코루틴
코루틴(Coroutine)은 비동기 프로그래밍을 간결하고 효율적으로 처리할 수 있게 해주는 프로그래밍 개념 중 하나입니다.
코틀린(Kotlin)에서는 코루틴을 통해 백그라운드 작업, 네트워크 통신, 데이터베이스 접근과 같은 비동기 작업을 쉽게 처리할 수 있습니다. 코루틴은 기존의 스레드 기반 프로그래밍보다 자원을 적게 사용하며, 코드를 더 읽기 쉽고 이해하기 쉬운 형태로 작성할 수 있게 돕습니다.
비동기 프로그래밍
비동기 프로그래밍이란
- 여러 작업을 동시에 수행할 수 있도록 하는 프로그램 패러다임
- Non-Blocking 방식으로 수행하면 CPU 리소스를 효율적으로 사용 가능
- 전통적으로 쓰레드 기반으로 작업을 나눠서 수행했음
간단히 말하자면 비동기 프로그래밍은 특정 코드의 실행이 완료될 때까지 기다리지 않고 다음 코드를 실행하는 프로그래밍 패러다임 즉, 작업이 끝나기를 기다리는 대신 다른 작업을 계속 처리할 수 있게 해줍니다. 이는 특히 I/O 작업, 네트워크 요청, 파일 시스템 작업 등의 경우 유용합니다.
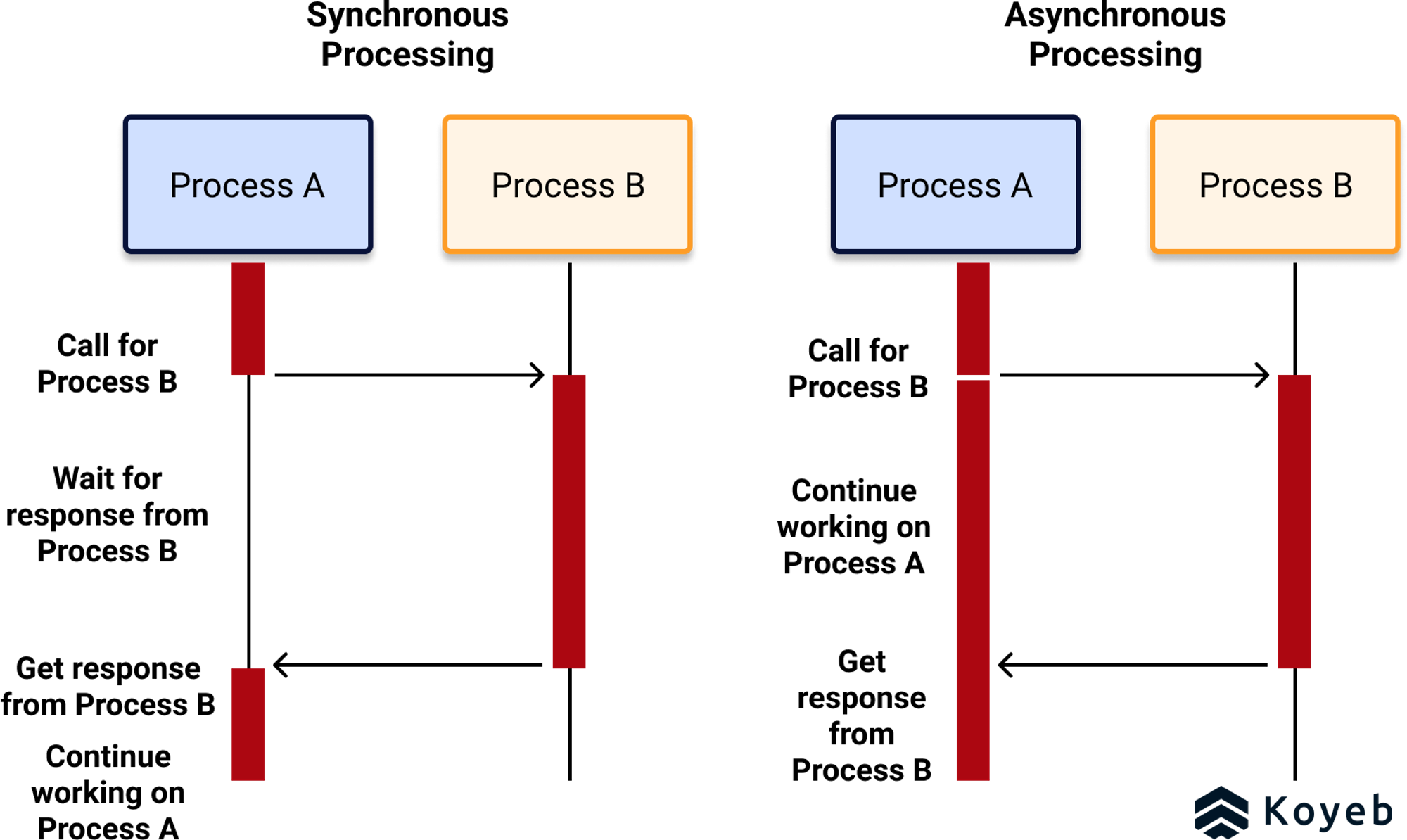
Blocking / Non-blocking 과 Sync / Async 는 다른 개념이다.
Blocking / Non-blocking 과 Sync / Async 는 '관점'을 어떻게 두느냐에 따라 다르다고 할 수 있겠다.
뒤에서 더 자세히 알아보도록 하고 일단 각각의 개념에 대해 알아보자
동기(Synchronous) vs 비동기(Asynchronous)
동기(Synchronous): 동기 방식에서는 작업을 순차적으로 실행
하나의 작업이 완료된 후 다음 작업이 시작됩니다. 이는 작업의 완료를 기다리며, 해당 작업이 끝나야만 다음 작업으로 넘어갈 수 있음을 의미합니다. 동기 방식은 코드의 실행 순서가 예측 가능하고 이해하기 쉽지만, 작업 처리 중 시스템의 자원을 효율적으로 사용하지 못할 수 있습니다.
비동기(Asynchronous): 비동기 방식에서는 작업의 완료를 기다리지 않고 다음 작업을 바로 시작할 수 있습니다. 비동기 작업을 요청하고, 그 작업이 진행되는 동안 다른 작업을 수행할 수 있어 자원을 보다 효율적으로 사용할 수 있습니다. 비동기 방식은 동시에 여러 작업을 처리할 수 있지만, 작업의 완료 순서를 관리하고 결과를 동기화하는 것이 복잡할 수 있습니다.
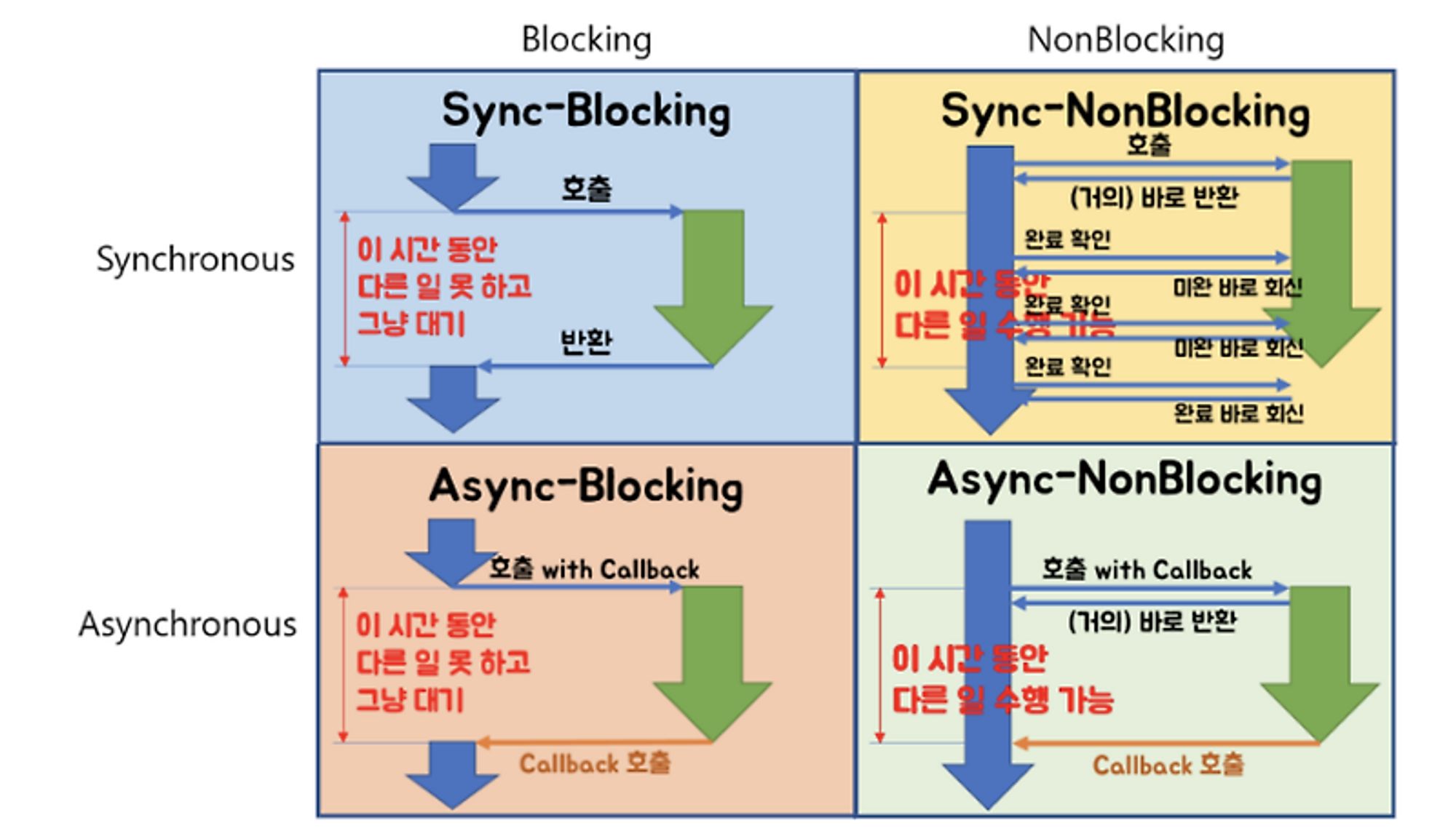
블로킹(Blocking) vs 논블로킹(Non-Blocking)
- 블로킹(Blocking): 블로킹 방식에서는 호출된 함수가 작업을 완료할 때까지 호출한 함수의 실행을 중단(블로킹)시킵니다. 즉, 블로킹 호출은 결과가 반환될 때까지 현재 스레드의 실행을 멈춥니다. 이 방식은 동기 방식의 작업 처리와 유사한 특성을 가지고 있습니다.
- 논블로킹(Non-Blocking): 논블로킹 방식에서는 호출된 함수가 바로 결과를 반환하거나 작업의 완료 여부와 관계없이 즉시 제어를 호출한 함수에 반환합니다. 이는 함수 호출이 즉시 반환되어 호출한 스레드가 다른 작업을 계속 수행할 수 있음을 의미합니다. 논블로킹 호출은 비동기 방식의 작업 처리에 주로 사용됩니다.
동기와 블로킹, 비동기와 논블로킹이 유사한 개념 같은데 어떤 관점으로 이 개념을 구분할 수 있을까
Blocking / Non-blocking 은 호출된 함수가 호출한 함수에게 제어권을 바로 주느냐 안주느냐,
Sync / Async 는 호출된 함수의 종료를 호출한 함수가 처리하느냐, 호출된 함수가 처리하느냐의 차이다.
이해가 쉽지가 않다.
아래 영상에서 잘 설명해주셔서 예시를 보는게 이해가 빠를 것 같다.
https://www.youtube.com/watch?v=oEIoqGd-Sns
아래 그림 정도의 개념만 들고 예시로 보자
동기 & 블로킹
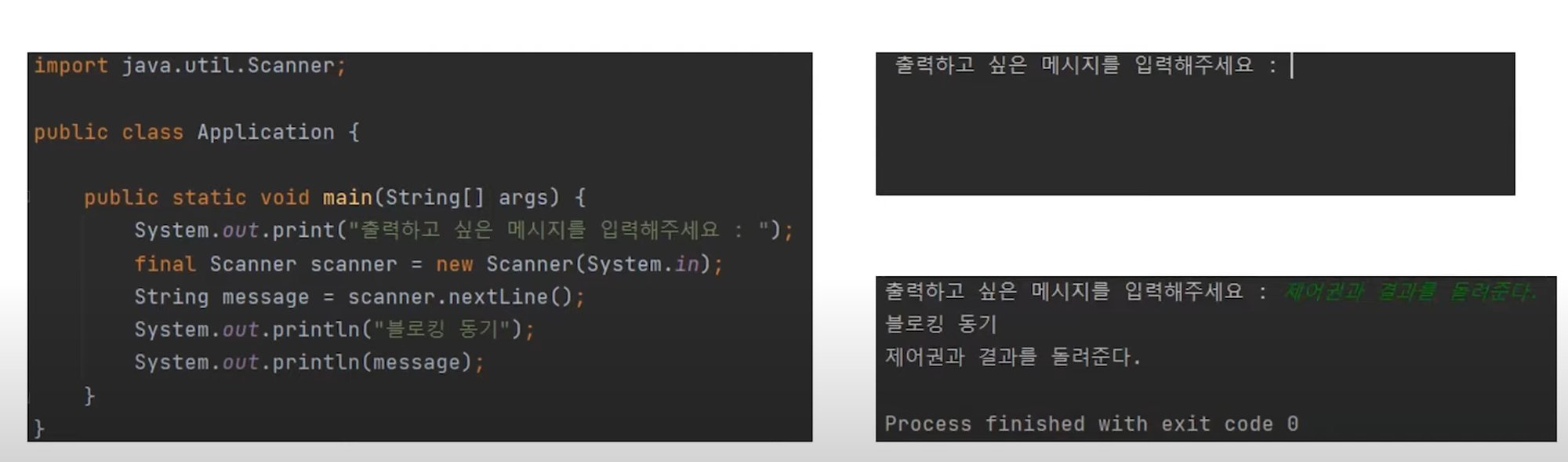
입력 요청이 일어났을 때 Blocking Sync 방식을 사용한다.
제어권이 호출된 함수로 넘어갔기 때문에 아래 내용은 실행이 되지 않는다. 일반적으로 우리가 아는 Sync의 개념일 것이다.
실제 안드로이드에서는 이런 입출력이 MainThread에서 일어나면 안되므로 Android에서는 동기 & 블로킹이 일어나는 일은 정상적인 앱에서는 없을 것으로 생각이된다.
동기 & 논블로킹
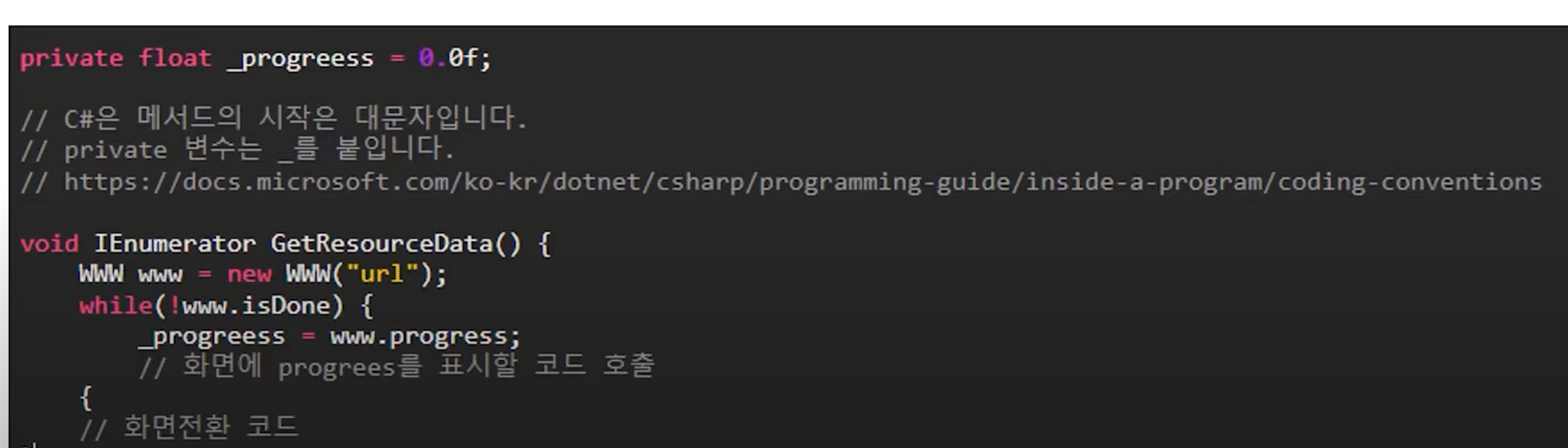
게임에서 Map을 이동하는 예시로 들고 있습니다.
게임에서 새로운 Map을 로드할 때 진행 프로그래스를 표시하는데 이때 작업이 완료되었는지 주기적으로 확인하는게 동기 & 논블로킹의 예시 입니다.
호출자는 서버의 호출된 함수의 최신 상태를 주기적으로 알 수 있습니다.
하지만 단점으로 계속 확인하는 과정에서 오버헤드가 발생하고, 확인 간격 사이에 변경 상황이 즉시 감지되지 않는다는 단점들이 있습니다.
비동기 & 블로킹
해당 조합은 동기 & 블로킹과 동일하게 동작되는 것 처럼 느껴집니다.
보통 이 조합의 경우 비동기 & 논블로킹 으로 하려다가 개발자의 실수로 이와 같이 동작하는 경우가 있다고 합니다. 일반적인 경우가 아니라고 합니다.
비동기 & 논블로킹
안드로이드에서 가장 흔히 사용되는 패턴입니다
예를 들어 Retrofit을 사용하여 네트워크 요청을 처리하는 경우가 있습니다.
import androidx.compose.runtime.*
import androidx.compose.material.*
import androidx.compose.ui.platform.LocalContext
import androidx.lifecycle.viewmodel.compose.viewModel
import kotlinx.coroutines.launch
@Composable
fun UserProfile(userId: String) {
val viewModel: UserProfileViewModel = viewModel()
val coroutineScope = rememberCoroutineScope()
val userProfileState = viewModel.userProfile.collectAsState()
LaunchedEffect(key1 = userId) {
coroutineScope.launch {
viewModel.loadUserProfile(userId)
}
}
/**
기타 UI
**/
when (val state = userProfileState.value) {
is UserProfileState.Loading -> CircularProgressIndicator()
is UserProfileState.Success -> Text("User Name: ${state.userProfile.name}")
is UserProfileState.Error -> Text("Error: ${state.error}")
}
}
해당 부분에서 loadUserProfile 을 통해 유저의 프로필 정보를 요청합니다.
이는 NonBlocking으로 바로 요청만하고 기타 ui작업을 이어서 실행합니다.
또한 함수의 종료 또한 호출된 함수에서 관리하지 않고 알아서 종료하고 데이터를 ViewModel 내부 데이터에 저장합니다.
이 방식은 비동기 작업을 논블로킹으로 처리하며, 작업의 결과에 따라 UI를 동적으로 업데이트합니다.
제 개인적으로 실제 안드로이드에서는 이러한 것들을 모두 자세히 알 필요는 없다고 생각합니다.
그냥 이 정도 개념있구나 인지하고 자신의 의도대로 올바르게 동작이 되고 있는지 그것을 판단할 때 도움 되는 개념정도라고 생각합니다.
쓰레드 방식 비동기 프로그래밍
기존에는 쓰레드 방식을 통해 비동기 프로그래밍을 주로 하였습니다.

하지만 어떠한 이유로 인해 코루틴이 나오게 되었고 많은 사람들이 사용하고 있는걸까요?
스레드 방식의 단점과 코루틴
1. 스레드 생성과 컨텍스트 스위칭 비용
스레드는 운영 체제에 의해 관리되는 독립적인 실행 단위입니다. 각 스레드에는 고유한 호출 스택이 할당되며, 이는 스레드가 함수를 호출하고 지역 변수를 저장하는 데 사용됩니다. 여러 스레드가 동시에 실행될 때, 운영 체제는 스레드 간의 컨텍스트 스위칭을 수행해야 합니다. 이는 현재 실행 중인 스레드의 상태를 저장하고, 다음에 실행할 스레드의 상태를 불러오는 과정을 말합니다. 컨텍스트 스위칭은 상당한 CPU 자원을 소모하는 작업으로, 특히 많은 수의 스레드가 동시에 실행될 때 이 비용은 더욱 증가합니다.
반면, 코루틴은 기본적으로 단일 스레드 내에서 실행됩니다. 코루틴은 작업 간 전환 시 운영 체제 레벨의 컨텍스트 스위칭을 필요로 하지 않습니다. 대신 코루틴 간 전환은 코루틴 객체의 상태 변경으로 처리됩니다. 코루틴이 일시 중단되면, 그 상태(예: 지역 변수, 실행 지점)는 힙 메모리에 저장되고, 이후 재개될 때 이 상태 정보를 바탕으로 실행이 계속됩니다. 이 과정에서 발생하는 오버헤드는 운영 체제가 관리하는 스레드의 컨텍스트 스위칭에 비해 훨씬 작습니다.
요약하면, 스레드는 OS의 커널에 의해 관리되며 컨텍스트 스위칭으로 인한 비용이 발생하는 반면, 코루틴은 하나의 스레드에서 작업 객체의 상태 전환만으로 동시성을 처리하여 자원 사용을 최소화하는 효율적인 방법을 제공합니다
작업의 상태 종류
1. 실행 중(Active): 코루틴이 실행 중이며 작업을 수행하고 있는 상태입니다.
2. 일시 중단(Suspended): 코루틴이 I/O 작업이나 네트워크 호출 등을 기다리며 실행을 일시적으로 멈춘 상태입니다. 이 상태에서 코루틴은 CPU 자원을 소비하지 않습니다.
3. 완료(Completed): 코루틴의 작업이 완료된 상태입니다.
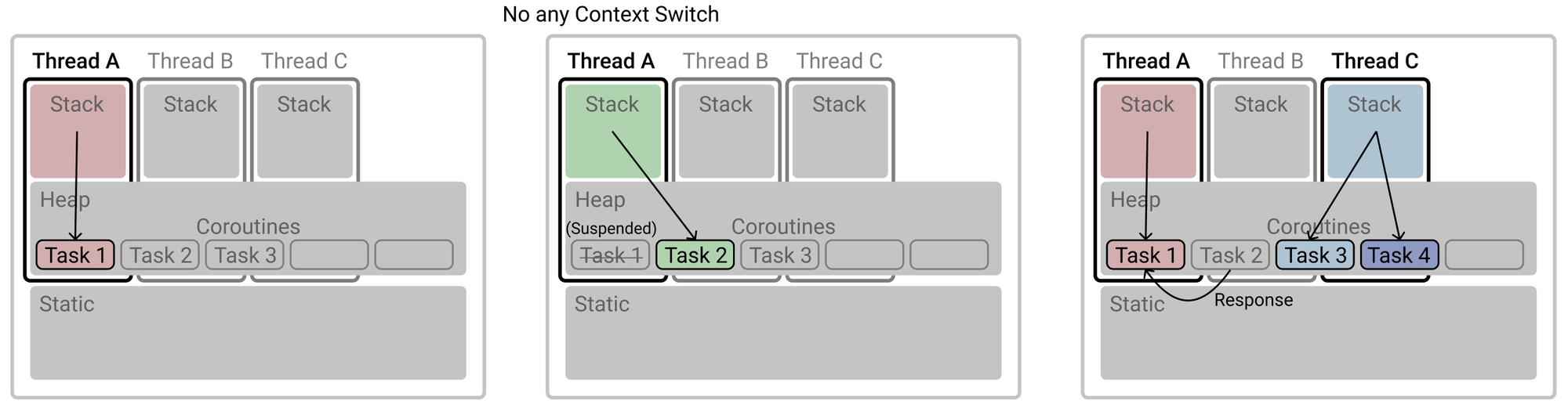
이게 Coroutine을 경량 쓰레드(Lightweight Thread)라고 부르는 이유다.
2. 자원 효율성
코루틴이 CPU 자원을 보다 효율적으로 사용할 수 있는 핵심 이유는 스레드를 사용하는 전통적인 방식에 비해 더 작은 작업 단위로 실행을 세분화할 수 있기 때문입니다. 스레드가 대기 상태에 들어가면, 그 스레드는 실행 가능한 다른 작업이 있음에도 불구하고 CPU 자원을 활용하지 못하고 메모리 자원을 소모하면서 대기합니다.
반면 코루틴은 단일 스레드 내에서 여러 '경량' 작업(코루틴)을 수행할 수 있게 합니다. 코루틴은 서로 협력적으로 작업을 수행하며, 하나의 코루틴이 I/O 작업이나 다른 대기 조건으로 인해 일시 중지되어도, 그 스레드는 멈추지 않고 다른 코루틴의 작업을 계속 처리할 수 있습니다.
그 외에도 코드적인 부분에서도 여러 장점이 있다고 하는데 저는 스레드를 많이 사용해보지 않아서 딱히 와닿지 않네요.
코루틴 사용해보기
fun main() = runBlocking {
launch {
wait1000ms()
println("World!")
}
println("Hello")
}
suspend fun wait1000ms() {
delay(1000L)
}
이 코드는 runBlocking 코루틴 빌더를 사용하여 메인 스레드를 블로킹하고, 그 내부에서 launch 코루틴 빌더를 통해 새로운 코루틴을 시작합니다.
launch로 시작된 코루틴 내에서 wait1000ms 함수는 delay 함수를 호출하여 코루틴을 1초 동안 중단시킵니다.
이때, delay 함수는 중단 함수(suspending function)이기 때문에 코루틴의 실행을 멈추게 하지만, 스레드를 차단하지는 않습니다.
따라서, println("Hello") 구문은 launch 코루틴 블록이 완료되기를 기다리지 않고 즉시 실행되어 "Hello"를 출력합니다. 1초 후, wait1000ms 함수 내의 delay가 완료되고, println("World!")가 실행되어 "World!"를 출력합니다.
코루틴 빌더
코루틴 빌더는 코루틴을 시작하기 위한 함수입니다. 코루틴 스코프 내에서 코루틴을 생성하고 시작하는 역할을 합니다.
코루틴 빌더에는 launch와 async가 있습니다.
launch: 반환 값이 없는 작업을 비동기적으로 실행할 때 사용됩니다. launch는 Job 객체**를 반환하며, 이는 코루틴의 실행을 제어할 수 있게 해줍니다.
async: 반환 값이 있는 작업을 비동기적으로 실행할 때 사용됩니다. async는 Deferred<T> 객체를 반환하며, 이는 나중에 결과 값을 가져올 수 있게 해줍니다.
val deferredResult: Deferred<Type> = GlobalScope.async {
// 비동기 작업 수행 후 결과 반환
}
val result: Type = deferredResult.await() // 결과값 기다리기
코루틴 빌더는 코루틴을 시작하기 위한 함수이고 코루틴은 빌더에 의해 시작되는 실행 흐름
코루틴 빌더 내부에는 여러 개의 코루틴이 있을 수 있습니다
즉, 코루틴은 자식 코루틴을 가질 수 있으며, 이는 코루틴 계층 구조의 중요한 부분입니다.
코루틴 스코프 내에서 시작된 코루틴은 자동으로 해당 스코프에 속한 부모 코루틴의 자식 코루틴이 됩니다.
부모 자식 관계의 동작 또한 중요한데 뒤에서 필요할 때 더 알아보겠습니다.
코루틴은 한 스레드 내에서 기본적으로 동시적
코루틴은 기본적으로 선점 x
suspend
suspend function은 코틀린 코루틴에서 비동기 코드를 간결하고 효율적으로 작성하기 위한 핵심 개념 중 하나
suspend function은 네트워크 요청, 데이터베이스 작업 등 비동기적으로 수행되어야 하는 작업을 처리하는 데 주로 사용됩니다. 함수의 실행을 일시 중지했다가, 비동기 작업의 결과가 준비되면 자동으로 재개합니다. 이 과정은 코루틴 스케줄러에 의해 관리됩니다.
suspend function을 사용함으로써 복잡한 비동기 로직도 마치 동기 코드를 작성하듯이 간결하고 이해하기 쉽게 표현할 수 있습니다.
네트워크 호출을 순차적으로 여러 번 실행해야 하는 상황을 가정해 봅시다. 코루틴을 사용하지 않고 콜백을 이용해 이를 구현한 코드는 다음과 같을 수 있습니다:
// Callback을 사용한 예시 (코루틴 사용 X)
fun fetchData(callback: (String) -> Unit) {
// 네트워크 요청을 가정한 비동기 작업
Thread {
Thread.sleep(1000) // 대기를 시뮬레이션
callback("Data fetched")
}.start()
}
fun main() {
fetchData { result1 ->
println(result1)
fetchData { result2 ->
println(result2)
fetchData { result3 ->
println(result3)
// 추가적인 네트워크 요청이 필요하다면 이런 식으로 계속됩니다.
}
}
}
}
이 코드는 네트워크 요청을 가정한 비동기 작업을 순차적으로 수행합니다. 콜백 지옥(callback hell)이라 불리는 이 패턴은 중첩이 깊어질수록 코드의 가독성과 유지보수성이 크게 떨어집니다.
import kotlinx.coroutines.*
suspend fun fetchData(): String {
delay(1000) // 네트워크 요청을 가정한 비동기 작업
return "Data fetched"
}
fun main() = runBlocking {
val result1 = fetchData() // 첫 번째 요청
println(result1)
val result2 = fetchData() // 두 번째 요청
println(result2)
val result3 = fetchData() // 세 번째 요청
println(result3)
// 추가적인 네트워크 요청을 쉽게 추가할 수 있습니다.
}
위 코드의 경우 fetchData가 순차적으로 실행됩니다.
suspend 함수를 순차적으로 호출하는 것은 비효율적입니다.
논 블로킹 실행을 통해 성능을 향상시킬 수 있으며, async와 await을 사용하여 동시에 여러 API 호출을 실행할 수 있습니다.
즉 하나의 코루틴 내에서는 동기적이기에 여러 코루틴을 만들면 됌
import kotlinx.coroutines.*
suspend fun fetchData(): String {
delay(1000) // 네트워크 요청을 가정한 비동기 작업
return "Data fetched"
}
fun main() = runBlocking {
// 병렬로 fetchData() 실행
val deferredResult1 = async { fetchData() } // 첫 번째 요청
val deferredResult2 = async { fetchData() } // 두 번째 요청
val deferredResult3 = async { fetchData() } // 세 번째 요청
// 결과 기다리기
println(deferredResult1.await())
println(deferredResult2.await())
println(deferredResult3.await())
// 추가적인 네트워크 요청도 같은 방식으로 쉽게 추가할 수 있습니다.
}

정리
- 하나의 스레드에 여러 코루틴 존재 가능하고 동시적으로 가능
- 코루틴은 스레드와 달리 비선점임 하나가 중단되거나 종료되어야 다른 하나가 실행됌
- 따라서 이러한 방식때문에 동기적 스타일로 코딩 작성할 수 있고 하나가 끝나지 않으면 다른 것 실행되지 않음
- 논 블로킹으로 하고 싶으면 코루틴 스코프 따로 만들어야함→ 이러면 동시적으로 동작하여 병렬처럼 보이게함 이 경우 협조적으로 구성되어야함
- 여러 코루틴이 존재 가능하므로 Thread Blocking 없이 다른 작업을 기다릴 수 있음, Suspend Function 혹은 Coroutine에서만 호출이 가능
Coroutine Scope
비동기 작업을 수행할 때 예제와 같이 작업들의 상관관계와 범위를 나눠서 생각을 해야함
부모 자식 관계 : 어떤 작업이 내부적으로 어떤 작업들로 이루어져 있고
작업 의존 관계 : 어떤 작업이 끝나야 그 다음 작업을 진행하는지
코루틴은 기본적으로 Coroutine Scope이라는 작업 범위를 만드는 것으로 시작
Coroutine Scope은 이름에서 유추할 수 있듯이 코루틴 작업의 범위(Scope)를 의미함
코루틴 스코프(Coroutine Scope)는 코루틴이 실행될 수 있는 컨텍스트를 정의합니다. 코루틴 스코프는 코루틴이 어떻게, 언제 실행될지를 결정하며, 코루틴의 생명 주기를 관리합니다. 코틀린에서는 다양한 코루틴 스코프를 제공하며, 각각의 사용 목적과 환경에 맞게 선택하여 사용할 수 있습니다.
코루틴 내부 많은 API 및 중단 함수는 CoroutineScope 안에서만 사용 가능하고, 밖에서는 컴파일 에러로 사용 불가
빌더들은 해당 스코프에 종속된 코루틴을 생성하며, 스코프가 취소되면 모든 하위 코루틴도 자동으로 취소
정리하면코루틴 스코프는 실행 범위를 정의하며, 코루틴의 생명주기를 관리한다 이로써 Structured concurrency(구조화된 동기성)을 제공함
Structured concurrency
구조화된 동기성(Structured Concurrency)란 코루틴과 같은 비동기 프로그래밍을 더 안전하고 이해하기 쉽게 만들기 위한 프로그래밍 패러다임
모든 비동기 작업이 명확하게 정의된 범위 내에서 실행되어야 하며, 그 범위가 종료될 때 모든 작업이 완료되거나 취소되어야 한다는 것입니다. 이로 인해 코드의 실행 흐름을 더 명확하게 파악할 수 있고, 메모리 누수 및 관련된 리소스 관리 문제를 방지할 수 있습니다.
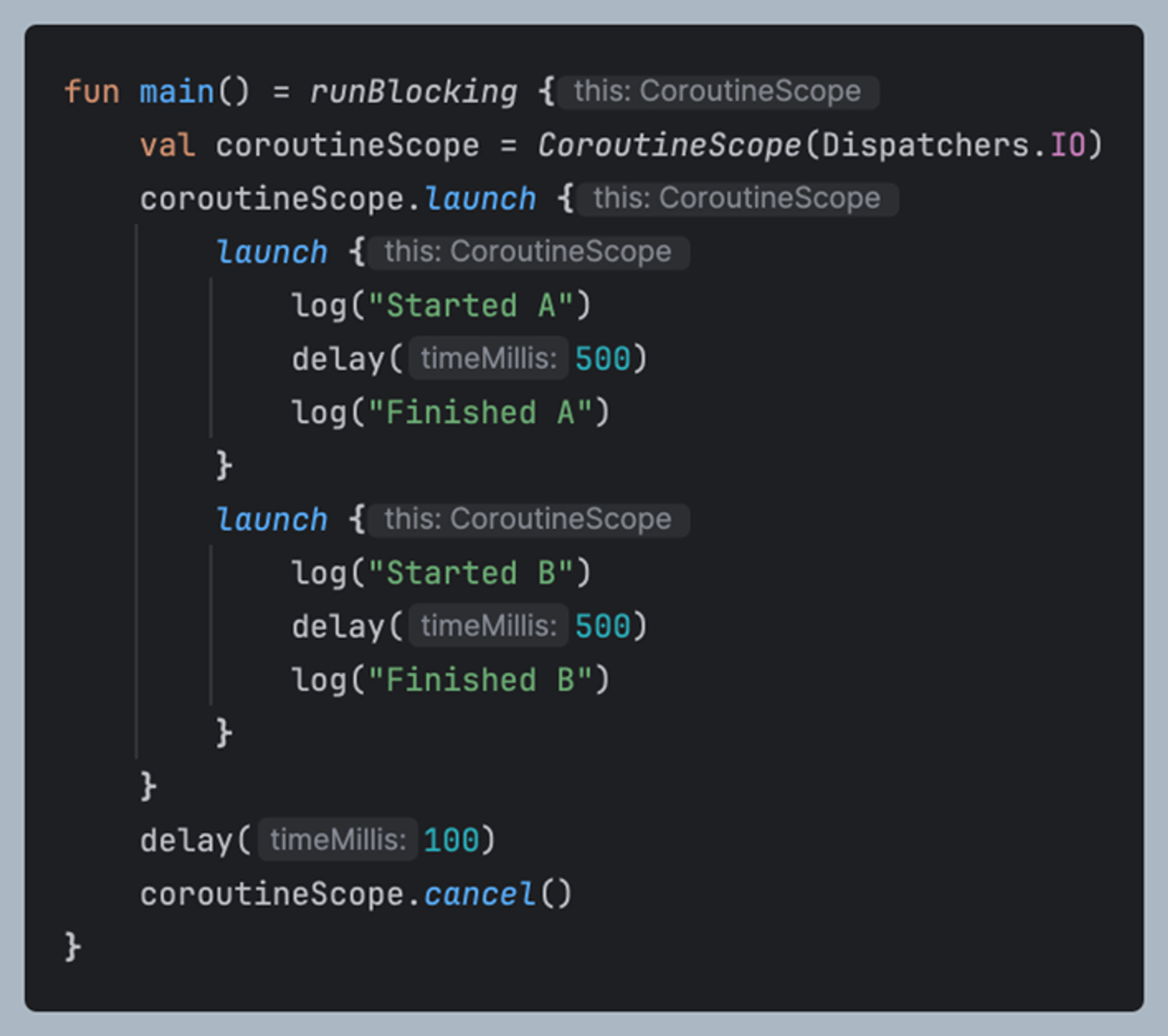

코루틴은 Scope에 바인딩 되며 부모 Scope이 종료 or 취소되면 자동으로 내부의 모든 코루틴 역시 종료 or 취소 됨
ex) ViewModel이 종료되면 viewModelScope 이 종료되고 내부에 바인딩된 모든 코루틴이 종료 됨
Coroutine Context
Coroutine Scope에 바인딩 되는 실행 환경 정보
코루틴의 이름, 디스패처, 잡 등 실행에 필요한 정보들을 보유
주요 Context : Coroutine Name, Job, Dispatcher
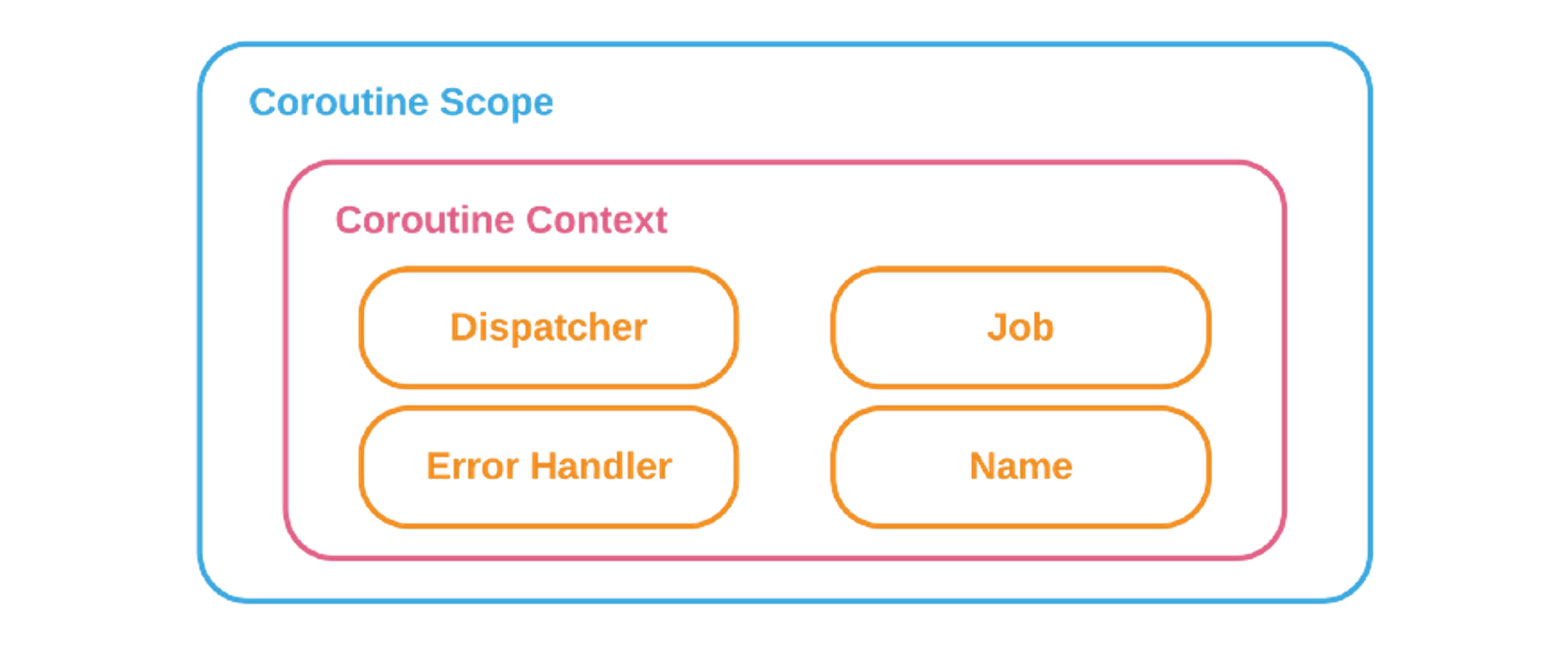
Coroutine Scope 내부에 Coroutine Context가 존재한다.
컨텍스트 정보들은 링크드 리스트 형태로 연결되어 있음
Context를 추가하고 싶을 때는 + 연산이 정의되어 있어서 Context A + Context B 이런식으로 사용 가능하다. Set과 같이 한 타입은 리스트에서 고유해야 함 ex) CoroutineName을 중복해서 추가하면 뒤에 넣은 이름이 덮어 씀
import kotlinx.coroutines.*
fun main() = runBlocking { // 이곳이 최상위 코루틴 스코프입니다.
launch {
delay(1000L)
println("코루틴 1 실행")
}
launch {
delay(500L)
println("코루틴 2 실행")
}
println("모든 코루틴 시작됨")
}
이 말은 한 스코프에서 생성된 코루틴들은 runBlocking의 컨텍스트를 상속받습니다
내부에 코루틴을 생성할 때 launch나 async를 사용하여 필요에 따라 자신만의 컨텍스트를 추가로 구성할 수 있습니다.
부모 코루틴 스코프가 자식의 Job 들을 컨텍스트로 관리하고 있으므로 쉽게 취소를 전파할 수 있습니다.
Coroutine Scope 종류
Coroutine Scope은 기본적으로 시스템이 제공해주는 미리 정의된 Scope과 유저가 직접 생성해서 사용하는 커스텀 Scope 두 종류가 있음
미리 정의된 Scope
1. GlobalScope : 앱의 생명주기와 함께 하는 Scope (잘 사용 x)
2. lifecycleScope : Android에서 컴포넌트의 라이프사이클에 해당하는 Scope
3. viewModelScope : Android에서 ViewModel의 라이프사이클에 해당하는 Scope
커스텀 Scope
CoroutineScope 함수를 이용해서 직접 생성
커스텀 CoroutineScope를 생성할 때는 코루틴 컨텍스트를 인자로 제공해야 합니다.
fun main() {
val customScope = CoroutineScope(Dispatchers.Default + Job())
customScope.launch {
// 커스텀 스코프 내부에서 코루틴 실행
println("코루틴 실행 중...")
}
// 필요한 경우 스코프의 생명주기를 관리할 수 있음
// customScope.cancel()을 호출하여 스코프와 모든 코루틴을 취소할 수 있음
}
Coroutine Dispatcher
코루틴 디스패처(Coroutine Dispatcher)는 코루틴이 어떤 스레드에서 실행될지 결정하는 역할을 합니다. 코틀린 코루틴에서는 Dispatcher 객체를 통해 여러 가지 디스패처를 제공하며, 각 디스패처는 코루틴이 실행될 컨텍스트를 결정합니다.
Dispatcher 종류
- Dispatchers.Default
- CPU 사용량이 많은 작업에 최적화된 디스패처입니다.
- 기본적으로 공유된 백그라운드 스레드 풀을 사용합니다.
- 예: 대규모 리스트 정렬, JSON 파싱 등
- Dispatchers.IO
- I/O에 최적화된 작업을 위한 디스패처입니다.
- 파일, 네트워크 호출, DB 트랜잭션 등 입출력 작업에 사용됩니다.
Dispatchers.Default와 마찬가지로 백그라운드 스레드 풀을 사용하지만, I/O 작업의 특성을 고려하여 구성되어 있습니다.
- Dispatchers.Main
- UI 작업을 위한 메인 스레드에서 실행되는 디스패처입니다.
- 안드로이드에서는 UI 업데이트 같은 작업을 이 디스패처를 통해 실행합니다.
- Dispatchers.Unconfined
- 호출한 스레드에서 코루틴을 시작하지만, 첫 번째 중단 지점 이후에는 실행되는 스레드가 지정되지 않습니다.
- 특정 스레드에 구애받지 않고 실행되며, 필요에 따라 스레드를 변경할 수 있습니다.
- 특정 사용 사례에 따라 유용할 수 있으나 일반적인 경우에는 추천하지 않습니다.
fun main() = runBlocking {
launch(Dispatchers.Main) {
// UI 업데이트 작업
}
launch(Dispatchers.IO) {
// 네트워크 호출 등 I/O 작업
}
launch(Dispatchers.Default) {
// CPU 집약적 작업
}
}
코루틴에서 디스패처를 명시적으로 지정하지 않으면, 코루틴이 실행될 기본 디스패처는 상위 코루틴의 컨텍스트를 상속받습니다.
코루틴을 이용해서 논블로킹 비동기적으로 작업을하는 방법
아래 코드는 runBlocking에서 시작해서 각각의 코루틴 하나씩 시작하겠다고 알리고 나오는 것이다.
그럼 각각의 코루틴은 논블로킹 비동기적으로 수행하지만 이는 동시성인 것이지 병렬성은 아니다.
각각의 코루틴 내부에서는 동기적으로 수행된다
이때 주의할점은 각 코루틴은 협조적이여야한다. 즉, 끝날 수 있어야하고 작업이 매우 긴 경우 중간중간에 중지함수가 포함되어있어야한다
import kotlinx.coroutines.launch
import kotlinx.coroutines.runBlocking
import kotlinx.coroutines.*
fun main() {
runBlocking {
println("m s")
launch {
val user = loadUser()
println("user: $user")
}
launch {
val product = loadProduct()
println("product: $product")
}
println("m f")
}
}
suspend fun loadUser() : String {
println("start use")
delay(2000)
println("finish use")
return "user"
}
suspend fun loadProduct() : String {
println("start pro")
delay(1500)
println("finish pro")
return "product"
}
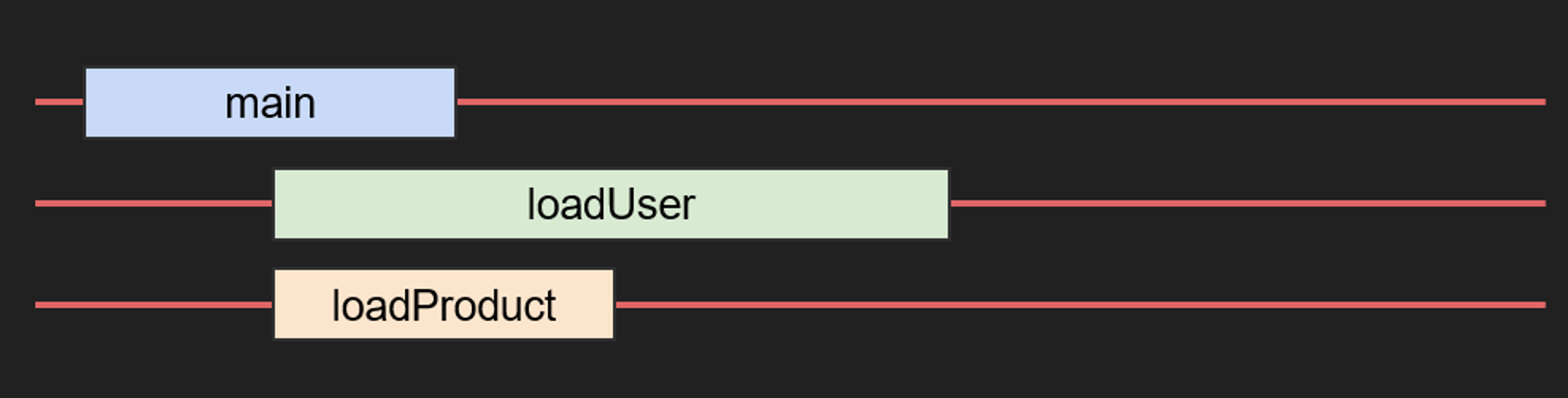
아래와 같이 async & wait를 쓰는 코드는 어떨까
fun main() {
runBlocking {
println("main started")
val user = async { loadUser() }
println("user loading request")
val product = async { loadProduct() }
println("product loading request")
println("user : ${user.await()}")
println("product : ${product.await()}")
println("main finished")
}
}
suspend fun loadUser(): String {
println("start use")
delay(2000)
println("finish use")
return "user"
}
suspend fun loadProduct(): String {
println("start pro")
delay(1500)
println("finish pro")
return "product"
}
[result]
main started
user loading request
product loading request
start use
start pro
finish pro
finish use
user : user
product : product
main finished
코루틴은 순서대로 시행이 된다.
하지만 첫번째 코루틴에서 두번째 코루틴(user)이 종료될때까지 기다리는 await를 쓴다.
그 와중 세번째(product) 코루틴이 끝나지만 첫번째 코루틴은 아직 두번째 코루틴의 종료를 기다리므로 println("product : ${product.await()}") 는 실행이 안된다.
withContext는 코루틴 내에서 다른 디스패처(즉, 다른 스레드 또는 스레드 풀)로 코드 블록의 실행 컨텍스트를 임시적으로 전환할 때 사용하는 코틀린 코루틴 라이브러리의 함수입니다.
withContext를 사용하면 현재 코루틴의 실행을 잠시 중단하고, 지정한 디스패처에서 코드 블록을 실행한 후, 결과를 반환하고 원래의 컨텍스트로 돌아올 수 있습니다.
withContext는 엄밀히 말하면 코루틴 빌더가 아니다
따라서 중간에 다른 작업을 디스패처를 변경하여 동시적으로 실행 하고 싶으면 async 또는 launch를 사용하면 된다.
코루틴의 취소
작업은 때때로 취소가 가능해야 함
ex) 화면을 종료해서 더이상 API로 부터 데이터를 받아올 필요가 없는 경우
ex) 시간이 비정상적으로 오래 걸려서 작업을 진행할 수 없는 경우
취소를 하지 않으면 사용하지 않는 메모리와 CPU의 낭비가 있음
코루틴의 실행 취소는 CoroutineContext의 한 종류인 Job이 관리
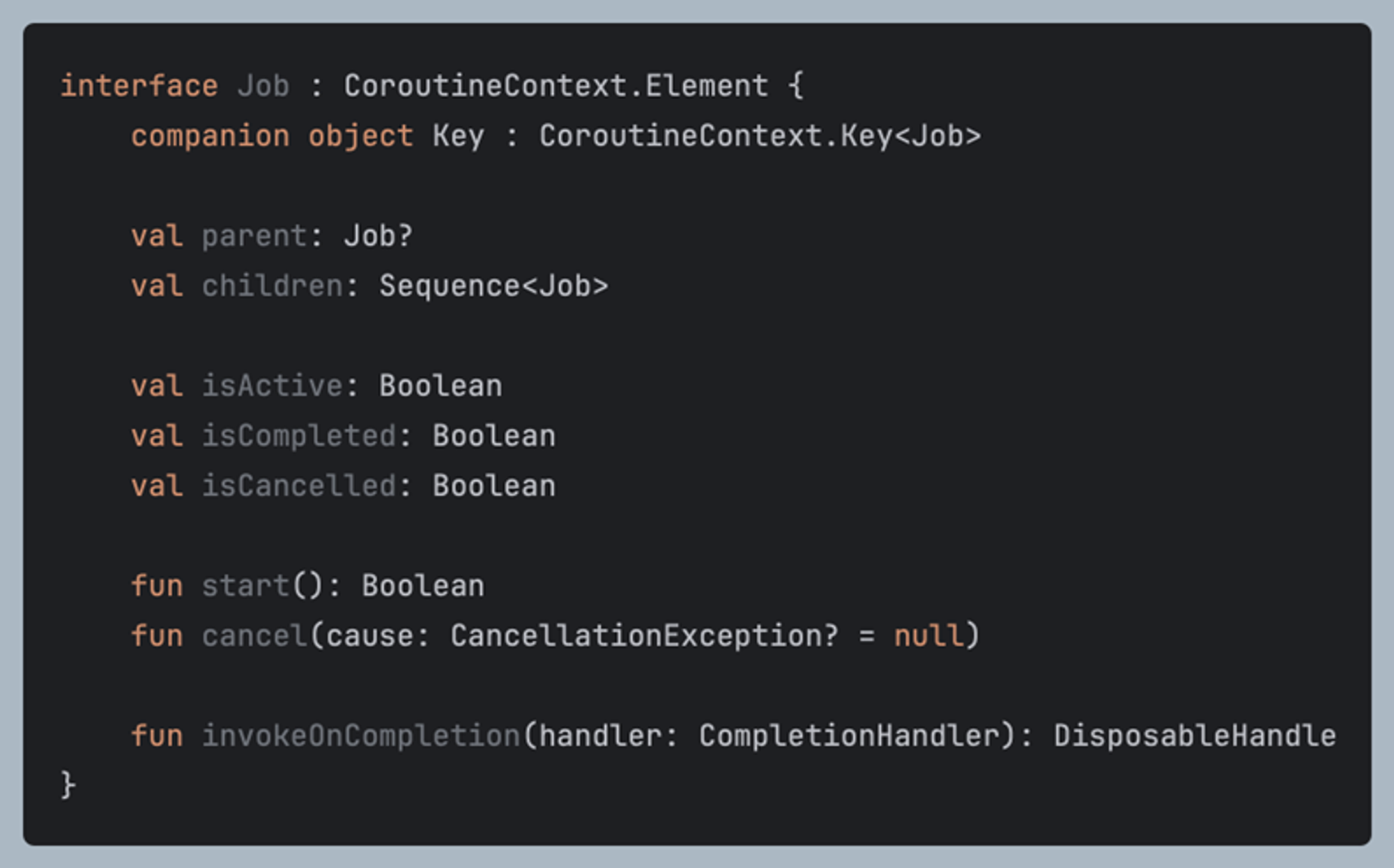
Job은 이전에 설명했듯이 부모와 자식이 있어서 구조적 동시성을 지원해줌
이러한 구조를 통해, 부모 Job이 취소되거나 실패할 경우, 그에 속한 자식 Job들도 함께 취소되거나 실패 처리되는 등의 동작을 자동으로 수행할 수 있습니다.
또한 부모 코루틴이 완료되기 전에는 자식 코루틴들이 모두 완료되어야 합니다. 이는 코드의 실행 흐름을 더욱 안전하고 예측 가능하게 만듭니다
1. launch에서 코루틴 취소
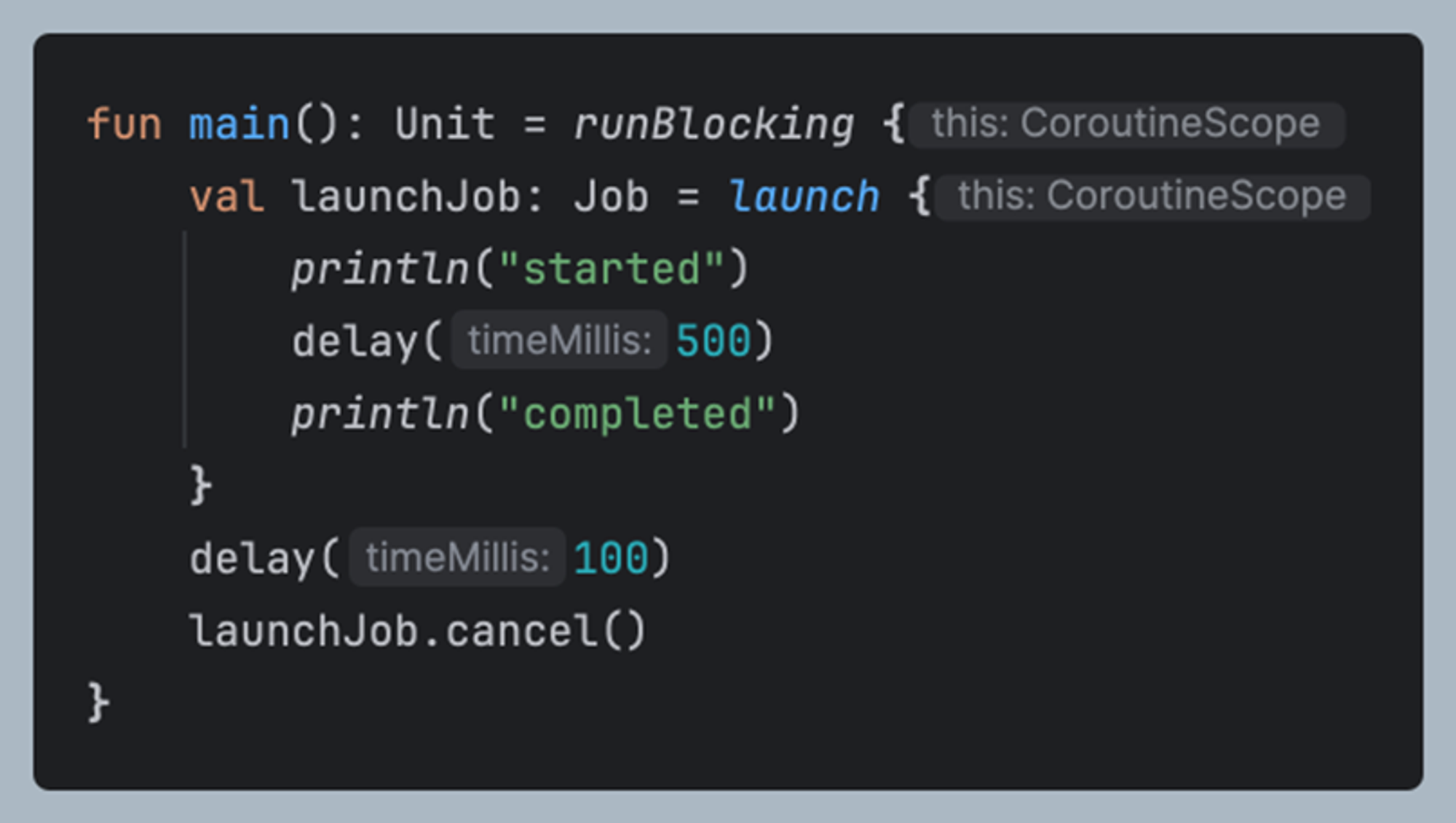
launch의 경우 코루틴을 만들면서 해당하는 Job을 리턴, 이 때 얻은 Job을 통해서 취소 가능
2. async에서 코루틴 취소
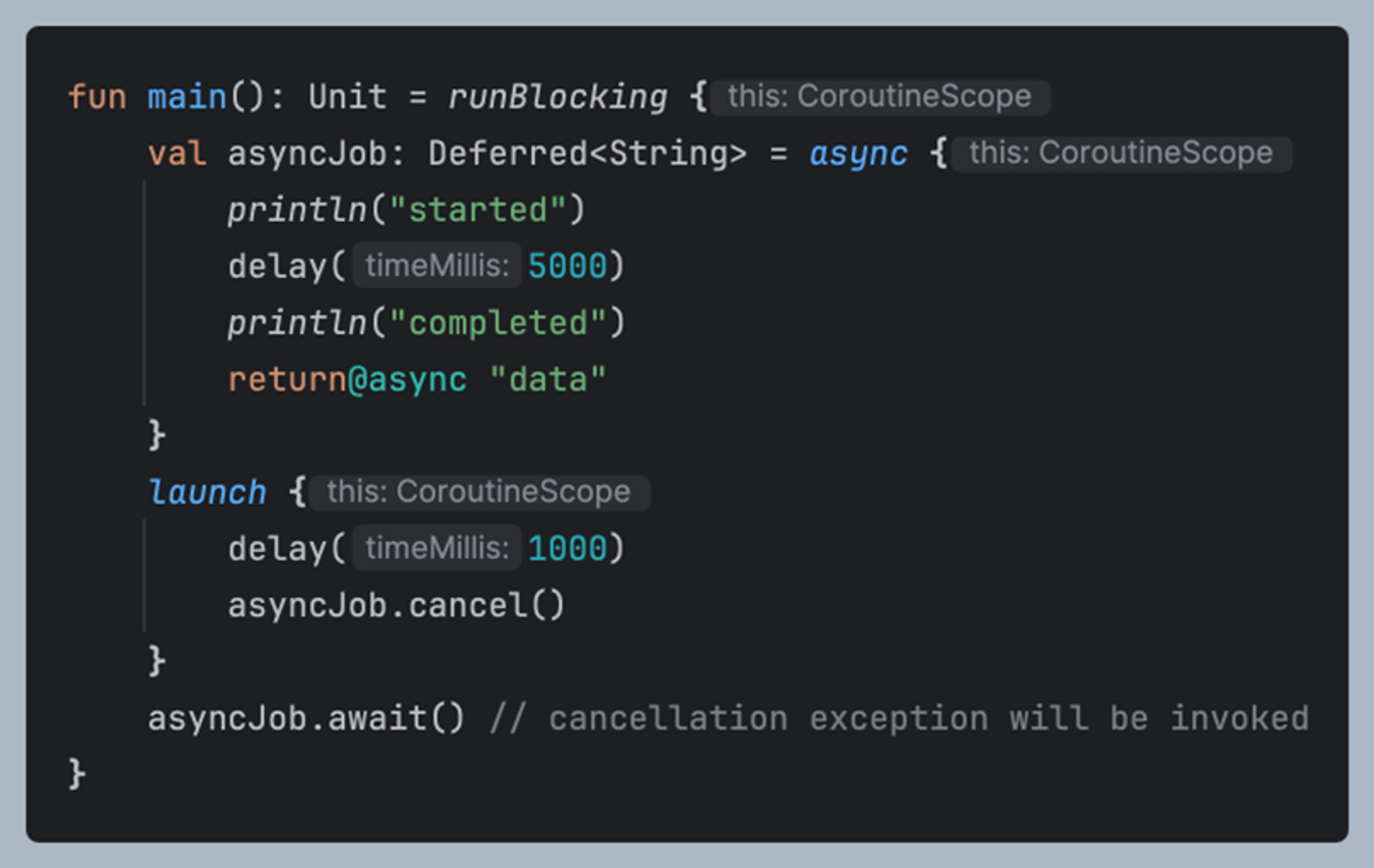
async의 경우 코루틴을 만들면서 해당하는 Deferred를 리턴
Deferred는 Job의 자식 인터페이스
Deferred를 통해서 취소 가능
await() 중에 취소되면 해당 지점에서 취소 에러 발생(JobCancellationException)

따라서, await를 호출할 때는 코루틴의 취소 상태를 고려하거나, 적절한 예외 처리를 구현해야 합니다.
try {
deferred.await() // 코루틴이 취소된 경우 CancellationException 발생
} catch (e: CancellationException) {
println("Caught CancellationException")
}
3. CoroutineScope에서 코루틴 취소
CoroutineScope 자체를 cancle 할수도 있습니다. 이 경우 정의된 Scope의 모든 코루틴을 취소 시킬 수 있음 Scope은 자신 내부에 등록된 Job을 탐색해서 취소를 요청
4. viewModelScope에서 코루틴 취소
viewModelScope는 Jetpack ViewModel 컴포넌트에 속한 프로퍼티로, ViewModel이 소유하는 코루틴 스코프입니다.
이 스코프는 ViewModel의 생명주기에 바인딩되어 있어, ViewModel이 소멸될 때 자동으로 스코프 내의 모든 코루틴이 취소됩니다. 이 또한 구조적 동시성이죠
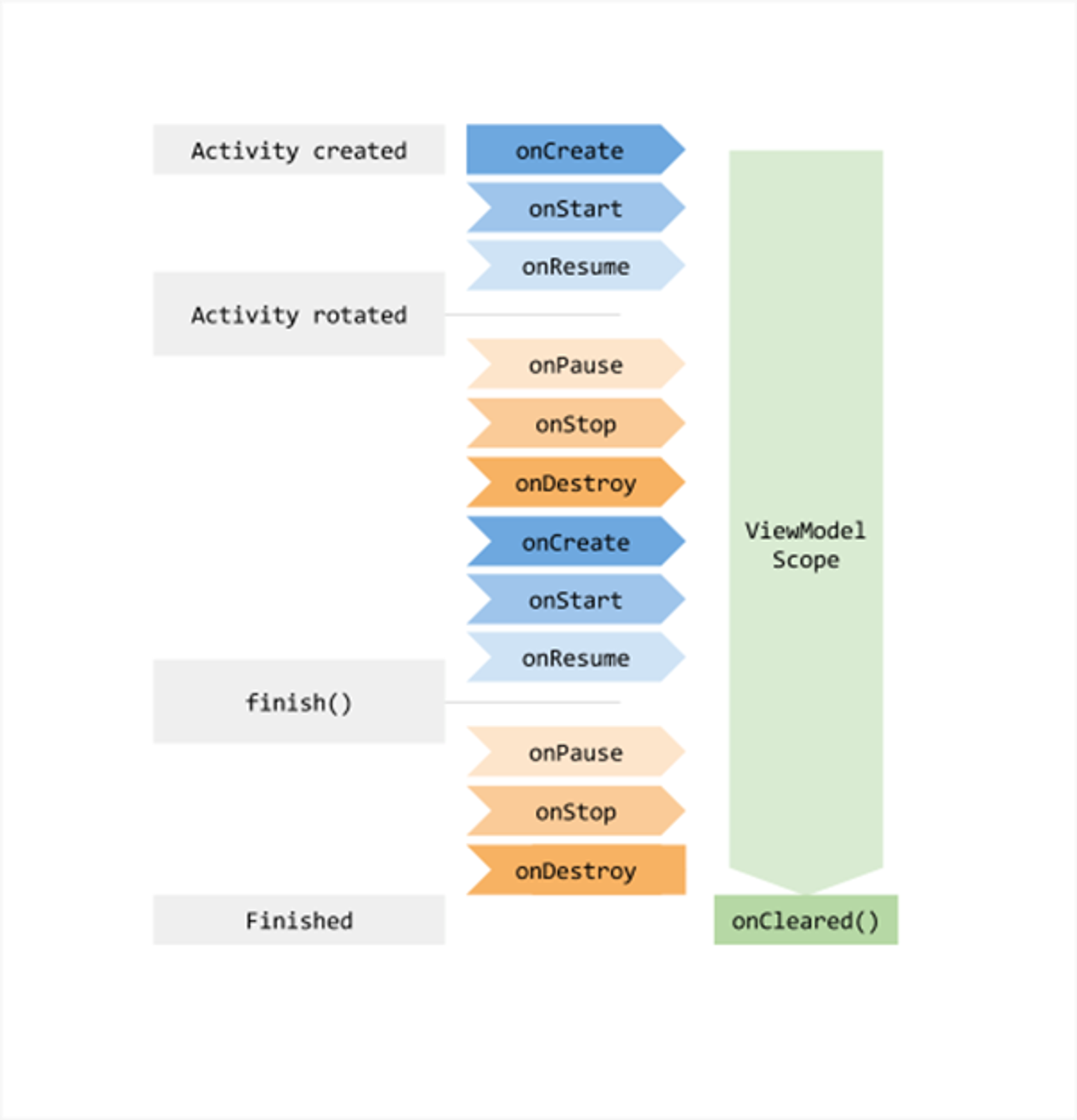
부모가 취소되면 자식에게도 취소가 전파 됨
반대로 자식이 취소되더라도 부모는 영향을 받지 않음
부모 취소
fun main() {
runBlocking {
val parentJob = launch {
println("parent start")
launch {
println("child start")
for (i in 0 .. 10) {
delay(100)
println("i : $i")
}
println("child complete")
}
delay(1000)
println("parent complete")
}
delay(500)
parentJob.cancel()
}
}
[result]
parent start
child start
i : 0
i : 1
i : 2
i : 3자식 취소
fun main() {
runBlocking {
val parentJob = launch {
println("parent start")
val child = launch {
println("child start")
for (i in 0 .. 10) {
delay(100)
println("i : $i")
}
println("child complete")
}
delay(300)
child.cancel()
println("parent complete")
}
delay(500)
}
}
[result]
parent start
child start
i : 0
i : 1
parent complete개발 할 때 종종 사용 후 자원을 해제해야 하는 경우가 있음
코루틴의 취소 자체는 코루틴이 실행 중인 작업을 중단시키지만, 자동으로 열린 파일이나 소켓 연결을 닫아주지는 않습니다.
- try finally
import kotlinx.coroutines.*
fun main() = runBlocking {
val job = launch {
try {
delay(1000
} finally
println("자원 정리")
}
}
delay(500)
job.cancelAndJoin()
println("코루틴 취소")
}취소가 요청되면 코루틴이 중단 되는 시점에 CancellationException이 발생함
예외 처리로 finally 부분에 자원을 해제하면 됨
코루틴이 취소될 때 finally 블록이 실행되는 것은 보장되지만, 취소된 코루틴에서 일부 종류의 작업을 수행하려고 하면 CancellationException이 발생할 수 있습니다. 특히, suspend 함수를 finally 블록 내에서 호출하려고 할 때 주의가 필요
finally 블록을 사용하여 자원 정리 코드를 구현할 때, 다음 사항을 고려해야 합니다:
- 비블로킹 코드 사용: 가능하면
finally블록 내에서는 취소에 안전한, 즉 블로킹되지 않는 작업을 수행해야 합니다. NonCancellable컨텍스트 사용:suspend함수를 포함한 중요한 정리 작업을 수행해야 하는 경우withContext(NonCancellable)을 사용합니다.
NonCancellable은 코루틴의 취소 상태와 무관하게 작업을 수행하기 위해 사용되는 코루틴 컨텍스트입니다.
예를 들어 자원 해제나 정리 로직과 같은 경우에 유용합니다.
import kotlinx.coroutines.*
fun main() = runBlocking {
val job = launch {
try {
delay(1000)
} finally {
withContext(NonCancellable) {
println("자원 정리 코드")
delay(1000)
println("자원 정리 완료")
}
}
}
delay(500)
job.cancelAndJoin()
println("코루틴 취소")
}- use 함수
import kotlinx.coroutines.*
import java.io.File
fun main() = runBlocking {
val job = launch {
File("example.txt").inputStream().use { inputStream ->
// 파일 처리
println("파일 읽는 중...")
delay(1000)
}
}
delay(500)
job.cancelAndJoin()
println("코루틴 취소 완료")
}
Closable 인터페이스가 구현된 자원이라면 use {} 를 통해서 내부적으로 finally { close() } 호출이 가능함 try finally { close() } 와 원리는 똑같지만 이를 좀 더 쉽게 쓸 수 있도록 지원해주는 API
그 외에도 여러가지가 있는데 그냥 try,finally와 withContext(NonCancellable)을 사용하는게 가장 직관적이면서 효과적일듯하다.
취소는 다음 중단점에서 이루어짐
import kotlinx.coroutines.*
fun main() = runBlocking {
val job = launch {
while (true) {
println("in progress")
}
}
delay(500)
job.cancel()
}위 코드를 보자
위 코드는 영원히 끝나지 않는다.
이상한 점을 느낄것이다.
새로운 코루틴을 만들어서 논블로킹 비동기적으로 동작하는데 왜 cancle이 되지않을까
그 이유는 취소 요청 즉시 코루틴이 종료되는 것은 아니기 때문이다.
job.cancel()을 호출하면 코루틴에 취소 신호가 전송됩니다. 하지만, 코드 내의 while (true) 루프는 취소 체크를 수행하지 않기 때문에, 코루틴이 취소되어도 무한 루프는 계속 실행됩니다.
코루틴의 취소는 "협조적"이어야 하며, 코루틴이 실행 중인 작업은 주기적으로 취소 여부를 확인하고 취소 상태에 따라 적절히 동작을 중단해야 합니다.
delay(), yield()와 같이 코루틴이 중단되는 시점에 도달하면 코루틴이 취소되었는지 확인하게 됨
만약 중단점 없이 연산작업을 오래 해야 한다면 해당 작업은 끝날 때까지 취소가 불가능함
fun main() = runBlocking {
val job = launch {
while (true) {
println("in progress")
yield()
}
}
delay(500)
job.cancel()
}yield는 코루틴이 긴 작업을 수행하고 있을 때, 다른 코루틴도 실행할 기회를 가질 수 있도록 합니다. 이는 코틀린 코루틴에서 협력적 멀티태스킹을 지원하는 중요한 메커니즘 중 하나입니다.
즉 runBlocking 부분이 중지를 해주어서 job이 실행되는데 job은 중지함수 없이 완전히 선점하고 있기 때문에 해당 부분도 중지함수를 포함시켜 협조적으로 만들어줘야한다.
마치 데드락에 걸린듯한 느낌을 준다.
이는 중지함수를 통해 해결가능
글이 너무 길어진거 같아서 다음 포스팅에 이어서...
