1) 가설검정
- 데이터가 특정 가설을 지지하는지 검정!
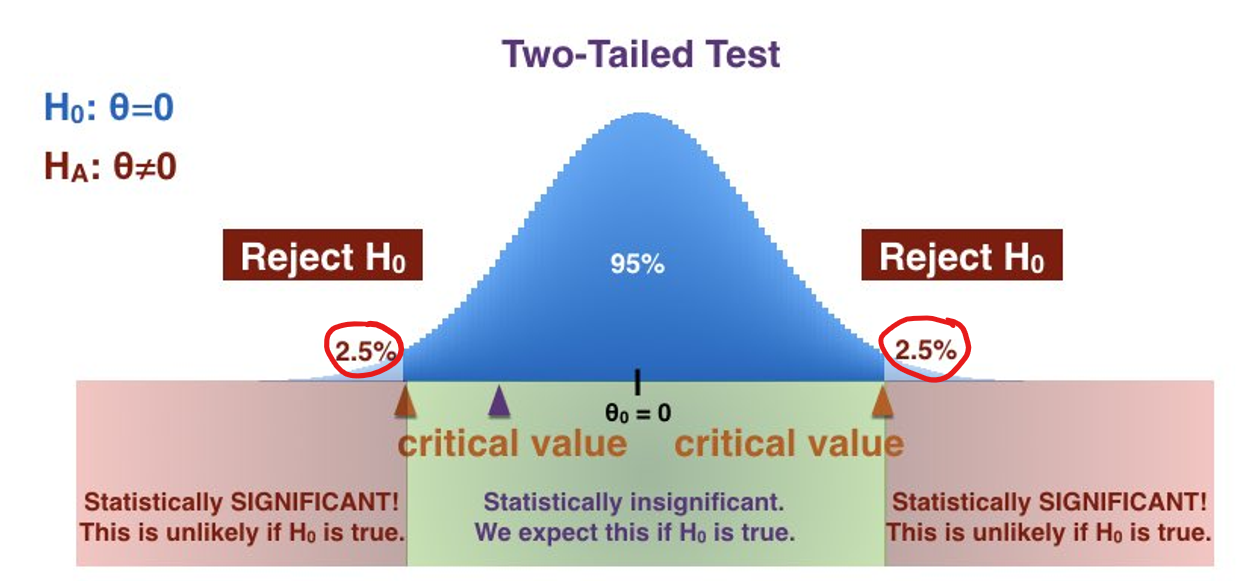
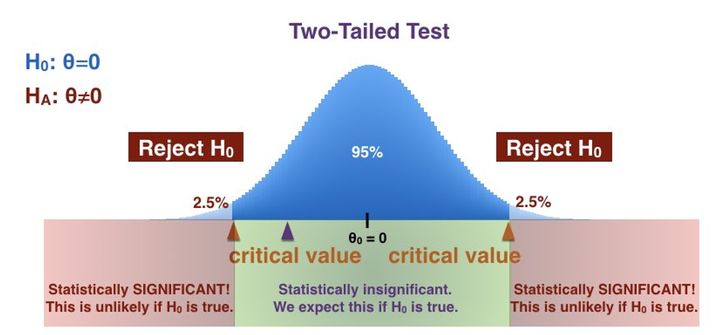
양쪽의 극히 작은 확률로 일어날 2.5 + 2.5 = 5의 비율 0.05 미만이 일반적으로 유의미한 값이 된다
가설검정
- 표본 데이터를 통해 모집단의 가설을 검증하는 과정.
- 데이터가 특정 가설을 지지하는지 평가하는 과정.
- 귀무가설(H0)과 대립가설(H1)을 설정, 귀무가설을 기각할지 결정.
- 데이터 분석시 두가지 전략을 취함.
- 확증적 자료 분석
- 탐색적 자료분석(EDA)
- 가설을 먼저 정하지 않고 데이터를 탐색해보며 가설 후보들을 찾고
데이터의 특징을 찾는 것.
2) 통계적 유의성과 p값
단계
- 귀무가설(H0)과 대립가설(H1)을 설정
- 유의수준(α) 결정
- 검정 통계량 계산
- p-값과 유의수준 비교
- 결론 도출
통계적 유의성
- 우연히 발생한 것이 아닌 어떤 효과가 실제로 존재함을 나타내는 지표.
- p값은 귀무 가설이 참일 경우 관찰된 통계치가 나올 확률을 의미.
- 일반적으로 p값 < 0.05이면 통계적으로 유의하다 판단.
p-값
- 귀무가설이 참일 때, 관찰된 결과 이상 극단적 결과가 나올 확률.
- 일반적으로 p-값이 유의수준(α)보다 작으면 귀무가설 기각.
- 유의수준으로 많이 사용하는 값 0.05.
p-값을 통한 유의성 확인
- p-값이 0.03%이라면, 3%의 확률로 우연히 이러한 결과가 나올 수 있음.
- 일반적으로 0.05이하라면 유의성이 있다고 봄.
3) 신뢰구간과 가설검정의 관계
신괴구간과 가설검정
- 신뢰구간과 가설 검정은 밀접하게 관련된 개념.
- 둘 다 데이터의 모수(ex.평균)에 대한 정보를 구하는 것이지만 접근 방식이 다름.
- 신뢰구간
- 가설검정
4) 실제 어떻게 사용되나?
가설을 설정하여 검증
- 새로운 약물이 기존 약물보다 효과가 있는지 검정.
- 이 때 새로운 약물은 기존 약물과 큰 차이가 없다 = 귀무가설
- 새로운 약물이 기존 약물과 대비해 효과가 있다 = 대립가설
A = np.random.normal(50, 10, 100)
B = np.random.normal(55, 10, 100)
mean_A = np.mean(A)
mean_B = np.mean(B)
t_test, p_value = stats.ttest_ind(A, B)
print(f"A 평균 효과: {mean_A}")
print(f"B 평균 효과: {mean_B}")
print(f"t-검정 통계량: {t_stat}")
print(f"p-값: {p_value}")
print(f"p-값: {p_value}")
if p_value < 0.05:
print("귀무가설을 기각합니다. 통계적으로 유의미한 차이가 있습니다.")
else:
print("귀무가설을 기각하지 않습니다. 통계적으로 유의미한 차이가 없습니다.")