1)표본오차와 신뢰구간
표본오차 (sampling Error)
- 표본에서 계산된 통계량과 모집단의 진짜 값 간의 차이
- 표본 크기가 클수록 표본오차는 작아짐.
- 이는 표본이 모집단을 완벽히 대표하지 못하기 때문에 발생하며, 표본의 크기와 표본 추출 방법에 따라 달라질 수 있음.
- 표본의 크기: 표본의 크기가 클수록 표본오차는 줄어듬. 더 많은 데이터를 수집할수록 모집단을 더 잘 대표함.
- 표본 추출 방법: 무작위 추출 방법을 사용하면 표본오차를 줄일 수 있음. 모든 모집단 요소가 선택될 동등한 기회를 지님.
신뢰구간 (Confidence Interval)
-
신뢰구간은 모집단의 특정 파라미터(예:평균, 비율)에 대해 추정된 값이 포함될 것으로 기대되는 범위
-
신뢰구간 계산 방법
- 신뢰구간= 표본평균±z x표준오차
- 여기서 z는 선택된 신뢰수준에 해당하는 z-값입니다. 예를 들어, 95% 신뢰수준의 z-값은 1.96입니다.
- 일반적으로 95% 신뢰수준을 많이 사용함.
-
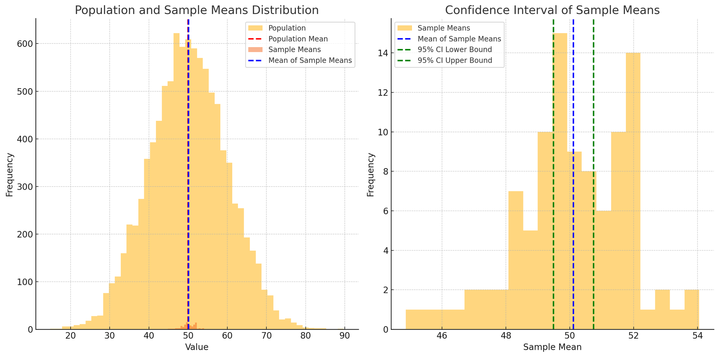
모집단과 표본 분포 (왼쪽 그림)
- 붉은색 점선은 모집단의 평균
- 파란색 점선은 표본의 평균
- 모집단의 분포는 넓고,표본 평균들의 분포는 좁아짐
- 표본 크기가 커질수록 표본 평균이 모집단 평균에 더 가까워지는 경향.
-
신뢰구간 시각화(오른쪽)
- 오른쪽 그림은 표본의 분포와 95% 신뢰구간을 보여줌
- 파란색 점선은 표본의 평균, 녹색 점선은 95% 신뢰구간의 상한과 하한을 나타냄
- 이 신뢰구간은 모집단의 평균을 포함할 것으로 예상되는 범위
실제 사용 범위
수학점수 표본으로부터 모집단의 평균 범위를 계산
-
100명의 학생을 표본으로 추출하여 그들의 평균 수학 점수를 구하고, 이 점수의 신뢰구간을 계산
import scipy.stats as stats # 표본 평균과 표본 표준편차 계산sample_mean = np.mean(sample) sample_std = np.std(sample) # 95% 신뢰구간 계산 conf_interval = stats.t.interval(0.95, len(sample)-1,loc=sample_mean, scale=sample_std/np.sqrt(len(sample))) print(f"표본평균: {sample_mean}") print(f"95% 신뢰구간: {conf_interval}") # 표본평균: 170.14185624937562 # 95% 신뢰구간: (np.float64(168.136304539803), np.float64(172.14740795894824))
