Apache Kafka란?
아파치재단 공식 사이트에서 카프카는 Apache Kafka® is an event streaming platform" "라고 표현하고 있다.
일반적인 IT 시스템 기반에 서비스를 제공하는 플랫폼 등에서 발생되는 데이터를 처리한다고 가정해보자.
아래와 같이 시스템이 복잡해짐에 따라 데이터를 제공하는 시스템(=Source System)의 수와 데이터를 제공받는 시스템(=target system)의 수가 증가함에 따라 이를 운영하는 개발자와 관리자들은 점점 더 복잡해지고 관리해지기 어려워질 것이다. 각각의 integration(source:target)의 protocol, data format, data schema등이 다 다르다면 그 복잡도는 더 올라갈 것이다.
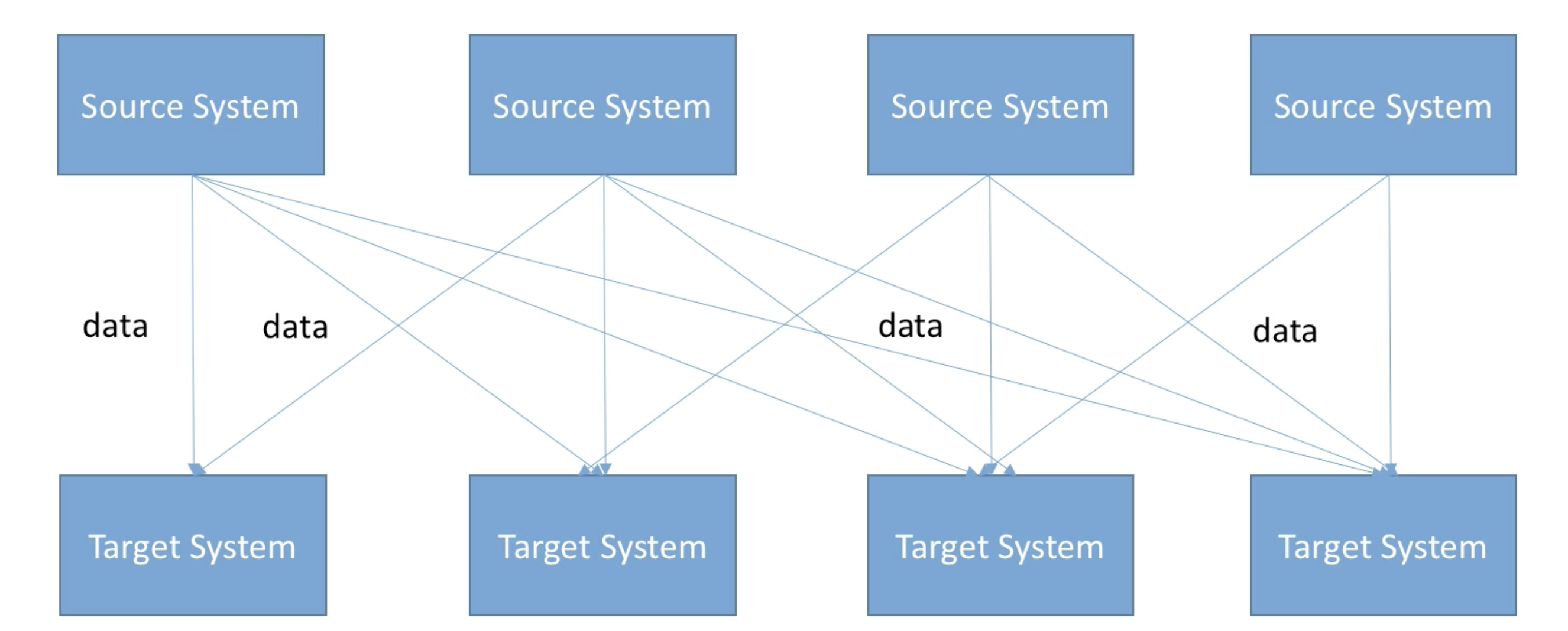
이를 해결하기 위해 링크드인에서 2011년도에 고안해낸 것이 바로 Apache Kafka 이다.

모든 source system은 kafka를 target으로 데이터를 송신하는 구조로 되어있다. target system 입장에서는 kafka에서 필요한 데이터를 가져가서 사용하는 형태로 되어있다. (일종의 중앙집중형)
위 아키텍쳐는 시스템간 의존도를 decouple 할 수 있게하여 대용량의 실시간 로그처리에 특화된 구조이다.
실시간(streaming)으로 생성되는 데이터를 가공 처리하여 event 핸들링 해야하는 Netflix, Uber와 같은 전세계 IT 서비스 공룡기업들에서 부터 국내 대기업, 스타트업 등에도 kafka와 같은 메시징 처리 시스템이 많이 사용되고 있다.
Apache Kafka의 구성요소와 동작
Kafka는 발행-구독(publish-subscribe) 모델을 기반으로 동작하며 크게 producer, consumer, broker로 구성된다. 아래의 사진은 단일 서버(broker) 기준 kafka의 동작방식을 나타낸다.
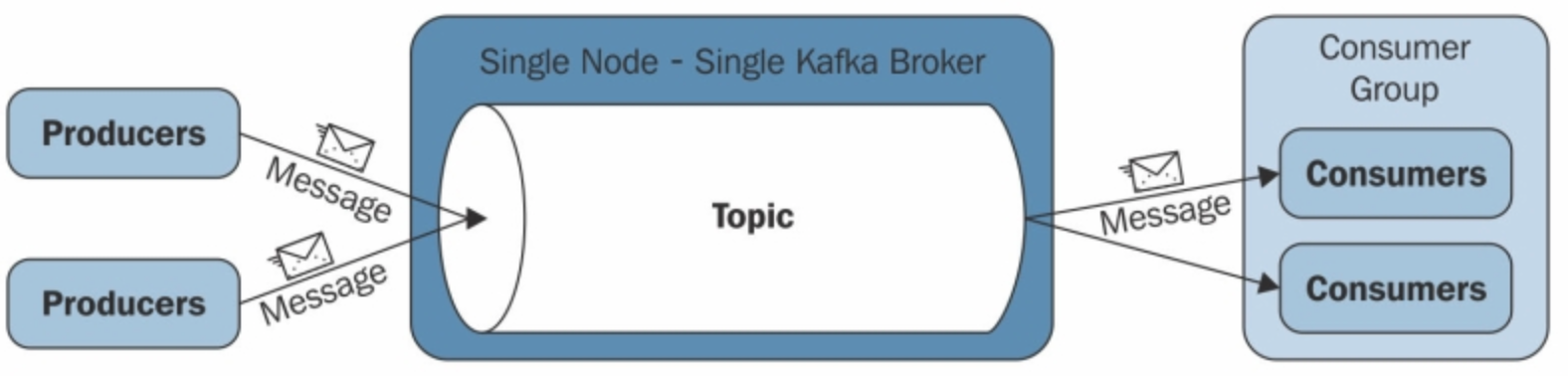
카프카 클러스터(위 그림에서는 broker)를 중심으로 프로듀서와 컨슈머가 데이터를 push하고 pull하는 구조입니다. Producer, Consumer는 각기 다른 프로세스에서 비동기로 동작한다.
클러스터 기반의 카프카 아키텍쳐는 아래와 같다.
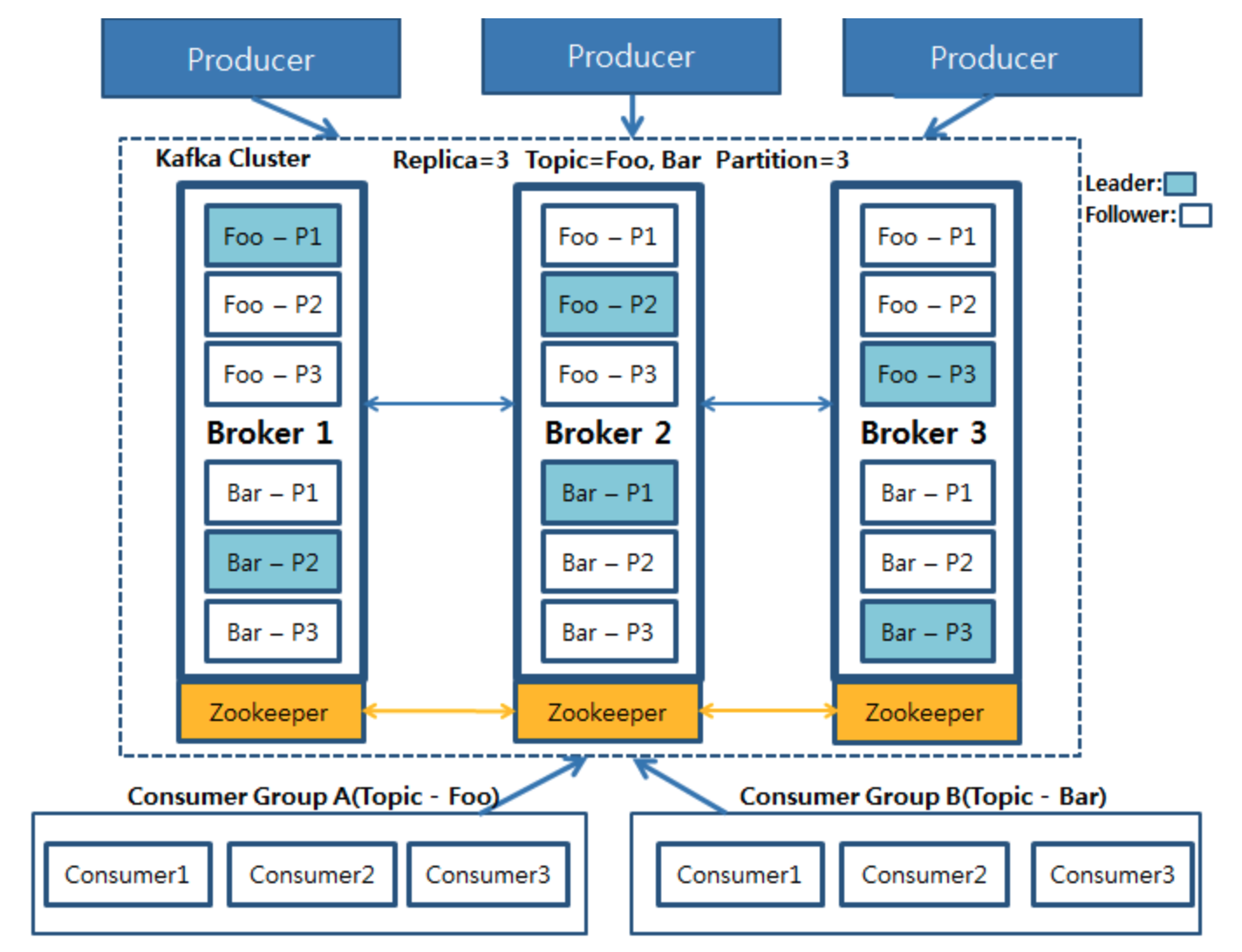
# 카프카 아키텍처를 구성하고 있는 구성요소
1. Topics, Partitions and Offsets
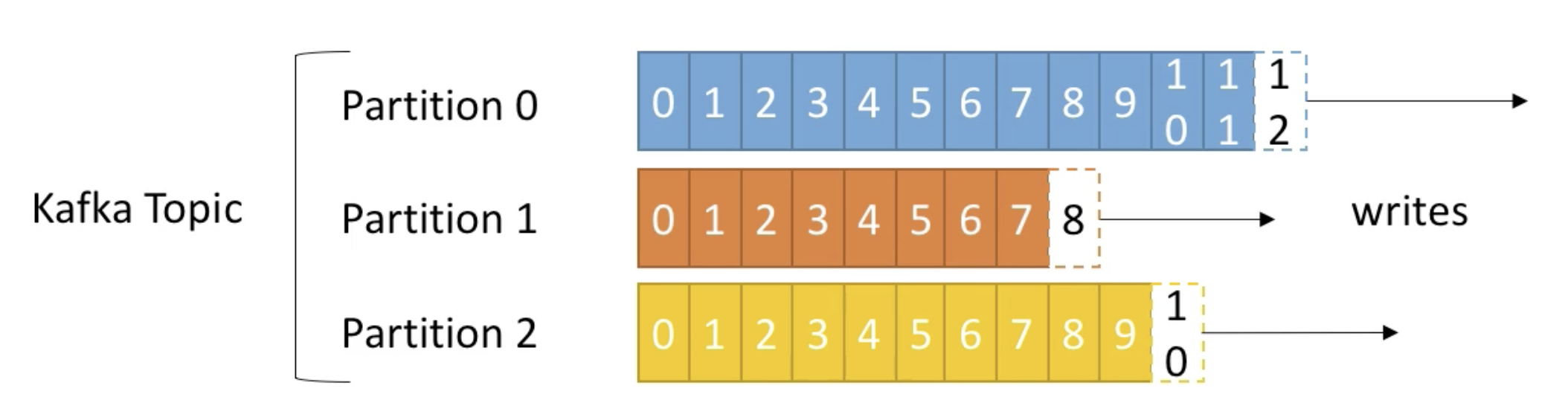
- 토픽(Topic) : 특정 스트림 데이터이며, 카프카 클러스터에 데이터를 관리할 시 기준이 된다.
- Similar to a table in a database (without all the constraints)
- 원하는 수만큼 토픽은 가질 수 있다.
- 토픽은 토픽 이름(=name)으로 구분됨
- 토픽은 파티션으로 나눠서 처리되며 각 파티션은 순서가 있고 각각의 파티션 내 메시지는 offset이라는 단위로 고유 id가 증가한다.
- 파티션(Partition): 각 토픽 당 데이터를 분산 처리하는 단위. 카프카에서는 토픽 안에 파티션을 나누어 그 수대로 데이터를 분산처리 한다. 카프카 옵션에서 지정한 replica의 수만큼 파티션이 각 서버들에게 복제된다
- offset은 특정 partition 에서만 의미가 있으며 순서 또한 속해있는 파티션 내에서만 보장된다. (즉, 'partion 0의 offset 3'은 'partion 1의 offset 3'에 있는 데이터와 다르다.)
- 데이터의 보존 주기는 default 7일이고 변경 가능하다. (log.retention.hours 설정)
- 데이터가 특정 파티션에 쓰여지면 절대 변경되지 않는다. (새로운 데이터는 새로운 파티션-오프셋에 쓰여짐)
- 특정 키로 파티션을 지정하지 않으면, 데이터는 랜덤하게 파티션이 지정되어 쓰여진다.
2. Brokers
- Kafka Cluster는 여러대의 broker(server)로 구성된다.
- 각 broker는 고유한 id 값으로 구분되며 특정 topic partition을 포함한다.
- bootstrap broker라 불리는 어떤 broker 에나 연결이 된다면, 전체 클러스터에 연결된 것이다.
- 통상 3개의 broker로 운영을 하는게 이상적이나 기업과 시스템의 규모에 따라서 100개 이상의 broker를 클러스터로 구성하여 운영하는 경우도 있다.
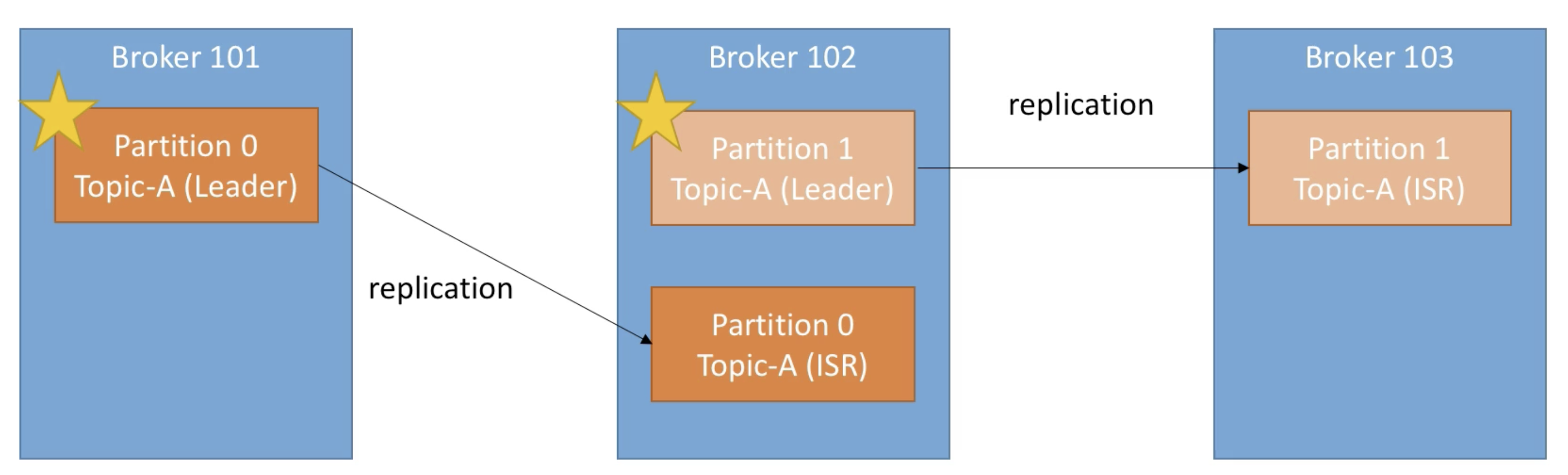
- Replication Factor
- Kafka topic 파티션의 Replication Factor(RF)는 broker 설정 중 offsets.topic.replication.factor에 의해 결정된다. 기본 값은 3으로, 하나의 파티션이 총 세 개로 분산 저장된다. (아래 사진은 replication factor가 2인 모습 -> leader 파티션 1 + ISR 파티션 1 / ISR = In-Sync Replica)
- Only 1개의 broker 만이 특정 파티션의 leader가 될 수 있고, leader만이 해당 파티션의 데이터를 송수신 가능하다. ISR 파티션의 경우는 데이터를 동기화 한다.
3. Producers
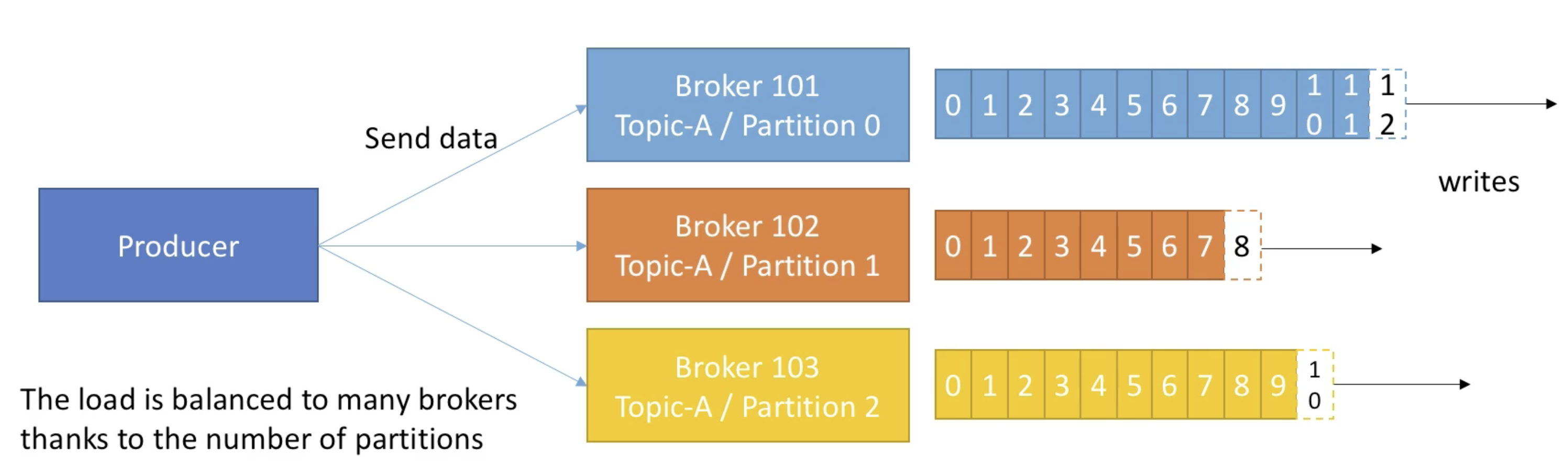
- Producer는 topic에 데이터를 write 한다.
- Producer는 데이터를 쓰는 때에 자동적으로 어떤 브로커와 파티션에 데이터를 write 할지 알고있다.
- Producer는 데이터를 write 할 때의 receive acknowledgment 를 선택할 수 있다.
- acks=0 : Producer는 acknowledgment를 기다리지 않음(데이터 손실 가능성이 있다.)
- acks=1 : producer는 leader acknowledgment를 기다렸다가 다음 액션을 함(제한된 데이터 손실 가능성)
- acks=all: leader+ISR acknowledgment를 모두 기다림(no data loss)
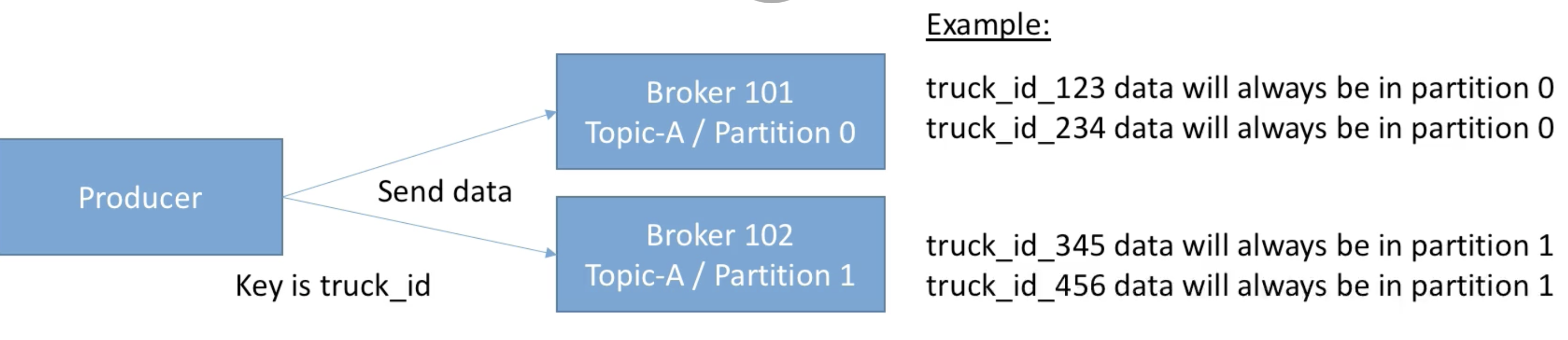
- Message keys
- Producer는 메시지 데이터와 함께 key를 선택하여 보낼 수 있다. (string, number, etc...)
- key=null 이라면, 데이터는 라운드로빈 동작으로 브로커에 순차적으로 데이터를 송신한다.
- key를 지정하여 데이터를 송신하면, 해당 key로 보내지는 데이터는 항상 (특정)같은 파티션으로 보내진다. (key hashing 방식)
4. Consumers & Consumer Groups
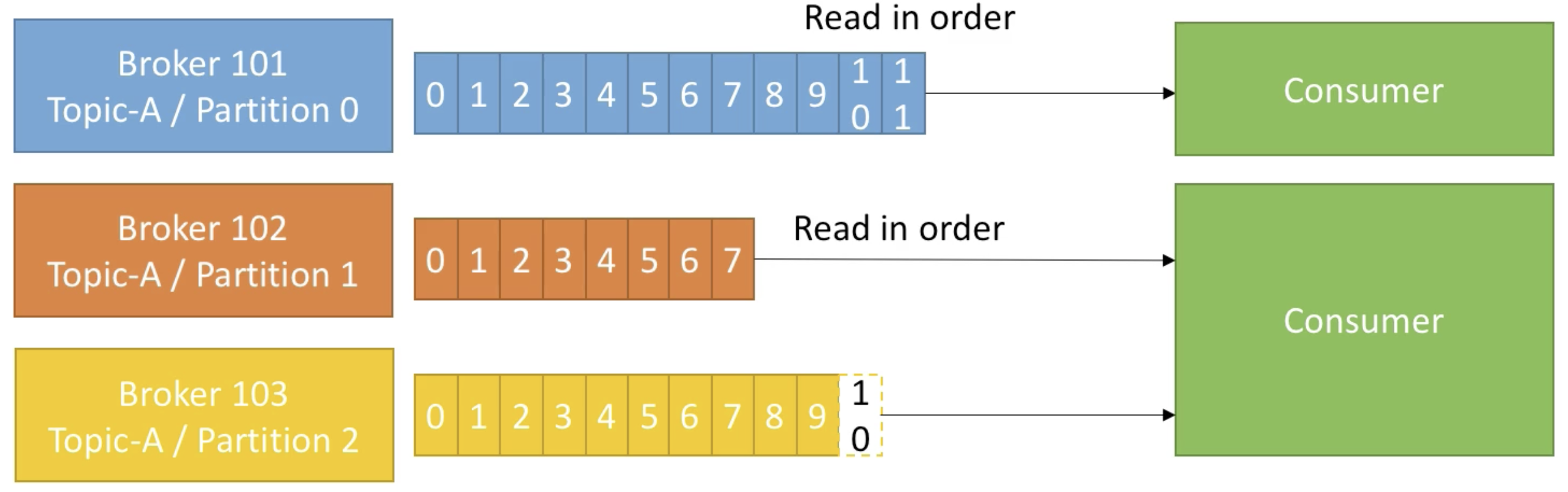
- Consumer는 topic에 있는 데이터를 read 한다.
- Consumer는 데이터를 읽을 때에 자동적으로 어떤 브로커와 파티션에서 데이터를 read 할지 알고있다.
- 데이터는 각 파티션 내에서 순서대로 읽어온다.
- Consumer Groups
- Consumer는 Consumer Groups 안에 속하여 데이터를 read 한다.
- 그룹 내 각 Consumer는 서로 다른 partition에 할당된다.
- 만약 컨슈머의 수가 파티션의 수보다 많다면 몇 컨슈머는 수행 하는 것이 없이 놀고 있을 수 있다.
- 컨슈머는 자동적으로 GroupCoordinator와 ConsumerCoordinator를 사용하여 컨슈머와 파티션을 할당 한다.

- Consumer Offsets
- Kafka는 어디 까지 reading 했는지에 대한 offset 정보를 저장하고 있다. (__consumer_offsets)
- '__consumer_offsets' 덕분에, 컨슈머가 죽더라도 마지막 offset 다음부터 데이터를 읽을 수 있다.
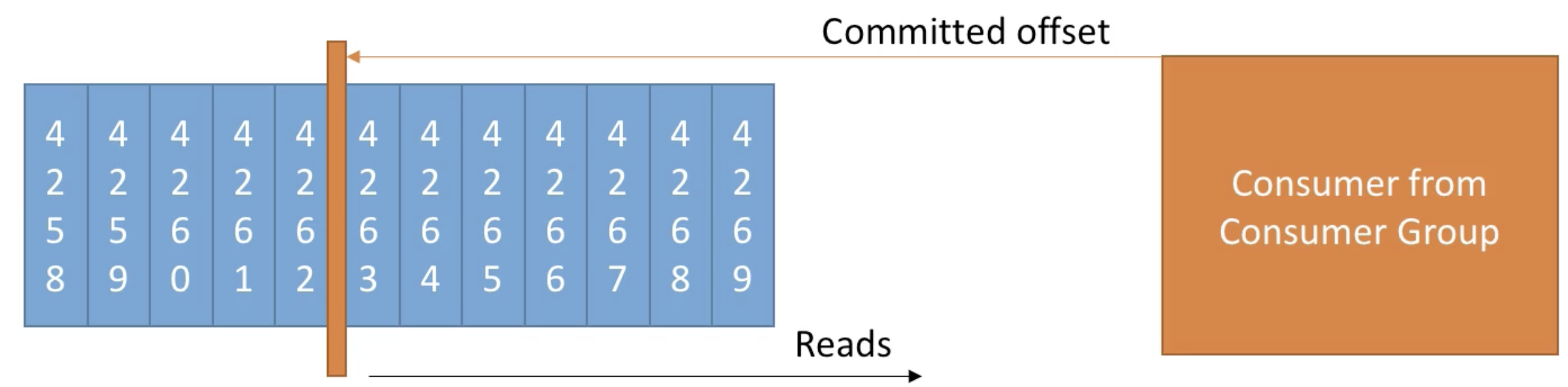
- 3 delivery semantics:
- At most once
- offsets are committed as soon as the message is received.
- If the processing goes wrong, the message will be lost (it won`t be read again.)
- At least once (usually preferred):
- offsets are committed after the message is processed.
- If the processing goes wrong, the message will be read again.
- This can result it duplicate processing of messages. Make sure your processing is idempotent (i.e. processing again the messages won`t impact your systems)
- Exactly once:
- Can be archieved for kafka => kafka workflows using Kafka Streams API
- For Kafka => External System workflows, use an idempotent consumer.
- At most once
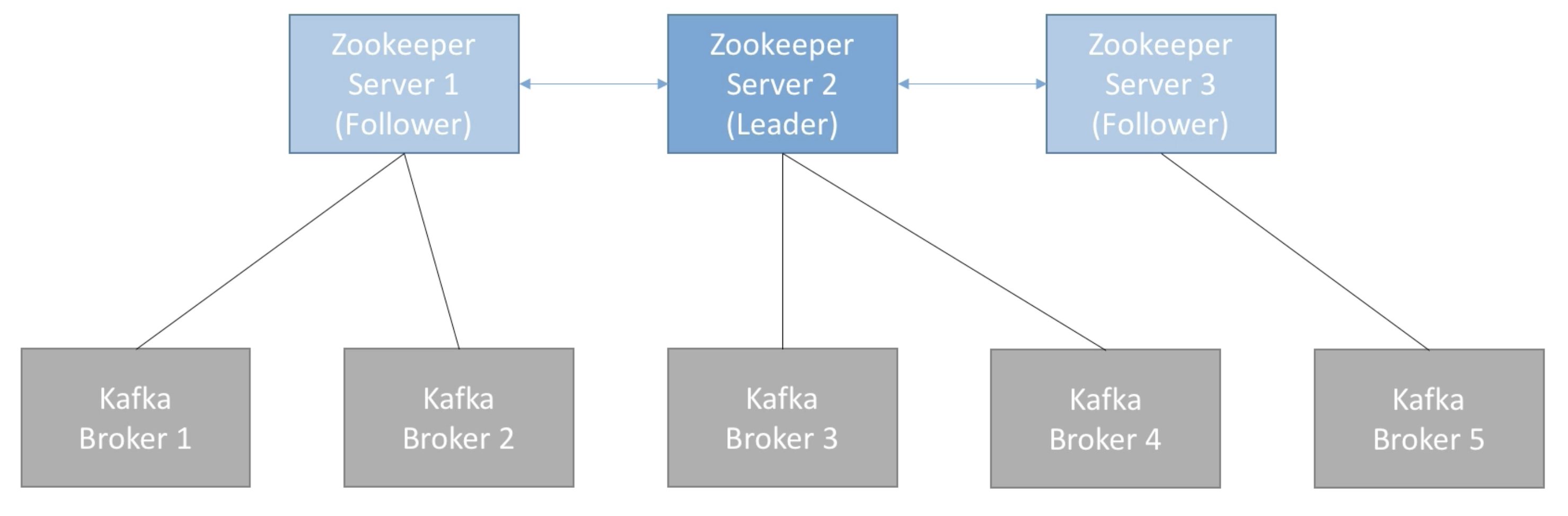
5. Zookeeper
- Zookeeper는 분산 코디네이션 시스템이다.
- 카프카 브로커를 하나의 클러스터로 코디네이팅하는 역할을 하며, 카프카 클러스터의 리더(Leader)를 발탁하는 방식을 제공한다.
- 새로운 토픽 생성, 브로커 서버 다운 등 모든 카프카 클러스터 내 변화들에 대하여 알림을 준다.
- 카프카는 주키퍼 없이는 작동할 수 없다.
- 보통 홀수 개의 서버 (3,5,7)수로 주키퍼는 운영됨
- consumer offset은 zookeeper가 가지고 있지 않다. (-> kafka topic 내 저장함 after v0.10)
이상으로 간단하게 Kafka의 개념과 구성요소 등에 대해서 작성하였다.
전체적인 kafka의 컨셉 디자인은 아래와 같이 정리할 수 있다.
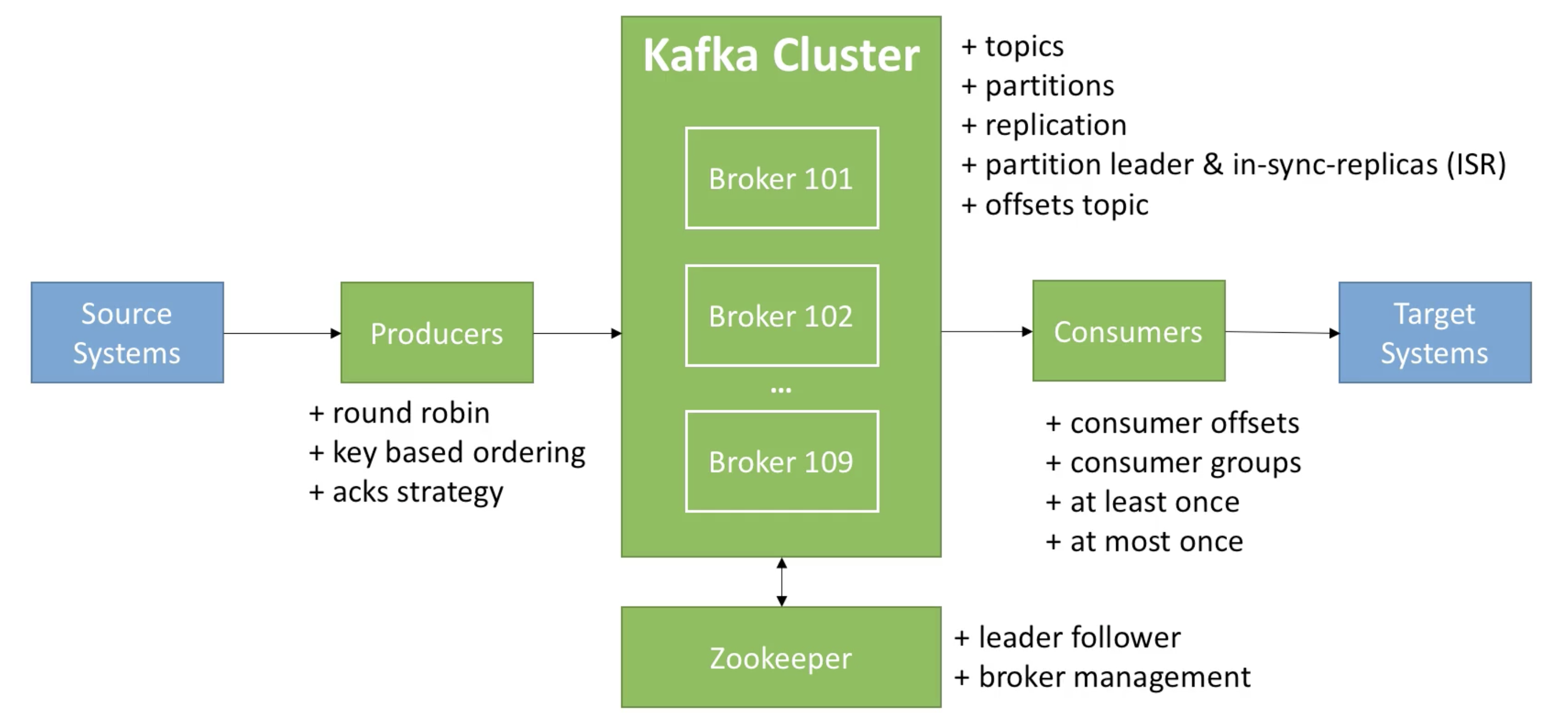
대량의 빅데이터를 실시간성으로 처리해야 하는 니즈를 담은 서비스들이 많아지면서 kafka와 같은 stream 기반의 데이터를 유실없이 빠르고 정확하게 처리할 수 있는 시스템에 대한 수요가 높아졌다.
최근 제일 큰 관심사 중 하나인 kafka 공부를 하며 정리용으로 내용을 담고 있어서 혹여나 내용에 이상이 있는 부분은 문의 부탁드립니다!
다음 시간에는 Kafka CLI의 간단히 직접 실습하고 이 부분에 대하여 정리해 보겠습니다.
[참고 자료]
https://kafka.apache.org/
https://kafka.apache.org/documentation/#design_pull
https://engkimbs.tistory.com/691
https://medium.com/@umanking/%EC%B9%B4%ED%94%84%EC%B9%B4%EC%97%90-%EB%8C%80%ED%95%B4%EC%84%9C-%EC%9D%B4%EC%95%BC%EA%B8%B0-%ED%95%98%EA%B8%B0%EC%A0%84%EC%97%90-%EB%A8%BC%EC%A0%80-data%EC%97%90-%EB%8C%80%ED%95%B4%EC%84%9C-%EC%9D%B4%EC%95%BC%EA%B8%B0%ED%95%B4%EB%B3%B4%EC%9E%90-d2e3ca2f3c2
https://victorydntmd.tistory.com/344
https://www.kafka-tutorials.com/?fbclid=IwAR3WUleZFaHy3u8OX-aOcSGin8y0I4Kpqq8Rmru2UkIcuKCg6vSNGkR_8Z4
