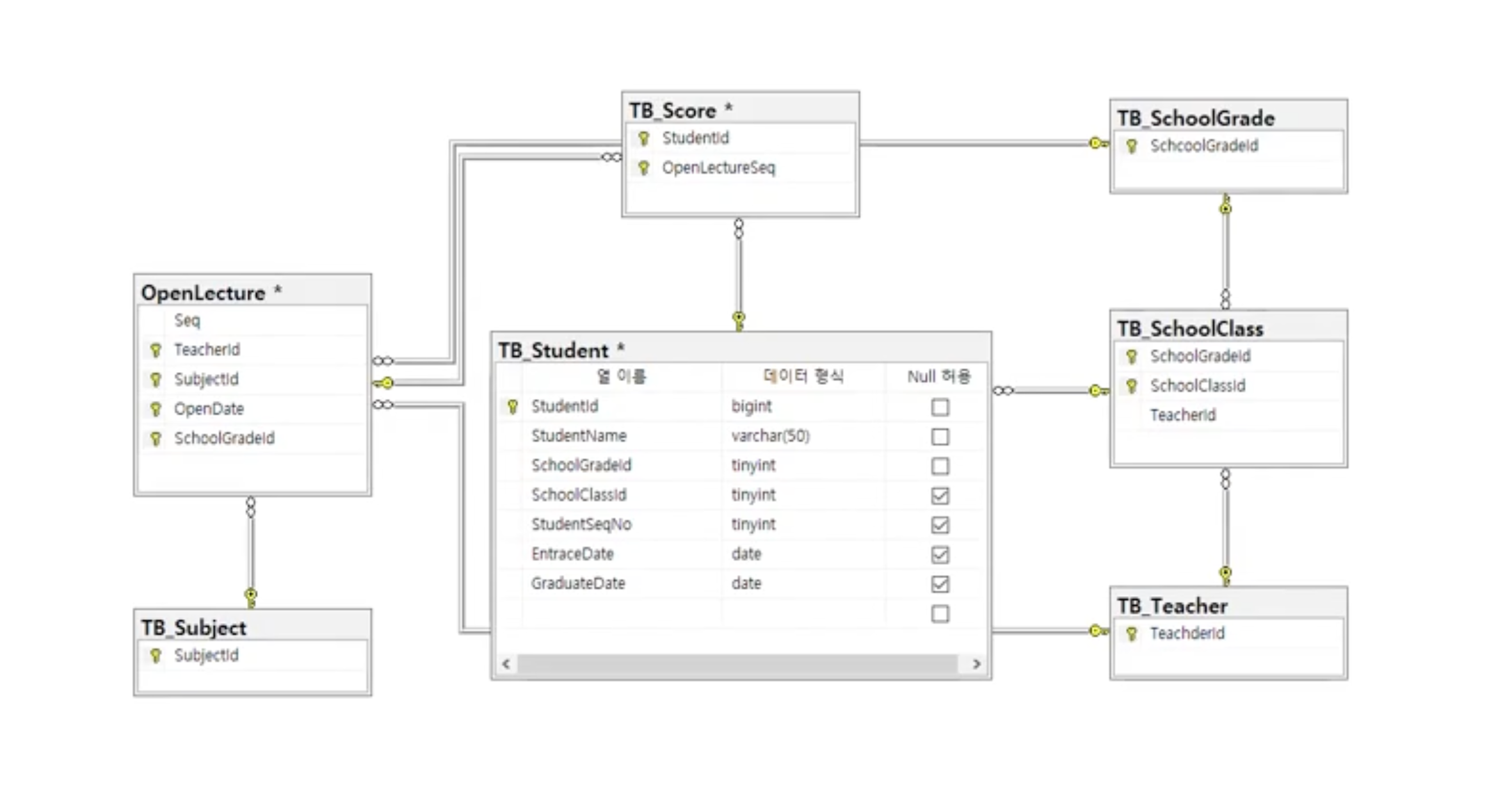
RDBMS

데이터 베이스
-> 구조화된 데이터들의 집합
관계형 데이터 베이스
-> 데이터들을 2차원 배열과 같은 테이블에 저장하고 관리
-> 관계형 데이터에서는 반드시 Primary Key 가 존재해야 한다
식별자
-> 하나의 레코드를 고유하게 구분할 수 있는 것으로 하나의 컬럼 또는 여러 개의 컬럼이 모여 Primary Key를 구성한다
어떤 컬럼을 주식별자로 설정 할 것인가
-> 고객들이 제공한 데이터로는 주로 주식별자로 설정하지 않는다 ( 데이터 오류가 있을 수 있기 때문에 )
decimal - 실수 컬럼 자료형 (실수의 오차범위가 가장 적음 화폐 단위에 사용하기 좋음)
-money의 자료형이 따로 있지만 오차범위 때문에 decimal를 더 사용한다
char 와 Varchar 차이
char은 할당 된 메모리의 크기 만큼 한 컬럼당 다 부여되지만 varchar은 메모리 할당이 가변이기 때문에 메모리 활용에 더 효과적임
uniqueidentifier
NEWID() 함수를 사용해서 유니크한 아이디를 준다
유니코드 ( 다국어의 데이터를 저장 할 때 사용 )
앞의 n을 붙인다
Primary Key 설계
고려사항
-유일하고 모든 레코드에 not null일 수 있는 컬럼을 찾는다
-후보 식별자가 없는 셩우 임의의 식별자를 만들어 부여한다
pk의 데이터 타입 결정
-레코드의 발생 가능한 최대 수를 예측한다
예) 처리해야 하는 대상이 대략 몇 개정도 되는가?
-단순하게 생각하고 의미를 부여하는 것은 대량의 데이터를 관리하기에는 불리할 수 있다
1:M 의 관계
한쪽이 관계를 맺은 쪽의 여러 객체를 갖는 것을 의미한다
외래키(foreign key) : 부모 테이블에 있는 동일 컬럼 자식 테이블에는 여러개의 데이터가 존재 할 수 있지만 부모 테이블에는 딱 한 개만 존재가 가능하다
설정 방법
-- 외래키 설정
FOREIGN KEY (컬럼명) REFERENCES 부모테이블명(컬럼명)
-- 이미 생성된 자식 테이블에 외래키 추가
ALTER TABLE 자식 테이블명
ADD FOREIGN KEY (컬럼명) REFERENCES 부모테이블명(컬럼명);
테이블에 외래키를 설정해주면 부모 테이블에 없는 primarykey의 데이터를 자식 테이블에 넣을 수 없다
외래키는 Not Null 지키자 ( 제대로 된 통계수치를 알 수 없다 )
자식 테이블에 부모 테이블의 primarykey 데이터가 존재하면 부모 테이블의 데이터를 삭제 할 수 없다
1:M 재귀적 관계
예) 회사 -> 부서 -> 부서2
테이블 안에 외래키를 만들어준다
M:N 의 관계
두 테이블에 관계가 전혀 없다면 중간에 비즈니스를 설명하는 테이블이 만들어 질 수 있다
주어 목적어 동사가 확실하게 나오는 테이블은 잘 설계된 테이블이라 할 수 있다 ( 해석이 잘 되는 테이블 )
서고 테이블 (서고id-PK)
서가 테이블 (서가id-PK) (서고id-PK FK) - 상속형(엄격)
-> 서가 테이블 컬럼에 null을 허용하지 않기 때문에 데이터가 들어올 때 절대적으로 서가 서고가 같이 들어와야 할 때에는 상속형을 사용해주면 된다
단점 : 상속을 받을 때 마다 pk가 늘어나기 때문에 데이터 삽입시 상다히 엄격해질 수 있다
서고 테이블 (서고id-PK)
서가 테이블 (서가seq-PK) (서가id) (서고id-FK) - 독립형
-> 서가 테이블에 null을 허용하기 때문에 서가 서고가 동시에 데이터가 들어오지 않아도 문제가 없을 때 사용해준다
단점 : 데이터 관련 에러가 발생 할 수 있음
- 자식 테이블이 되지 않는 테이블은 해당 데이터에 기준이 될 수 있는지 고민해보자 (참조만 되는 테이블) - select만 되는 절대적인 테이블
- pk에 의미를 주지 말자 ( 예 : 반id - pk 반이름 반이름 컬럼을 따로 줘서 확장성을 키우자 )
- TB - 테이블 접두어를 붙이자
update 테이블명 set 컬럼명 = cast(컬럼명 as varchar) + '삽입 할 문자'
-> 반이름(반id = 3 , 반이름 = 3반) 을 한 번에 수정 할 수 있는 쿼리문
-
서로 상관관계가 있을 때에는 부모없는 자식을 만들 수 없다 ( 만약 부모의 데이터를 삭제해야한다면 상태를 나타내는 컬럼을 추가해준다 )
-
회원 테이블에 상태를 나타내는 컬럼이 없으면 탈퇴시 데이터를 삭제해줘야 하는데 이미 그 회원과 상관관계를 맺은 데이터가 있다면 그 데이터는 부모 없는 자식이 된다 그러므로 삭제는 지양하고 상태 컬럼으로 유지와 탈퇴를 분간하면 된다
-
null을 허용하지만 유니크한 데이터를 줘야 한다면 pk말고 유니크를 지정해주자
-
설계시 다향한 변수또한 생각을 해야한다
성정 (varchar(1000))
국어 90#수학90#영어40
프로그래밍시 파밍하여 데이터 추출
--지양 하는 방법 join하여 데이터 확인이 불가능하다
학교 성적관리 테이블 예시
1:1 관계
어느 쪽 당사자의 입장에서 상대를 보더라도 반드시 단 하나씩 관계를 가지는 것을 말한다
예 ) 책 정보 테이블과 책 위치 테이블을 만든다 1:1
책의 구분 컬럼을 테이블로 따로 만들어 데이터 삽입시 에러를 줄인다
정규화
데이터 모델링에서 제일 중요한 것은 무결성을 보장하는 것
Anomaly 란
데이터의 이상 현상
중복때문에 anomaly가 발생 ( 의도하지 않은 이상 현상 발생 가능 )
update deltet insert 에서 발생 할 수 있음
1 정규화
-> 데이터 중복을 제거하기 위한 테이블 분할
2 정규화
-> 두 개 이상으로 구성된 PK 에서 발생한다 식별자 일부에 종속되는 어트리뷰트는 제거해야 한다
-> 상품명은 삼품 코드에만 종속되고 주문번호와는 관계 없음
-> 상품명을 따로 테이블로 만들어 줌
3 정규화
-> 식별자 이외의 속성간에 종속 관계가 존재하면 안 된다
-> 종속 관계가 있으면 중복 값이 생긴다
-> 이행 종속 관계를 분해하는 것
1정규화
- 모든 속성은 반드시 하나의 값을 가져야 한다
- 값이라는 것은 원자성을 가져야 한다 즉 더 이상 쪼갤 수 없는 하나의 값만을 가져야 한다
대상
- 다가 속성이 사용된 릴레이션
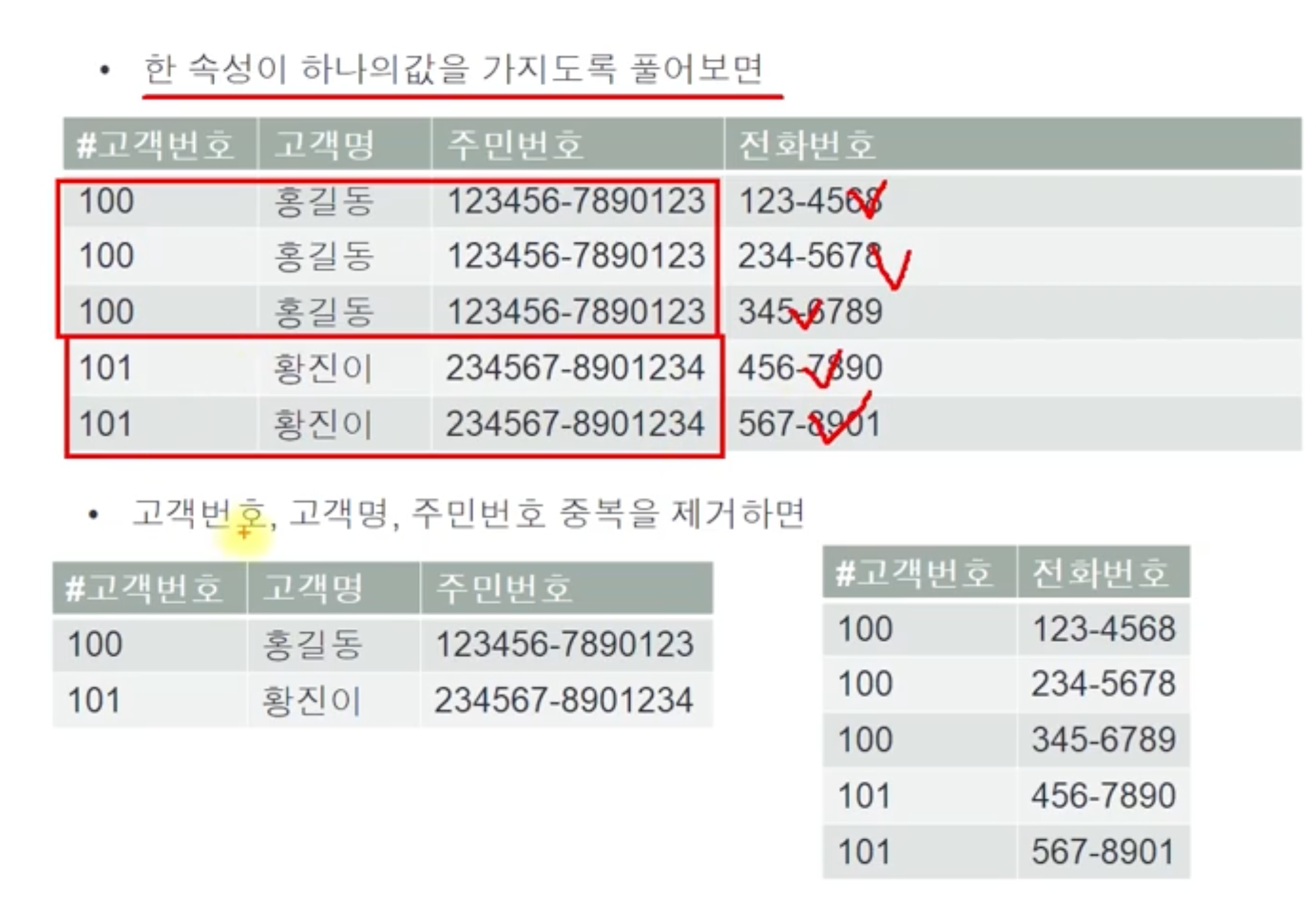
-
복합 속성이 사용된 릴레이션

-
유사한 속성이 반복된 릴레이션
-
중첩 릴레이션
-
동일 속성이 여러 릴레이션에 사용된 경우
2정규화
- 두 개 이상으로 구성된 pk에서 발생
- r의 모든 속성이 후보 식별자 전체에 종속
- 일반 속성이 후보 식별자 전체에 종속
- 일반 속성이 후보 식별자 전체에 종속되지 않고 일부에 종속된다면 2정규형 아님
- 따라서 2정규형이기 위해서는 모든 비 식별자 속성은 후보 식별자 속성에 완전함수 종속돼야 한다
3정규화
- 식별자가 아닌 일반 속성 간에는 종속성이 존재하지 않는다
- 3정규형의 대상이 되는 속성을 이행 종속 속성이라고 함
db는 중복이 발생하지 않게 관계성을 잘 설계해야한다
역정규화
- 효율을 위해서 정규화된 결과의 일부를 수정하여 중복을 허용
- 정규화되지 않은 상태에서 중복을 허용하는 것과는 다름
- 대부분 join시 발생되는 엄청난 계산량을 해결하기 위해서 사용
테이블 설계의 마지막은 튜닝이다

개발자로서 성장하는 데 큰 도움이 된 글이었습니다. 감사합니다.