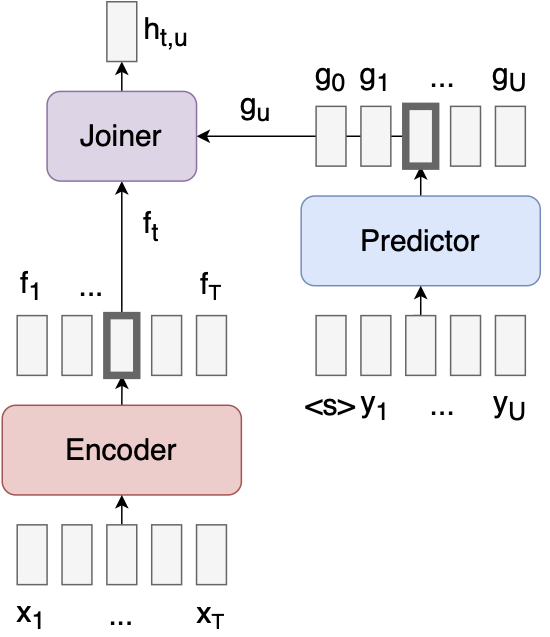
Sequence-to-sequence learning with Transducers
Transducer(RNN을 사용할 필요는 없지만 "RNN Transducer" 또는 "RNN-T"라고도 함)는 Alex Graves가 "반복 신경망을 사용한 시퀀스 변환(Sequence Transduction with Recurrent Neural Networks)"에서 제안한 seq2seq 모델입니다. 이 논문은 ICML 2012 Workshop on Representation Learning에서 출판되었습니다. Graves는 Transducer가 음성 인식에 사용하기에 적합한 모델이며 작은 데이터 세트(TIMIT)에서 좋은 결과를 달성했음을 보여주었습니다.
그 이후로 Transducer는 CTC 모델(예: Deep Speech 2) 또는 attention 모델(예: Listen, Attend 및 Spell)에 비해 많이 사용되지 않았습니다. 그러나 2019년에 Transducer는 Google 연구원들이 휴대폰에서 기기 내에서 대기 시간이 짧은 음성 인식(entirely on-device low-latency speech recognition)을 완전히 가능하게 할 수 있음을 보여주면서 큰 주목을 받았습니다. 그리고 최근에는 LibriSpeech 벤치마크에 대한 새로운 SOTA WER을 달성하기 위해 Transducer가 사용되었습니다.
그렇다면 Transducer란 무엇이며 언제 사용하고 싶습니까? 이 게시물에서는 Transducer 모델이 다른 시퀀스-투-시퀀스 모델과 어디에 적합한지 살펴보고 작동 방식에 대한 자세한 설명을 살펴보겠습니다.
이 게시물에는 toy problem에 대한 Transducer의 PyTorch 구현이 포함된 Colab 노트북도 포함되어 있습니다. 여기(here)로 바로 건너뛸 수 있습니다.
Attention Models
여기서 우리가 관심을 갖는 문제는 입력 시퀀스 를 출력 시퀀스 로 매핑하는 것이 목표인 시퀀스 변환 문제입니다.
시퀀스 변환 문제에 적합한(go-to) 모델은 RNN 인코더-디코더 모델(RNN encoder-decoder models) 또는 Transformer(Transformers)와 같은 Attention 기반 시퀀스-시퀀스 모델입니다.
다음은 Attention 모델의 다이어그램입니다. (아래 다이어그램에서 빨간색은 모듈이 x 에 대한 액세스 권한이 있음을 나타내고, 파란색은 y 에 대한 액세스 권한이 있음을 나타내고, 보라색은 x, y에 대한 액세스 권한이 있음을 나타냅니다.
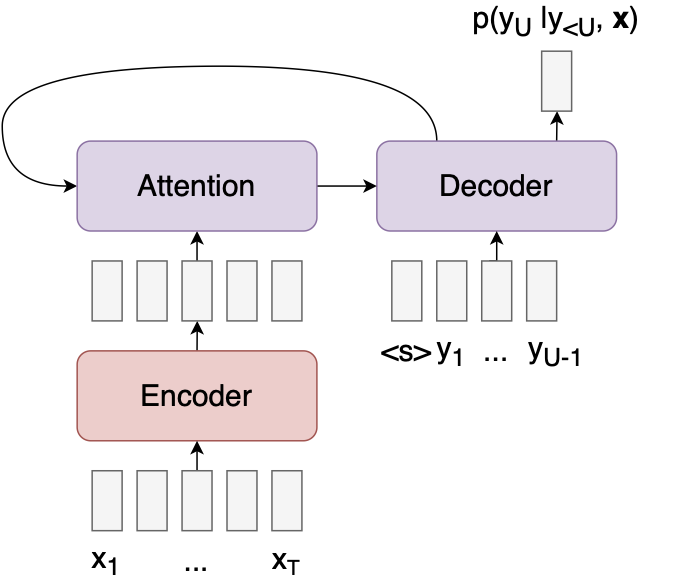
모델은 입력 x를 일련의 특징 벡터로 인코딩한 후 인코딩된 입력 및 이전 출력의 함수로 다음 출력 의 확률을 계산합니다. Attention 메커니즘을 통해 디코더는 각 출력을 예측할 때 입력 시퀀스의 다양한 부분을 볼 수 있습니다. 예를 들어 다음은 번역 작업 중에 디코더가 찾는 위치에 대한 히트맵입니다(from Bahdanau et al.).

Attention 모델은 모든 문제에 적용될 수 있지만 몇 가지 이유로 음성 인식과 같은 특정 문제에 대해 항상 최선의 선택은 아닙니다.
Attention 모델의 문제
- Attention 작업은 긴 입력 시퀀스의 경우 비용이 많이 듭니다. 모든 출력에 대한 전체 입력에 참여하는 복잡성은 이며 오디오의 경우 및 가 큽니다.
- 어텐션 모델은 디코더가 처리하기 전에 전체 입력 시퀀스를 사용할 수 있어야 하기 때문에 온라인(실시간)으로 실행할 수 없습니다.
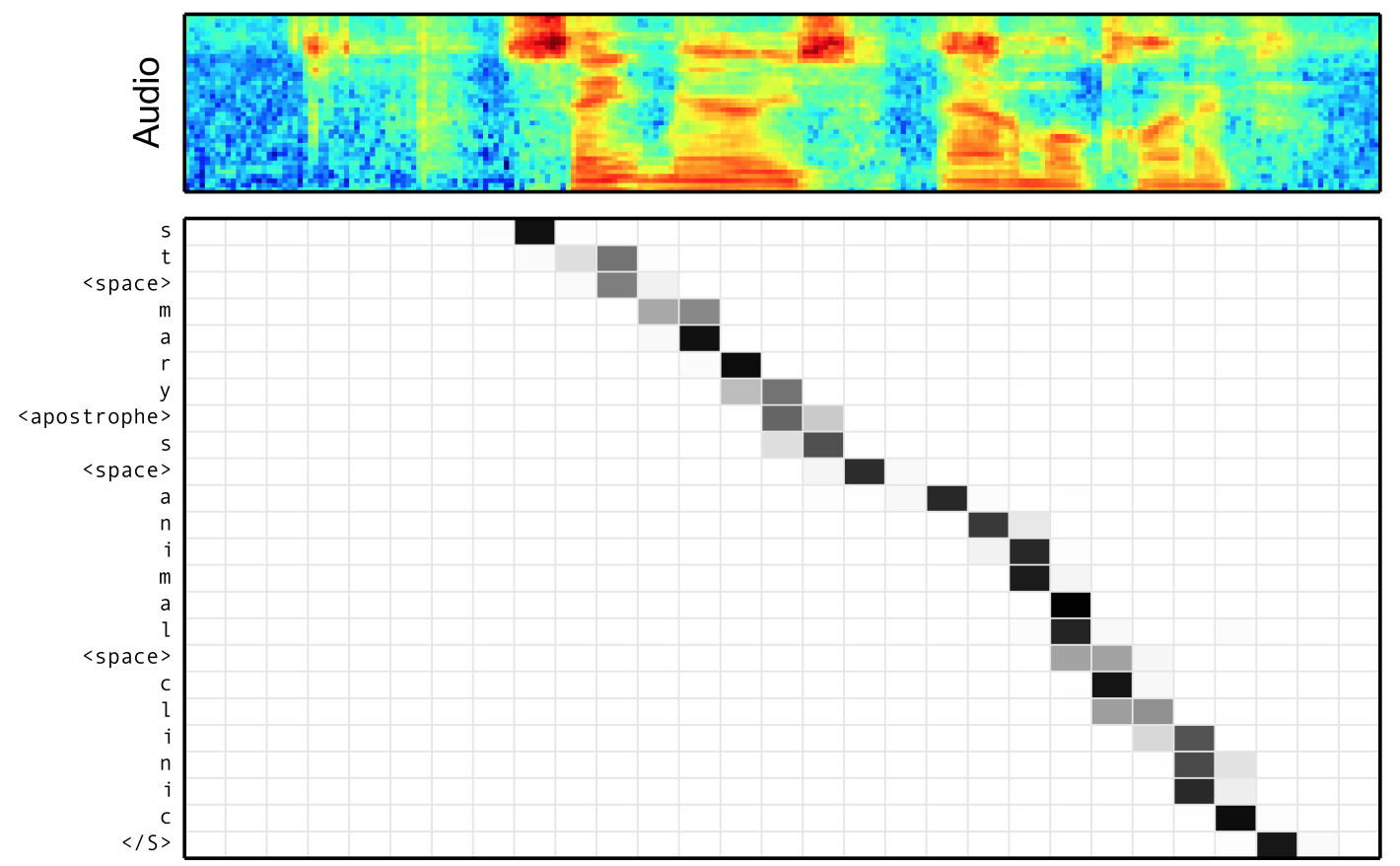
- Attention 모델은 또한 음성 인식의 경우 입력과 출력 간의 정렬이 단조롭다(
monotonic)는 사실을 활용하지 않습니다. 즉, transcript에서 단어 A가 단어 B 뒤에 오는 경우 오디오 신호에서 단어 A는 단어 B 뒤에 와야 합니다(단조 정렬(monotonic alignment)의 예는 Chan et al.의 아래 이미지 참조). Attention 모델에는 이러한 귀납적 편향(inductive bias)이 부족하다는 사실로 인해 음성 인식 훈련이 더 어려워지는 것 같습니다; 훈련을 안정화하기 위해 보조 손실 항(auxiliary loss terms)을 추가하는 것이 일반적입니다.
이는 Attention 모델보다 일부 문제에 더 적합한 연결주의 시간 분류(CTC) 모델로 이어집니다.
CTC Models
CTC 모델은 단조로운(monotonic) 입력-출력 정렬이 있다고 가정합니다. 결과적으로 모델이 훨씬 단순해졌습니다.
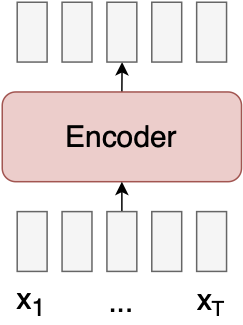
정말 간단합니다! CTC 모델을 구현하려면 단일 신경망만 필요하며 값비싼 global Attention 메커니즘은 필요하지 않습니다.
그러나 CTC 모델에는 몇 가지 문제가 있습니다.
CTC 모델의 문제
- Problem 1
- 출력 시퀀스 길이 U는 입력 시퀀스 길이 T보다 작아야 합니다.
- 이는 T가 U보다 훨씬 큰 음성 인식에서는 문제가 되지 않는 것처럼 보일 수 있습니다.
- 그러나 이는 모델을 훨씬 더 빠르게 만들 수 있는 풀링을 수행하는 모델 아키텍처를 사용하지 못하게 합니다.
- Problem 2
- 출력은 서로 독립적인 것으로 가정됩니다.
- 그 결과 CTC 모델은 "I ate food" 대신 "I eight food"와 같이 명백히 잘못된 출력을 생성하는 경우가 많습니다.
- CTC로 좋은 결과를 얻으려면 일반적으로 보조 언어 모델(secondary language model)을 통합하는 검색 알고리즘이 필요합니다.
Transducer Models
Transducer는 Attention 모델에 비해 일부 장점을 유지하면서 CTC와 관련된 두 가지 문제를 모두 우아하게 해결합니다.
Transducer는,
- 각 입력에 대해 여러 출력을 허용하여 Problem 1을 해결합니다.
- ❓ 이걸로 생기는 trade-off 단점은?
- 예측 네트워크와 Joiner5 네트워크를 추가하여 Problem 2를 해결합니다.
- ❓ 모델 내부에 LM 기능을 하는 Predictor가 있는거랑, CTC 이후에 추가적으로 LM을 쓰는게 크게 다른건가?
- 후자는 LM을 독립적으로 학습해야 하는거 가장 큰 차이점인가?
- 밑에서는 Predictor의 LM도 따로 사전 학습 한다는데?
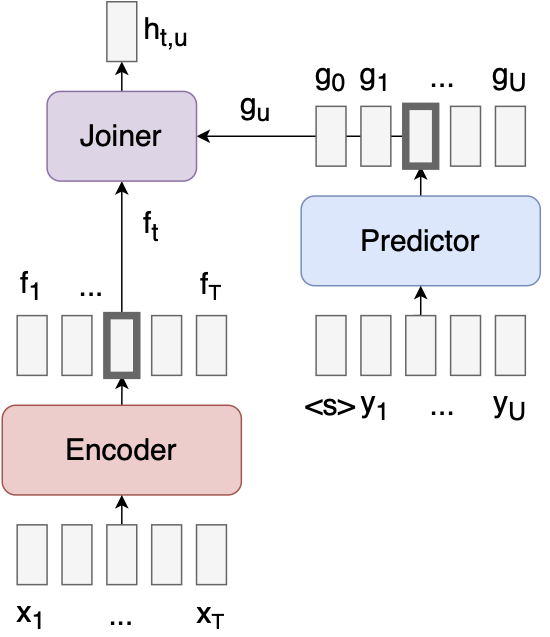
Predictor는 autoregressive 합니다. Predictor는 표준 언어 모델처럼, 이전 출력을 입력으로 사용하고 다음 출력을 예측하는 데 사용할 수 있는 feature을 생성합니다.
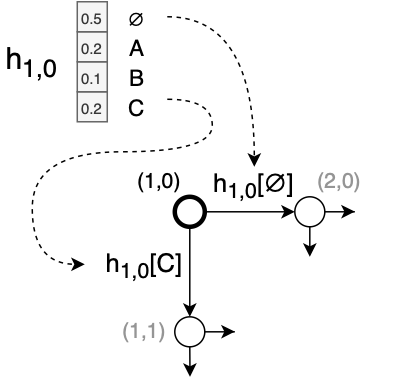
Joiner는 인코더 벡터 와 예측 벡터 를 결합하고 "null" 출력 ∅을 포함하는 모든 레이블에 대해 소프트맥스 를 출력하는 간단한 피드포워드 네트워크입니다.

입력 시퀀스 x가 주어지면 간단한 탐욕 검색 알고리즘을 사용하여 출력 시퀀스 y를 생성할 수 있습니다.
-
t=1, y=0, y=empty list 로 세팅하고 시작
-
x를 이용하여 계산, y를 이용하여 계산
-
를 이용하여 계산
-
의 argmax가 labe l이면, u += 1, 라벨을 출력(이를 y에 추가하고 Predictor에 다시 공급)
의 argmax가 ∅ 이면, t += 1, (즉, 다음 입력 시간 단계로 이동하고 아무것도 출력하지 않습니다.)
-
t=T+1 이면, 끝. 아니면, 2부터 다시 수행
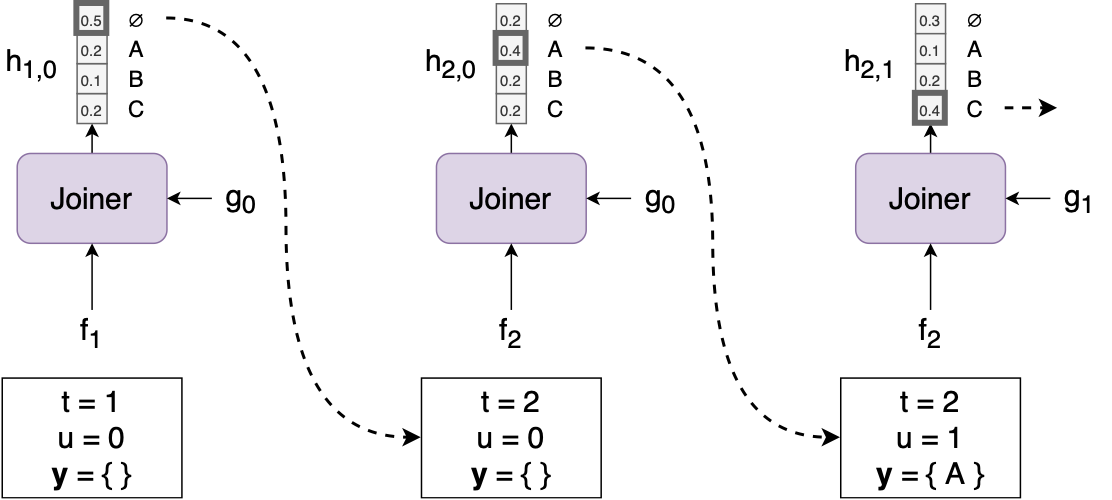
여기서 주목해야 할 트랜스듀서에 대한 몇 가지 멋진 점
- 인코더가 인과적인(causal) 경우(즉, 양방향 RNN과 같은 것을 사용하지 않는 경우) 검색(encoder, predictor, joiner의 일련의 과정을 의미하는 듯)은 온라인/스트리밍 방식으로 실행될 수 있으며 각 가 도착하자마자 처리됩니다.
- Predictor는 x와 y를 모두 보는 Attention 모델의 디코더와 달리 y에만 액세스할 수 있고 x에는 액세스할 수 없습니다. 이는 쌍(음성, 텍스트) 데이터보다 훨씬 더 많은 텍스트 전용 데이터에 대해 Predictor를 쉽게 사전 훈련할 수 있음을 의미합니다.
Alignment
쌍이 주어지면 변환기는 x와 y 사이에 가능한 단조 정렬(monotonic alignments) 집합을 정의합니다. 예를 들어, 길이 T=4의 입력 시퀀스와 길이 U=3의 출력 시퀀스("CAT")를 생각해 보세요. 다음과 같이 그래프를 사용하여 정렬 집합을 설명할 수 있습니다.
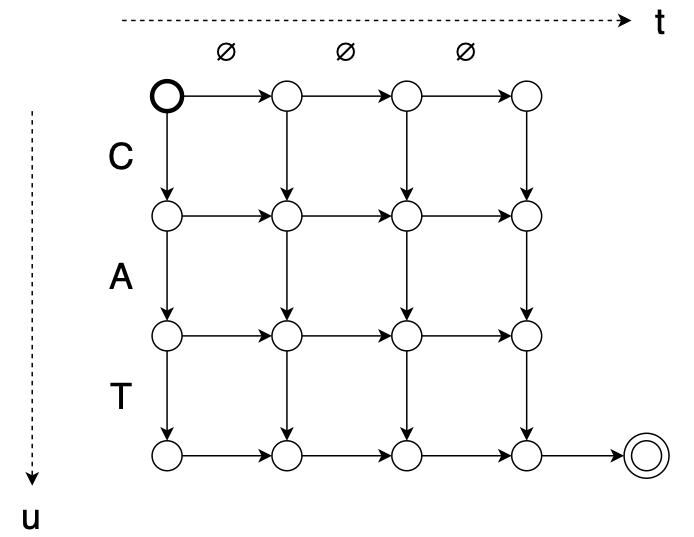
정렬 에 대한 그래프는 다음과 같습니다.
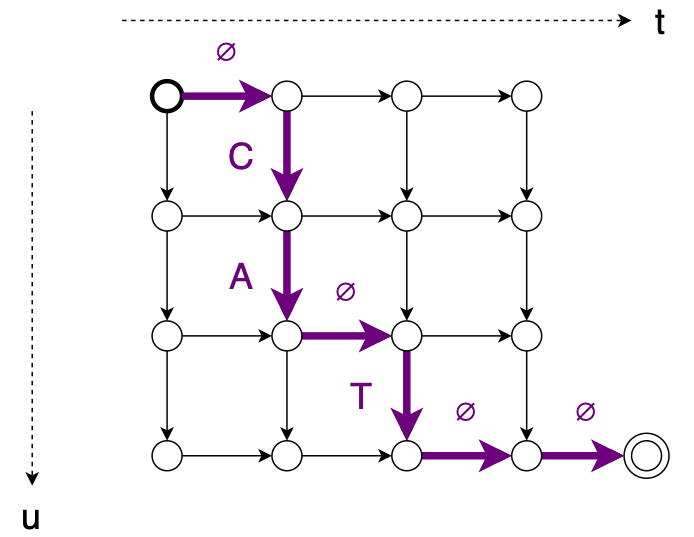
또 다른 정렬 에 대한 그래프는 다음과 같습니다.
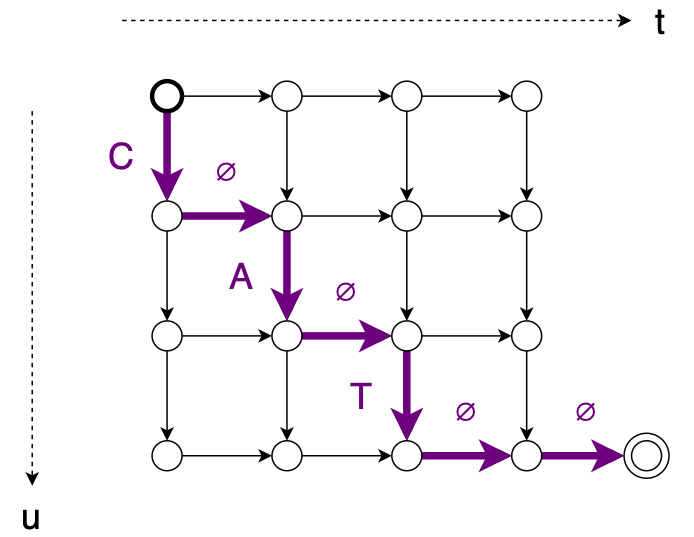
경로를 따라 각 edge 확률의 값을 곱하여 이러한 정렬 중 하나의 확률을 계산할 수 있습니다. 여기서 간선의 값은 의 해당 항목입니다.
Training
모델을 어떻게 훈련하나요? 실제 정렬 z를 안다면 , 일반 Classifier처럼 h와 z 사이의 교차 엔트로피를 최소화할 수 있습니다. 그러나 우리는 일반적으로 실제 정렬을 알지 못합니다(일부 작업의 경우 “실제” 정렬이 존재하지 않을 수도 있음).
대신, Transducer는 를 와 사이의 모든 가능한 정렬 확률의 합으로 정의합니다. 우리는 손실함수 를 최소화함으로써 모델을 학습합니다.
일반적으로 손실 함수를 모두 직접 추가하여 계산하기에는 가능한 정렬이 너무 많습니다. 합계를 효율적으로 계산하기 위해 "전향 변수(forward variable)" ()를 계산합니다.
-
이전 t, 이전 u에 대해 모두 고려하여, t번째 시점에 u번째 음소가 등장할 확률
-
❓근데 이러면 y축이 CAT으로 고정되는게 맞는데
-
❓학습과정에선 정답레이블이 주어져 있으니까 y축이 고정되는게 맞나?
-
❓그럼 , 이렇게 공존할 수 없는건가? u번째 음소에 나타날 레이블은 고정되어 있는 건가?
-
❓그럼 이 맞나?
정렬 그래프의 가장자리를 따라 값을 전달하는 것으로 이 계산을 시각화할 수 있습니다.
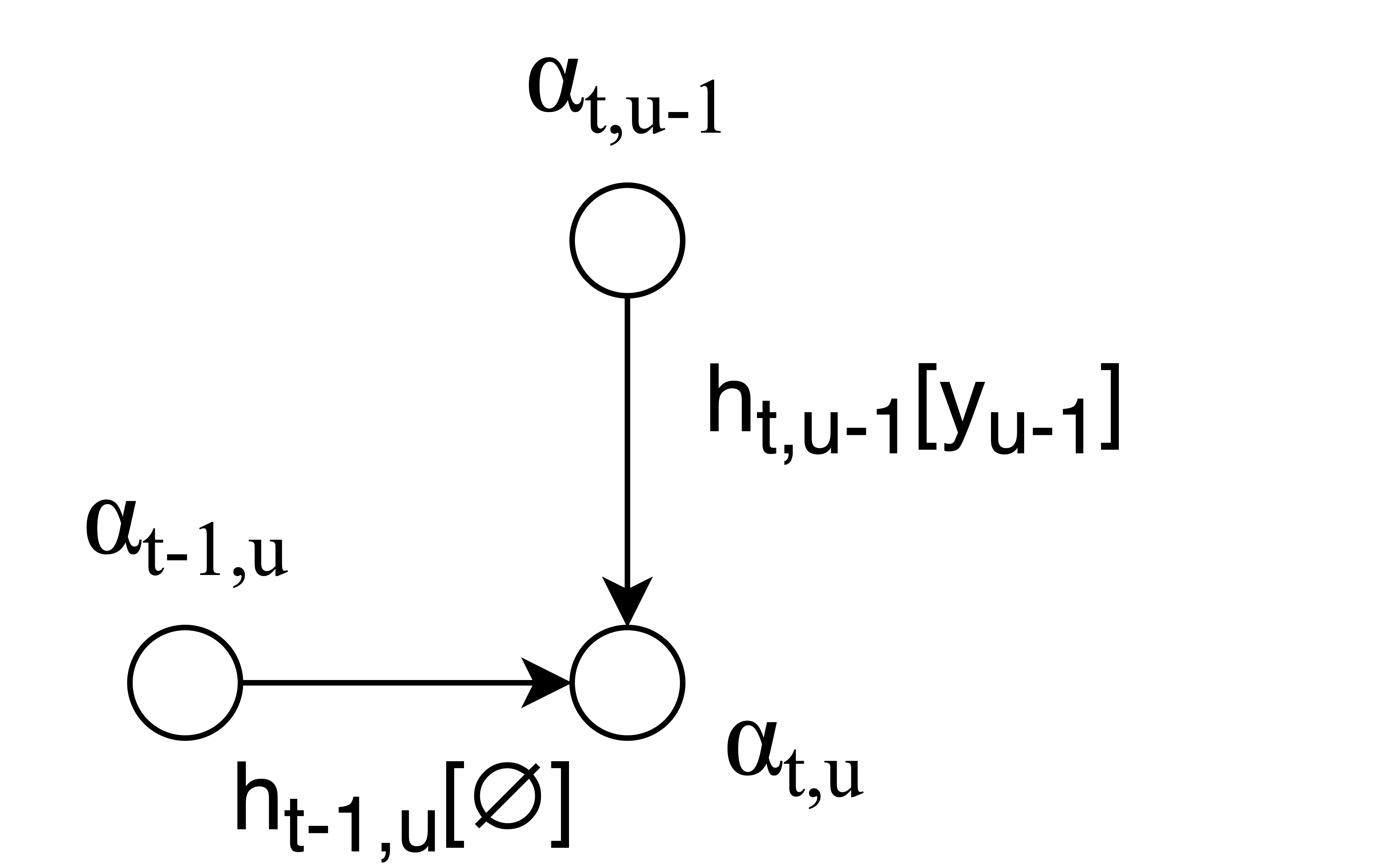
정렬 그래프의 모든 노드에 대해 를 계산한 후 그래프의 마지막 노드에서 순방향 변수를 사용하여 를 얻을 수 있습니다.
일반적인 이유로 로그 도메인에서 모든 작업을 수행해야 합니다. 로그 도메인에서 계산은 다음과 같습니다.
- ❓ logsumexp?
- https://gregorygundersen.com/blog/2020/02/09/log-sum-exp/
- 읽어보면 도움이 될 것 같다
어쨋든, 위의 식을 적용하면 다음을 도출할 수 있습니다.
마지막으로 손실의 기울기 를 계산하기 위한 두 번째 알고리즘이 있습니다. 이 알고리즘은 와 동일한 계산을 사용하지만 역방향으로 마지막 노드부터 시작하는 후방 변수 를 계산합니다.
노트북에서는 순방향 계산만 작성하고 자동 미분을 사용하여 기울기를 계산하는 손실 함수의 간단한 PyTorch 구현을 제공합니다. 이는 하위 수준 구현보다 훨씬 느리지만 프로그래밍하고 읽기가 더 쉽습니다.
Memory usage
일반적으로 Transducer 모델은 좋은 아이디어처럼 보입니다. 그러나 문제는 다음과 같습니다(최근까지 Transducer가 따라잡지 못한 무언의 이유일 수도 있음).
T=1000, U=100, L=1000 라벨, 배치 크기 B=32가 있다고 가정합니다. 그런 다음 모든 (t,u)에 대해 를 저장하여 정방향 알고리즘을 실행하려면 B×T×U× 크기의 텐서가 필요합니다. 또는 단정밀도 부동소수점을 사용하는 경우 12.8GB입니다. 그리고 그것은 단지 출력 텐서일 뿐입니다. 크기의 조이너 네트워크의 숨겨진 단위 활성화도 있습니다.
따라서 당신이 충분한 RAM을 갖춘 TPU를 소유한 특정 기술 회사가 아닌 이상(누가 가장 많은 Transducer 논문을 출판했는지 맞춰보세요!) 훈련 중에 메모리 소비를 줄이는 방법을 찾아야 할 수도 있습니다. 예를 들어 인코더에서 풀링하여 T를 줄이거나 작은 배치 크기 B를 사용하는 것입니다.
아이러니하게도 이는 훈련 중에만 발생하는 문제입니다. 추론하는 동안에는 y에 대한 현재 활성화 및 가설을 저장하는 데 약간의 메모리만 필요합니다.
Search
앞서 우리는 greedy 검색을 사용하여 항상 의 최상위 출력을 선택하여 y를 예측할 수 있다는 것을 보았습니다. 대신 y에 대한 여러 가설을 유지하고 각 입력 시간 단계에서 이를 업데이트하는 빔 검색을 사용하면 더 나은 결과를 얻을 수 있습니다.
Transducer 빔 검색 알고리즘은 원본 논문에서 찾을 수 있습니다. 비록 단순한 Attention 모델 빔 검색보다 다소 거칠고 아직 직접 구현하지 않았음을 고백합니다. (Check out the soon-to-be-released SpeechBrain toolkit for my colleagues’ implementation.)
Code
마지막으로 Transducer용 Colab 노트북은 여기(here)에서 찾을 수 있습니다. 노트북은 장난감 시퀀스 변환 문제(문장에서 누락된 모음 채우기: "hll wrld" –> "hello world")를 위해 PyTorch에서 Transducer 모델을 구현합니다. 여기에는 손실 함수, 탐욕 검색 및 단일 정렬 확률 계산 기능이 포함됩니다.
