Go 언어의 장점으로 고루틴을 이용한 뛰어난 동시성 지원을 꼽을 수 있습니다. 기존에 다른 많은 언어들은 스레드를 통해 동시성을 지원했습니다. 그렇다면 Go 언어는 왜 고루틴이라는 새로운 동시성 요소를 지원하기 시작했을까요?
고루틴은 쓰레드보다 가볍다.
고루틴은 흔히 경량 스레드라고 소개합니다. 이렇게 소개하는 이유는 크게 3가지 입니다.
메모리 소비
고루틴은 스레드에 비해 더 작은 메모리만 필요로 합니다. 고루틴 생성에는 2KB의 스택만 필요로 하고 필요에 따라 힙을 사용합니다. 반면 스레드는 스레드의 간 메모리 보호 역할을 하는 공간을 포함하여 1MB 정도의 스택을 필요로 합니다.
따라서 들어오는 요청을 처리하는 서버에서 문제없이 요청당 하나의 고루틴을 만들 수 있지만 요청당 하나의 스레드는 OOM으로 이어질 수 있습니다.
생성 및 소멸 비용
스레드는 OS에 리소스를 요청하고 다 사용하면 반환해야 하기 때문에 상당한 생성, 소멸 비용이 들어갑니다. 스레드 풀을 이용하면 어느 정도는 문제를 해결할 수 있습니다. 이와 대조적으로 고루틴은 Go 런타임에 의해 생성 및 소멸되며 매우 적은 비용으로 이루어집니다. Go 언어는 고루틴의 수동 관리를 지원하지 않습니다.
컨텍스트 스위칭 비용
컨텍스트 스위칭이란 CPU가 어떤 프로세스를 실행하고 있는 상태에서 인터럽트에 의해 다음 우선순위를 갖는 프로세스가 실행되어야 할 때 기존의 프로세스 정보들은 PCB에 저장하고 다음 프로세스의 정보를 PCB에서 가져와 교체하는 작업을 말합니다. 여기서 상태란, CPU가 해당 프로세스를 실행하기 위한 해당 프로세스의 정보를 의미합니다.
아래 그림에서 프로세스 P1이 실행 중일 때 인터럽트가 발생하면 P1의 상태 정보를 PCB1에 저장하고 P2의 상태 정보 PCB2를 로딩하여 P2를 실행합니다. P1, P2는 서로 대기, 실행을 번갈아가며 실행되는데 이를 컨텍스트 스위칭 이라고 이야기합니다.
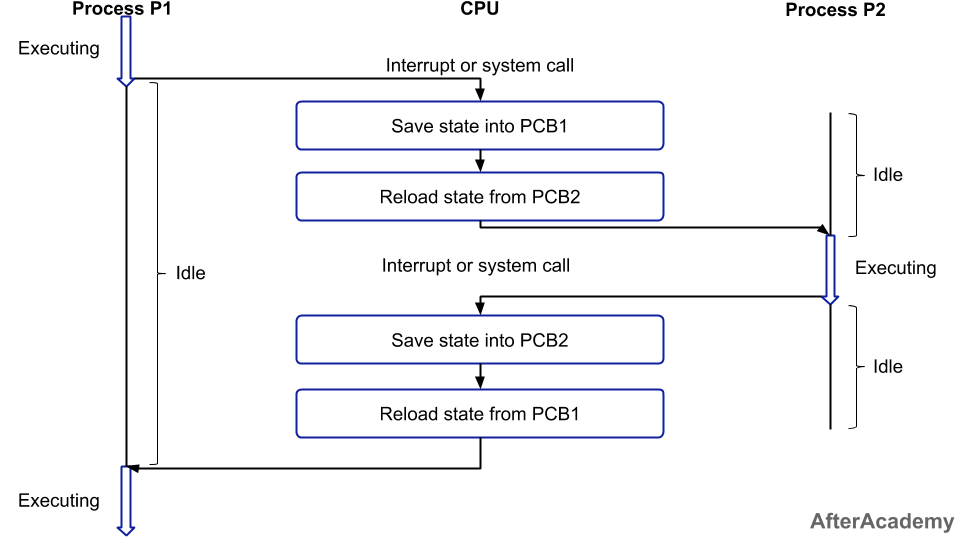
컨텍스트 스위칭은
- I/O 인터럽트
- CPU 사용 시간 만료
- 자식 프로세스 Fork
등이 발생하는 상황에서 발생하며, 컨텍스트 스위칭이 발생하는 시간 동안에는 CPU가 아무런 일도 할 수 없어 오버헤드가 발생하고 성능이 떨어집니다.
스레드가 프로세스보다 가볍다고 하는 이유도 컨텍스트 스위칭과 관련 있습니다. 아래는 PCB의 구조입니다.
| 정보 | 설명 |
|---|---|
| Process Id | 프로세스의 고유 번호 (PID) |
| Process state | 준비, 대기, 실행 등의 상태 |
| Program counter | 다음 실행될 프로세스의 포인터 (PC) |
| Register information | CPU 레지스터 관련 정보 |
| Scheduling information | 스케줄링 및 프로세스 우선 순위 정보 |
| Memory related information | 자원 할당 정보 |
| Accounting information | CPU 사용 시간, 실제 사용 시간, 실행 ID 정보 |
| Status information related to I/I | 입출력 상태 정보 |
프로세스는 1개 이상의 스레드를 가지고 있는데요, 위 내용만으로는 여러 스레드에 대한 정보 관리할 수 없습니다. 그래서 여러 스레드의 상태 정보를 관리하는 자료구조로 TCB가 존재합니다. TCB는 같은 프로세스에서 컨텍스트 스위칭하는 스레드에 대한 정보를 저장합니다.
| 정보 | 설명 |
|---|---|
| Thread Id | 스레드의 고유 번호 (TID) |
| Stack pointer | 프로세스에서 스레드의 스택을 가르키는 포인터 (SP) |
| Program counter | 프로세스에서 다음 실행될 스레드의 포인터 (PC) |
| Thread state | 준비, 대기, 실행 등의 스레드 상태 |
| Thread register information | 스레드의 레지스터 정보 |
| PCB pointer | PCB에 대한 포인터 |
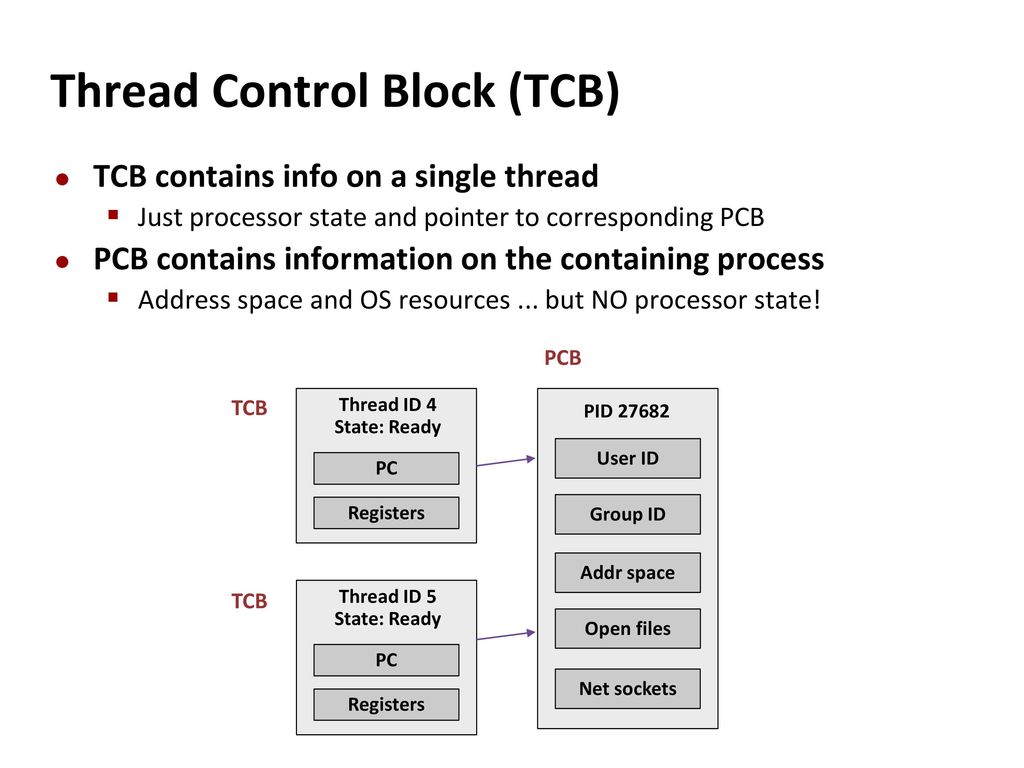
TCB는 PCB에 비해 적은 정보만 필요하므로 스레드의 컨텍스트 스위칭은 프로세스의 컨텍스트 스위칭보다 더 빠르게 이루어질 수 있습니다. 그리고 이런 스레드에 비해서도 고루틴은 컨텍스트 스위칭을 위해 더 적은 정보만을 요구하며, 매우 빠른 컨텍스트 스위칭이 가능합니다.
| 정보 | 설명 |
|---|---|
| Program counter | 고루틴 인터럽트 후 복원하기 위한 프로그램 카운터(PC)로 고루틴 내부에 저장 |
| Stack Pointer | 고루틴의 스택을 가르키는 포인터 (SP) |
| DX | CPU 레지스터 중 DX |
Go 런타임의 스케줄링
Go 런타임은 프로그램이 실행되는 내내 고루틴을 관리합니다. Go 런타임은 모든 고루틴을 다중화된 스레드들에 할당하고 모니터링하며, 특정 고루틴이 블록되면 다른 고루틴이 실행될 수 있도록 교체하는 일을 반복합니다. 이 말은 고루틴이 블록 되더라도 다중화된 스레드는 블록 되지 않는다는 것을 의미합니다. 모든 것은 Go 런타임이 알아서 처리해 줍니다.
GMP 구조체
- G (Goroutine) : 고루틴을 의미
- 런타임이 고루틴을 관리하기 위해서 사용합니다.
- 컨텍스트 스위칭을 위해 스택 포인터, 고루틴의 상태 등을 가지고 있습니다.
G는 LRQ에서 대기하고 있습니다.
- M (Machine) : OS 스레드를 의미
M은P의 LRQ로부터G를 할당받아 실행합니다.- 고루틴과 OS 스레드를 연결하므로 스레드 핸들 정보, 실행중인 고루틴,
P의 포인터를 가지고 있습니다.
- P (Processor) : 논리 프로세서를 의미
- 최대 GOMAXPROCS개를 가질 수 있습니다.
- P는 컨텍스트 정보를 담고 있으며, LRQ를 가지고 있어서
G를M에 할당합니다.
- LRQ(Local run queue) :
P마다 존재하는 Run QueueP는 LRQ로 부터 고루틴을 하나씩 POP하여 실행합니다.P마다 하나의 LRQ가 존재하기 때문에 레이스 컨디션을 줄일 수 있습니다.- LRQ가
M에 존재하지 않는 이유는M이 증가하면 LRQ의 수도 증가하여 오버헤드가 커지기 때문입니다.
- GRQ(Global run queue) : LRQ에 할당되지 못한 고루틴을 관리하는 Run Queue
- 실행 상태의 고루틴은 한번에 10ms까지 실행되는데, 10ms 동안 실행된 고루틴은 대기 상태가되어 GRQ로 이동됩니다.
- 고루틴이 생성되는 시점에 모든 LRQ가 가득찬 경우 GRQ에 고루틴이 저장됩니다.
GMP 구조체는 runtime.runtime2.go 에 구현되어 있습니다.
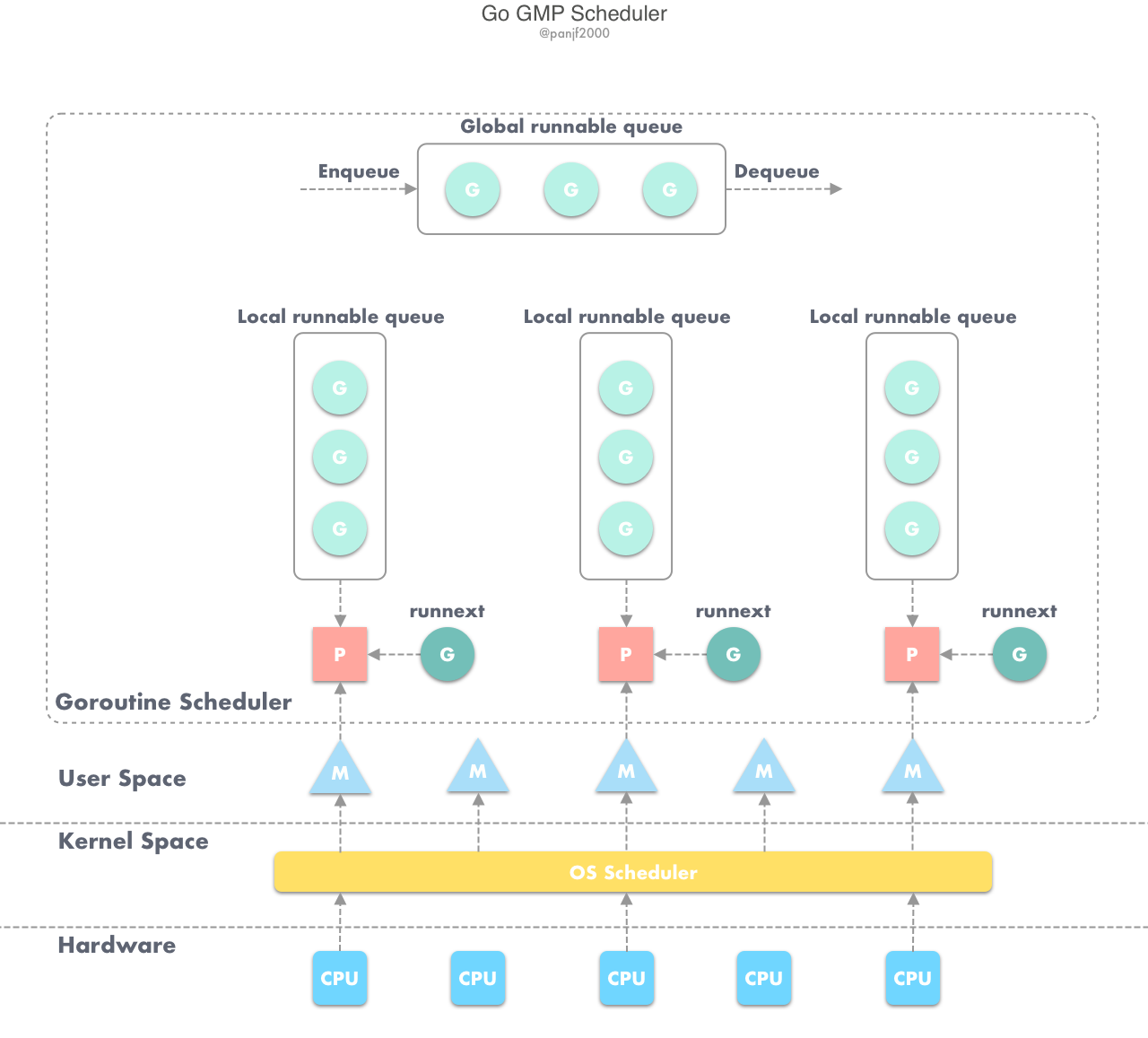
프로그램이 실행되면 P가 할당되고 각 P에는 M이 할당됩니다. P는 LRQ가 존재하며, P의 컨텍스트 내에서 실행되도록 설정된 고루틴을 관리합니다. LRQ의 고루틴들이 P에 할당된 M에서 교대로 실행되도록 스케줄링 됩니다. OS가 M에게 할당한 시간 동안 G 작업을 다 끝내면 M은 스피닝(Spinning, Busy waiting)하며 P의 LRQ의 맨앞에 있는G를 가져옵니다.
고루틴 선택 (Poll order)
P가 선택할 수 있는 고루틴은 여러 가지가 있습니다.
- Local Run Queue
- Global Run Queue
- Invoke Network poller
- Work Stealing
고루틴을 선택하는 다양한 방법이 존재하지만 크게는 아래와 같은 순서로 이루어집니다.
P가 자신의 LRQ에서 고루틴을 POP- LRQ, GRQ가 비어 있으면 다른
P의 LRQ에서 고루틴을 POP (Work Stealing) - GRQ를 확인하여 고루틴을 POP
작업 훔치기 (Work Stealing)
M, P가 모든 일을 마치면 GRQ 또는 다른 P의 LRQ에서 일을 가져옵니다. 이를 통해서 병목 현상을 없애고 OS 자원을 더 효율적으로 사용합니다. 그림을 보면,
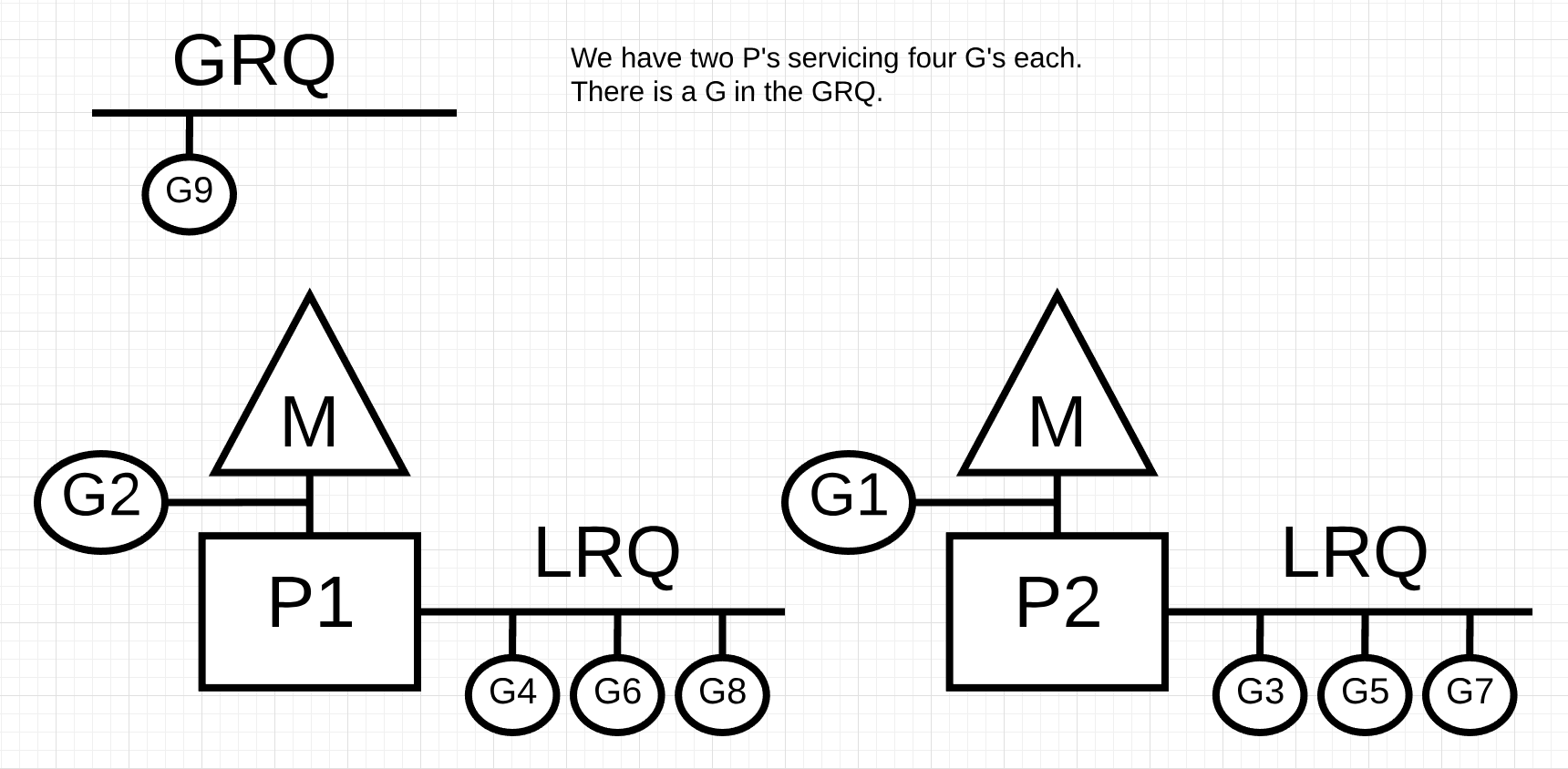
P1, P2는 LRQ의 고루틴을 POP하여 작업을 수행합니다.
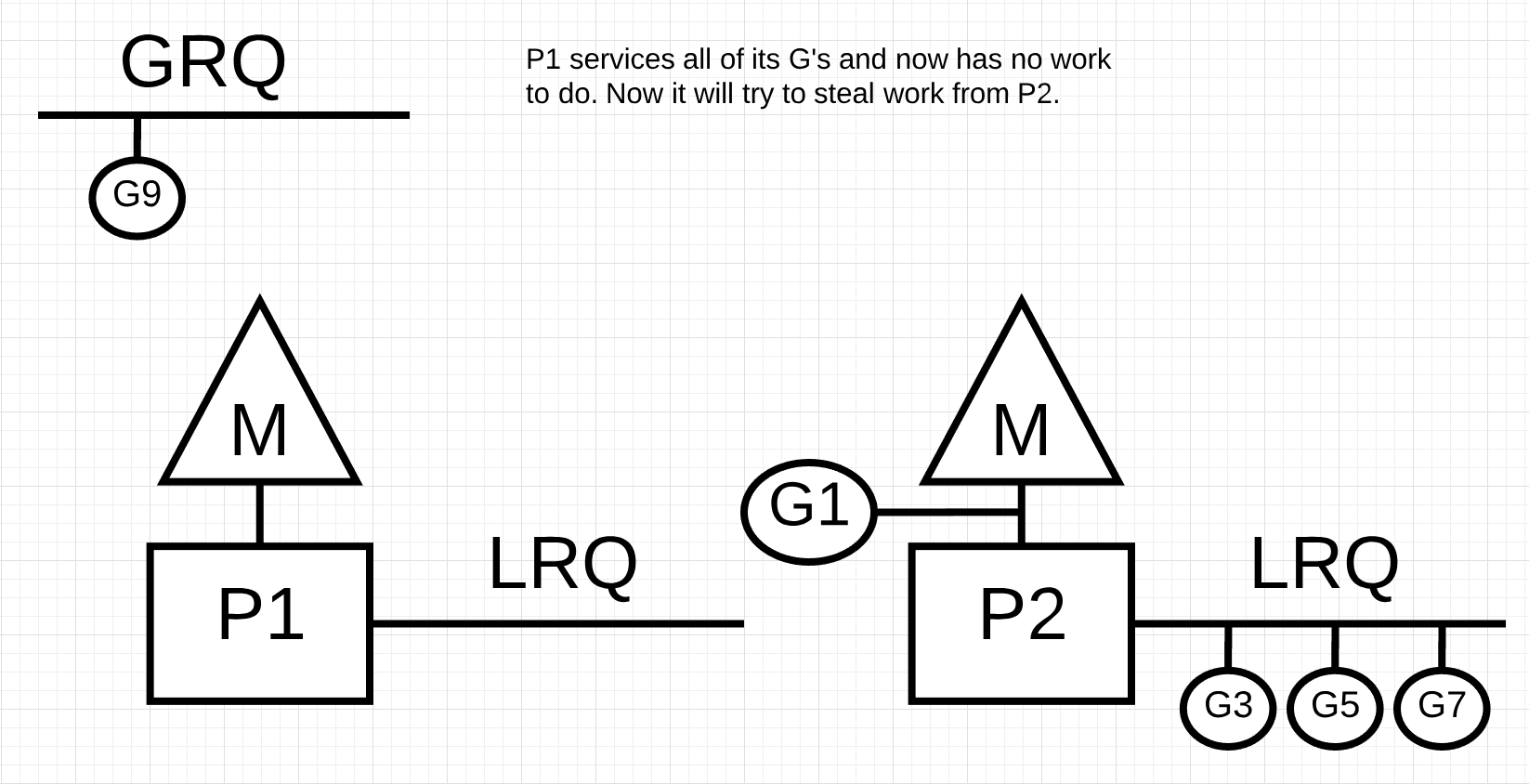
P1이 LRQ의 모든 작업을 완료합니다. P2는 여전히 G1 작업을 처리 중입니다. 이 시점에 작업 훔치기가 시도됩니다.
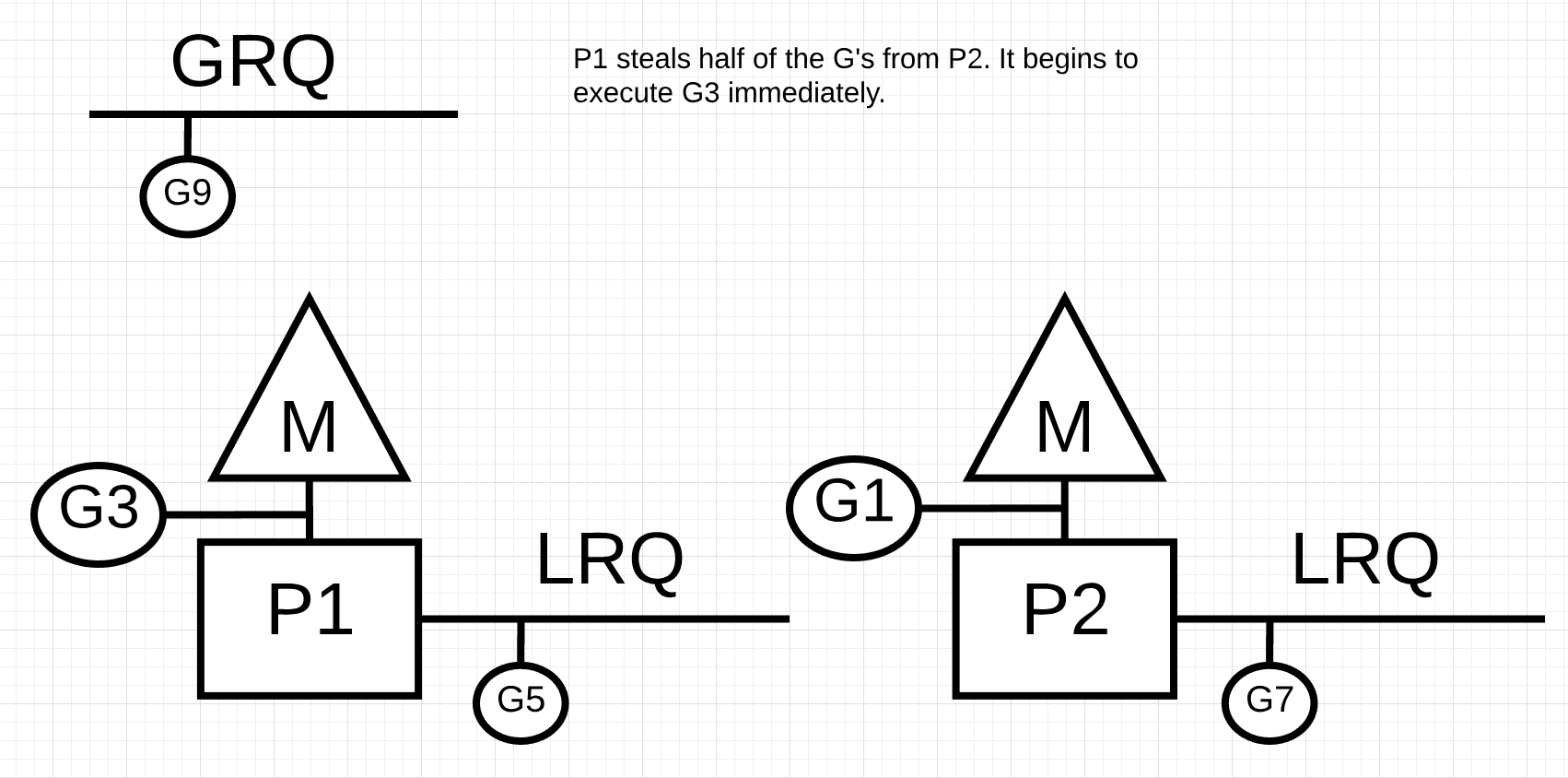
P1은 P2의 LRQ를 확인하여 절반인 G3, G5를 가져와 작업을 계속 진행합니다.
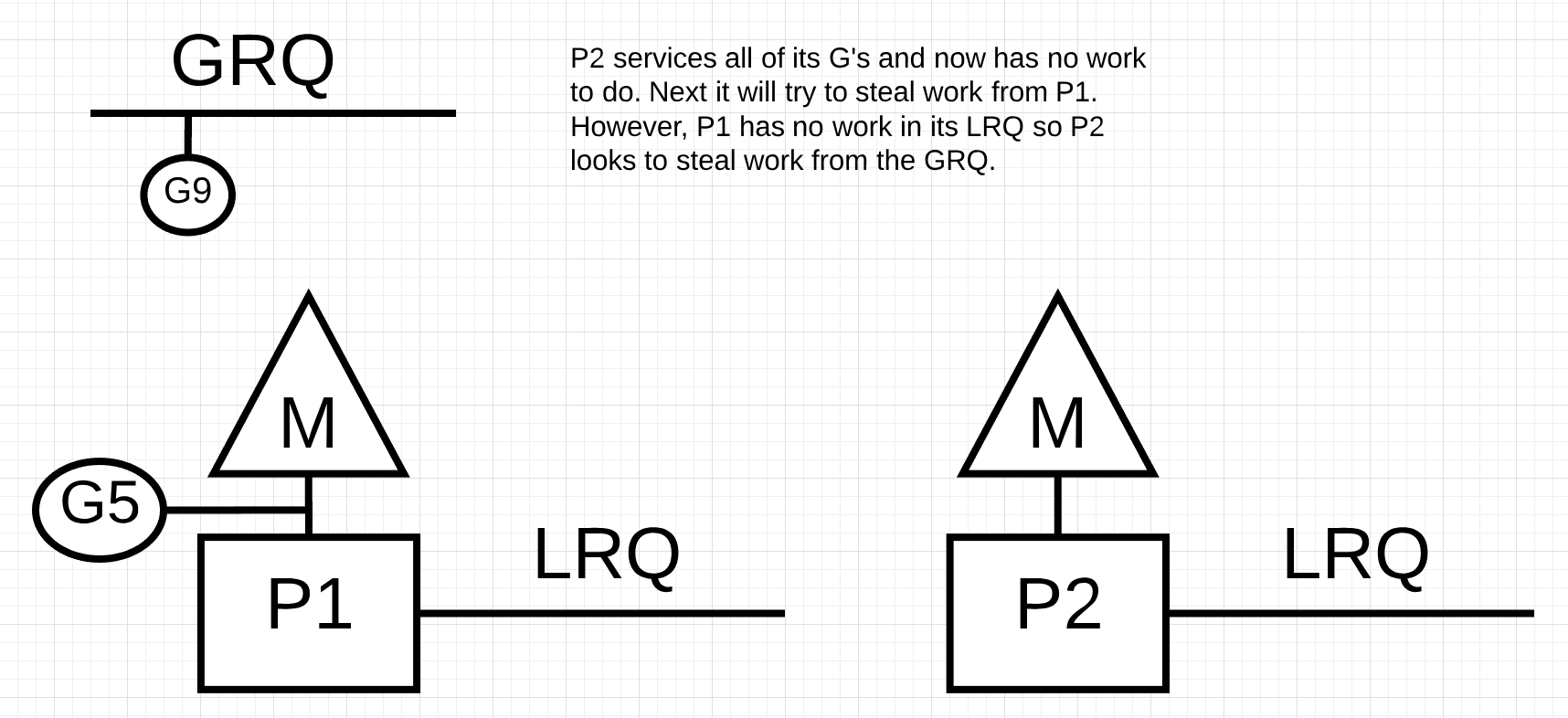
이번엔 P2가 작업을 완료했습니다. 그리고 작업 훔치기를 시도하기 위해서P1의 LRQ를 확인하지만 실행 중인 고루틴을 제외하면 대기 중인 고루틴이 존재하지 않습니다. 계속해서 P2는 GRQ를 확인하고 대기 중인 G9를 가져와서 작업을 진행합니다.
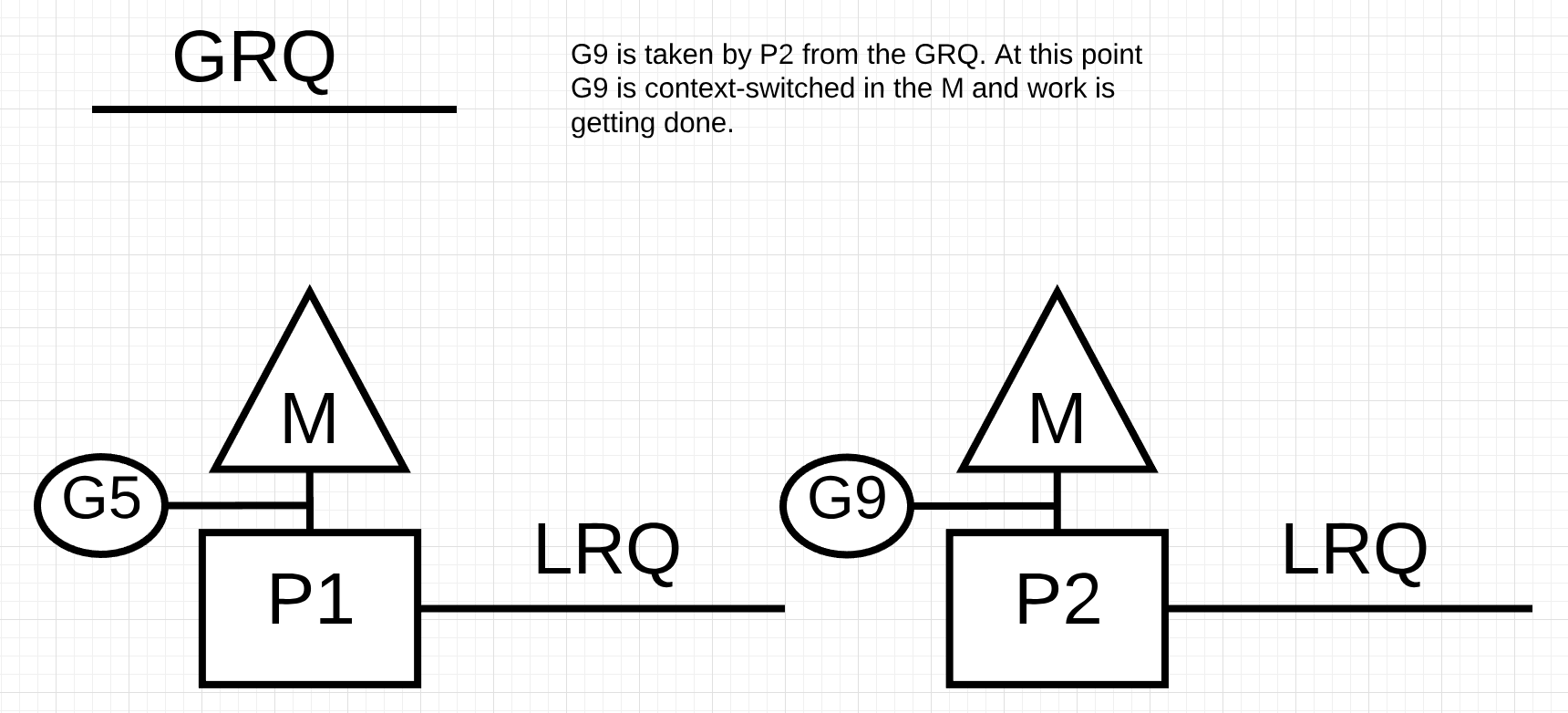
이를 통해서 프로세서 간에 효과적으로 로드 밸런싱이 가능하며, M이 컨텍스트 스위칭 하는 것을 막을 수 있습니다.
결론
발표를 위해서 준비한 내용인데요, 사실 발표 직전까지도 여전히 이해되지 않고 부족한 내용이 많았습니다. 발표가 마무리되면 다시 한번 공부해서 확실하게 이해를 해보도록 해야 할 것 같습니다.
공부하면서 알게 된 것은 Go 런타임이 스케줄링을 위해 하드웨어 및 OS 스케줄링 고려, 알고리즘 최적화, 실험 결과를 통한 설정 최적화 등 흥미로운 내용을 많이 구현하고 있었다는 사실입니다. 이런 내용에 대해 깊이 있게 이해하면 조금 더 잘 동작하는 동시성 프로그래밍을 잘 할 수 있을 것이라 생각합니다.
참고 자료
- https://blog.nindalf.com/posts/how-goroutines-work/
- https://afteracademy.com/blog/what-is-context-switching-in-operating-system
- https://nesoy.github.io/articles/2018-11/Context-Switching
- https://teraphonia.tistory.com/802
- https://www.scs.stanford.edu/12au-cs140/notes/l2.pdf
- https://d2.naver.com/helloworld/0814313
- https://blog.puppyloper.com/menus/Golang/articles/Goroutine%EA%B3%BC%20Go%20scheduler
- https://www.slideshare.net/KennethCeyer/grpc-goroutine-gdg-golang-korea-2019
- https://marsettler.com/posts/2018-10-13-go-work-stealing-scheduler/
- https://itnext.io/load-balancing-goroutines-in-go-57e0896c7f86
- https://cppis.github.io/golang/common/2020/10/21/whats.golang.scheduler.os.scheduler.html
- https://cppis.github.io/golang/common/2020/10/23/whats.golang.scheduler.go.scheduler.html
- https://ssup2.github.io/theory_analysis/Golang_Goroutine_Scheduling/
