
Kafka
- 빠르고 확장 가능한 작업을 위해 데이터 피드의 분산 스트리밍, 파이프 라이닝 및 재생을 위한 실시간 스트리밍 데이터를 처리하기 위한 목적으로 설계된 오픈 소스 분산형 게시-구독 메시징 플랫폼 [tibco]
- 실시간으로 기록 스트림을 게시, 구독, 저장 및 처리할 수 있는 분산형 데이터 스트리밍 플랫폼[RedHat]
- 실시간 이벤트 기반 애플리케이션 개발을 지원하는 것을 비롯하여 많은 이점을 가진 오픈 소스 분산형 스트리밍 플랫폼[IBM]
- 실시간으로 스트리밍 데이터를 수집하고 처리하는 데 최적화된 분산 데이터 스토어[AWS]
- 고성능 데이터 파이프라인, 스트리밍 분석, 데이터 통합, 미션 크리티컬 애플리케이션을 위해 사용하는 오픈 소스 분산 이벤트 스트리밍 플랫폼[apache kafka]
주요 키워드는 “빠름, 확장 가능, 분산 스트리밍, 파이프라이닝, 실시간, 게시-구독(Pub/Sub), 이벤트” 정도로 보인다.
아래에서 이어서 알아보자.
카프카의 탄생 배경
- 카프카는 SNS 서비스인 Linked-In에서 개발했다.
- 아래는 카프카 개발 이전의 링크드인 데이터 처리 시스템 구조도이다.
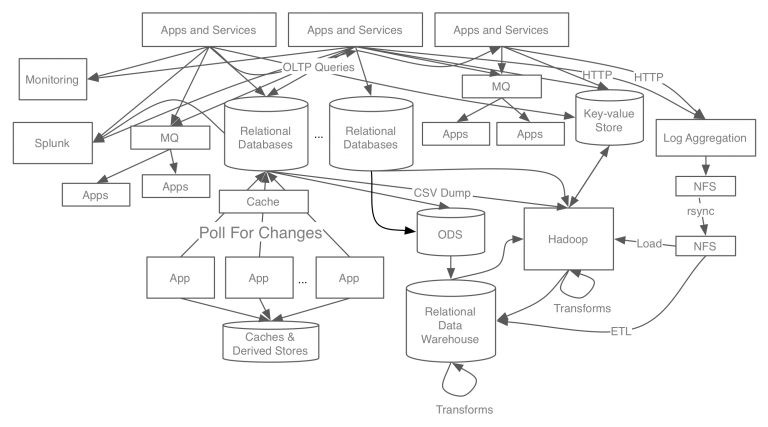
기존 데이터 시스템의 문제점
- 각 서비스와 DB가 End-to-End로 연결되어 파이프라인이 파편화되고 시스템 복잡도가 높아짐.
- 각 파이프라인에서 사용하는 프로토콜, 데이터 형식 등이 다름.
- 그에 따라 유지보수, 서비스의 확장, 장애 대처가 매우 어려워짐.
위의 문제점 때문에 새로운 아키텍처인 카프카를 개발
카프카 이후
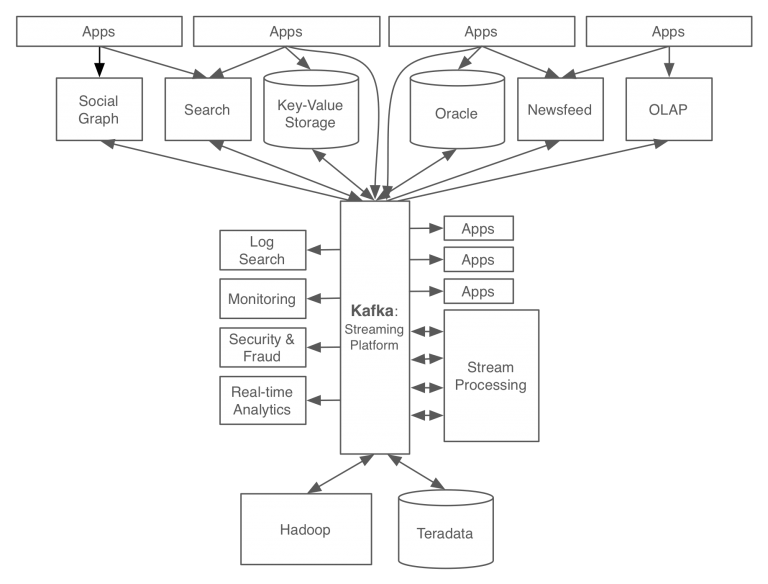
- End-to-End 방식에서 벗어나 카프카를 중심으로 파이프라인이 구축됨.
- producer와 consumer를 분리하여 시스템 결합도가 낮아짐.
- 데이터 흐름을 중앙화하여 시스템 복잡도를 낮춤
- 서비스 확장에 용이한 구조
카프카 용어
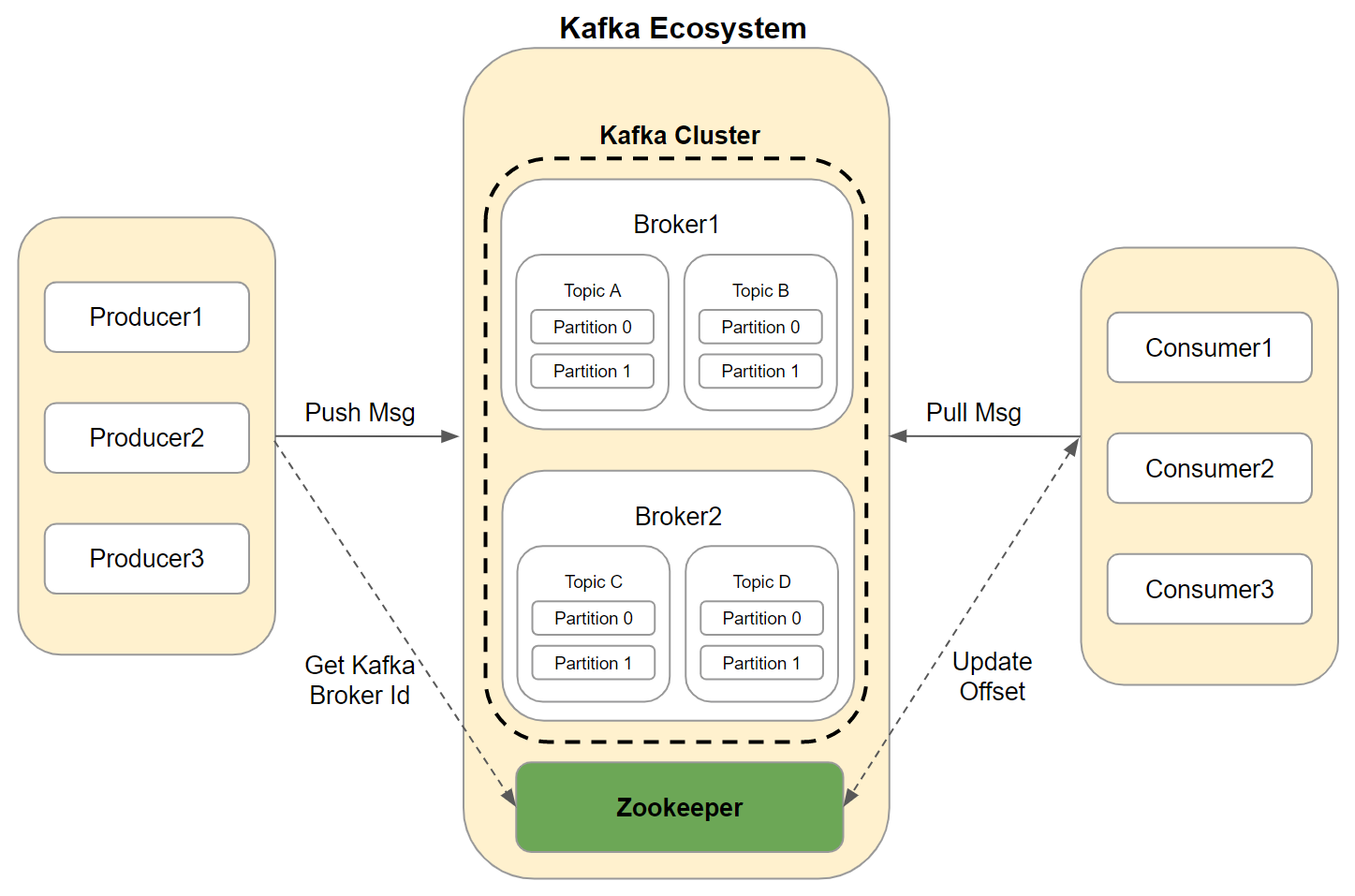
구성 요소
브로커
- 카프카 애플리케이션이 설치된 서버 혹은 노드를 의미
- Producer로부터 메시지를 전달받아 Topic에 저장하고, Consumer에 전달하는 역할을 함
카프카 클러스터
- 브로커들의 집합(일반적으로 3개 이상)을 의미
- 확장성 및 고가용성을 위해 하나의 클러스터는 여러 개의 브로커를 가질 수 있음
- 브로커 중 하나는 Controller 기능을 수행
- Controller
- 브로커의 생존 여부(liveness)를 체크함
- 임의의 브로커가 중단된 경우 해당 브로커에 있던 리더 파티션을 탈락시키고 다른 팔로워 파티션 중 하나를 리더로 뽑음(leader election)
- Controller
주키퍼
- 분산 애플리케이션을 위한 코디네이션 시스템
- 카프카의 메타데이터(브로커 id, 컨트롤러 id 등) 관리 및 브로커의 정상상태 점검(health check) 담당
토픽, 파티션, 오프셋
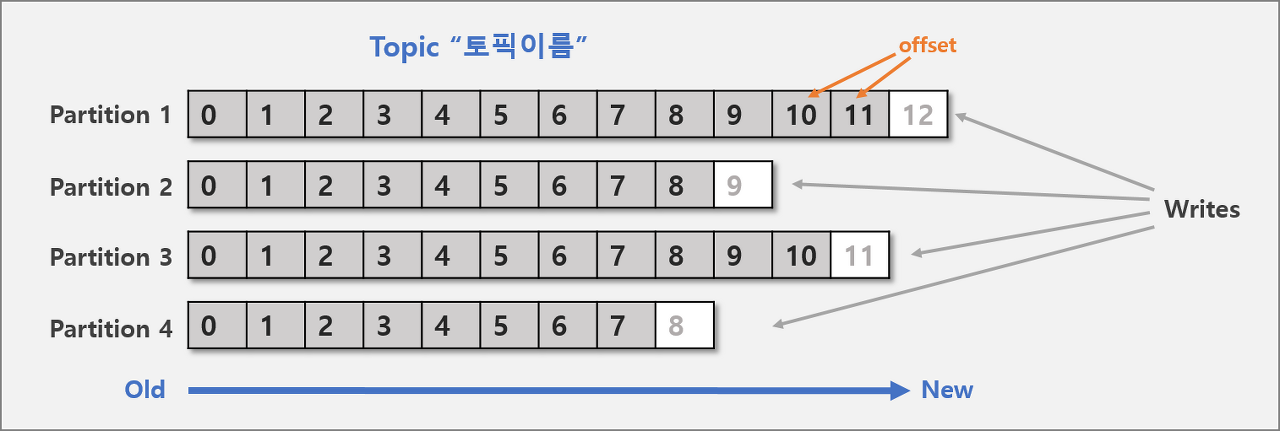
토픽
- 메시지를 구분하는 단위
- 파일시스템의 폴더와 유사함
파티션
- 메시지를 저장하는 물리적인 파일
- 한 개의 토픽은 한 개 이상의 파티션으로 구성됨
- 파티션은 메시지 추가만 가능(append-only)
오프셋
- 파티션에 저장된 레코드의 증가하는 64bit 정수 인덱스
- 0부터 시작하며 파티션에 레코드가 저장될 때마다 1씩 증가함
- 파티션에서 데이터를 읽을 때 오프셋의 오름차순으로 읽음
- 각 컨슈머마다 자신이 소비한 메시지 오프셋을 추적하여 장애 복구 가능
프로듀서와 컨슈머
- 메시지 큐에서도 나왔던 개념
- 프로듀서와 컨슈머는 카프카 구성 요소가 아니고 외부의 클라이언트를 의미
프로듀서
- 메시지(이벤트)를 발행하여 생산(Write)하는 주체
- 프로듀서는 메시지 전송 시 토픽을 지정
- 같은 키를 갖는 메시지는 같은 파티션에 저장되며 순서가 유지됨(FIFO)
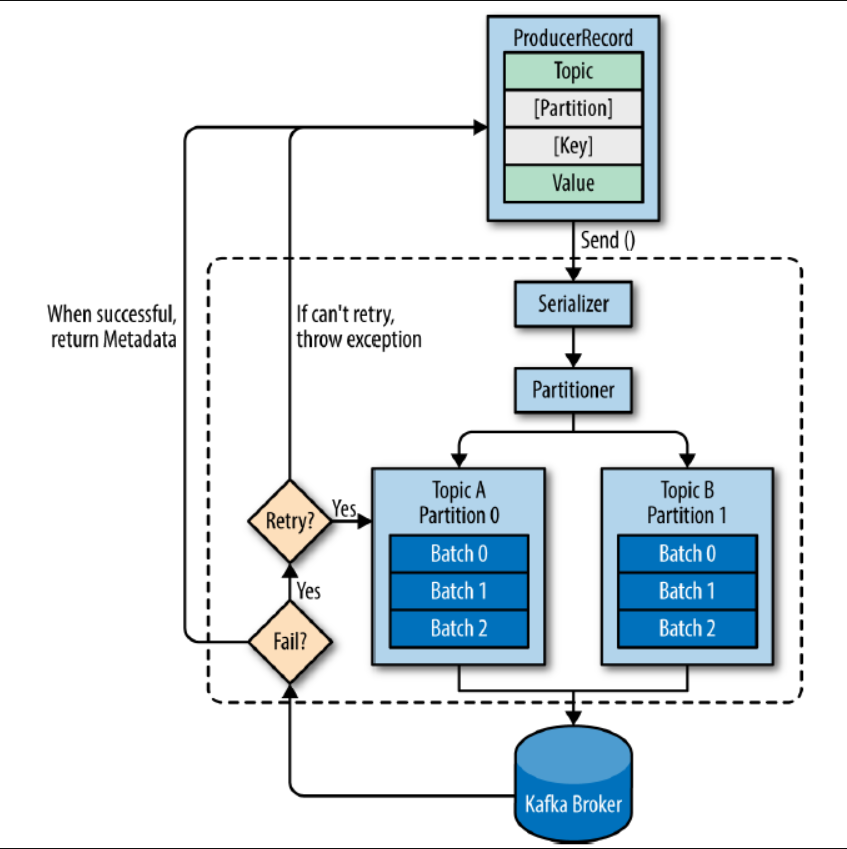
프로듀서의 메시지 전송 과정
- 레코드는 토픽, 파티션, 키, 밸류로 구성됨
- 토픽과 밸류는 필수, 파티션과 키는 선택
- 직렬화(Serializer) : byte 배열로 변환
- 파티셔닝(Partitioner) : 파티션 결정, 레코드에서 파티션이 지정되지 않았다면 라운드 로빈 방식으로 파티셔닝
- 메시지 배치(Record Accumulator) : 카프카로 전송하기 전에 파티션 별로 레코드를 모아두었다가 한 번에 전송
- 압축(Compression) : 브로커로 빠른 전달 및 브로커 내부에서 빠른 복제를 위해 메시지를 압축
- 전달(Sender) : 카프카로 전송
컨슈머
컨슈머는 다음 3가지 특징을 통해 효율적이고 유연한 메시지 구독 기능 제공
- Polling 구조
- 단일 토픽 멀티 컨슈밍
- 컨슈머 그룹
Polling 구조
- 일반적으로 다른 메시지 큐는 메시지 큐에서 메시지를 Push하는 방식
- 이런 방식의 단점은 메시지 큐가 컨슈머 환경을 고려해야 한다는 것
- 하지만 Kafka는 컨슈머가 브로커에게 메시지를 요청하는 Polling 구조로 설계됨
- 각 컨슈머가 자신의 환경에 메시지 구독 성능을 최적화할 수 있는 장점을 가짐
단일 토픽 멀티 컨슈밍
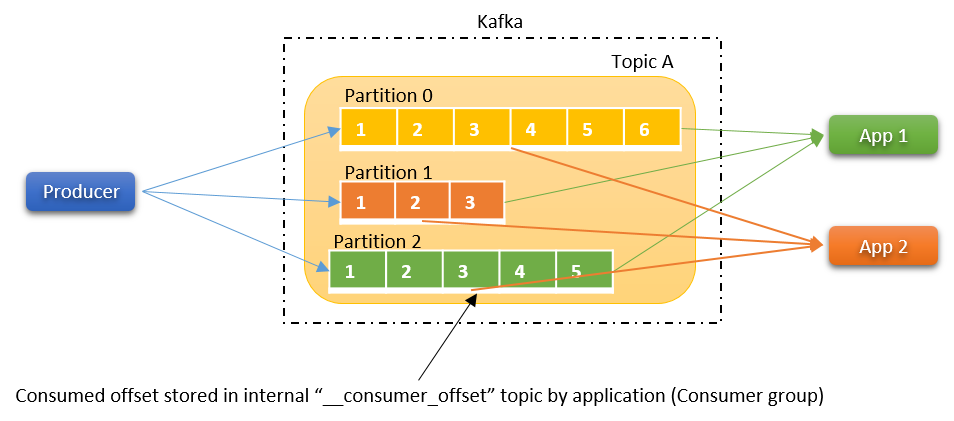
- 하나의 토픽에 서로 다른 컨슈머 어플리케이션이 동시에 구독 가능
- 컨슈머가 메시지를 읽어도 브로커의 메시지가 삭제되지 않는 카프카의 특성
- 각 컨슈머가 어느 토픽, 어느 파티션의 몇 번째까지 읽었는지를 저장하는 오프셋이 사용됨
컨슈머 그룹
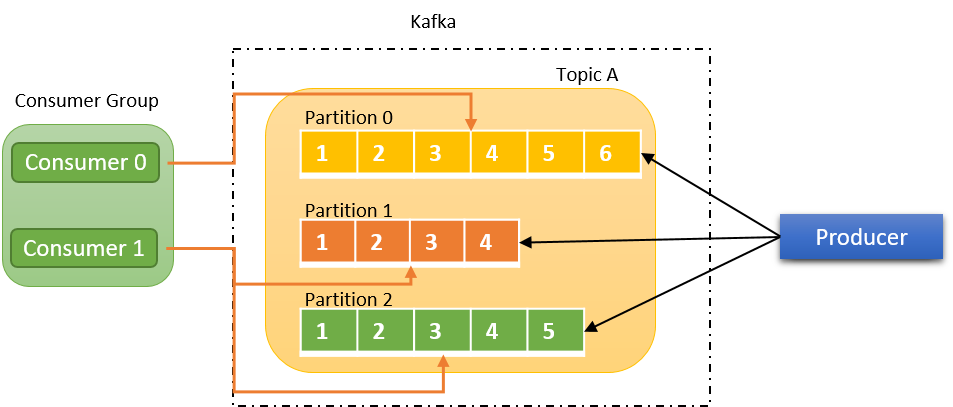
- 컨슈머 그룹 내의 컨슈머는 토픽 파티션의 소유권(혹은 구독권)을 나눠 가짐
- 컨슈머 그룹에 컨슈머가 추가되거나 이탈하면 컨슈머 그룹 내부에서 파티션 소유권이 재조정됨(Rebalancing)
- 파티션뿐만 아니라 컨슈머도 병렬 처리가 가능하게 됨에 따라 처리 속도가 빨라지고, 확장이 쉬워짐
파티션과 컨슈머 그룹 확장 시 유의사항
- 파티션의 개수를 늘릴 수는 있으나 줄일 수는 없다. 그렇기에 파티션 확장은 유의해야 한다.
- 여러 파티션을 가진 토픽에 대해서 컨슈머를 병렬 처리하고 싶을 때 컨슈머는 파티션보다 적은 개수로 생성해야 한다.
CASE 파티션 2개 & 컨슈머 1개인 경우 1개의 컨슈머 당 2개의 파티션이 할당 파티션 2개 & 컨슈머 2개인 경우 1개의 컨슈머 당 1개의 파티션이 할당 파티션 2개 & 컨슈머 3개인 경우 2개의 컨슈머만 각각 1개의 파티션이 할당되고 남은 1개의 컨슈머는 동작하지 않음
카프카의 특징
높은 처리량, 낮은 지연시간
- 다중 프로듀서, 다중 컨슈머가 상호 간섭 없이 메시지 쓰고 읽음
- batch 전송 기능으로 동시 처리량 증가
- 압축 전송 지원으로 빠른 복사, 빠른 전송
- 페이지 캐시로 인한 높은 처리 속도
고가용성(HA - High Availability)
- 카프카의 토픽은 파티션 단위로 쪼개져 클러스터의 각 서버에 분산되어 저장되고 복제됨
- 장애가 발생 시 파티션 단위로 fail over가 수행됨
- Replication, Leader-Follower
메시지 내구성
- 컨슈머가 데이터를 소비하더라도 브로커에 남아있음
- 메시지를 디스크에 저장함으로써 장애 발생 시에도 안전하게 복구 가능
분산 아키텍처
- 단일 시스템 대비 성능 우수
- 시스템 확장 용이(Scalability)
- 높은 내결함성(Fault Tolerance)
- 시스템의 일부에서 결함이 발생해도 정상적 or 부분적으로 기능을 수행하는 것
Kafka 언제 사용할까?
- 많은 양의 실시간 로그 혹은 실시간 스트림을 처리해야 할 때
- 다양한 데이터 요구사항으로 인해 Event Driven System을 구축할 때
- 데이터 파이프라인이 복잡하게 연결되어 유지보수 및 확장이 어려울 때
사용이 어려운 경우
- 메시지의 수정이 자주 발생할 때
- 대용량 데이터 처리가 필요하지 않을 때
References
https://kafka.apache.org/documentation/#gettingStarted
https://www.tibco.com/ko/reference-center/what-is-apache-kafka
https://www.redhat.com/ko/topics/integration/what-is-apache-kafka
https://www.ibm.com/kr-ko/topics/apache-kafka
https://aws.amazon.com/ko/what-is/apache-kafka/
https://www.samsungsds.com/kr/analyltics-kafka/kafka.html
https://ifuwanna.tistory.com/487
https://always-kimkim.tistory.com/entry/kafka101-producer
https://unit-15.tistory.com/135
https://hudi.blog/what-is-kafka/
https://zeroco.tistory.com/105
https://www.youtube.com/watch?v=catN_YhV6To&t=29s&ab_channel=데브원영DVWY
https://www.youtube.com/watch?v=waw0XXNX-uQ&list=PL3Re5Ri5rZmkY46j6WcJXQYRlDRZSUQ1j&index=1&ab_channel=데브원영DVWY
https://blog.voidmainvoid.net
https://www.linkedin.com/pulse/kafka-consumer-overview-sylvester-daniel
https://colevelup.tistory.com/16
