되어, 정점의 색상과 위치를 예측합니다. 최종적으로, 입력된 텍스트 설명에 맞춰 변형된 3D 모델이 만들어집니다.
3-2. TDAM
기존의 텍스트 기반 3D 스타일화 기술은 입력된 텍스트를 충분히 활용하지 못해, 결과물이 만족스럽지 않거나 학습 속도가 느린 문제가 있었습니다. 이를 해결하기 위해 X-Mesh는 TDAM이라는 새로운 모듈을 도입했습니다. TDAM은 텍스트의 지도를 받아 3D 모델의 정점 속성을 더 정확하게 예측하도록 도와줍니다.
TDAM은 동적 선형 계층을 사용하여 텍스트 입력에 따라 변형 규칙을 실시간으로 생성합니다. 이 모듈은 정점의 색상과 위치를 예측할 때, 텍스트와 관련된 공간적 및 채널적 주의를 모두 적용합니다. 간단히 말해, 텍스트 설명을 반영하여 3D 모델의 각 부분을 더 정밀하게 조정합니다.
이 과정은 두 단계로 이루어집니다. 먼저, 채널 주의 메커니즘을 통해 텍스트와 관련된 정점의 채널을 활성화합니다. 그런 다음, 공간 주의 메커니즘을 통해 텍스트와 관련된 정점을 활성화합니다. 이 두 단계는 텍스트 설명을 더 잘 반영한 3D 모델을 빠르게 학습할 수 있도록 도와줍니다.
4. Benchmarks and Metrics
텍스트 기반 3D 스타일화 기술을 평가하기 위해 우리는 표준화된 텍스트-메시 벤치마크와 두 가지 자동 평가 지표를 제안합니다. 이는 공정하고 객관적인 비교를 가능하게 하여, 향후 연구들이 더 나은 성과를 낼 수 있도록 돕습니다
4-1. MIT-30
MIT-30 벤치마크는 30개의 기본 메시 카테고리를 포함하며, 각 카테고리는 5개의 다른 텍스트 프롬프트로 주석이 달려 있습니다. 예를 들어, "고양이", "자동차", "의자" 등의 카테고리에 대해 "파란색 고양이", "빨간색 자동차"와 같은 텍스트 프롬프트가 제공됩니다. 이를 통해 다양한 스타일화 결과를 평가할 수 있습니다.
4-2. Metrics
기존의 연구들은 주로 사용자 연구에 의존하여 결과를 평가했지만, 이는 주관적이고 재현 불가능한 한계가 있습니다. 이를 극복하기 위해 우리는 두 가지 자동 평가 지표를 도입했습니다.
- Multi-view Expert Score (MES): 스타일화된 3D 모델의 품질을 평가하기 위한 지표입니다. 고정된 고도와 방위각에서 24개의 이미지를 렌더링한 후, 각 이미지와 텍스트 간의 유사성을 측정하여 평균 점수를 계산합니다.
- Iteration for Target Score (ITS): 스타일화 모델의 수렴 속도를 평가하기 위한 지표입니다. 일정한 품질(MES) 점수에 도달하는 데 필요한 반복 횟수를 측정합니다.
5. Experiments

위 그림은 X-Mesh와 기존의 최첨단 방법들을 비교하여, X-Mesh의 우수성을 증명합니다. Text2Mesh는 과도한 정점 변위로 인해 비정상적인 변형을 자주 일으킵니다. 예를 들어, "a dark castle"이라는 프롬프트에 대해 Text2Mesh는 원래 성 구조와 일치하지 않는 여러 스파이크를 생성합니다. 반면 TANGO와 TEXTure는 원래 메시의 정점을 변형하지 않기 때문에 이러한 변형 문제는 발생하지 않지만, 스타일화 품질과 텍스트 이해에 몇 가지 단점이 있습니다. "a colorful candy vase"이라는 예에서 TANGO와 TEXTure는 꽃병의 기본 구조를 고려하지 않고 여러 색상을 단순히 적용합니다. 반면, X-Mesh는 정점 속성 예측 동안 텍스트의 동적 지도를 도입하여 목표 텍스트와 일치하는 텍스처를 생성합니다.
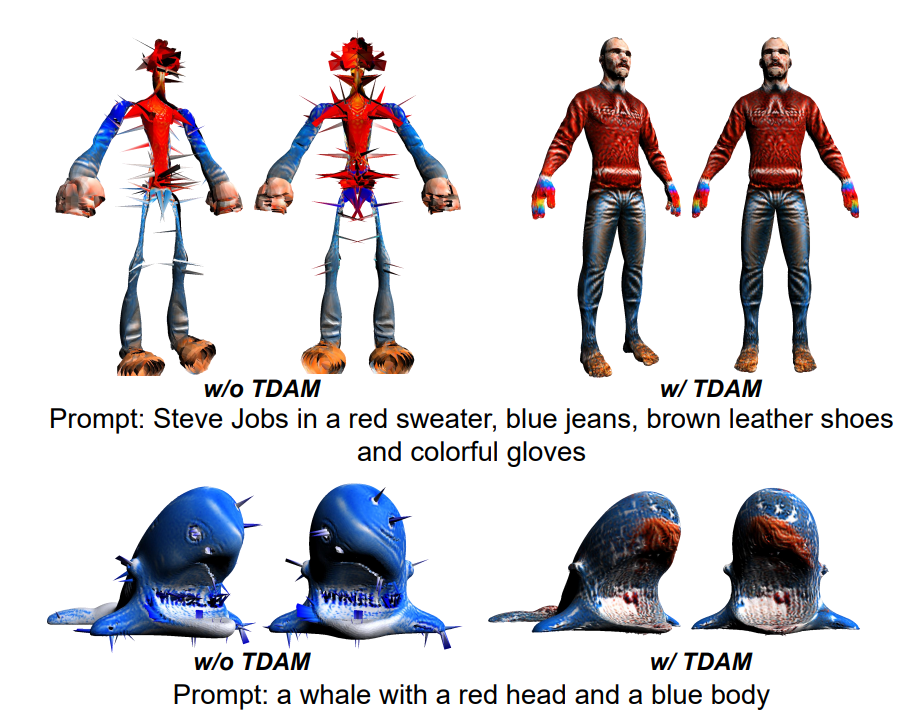
위 그림은 제안된 X-Mesh가 TDAM 모듈의 도움으로 복잡한 텍스트 프롬프트를 처리하는 능력을 조사합니다. 실험 결과, TDAM이 없는 모델은 복잡한 프롬프트에서 쉽게 붕괴되는 경향이 있습니다. 예를 들어, TDAM이 없는 모델은 최종 스타일화된 메시가 정상적인 기하학적 구조를 잃고 많은 스파이크가 나타납니다. 반면, TDAM이 있는 모델은 목표 텍스트와 일치하는 적절한 색상과 기하학적 속성을 예측할 수 있습니다.
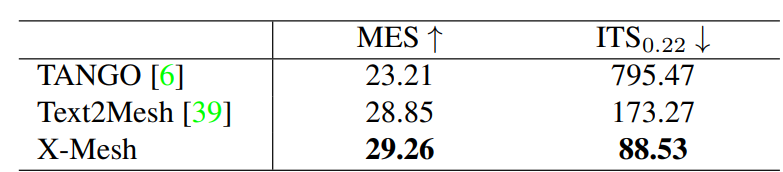
이전 연구에서는 스타일화된 결과를 평가하기 위해 User Study를 사용했습니다. 그러나 이러한 평가는 주관적이고 재현 불가능한 한계가 있습니다. 이를 극복하기 위해 스타일화된 Mesh의 품질과 스타일화 모델의 수렴 속도를 측정하는 두 가지 자동 평가 지표인 MES와 ITS를 제안합니다. X-Mesh는 이전 방법들보다 우수한 성능을 보입니다. MIT-30에서 X-Mesh는 MES에서 0.41의 향상을 이루어, X-Mesh가 더 나은 스타일화 품질을 제공함을 나타냅니다. 또한, X-Mesh는 가장 낮은 ITS를 보여 우리의 방법이 이전 방법들보다 빠르게 수렴함을 강조합니다.
6. Conclusion
이 논문에서는 텍스트 기반 3D 스타일화의 새로운 프레임워크인 X-Mesh를 제안했습니다. X-Mesh는 TDAM을 활용하여 정점 속성을 예측함으로써 더 정확한 스타일화와 빠른 수렴을 달성합니다. 또한, 텍스트-메시 벤치마크와 두 가지 자동 평가 지표를 도입하여 텍스트 기반 3D 스타일화 기술을 공정하고 객관적으로 평가할 수 있도록 했습니다. 실험 결과는 X-Mesh가 기존의 최첨단 방법들보다 뛰어난 성능을 보임을 입증하였습니다.
