Apache Spark란?
- Apache Spark 는 대용량 데이터 프로세싱을 위한 빠르고 범용적인 인메모리 기반 클러스터 컴퓨팅 엔진 이다.
- 분산 메모리 기반의 빠른 분산 병렬 처리
- 배치, 대화형 쿼리, 스트리밍, 머신러닝과 같은 다양한 작업 타입을 지원하는 범용 엔진으로서 Apache Hadoop과 호환된다
- Scala, Java, Python, R 기반의 High-Level APIs 를 제공
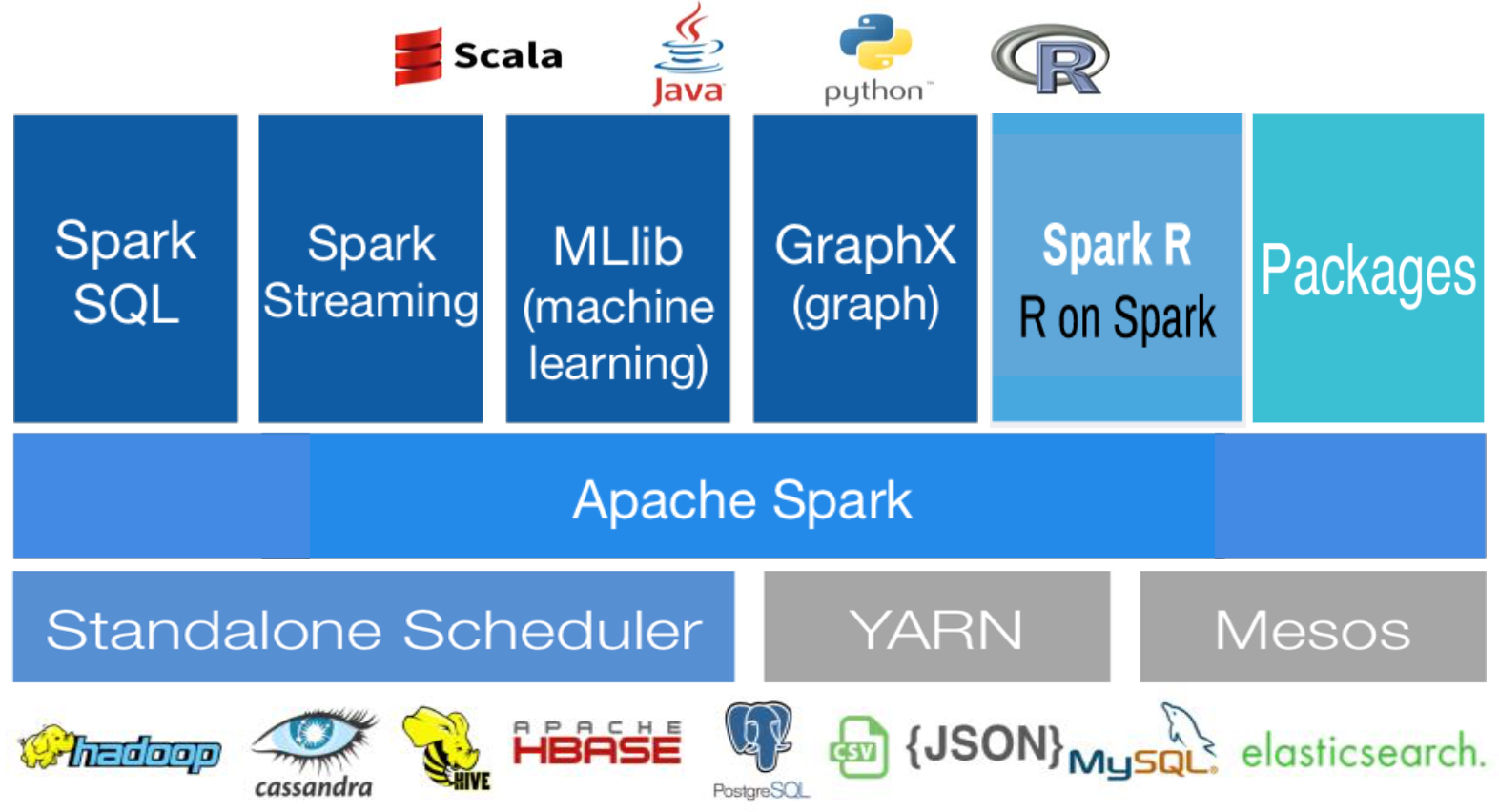
Apache Spark의 주요 특징
- In-Memory 컴퓨팅 (물론 Disk 기반도 가능)
- RDD (Resilient Distributed DataSet) 데이터모델
- 다양한 개발언어 지원 (Scala, Java, Python, R, SQL)
- Rich APIs 제공 (80여개 이상, 2~10x Less Code)
- General execution graphs => DAG (Directed Acyclic Graph) => Multiple Stages of Map-Reduce
- Hadoop과 유연한 연계 (HDFS, HBase, YARN ..)
- 빠른 데이터 Processing (In-Memory Cached RDD, Up to 100x faster)
- 대화형 질의를 위한 Interactive Shell (Scala, Python, R Interpreter)
- 실시간 (Real-Time) Stream Processing (vs. MapReduce for stored Data)
- 하나의 애플리케이션에서 배치, SQL 쿼리, 스트리밍, 머신러닝과 같은 다양한 작업을 하나의 워크플로우로 결합 가능
- Both fast to write and fast to run
RDD (Resilient Distributed Dataset)
- Dataset : 메모리나 디스크에 분산 저장된 변경 불가능한 데이터객체들의 모음
- Distributed : RDD에 있는 데이터는 클러스터에 자동분배 및 병렬 연산 수행
- Resilient : 클러스터의 한 노드가 실패하더라도 다른 노드가 작업 처리 (RDD Lineage, Automatically rebuilt on failure)
- Immutable : RDD는 수정이 안됨. 변형을 통한 새로운 RDD 생성
- Operation APIs :
- Transformations (데이터 변형, e.g. map, filter, groupBy, join)
- Actions (결과 연산 리턴/저장, e.g. count, collect, save)
- Lazy Evaluation : All Transformations (Action 실행 때까지)
- Controllable Persistence : Cache in RAM/Disk 가능 (반복 연산에 유리)

<RDD 생성 > RDD 변형 > RDD 연산>
Hadoop (vs Apache Spark)
하둡 Hadoop
- 참고: http://toppertips.com/hadoop-3-0-architecture/ (hadoop architecture)

- 동작원리 -
하둡 프레임워크는 파일 시스템인 HDFS(Hadoop Distributed File System)과 데이터를 처리하는 맵리듀스(MapReduce) 엔진을 합친 것으로 대규모 클러스터 상의 데이터 처리를 다음과 같은 방식으로 단순화합니다.
- 잡을 잘게 분할하고 클러스터의 모든 노드로 매핑(map)
- 각 노드는 잡을 처리한 중간결과를 생성하고
- 분할된 중간 결과를 집계(reduce)해서 최종 결과를 낸다.
이를 통해서 데이터를 여러 노드로 분산(distribution)하고 전체 연산을 잘게 나누어 동시에 처리하는 병렬 처리(parallelization)가 가능하고, 부분적으로 장애가 발생할 경우 전체 시스템은 동작할 수 있는 장애 내성(fault tolerance)을 갖는 시스템을 만들 수 있습니다.
맵리듀스의 핵심은 최소한의 API(map과 reduce) 만 노출해 대규모 분산 시스템을 다루는 복잡한 작업을 감추고, 병렬 처리를 프로그래밍적 방법으로 지원하는 점입니다. 또한 다루는 데이터가 크기 때문에 데이터를 가져와서 처리하는 것이 아니라, 데이터가 저장된 곳으로 프로그램을 전송합니다. 이 점이 바로 기존 데이터 웨어하우스 및 관계형 데이터베이스와 맵리듀스의 가장 큰 차이점입니다.
- 한계 -
- 맵리듀스 잡의 결과를 다른 잡에서 사용하려면 이 결과를 HDFS 에 저장해야 하기 때문에, 이전 잡의 결과가 다음 잡의 입력이 되는 반복 알고리즘에는 본질적으로 맞지 않습니다.
- 나눴다가 다시 합치는 하둡의 2단계 패러다임을 적용하기 어려운 경우가 있습니다.
- 하둡은 low-level 프레임워크이다 보니 데이터를 조작하는 high-level 프레임워크나 도구가 많아 환경이 복잡해졌습니다.
Spark Software Components

- Spark runs as a library in your program (one instance per app)
- Spark Driver
- client side application that creates Spark Context
- Spark Context
- Talks to Spark Driver, Cluster Manager to launch Spark Executors
- Runs tasks locally or on a cluster manager (Standalone, Mesos, YARN)
- Spark Application
- Driver program, Workers program
- Workers programs run on cluster nodes(Executors) or in local threads


성장하는 데이터 엔지니어를 꿈꾸는 호리입니다.