성능 향상의 필요
Story의 RegionView를 표시하는 부분에서 눈에 띄게 버벅임이 발생하여 이를 개선하고자 결정하였다.
후에 알게 된 사실은, 내가 디버그 모드로 앱을 컴파일해서 버벅임이 발생했던 것이었다.
릴리즈 모드로 앱을 컴파일한 후, 버벅임 문제가 크게 개선된 것을 확인할 수 있었다.
이 부분에 대한 설명은 글의 마지막에 적어두었다.
이걸 어떻게 알았냐면 첫 번째로 해당 부분에 대해서 profile을 진행해보았을 때 문제가 전혀 없었다.

두 번째로 주목한 점은 벤치마크를 진행할 때 실제 화면에서는 버벅임이 전혀 발생하지 않았다는 것이었다.
그런데, 수동으로 앱을 실행했을 때만 그 버벅임을 느낄 수 있었다.
이 때 눈치를 챘어야 했는데 조금 삽질을 했다.
이런 삽질 과정을 통해 얻은 교훈과 배운 점들이 있었고, 이를 공유하고자 이 글을 작성하였다..!
1. 네트워킹 Thread 확인
먼저, StoryRegionResource 가져오는 과정에서 네트워크 요청이 메인 스레드에서 이루어지는지 확인하였습니다. 예상대로 해당 부분은 문제의 원인이 아니었습니다.
2. Paging 3 도입 및 로컬 데이터베이스 캐싱 전략에 대한 고민
Paging 3를 사용하면 한 번에 전체 데이터를 로드하는 것이 아니라, 페이지별로 데이터를 조각화하여 로드할 수 있다. 이러한 방식은 메모리 사용을 최적화하며 앱의 전반적인 성능 향상에 도움이 될 수 있다. 하지만, 서버 개발 측에서 이미 진행을 멈추었기 때문에, 이 기능을 도입하는 것이 현실적으로 어렵다고 판단하였다. 또한, 이미 LazyVerticalGrid를 사용하여 필요한 데이터만 로드하는 구조를 채택하고 있기 때문에, Paging 3의 도입이 크게 차이를 만들지 않을 것으로 예상하였다.
현재 진행 중인 프로젝트는 Demo 버전으로, 테스트를 위해 작성된 JSON 샘플 데이터를 바탕으로 FakeRemoteRepo를 구현하였다. 이 샘플 데이터의 규모가 크지 않기 때문에, Paging의 필요성이 크게 느껴지지 않았다.
다른 한편으로, 로컬 데이터베이스를 활용한 캐싱 전략을 고려했지만, 주요 기능이 이미지 로드인 앱의 특성상 이는 큰 이점이 없다고 판단하였다.
이미지 자체를 로컬에 저장하는 것은 공간을 많이 차지하게 되고, URL만 저장하는 경우 오프라인 접근성의 이점이 없다고 판단하였다. 또한, 주요 오버헤드는 백엔드에서 이미지 URL을 제공하는 것이 아니라, 해당 URL로부터 이미지를 로드하고 렌더링하는 과정에서 발생한다고 생각되었다. 이러한 고려 사항들로 인해, 결국 Paging 3와 로컬 데이터베이스의 도입은 결정되지 않았다.
추가로 인스타그램의 동작을 분석한 결과, 인스타그램은 페이징을 사용하지만 로컬 데이터베이스 캐싱은 활용하지 않는 것으로 보였다.
주요 콘텐츠인 이미지와 동영상에 대한 오프라인 캐싱은 확인되지 않았다. 또한, 빠르게 스크롤을 할 경우 데이터 로딩을 위한 일시적인 정지가 있었고, 새로운 페이징 데이터가 로드되어 일괄적으로 처리된 후에만 스크롤이 다시 확장되는 방식을 관찰하였다.
그래서 Paging은 백엔드 개발자 형이 퇴사당한다면 한번 도입해보자고 말하고 싶다. (장난입니다 행복하세요)
3. 이미지 Loading 및 Rendering 문제
다음으로 고민했던 주요 부분은 이미지의 로딩 및 렌더링과정에서 발생하는 부하 때문에 생기는 화면의 버벅임이었다.
이러한 문제를 근본적으로 해결하기 위해, 먼저 이미지 데이터를 네트워크에서 메모리로 가져오는 이미지 로딩 과정을 자세히 살펴보기로 결정했다.
저는 이미지 로딩을 위한 라이브러리로 Coil을 선택했습니다.
먼저 네트워크에서 이미지 데이터를 메모리에 가져오는 과정인 이미지 로딩 부분을 확인 해보았다.
나는 이미지 로딩 라이브러리로 Coil을 사용하였다
Coil
Coil은 Kotlin을 기반으로한 최신의 안드로이드 이미지 로딩 라이브러리입니다. Coil의 주요 특징은 메모리와 CPU 효율성에 중점을 둔 설계, 코루틴 기반의 비동기 처리, 생명주기 인식 기능 등이 있다고 합니다.

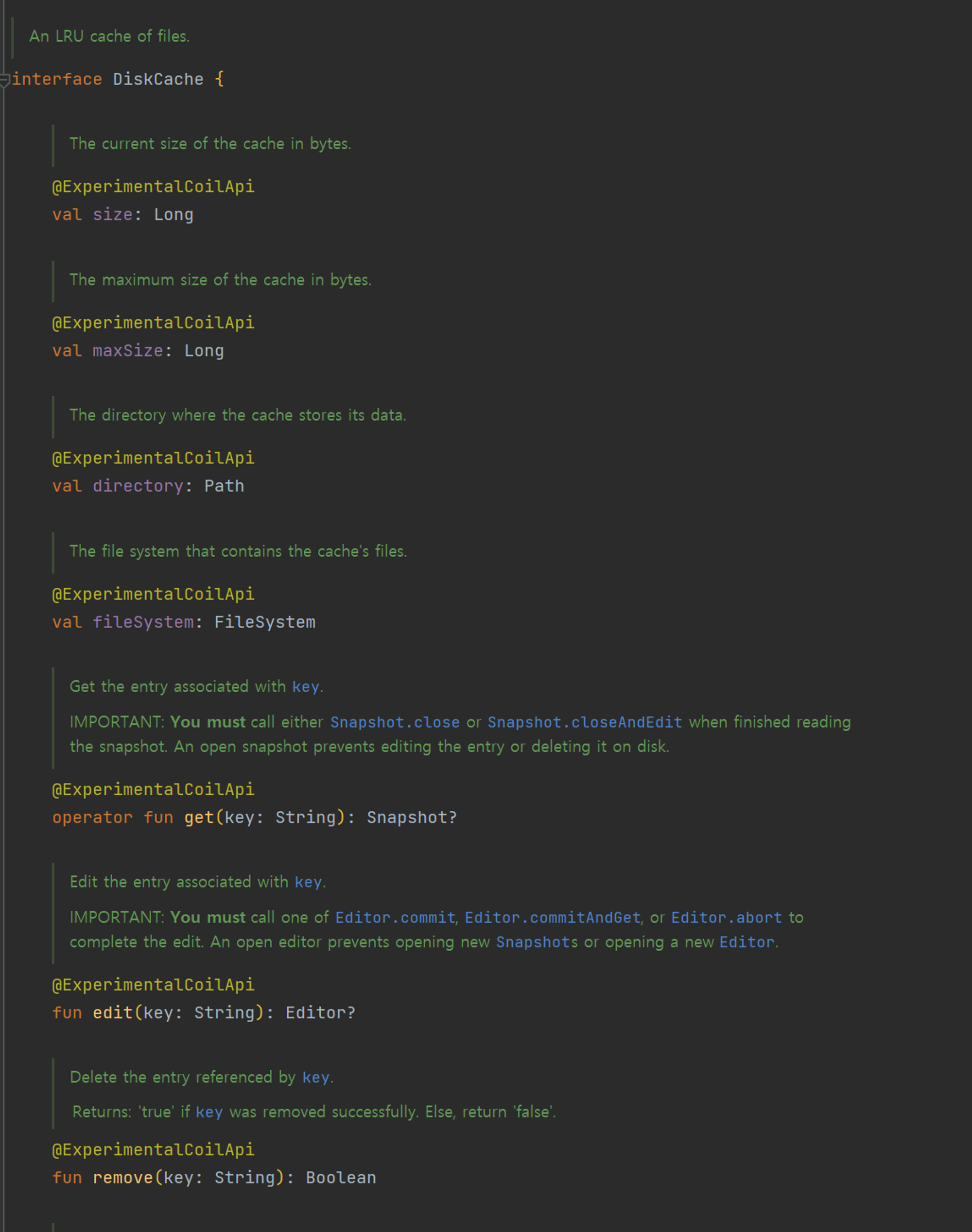
Coil의 핵심 구성 요소 중 하나는 ImageLoader 이다.
이는 URL로부터 이미지를 가져와 처리하는 기능을 담당한다.
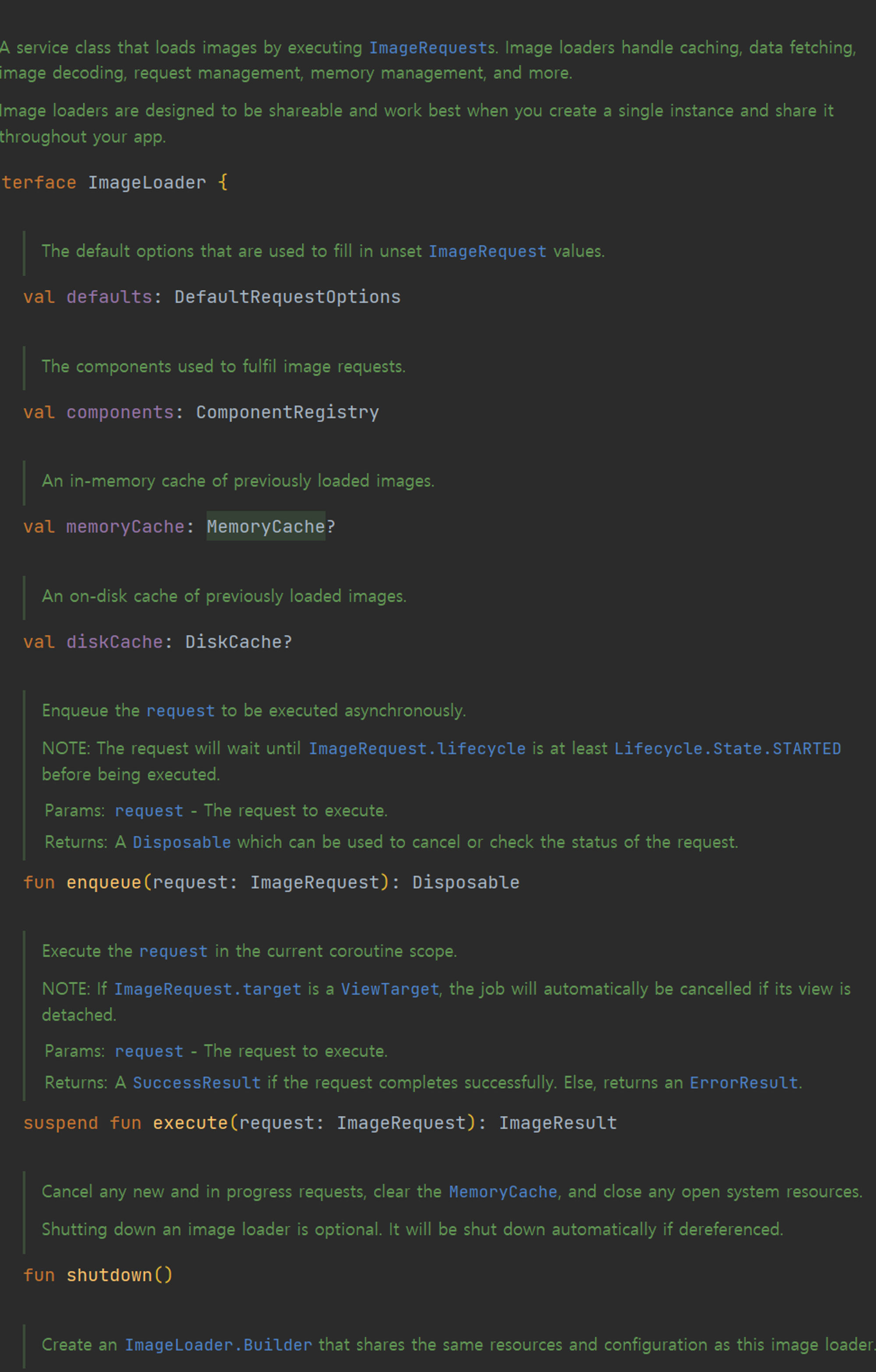
주석에서 볼 수 있듯이 Coil의 ImageLoader는 caching, data fetching , image decoding, reqeust management , memory management 등 다양한 작업을 처리한다고 한다.
프로퍼티
memoryCache: MemoryCache?: 이전에 로드된 이미지들의 메모리 캐시입니다.diskCache: DiskCache?: 이전에 로드된 이미지들의 디스크 캐시입니다.
메서드
enqueue(request: ImageRequest): Disposable:ImageRequest를 비동기적으로 실행하기 위해 대기열에 넣습니다. 요청의 실행은ImageRequest.lifecycle이Lifecycle.State.STARTED상태가 될 때까지 기다립니다.suspend fun execute(request: ImageRequest): ImageResult: 현재 코루틴 스코프에서ImageRequest를 실행합니다. 만약ImageRequest.target이ViewTarget인 경우, 해당 뷰가 분리되면 작업이 자동으로 취소됩니다.shutdown(): 새로운 요청과 진행 중인 요청을 취소하고,MemoryCache를 지우며, 열려있는 시스템 리소스를 닫습니다.
이러한 특징을 통해, Coil이 안드로이드 생명주기를 인식하며 메모리 및 디스크 캐시를 효과적으로 활용한다는 것을 확인할 수 있습니다.
Cache 부분 수정을 통해 이미지 로더의 성능을 향상시키려고 좀 더 알아봤습니다.
메모리 캐시
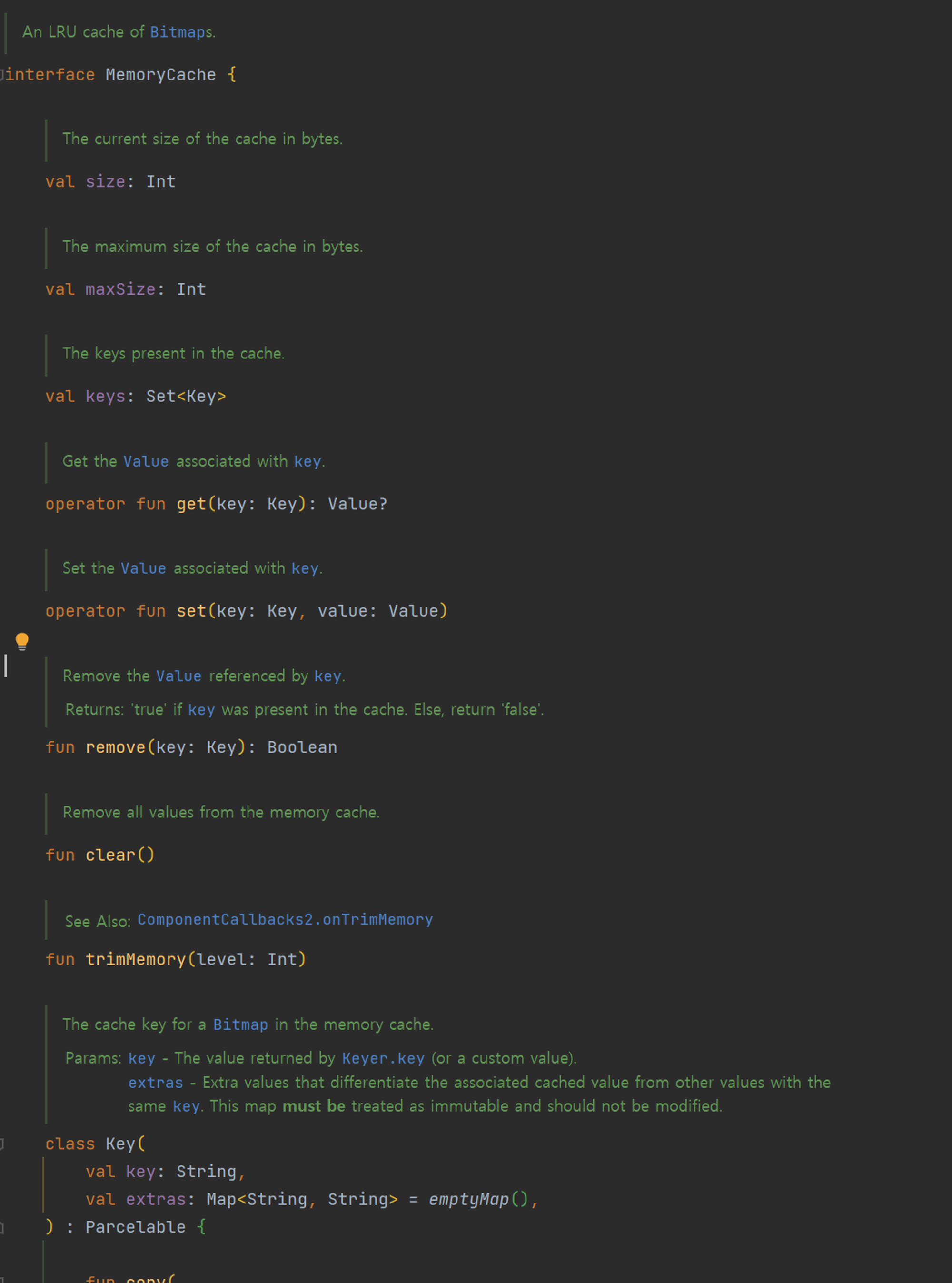
Coil 메모리 캐시는 주로 자주 사용되는 비트맵(Bitmap),을 빠르게 접근할 수 있도록 RAM에 임시로 저장하는 것을 의미합니다.
즉 주석에서 확인 할 수 있듯이 LRU (Least Recently Used) 전략을 사용합니다.
메모리 캐시를 사용하면 다시 그 객체를 생성하거나 네트워크 요청을 다시 보내는 것과 같은 무거운 작업을 줄일 수 있습니다.
size: 현재 캐시의 크기를 바이트 단위로 나타냅니다.maxSize: 캐시의 최대 허용 크기를 바이트 단위로 나타냅니다.keys: 캐시에 현재 저장된 모든 키의 집합get: 주어진 키에 연결된 값을 가져옵니다set: 주어진 키와 값을 캐시에 저장remove: 주어진 키와 그에 연결된 값을 캐시에서 제거clear: 모든 값을 캐시에서 제거trimMemory: 시스템의 메모리가 부족할 때 호출
내부적으로 좀 더 들어가보니간 cache가 LinkedHashMap을 통해서 이루어지고 있는데 옛날에 네부캠에서 LinkedHashMap 사용해서 간단하게 LRU 구현했던 기억이 나네요…

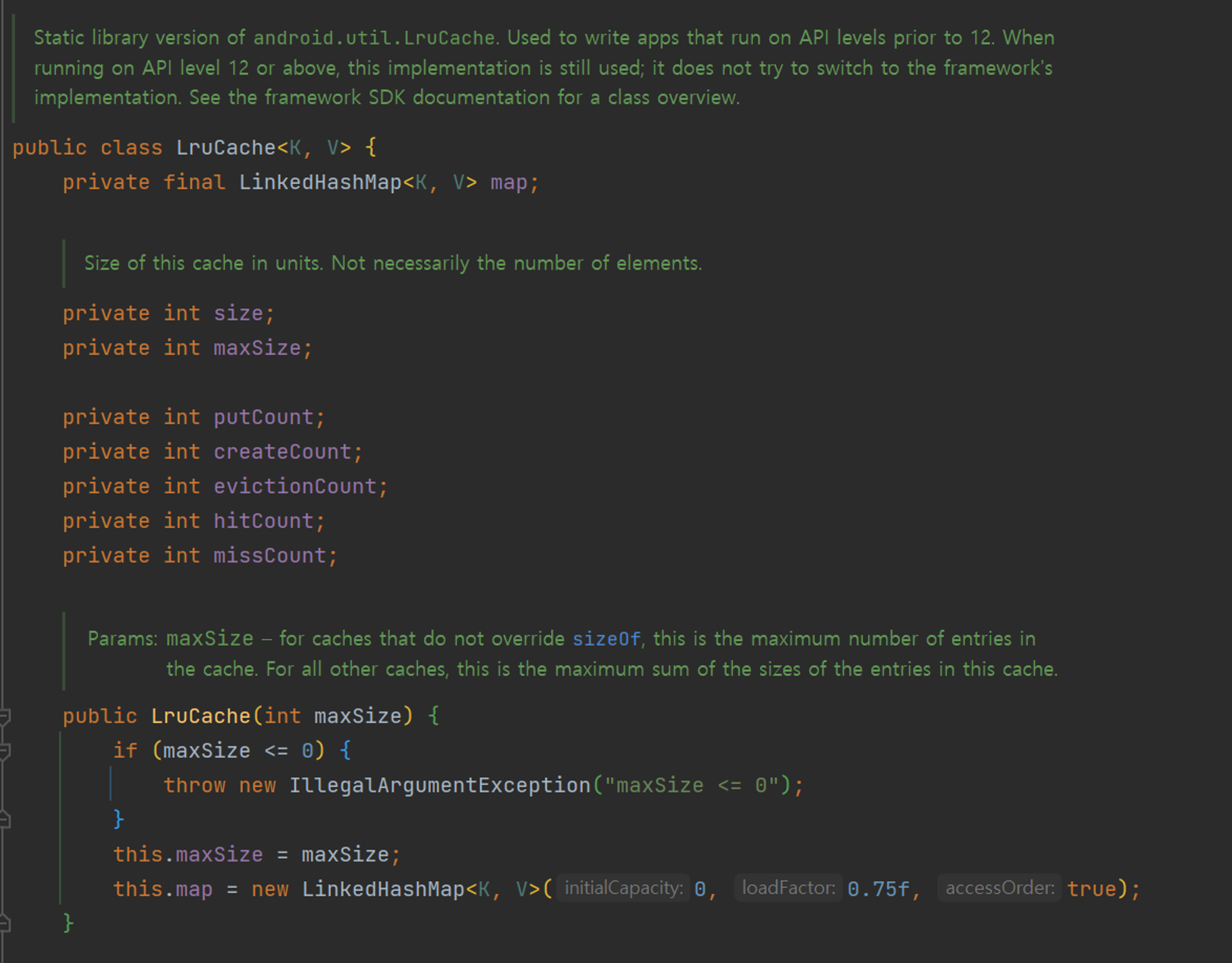
결론적으로 Coil의 핵심적인 특징 중 하나는 메모리 캐시를 통해 이미지를 저장하고, LRU (Least Recently Used) 캐시 전략을 사용한다는 점입니다.
실제로 성능을 향상시키기 위해 maxSize나 maxSizePercent 값을 조절하여 메모리 캐시 크기를 늘려봐야겠다라고 생각했습니다.
또한, 디스크 캐시도 확인해 보았는데, 이 또한 메모리 캐시와 비슷하게 LRU 캐시 전략을 채택하고 있습니다. 그러므로 디스크 캐시의 구체적인 설명은 생략하겠습니다.
정리하자면 Coil을 사용할 때의 주요 데이터 처리 흐름은
- 이미지 로딩 요청이 들어올 때, Coil은 먼저 메모리 캐시를 확인합니다.
- 만약 메모리 캐시에서 해당 이미지를 찾을 수 없다면, 다음으로 디스크 캐시를 확인합니다.
- 디스크 캐시에도 해당 이미지가 존재하지 않는 경우, 마지막으로 해당 URL을 통해 실제로 이미지를 다운로드합니다.
이러한 캐시 전략은 반복적인 이미지 요청에서 불필요한 다운로드를 방지하고 성능을 향상시키기 위한 것. 그러나 캐시 미스가 발생하면 네트워크 다운로드와 같은 상대적으로 높은 오버헤드가 발생합니다. 따라서 이러한 오버헤드를 최소화하기 위해 캐시 크기를 조절하는 방법을 고려하였습니다.
lazy 컴포넌트들은 스크롤 시 아이템의 재사용(recycling)을 위해 리컴포지션을 수행 하는데 이때 메모리 캐시 히트가 발생해서 이미지를 빠르게 불러올 수 있다면, 스크롤 성능 향상에 도움이 될 것이라는 생각으로 접근하였습니다.
그러나, 메모리 캐시의 크기를 너무 크게 설정하면 메모리 부족(OOM, Out of Memory) 문제가 발생할 위험이 있습니다. 특히, 안드로이드는 Swap Space가 없기 때문에 메모리가 부족해지면 OOM Killer에 의해 앱이 강제 종료될 수 있습니다.
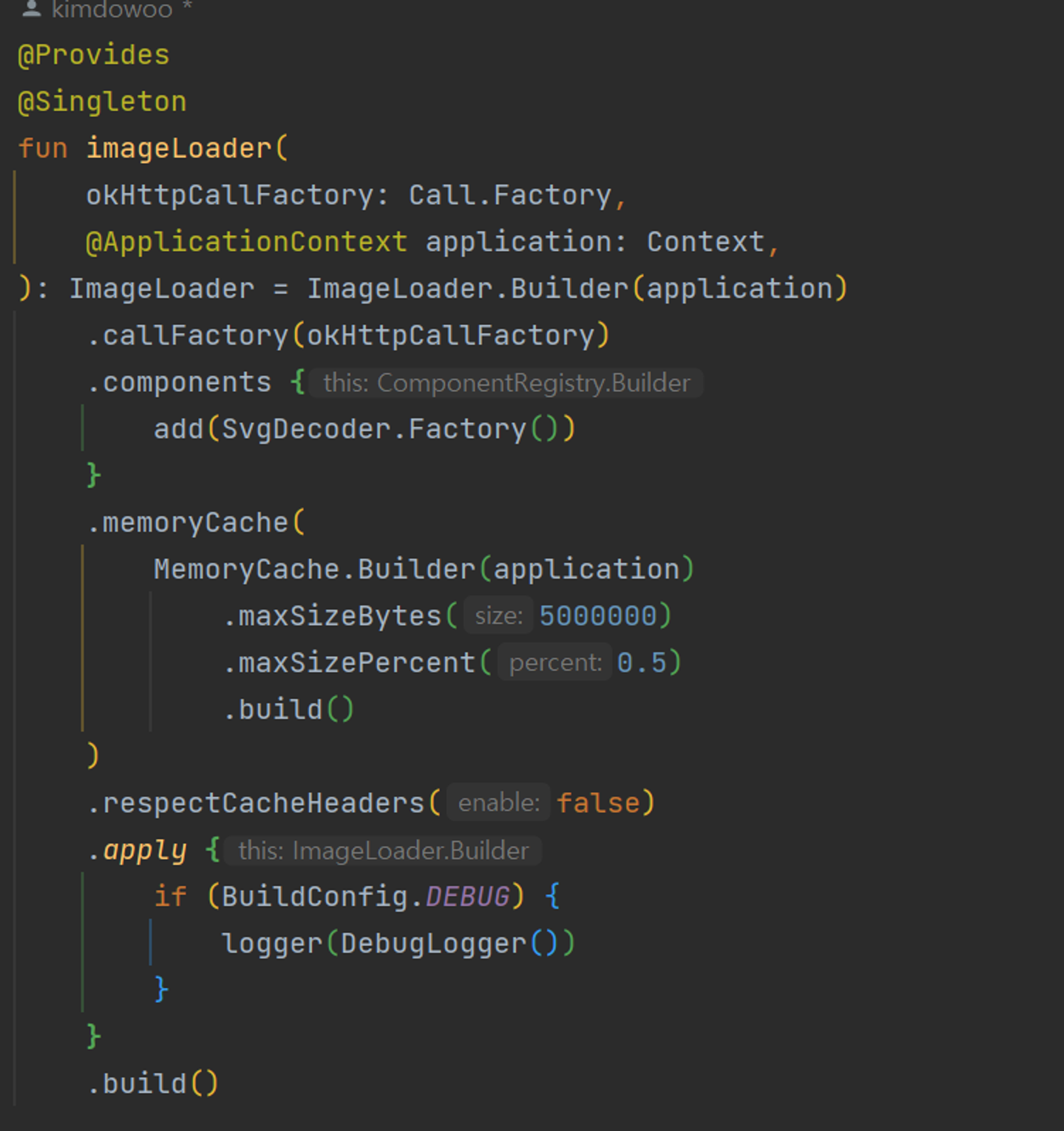
ImageLoader의 설정을 조정하면서 memoryCache의 용량을 늘려가며 테스트를 진행해보았습니다.
그러나, 캐시 용량을 크게 증가 시킨 후에도 불구하고 실제 사용자 경험에 뚜렷한 차이를 느끼기 어려웠습니다.
Coil은 이미 앱의 사용 가능한 힙 크기에 기반하여 캐시 용량을 적절히 조정하는 최적화 알고리즘을 내장하고 있다고 합니다. 이로 인해, 특별한 상황이 아닌 경우, 이러한 사용자 정의 설정이 크게 효과가 없다고 판단하고 넘어갔습니다.
결론적으로, Coil의 기본 캐시 설정이 이미 꽤 최적화되어 있어 추가적인 조정 없이도 훌륭한 성능을 제공한다는 결론을 내렸습니다.
4. 네트워크 문제
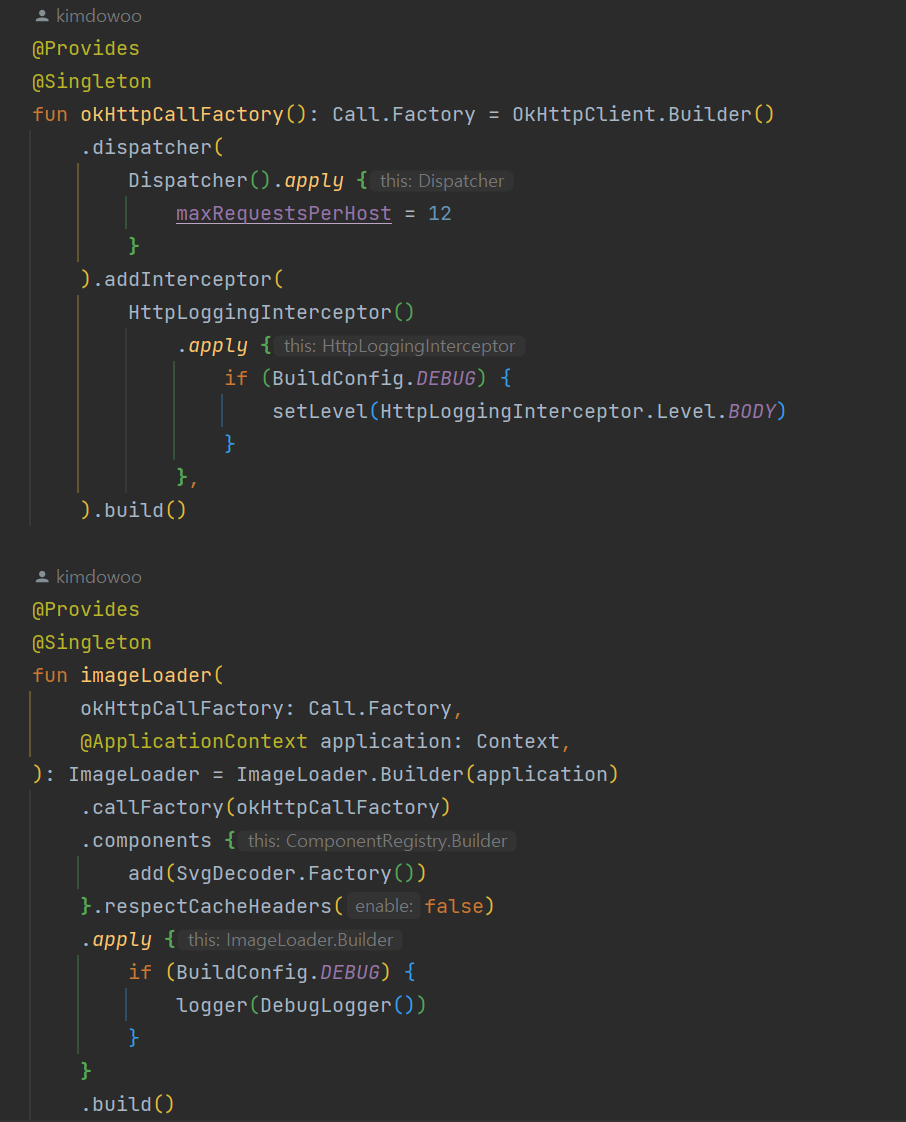
사실 이때도 버벅임이 네트워크 문제라고 생각이 되진 않지만 이때는 할 수 있는 것들을 다 해보려고 했다. url을 통해 네트워크에 접근하는 성능 부분에서 개선을 하고자 ImageLoader에서 사용하는 OkhttpClient를 생성할 때 세부 속성값을 변경해보았다.
okhttpClient 내부 변수들은 굉장히 많은데
이 부분에서 성능 개선에 도움이 될 부분들만 골라보았다.
- dispatcher: 동시에 처리되는 네트워크 요청의 수를 조절하면 성능에 영향을 줄 수 있다. 디스패처를 통해
maxRequests나maxRequestsPerHost를 조정하면 될 것 같다.
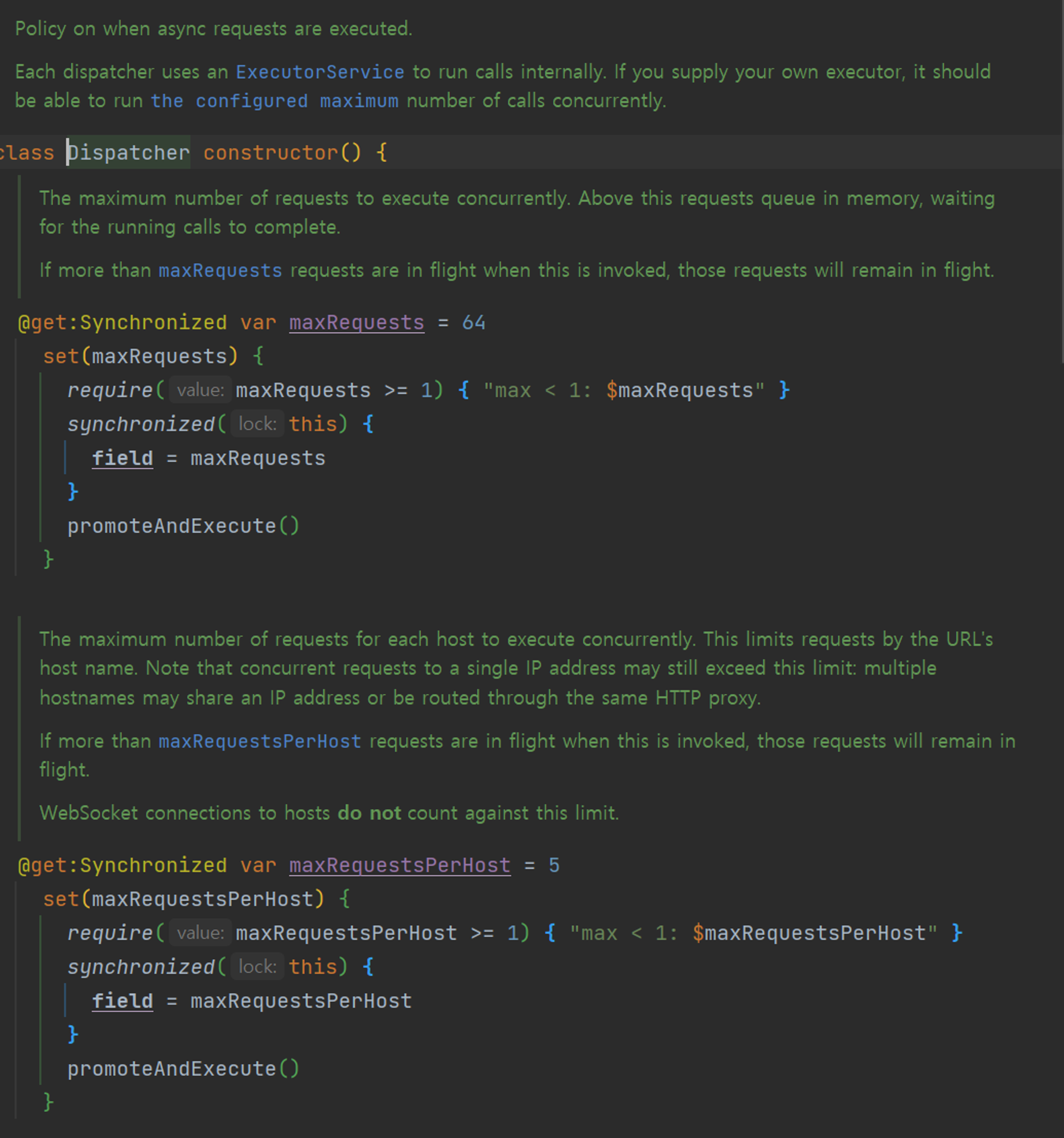
maxRequests:
- 이 변수는 동시에 실행될 수 있는 최대 요청 수를 의미
- 만약 동시에 실행 중인 요청의 수가
maxRequests값을 초과한다면, 초과하는 요청들은 메모리에 큐에 저장됩니다. 실행 중인 요청이 완료되면 큐에서 대기 중인 요청이 실행
즉, maxRequests 값보다 많은 요청이 동시에 들어올 경우, 대기 시간이 발생하게 됩니다. maxRequests 값을 높이면 동시 처리량이 증가하므로 성능 향상을 기대할 수 있지만, 반대로 너무 큰 값으로 설정하면 앱의 리소스 사용량이 급증하여 네트워크 사용량 급증, 메모리 오버플로우, 배터리 소모 증가 등의 부작용이 발생할 수 있어서 조심해야한다.
maxRequestsPerHost:
- 이 변수는 특정 호스트에 대해 동시에 실행될 수 있는 최대 요청 수를 정의
- 특정 API 서버에 동시에 여러 요청을 보낼 때 이 값을 초과하면 초과하는 요청들은 대기 상태로 전환한다.
마찬가지로 설정한 값보다 많은 요청을 특정 호스트에 보내면 대기 시간이 발생한다.
물론 이 값들을 증가시키면 동시 처리 능력이 상승하지만, 그만큼 서버 부하나 앱의 리소스 사용량도 증가할 수 있다. 따라서 무작정 높이기보다는 최적의 값에 도달하기 위한 테스트가 필요하겠다.
기본 값은 5이다.
해당 앱은 단일 호스트 서버에 주로 요청을 보내므로 maxRequestsPerHost 만 올리면 되겠다 생각했는데 그냥 둘 다 올려보았다.
LazyVerticalGrid를 사용하면 한 화면에 최대 6개의 이미지가 동시에 로드된다. 또한 LazyVerticalGrid의 특성상 인접한 영역의 이미지도 미리 로드되므로 이를 고려하여 maxRequestsPerHost값을 12로 설정하였다.
프로파일링을 진행하지 않고, 수동으로 앱을 실행하여 육안으로 테스트했다. 버벅임은 여전히 해결되지 않았지만, maxRequestsPerHost 값의 조정으로 이미지 로딩 속도는 향상된 것 같았다. 따라서 maxRequestsPerHost 설정값은 그대로 유지하기로 결정했다.
- connectionPool : 커넥션 풀은 재사용 가능한 TCP 연결을 관리하여 연결의 재사용을 통해 성능 향상을 가져온다. 너무 많은 연결이 재사용되면 메모리 사용량이 증가할 수 있으므로 적절한 값으로 설정하는 것이 중요
이 부분은 난 단일 백엔드 서버를 이용하므로 커넥션의 개수 증가가 딱히 필요없다고 판단하였다.
기본값으로 5개 커넥션과 연결을 5분 동안 유지하므로 충분하다고 판단하였다.
추가적으로 protocol은 이미 Http/2를 최우선으로 사용하려고 시도하기 때문에 이 부분은 넘어갔다.

5. Compose
버벅임에 별 성과가 없자 다시 첫 단계부터 살펴보았다.
사실 UI 코드를 작성할 때 이미 최적화 부분에 대해서 충분히 고민하면서 작성하였기에 이 부분은 초기에 고려하지 않았다. 하지만 다시 보았다.
Compose에서 성능 개선에 관련하여 공식 문서를 찾아보았다.

Composable 함수는 아래와 같은 이유들로 리컴포지션(Recomposition)이 일어날 수 있다:
- 상태(State) 변화: Composable 내에서 사용되는 상태나 데이터가 변경되었을 때.
- 부모 컴포저블의 리컴포지션: 부모 컴포저블이 리컴포지션되면 그 하위의 컴포저블들도 재구성될 수 있다.
이 때 Composable 함수 내에서 복잡한 계산이나 데이터 처리가 수행된다면 해당 함수가 리컴포지션이 일어날 때마다 그 계산도 반복이 된다.
이 과정에서 성능 저하가 발생할 수 있다.
따라서 공식문서에서는 ViewModel이나 다른 로직 계층에서 데이터를 처리하고, 처리된 결과만 Composable 함수에 전달하여 UI를 갱신하는 방식을 사용하는 것이 좋다. 또한, remember와 같은 Composable 메모제이션 함수를 활용하여 불필요한 재계산을 최소화하라고 권장한다.
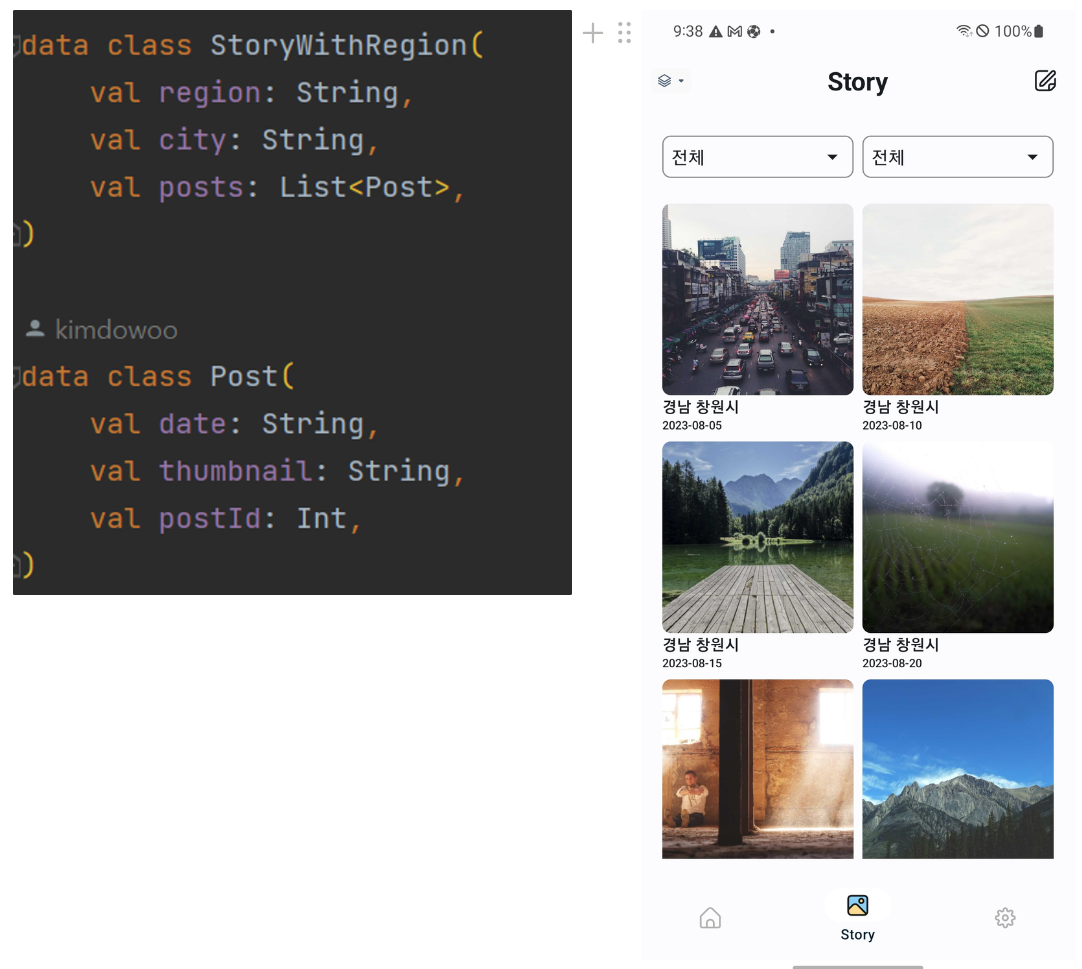
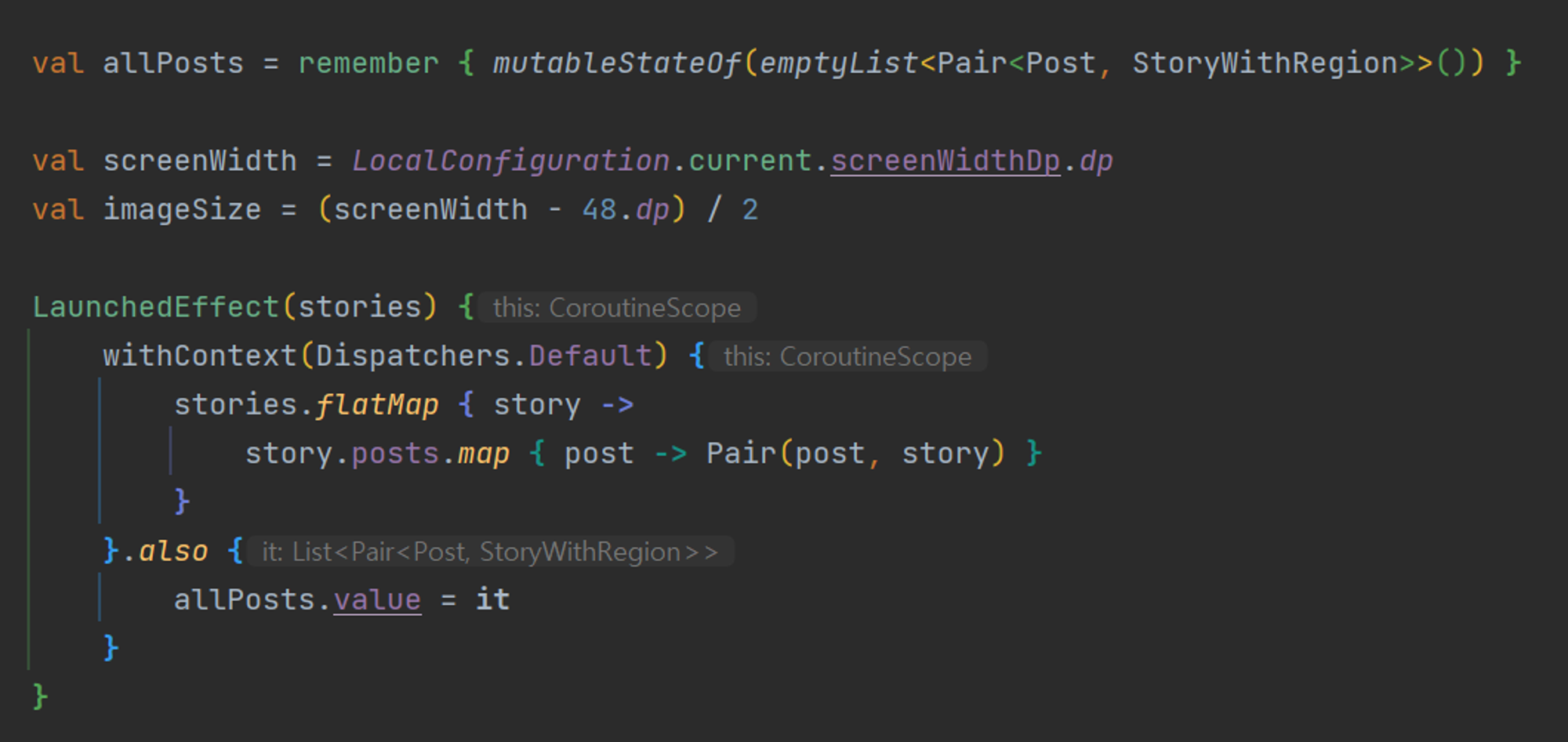
나는 백엔드에서 스토리 데이터를 가져올 때 해당하는 Region과 city에 일치하는 Post들을 List로 받는다. 이 부분에서 디자이너가 Figma에 정의한 디자인과 일치시키기 위해서는 LazyVertical을 사용하여 표시되는 각 Item이 해당 Region과 City 정보를 포함하게 구현해야 했다.
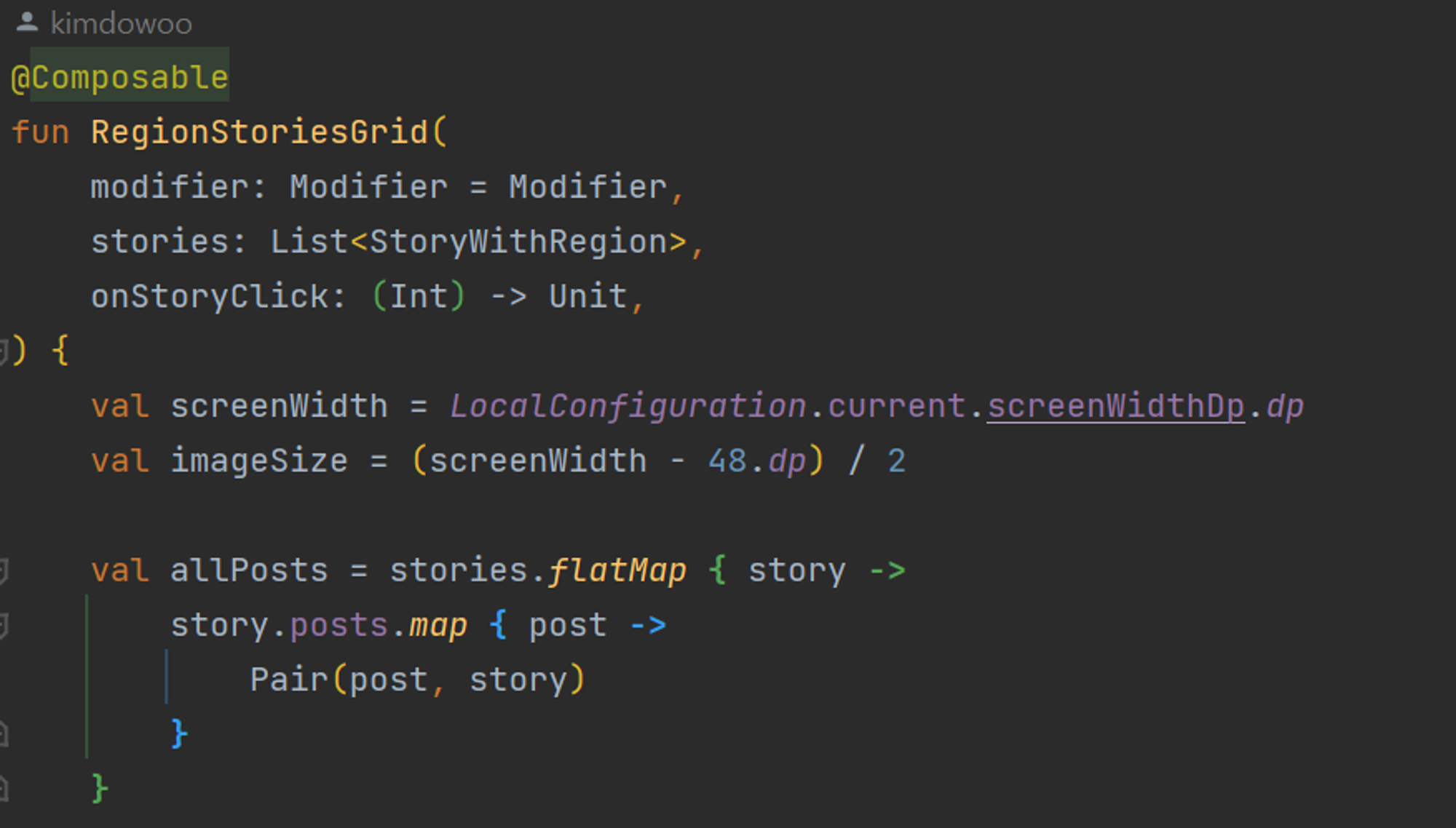
그렇기 때문에 아래 코드처럼 flatMap을 이용하여 각 스토리의 모든 Post에 대해 해당하는 Region과 City를 연결하였다.
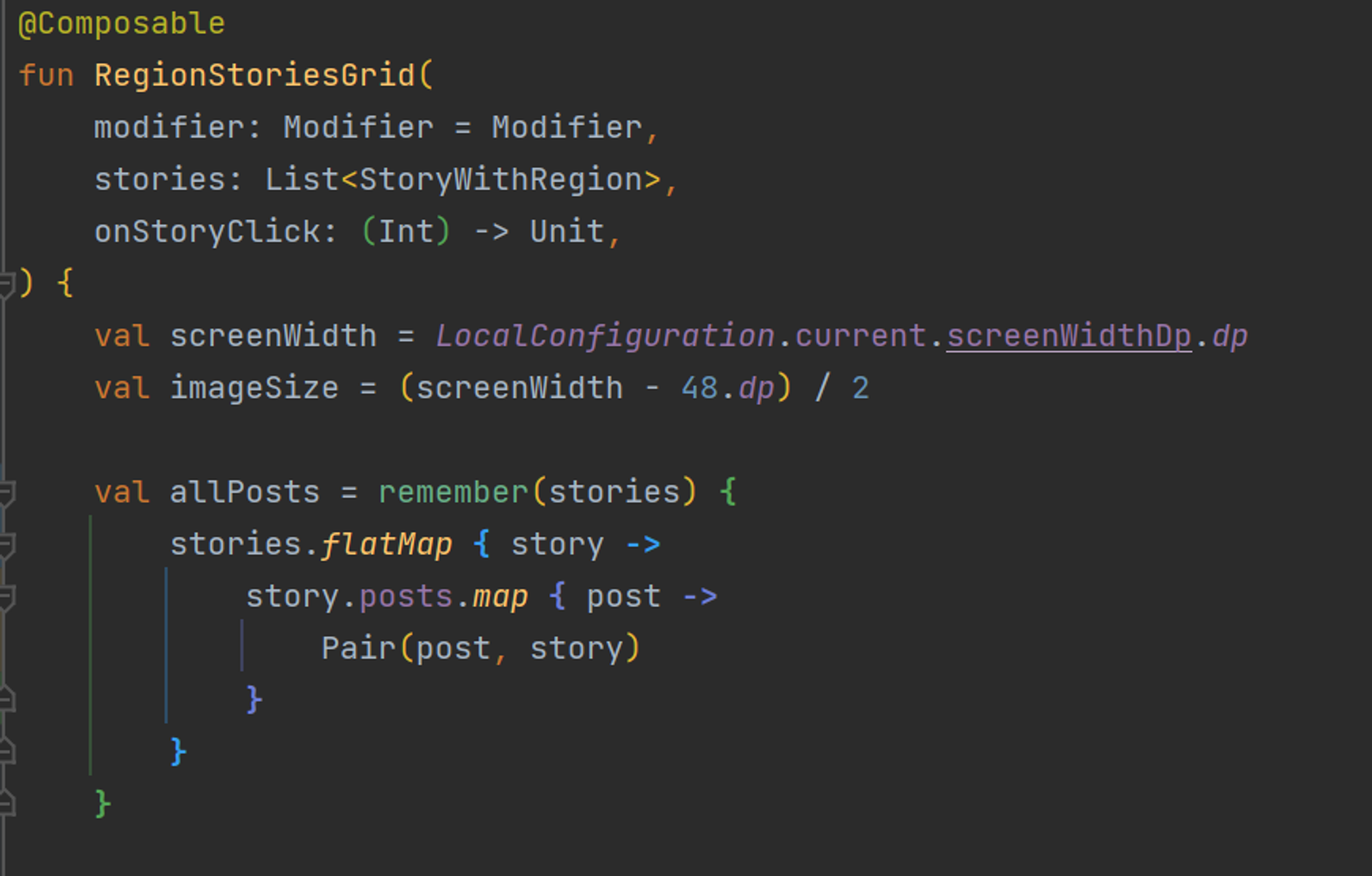
이러한 연산은 데이터 크기가 증가함에 따라 성능에 영향을 줄 수 있다고 생각했다. 따라서 불필요한 재계산을 피해야 한다. 따라서 remember를 통해 이미 계산된 결과를 재사용할 수 있게 캐싱해두는 것이 바람직하다. 이를 통해 Composable 함수가 리컴포즈 될 때마다 동일한 연산을 반복하지 않고, 결과를 빠르게 얻을 수 있다.
Calendar부분에서도 수정을 하였습니다.
또한, 날짜에 따른 Post객체를 효율적으로 검색하기 위해 Date를 키로,객체를 값으로 가지는 Map을 구현하였습니다. 이 Map의 생성도 remember를 활용하여 최적화하였습니다.

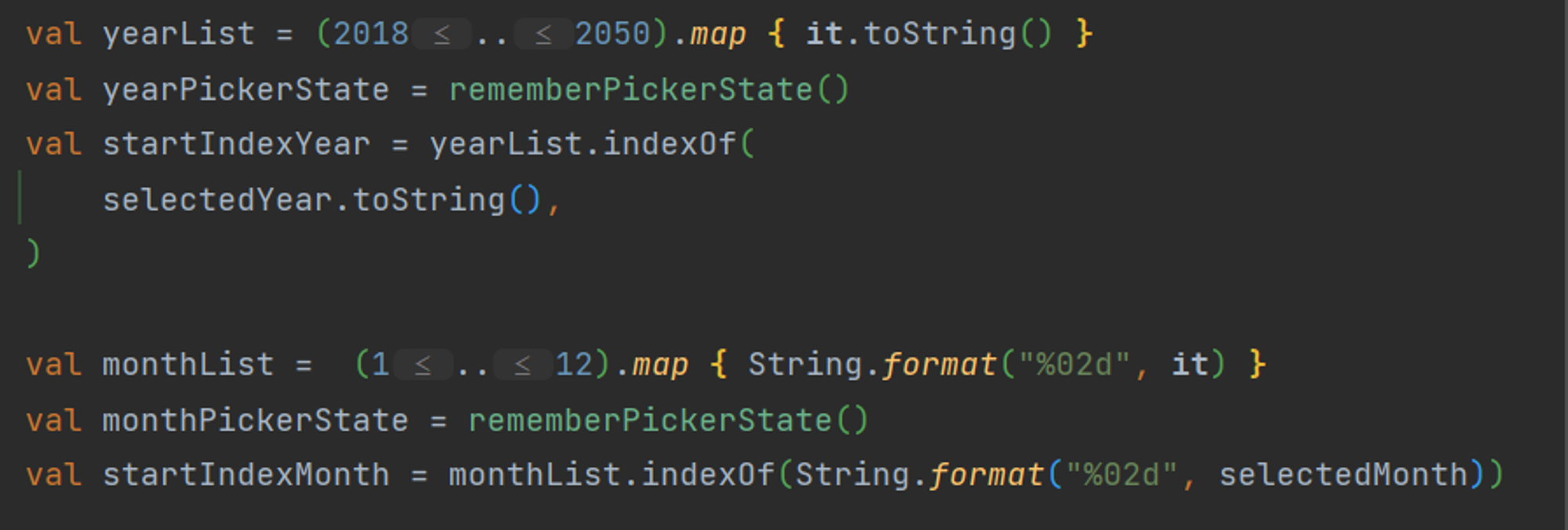
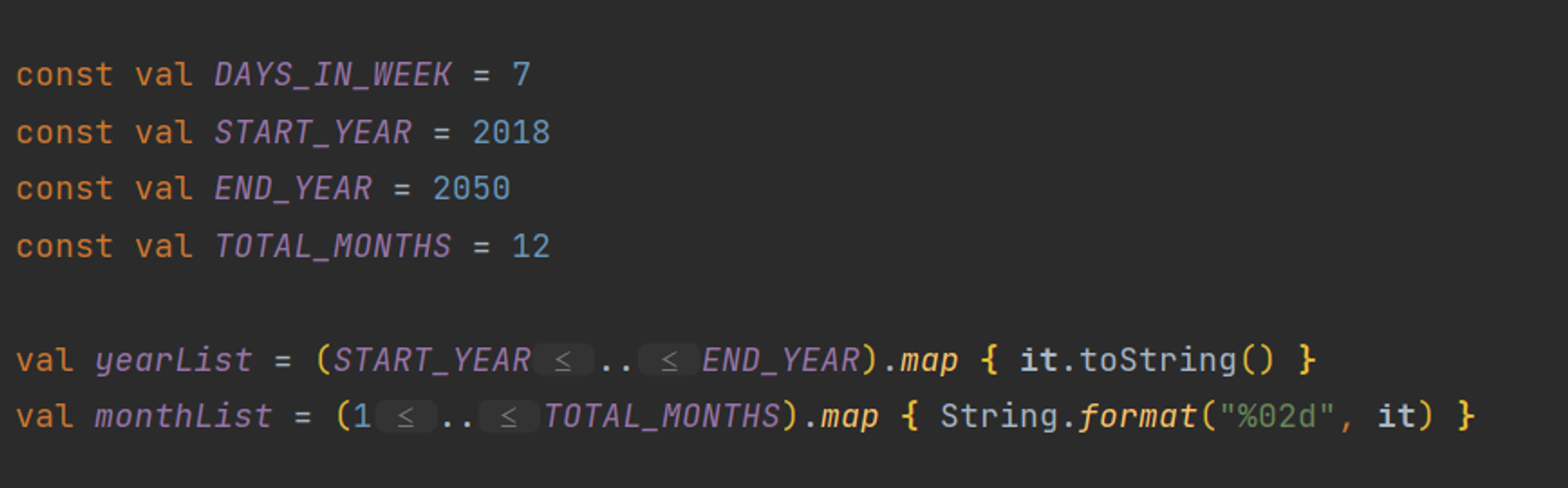
추가로 Date 선택 Dialog에서 표시되는 범위를 계산하는 부분은 반복된 계산을 최소화하기 위해 remember를 사용하여 메모제이션을 고려했습니다. 그러나, 이 부분의 데이터는 동적으로 변화하는 것이 아니므로, 함수의 외부에서 바로 선언하는 것이 더 적절하다고 판단했습니다. 결과적으로, Composable 내부에 있던 해당 로직을 외부로 이동시켰습니다.
이랬던 것을 아래처럼 변경
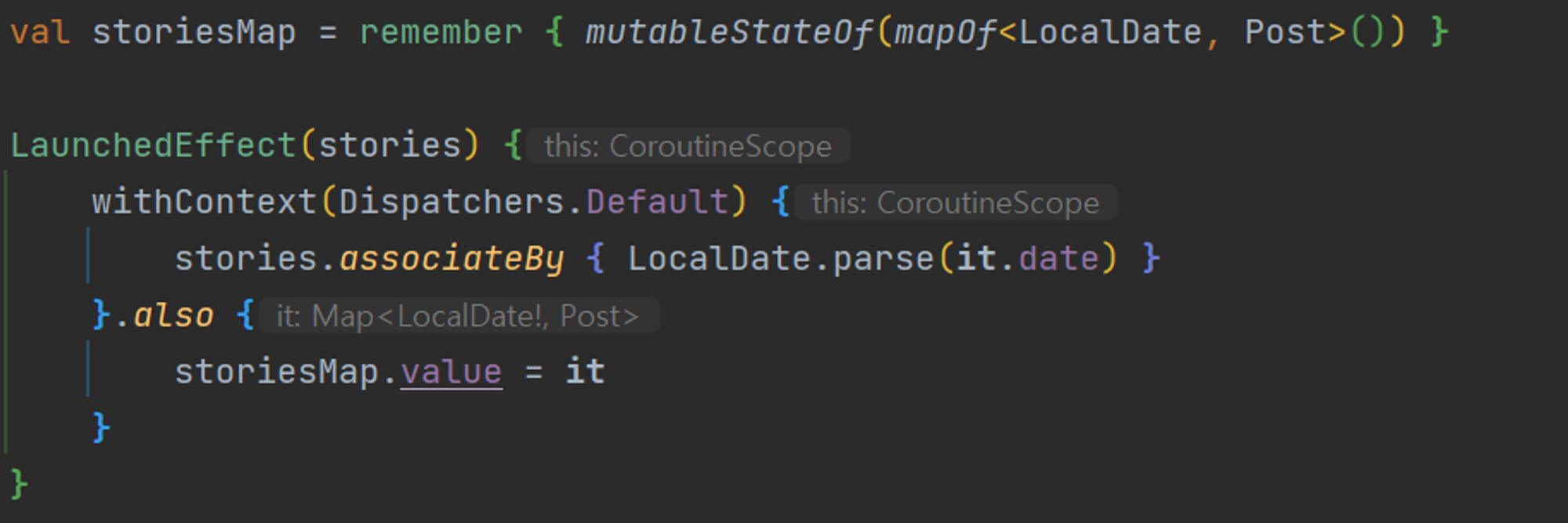
LaucnedEffect 도입
remember 안에서 일어나는 연산은 UI 스레드에서 실행된다는 사실을 알게되었다.
stories 리스트가 커지게 되면 연산 시간도 증가하게 되며, 이로 인해 UI의 버벅임 현상이 발생할 가능성이 있다. 이러한 문제를 해결하기 위해 Composable 내에서 코루틴을 사용할 수 있는 LaunchedEffect를 도입하기로 결정하였습니다.
이 연산은 CPU 집중적인 연산에 해당하므로, 이를 효율적으로 처리하기 위해 Dispatchers.Default에서 실행되도록 하였습니다.
사실 이 부분의 최적화가 버벅임 문제를 크게 해결하진 않았지만,조금 플라시보 효과인 것 같지만 조금 개선된 것 같기도하고 장기적인 관점에서 보았을 때 확실히 개선된 점이 있을거라 생각했다.
6. 출시 모드에서 빌드 및 R8 사용

공식 문서에서는 Compose의 성능 향상을 위해 릴리즈 모드에서 빌드를 하고, R8 코드 축소와 최적화를 사용하라고 권장하고 있습니다.
이걸 보고 아차 싶었다.
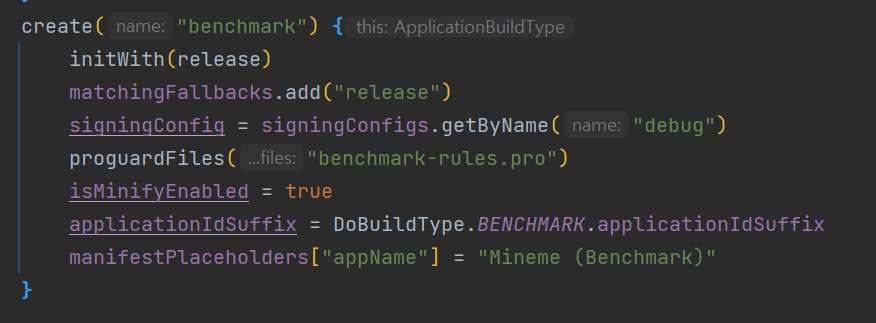
나는 릴리스와 벤치마크를 위한 빌드 변형에서 R8을 사용하여 코드를 축소하고 최적화하였다.
또한 코드의 많은 부분에서 디버그 모드 중에 로그를 출력하도록 설정하였습니다.
이러한 부분에서 디버그에서는 앱이 버벅임이 발생할 수 있다
릴리스 모드에서 앱을 실행해보니 버벅임이 신기하게 사라졌다.
결과
debug와 release 앱을 HWUI 렌더링 프로파일를 통해 GPU를 활용한 렌더링 성능을 그래프로 비교했습니다.

in debug
in release
마무리
정말 간단히 해결할 수 있는 부분이였다.
(사실 해결이라고 하기도 말하기 어려울정도)
이 과정에서 배운 점도 많아서 의미없는 시간이라고 생각하지 않는다.
이렇게 또 성장해나갔다고 생각하며 그 과정을 공유하였다.
다음 글은 여기에 적용되는 R8에 대해 설명하는 글을 작성해보겠습니다.
