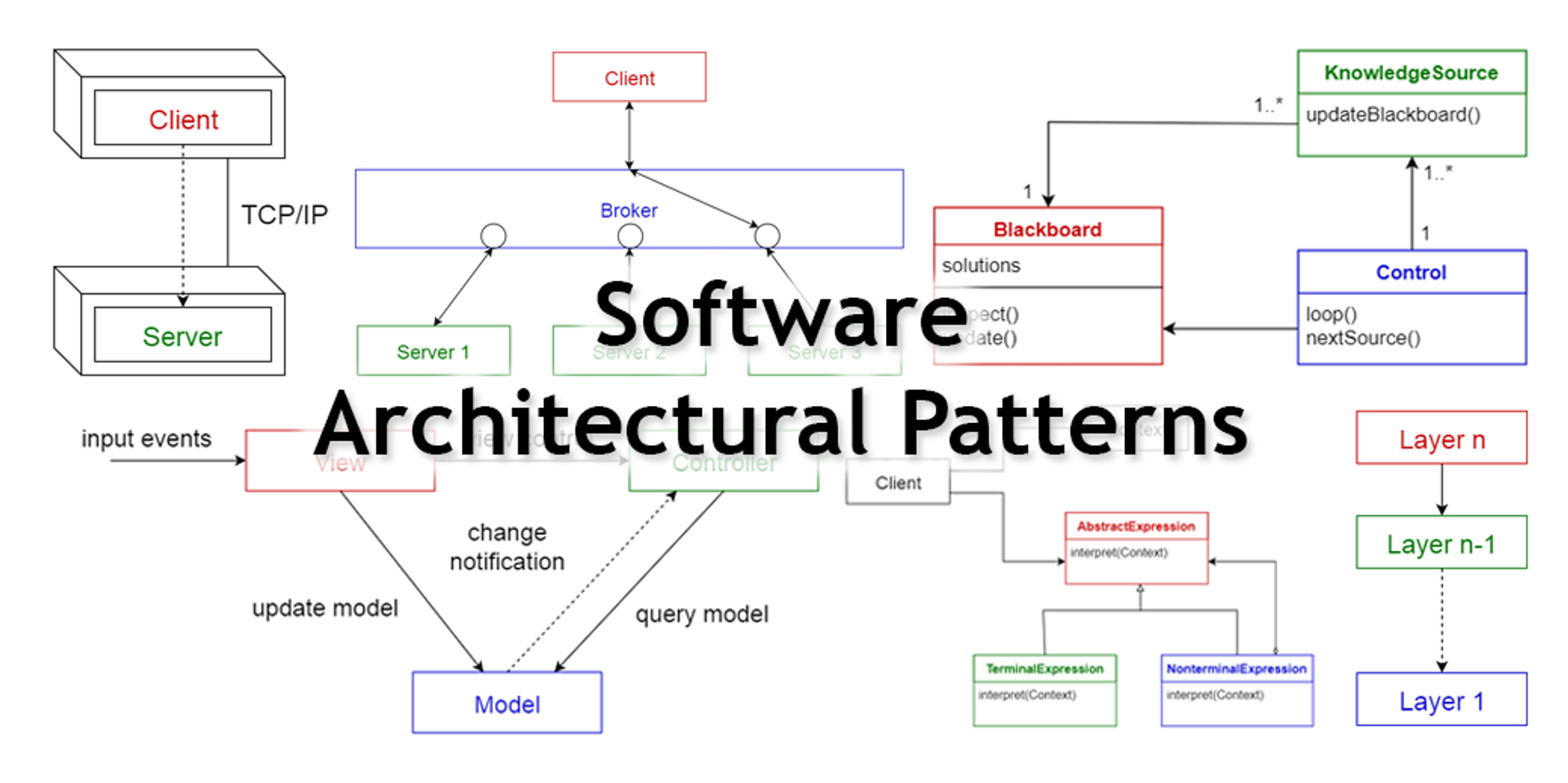
클린 아키택쳐… 정말 많이 들었지만 다루기 힘든 주제입니다.
아키택처란 항상 100%의 정답이 없고 내부적인 판단으로 유동적으로 변경되며 그 해당 아키택처의 효과를 이해하기엔 많은 경험과 숙련도가 필요하기에 도입하기 위해 공부할 때 이해하기가 쉽지 않다.
내가 경험한 내용을 기반으로 해당 내용을 작성해보겠다.
Architecture
먼저 WIKIEDIA 정의 이다.
소프트웨어 아키텍처란 소프트웨어 시스템을 추론하기 위해 필요한 구조들의 모임이며, 그러한 시스템과 구조를 만드는데 필요한 규율이다
개발을 조금만 접해봤다면 다양한 아키택처와 다양한 디자인 패턴에 대해 들어봤을 것이다.
내 생각을 통해 클린 아키택처 및 기타 디자인 패턴에 대해 쉽게 서술한다면 과거 많은 개발자들이 소프트웨어 개발 과정에서 발견한 설계 노하우 들이라고 생각한다.
현재 나와 같이 실무 경험이 적은 사람들은 미래에 발생할 문제들에 대응해 설계 능력이 부족할 수 있다.
이럴 때 과거 선배들이 삽질하며 일반적으로 발생하는 문제에 대응하는 구조를 만들어 놓은 이러한 아키택쳐 및 패턴은 유용하게 사용이 된다.
자세한 설계의 효과부분은 밑에서 실제 코드와 함께 더 자세히 알아보겠다.
또한 이러한 유명한 아키택처 또는 패턴을 공부하고 배운다면 새로운 프로젝트에 이해하고 적응하는데 훨씬 낮은 코스트가 들어간다.
내 경험을 말하자면 나는 cleanArchitecture을 공부한 후 nowInandroid라는 오픈소스를 분석하였다.
이 때 이 클린 아키택쳐를 공부했던 부분이 코드를 이해하는데 정말 많은 도움이 되었다.
따라서 아키택처는 개발자 간의 약속 또한 될 수 있는 것이다.
코드의 가독성을 올려주고 설계적인 측면에서 예측 가능한 코드를 만들어서 프로세스의 시간을 단축할 수 있다는 것이다.
그럼 어떤 것을 좋은 아키택처라고 할 수 있을까?
일단 당연하게도 소프트웨어 본연의 목표를 충족해야한다.
- 기능적 : 유저에게 그들이 원하는 기능을 제공
- 구조적 : 기능의 변화에 따라 유연하게 변경되어 제공
현대 소프트웨어는 지속적으로 변화가 필요하다.
변경이 필요 할 때 아키텍처가 제대로 고려되어 있지 않다면 최악의 경우에 앱을 새로 만드는게 나을 수 있음
SOLID
SOLID는 Uncle Bob이 제안하는 클래스를 구현하는 방법론이다.
사실 SOLID 원칙은 5가지가 있지만 5가지는 독립적인 부분이 아니다.
서로 연관이 되어 있는 부분이 많다고 생각한다.
SOLID의 궁극적인 목표는 아키택처의 목표와 같다.
1. 변경에 유연해야 한다.
2. 이해하기 쉬워야 한다.
3. 재사용이 쉬워야 한다.
1. Single Responsibility Principle / 단일 책임 원칙
단일 책임 원칙은 각 클래스나 컴포넌트가 하나의 기능만을 담당 하도록 설계하는 것을 의미합니다.
예를 들어, 하나의 클래스에서 데이터 로딩, 업데이트 및 UI 표시를 모두 처리하는 것은 이 원칙을 위반하는 것입니다.
사실 나는 아직 모호하다. 하나의 기능의 경계는 뭘까?
결국은 가독성을 유지하는 내에서 유지보수등 미래의 가능성을 고려하는 개발자의 판단 필요하다고 결정을 햇다.
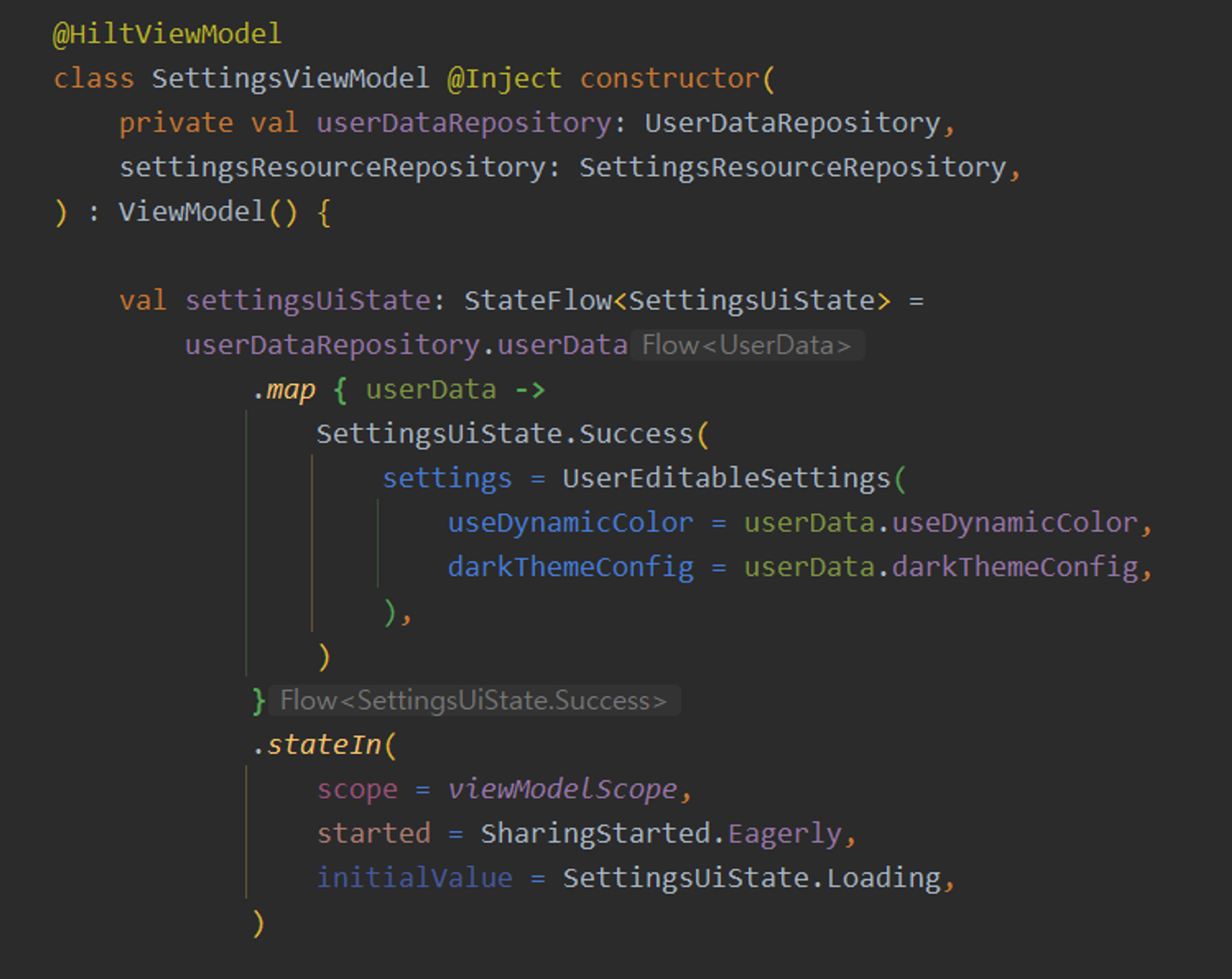
해당 코드는 Mineme 프로젝트의 SettingsViewModel의 일부분이다.
이 ViewModel은 Repository에서 데이터를 요청하고 저장하는 역할만을 수행한다. 이처럼 역할을 나누면 각각의 컴포넌트는 독립적으로 수정할 수 있어, 유지보수에 용이하다.
해당 코드는 Usecase를 사용하지 않기로 결정해서 ViewModel에 비즈니스로직이 있다.
그럼 어디까지 분리해야하는가? 내 생각에는 이해 하기 쉽게 한 기능이라고 한 것 같다. 사실 무조건 한 기능을 지키지 않아도 된다고 생각한다. 중요한 것은 개발하는 조직이 커뮤니케이션 하는 단위 즉, 좀 더 복잡히 말하자면 하나의 기능에 대해 접근하는 하나의 개발자 단위로 나누면 좋을 것 같다.
A개발자가 유지보수 및 개발하는 기능 부분
B개발자가 유지보수 및 개발하는 기능 부분
이렇게 중요한 것은 각 기능이 한 명의 개발자나 작은 팀 단위로 관리될 수 있도록 구분하는 것이 베스트라고 생각한다. 이로인해 각 팀 또는 개인이 명확한 책임을 가지고 효율적으로 커뮤니케이션 할 수 있을 것이다.
2. Open-Closed Principle / 개방-폐쇄 원칙 ,Dependency Inversion Principle / 의존성 역전 원칙
개방-폐쇄 원칙 : 확장에는 열려 있어야 하고, 변경에는 닫혀 있어야 한다.
즉 확장은 큰 cost없이 이루어져야하며 변경은 최대한 적은 cost로 진행되야한다는 것 같다.
개체와 개체의 기능 구현을 분리하고 개체가 기능을 직접 참조하지 않도록 하는게 중요
일반적으로 이러한 방식은 추상화를 통해 이루어진다.
내가 생각하기로 이 방식은 의존 역전 법칙과 밀접하게 연관 있다.
의존성 역전 원칙 : 구체적인 구현체가 아닌 인터페이스에 의존해야한다. 이로 인해 독립적으로 부분을 나눌 수 있어 유지보수 및 테스트에 효율적이다
내 코드의 일부분으로 예시로 알아보겠다.
테스트 용이성을 보여주는 예제이다.
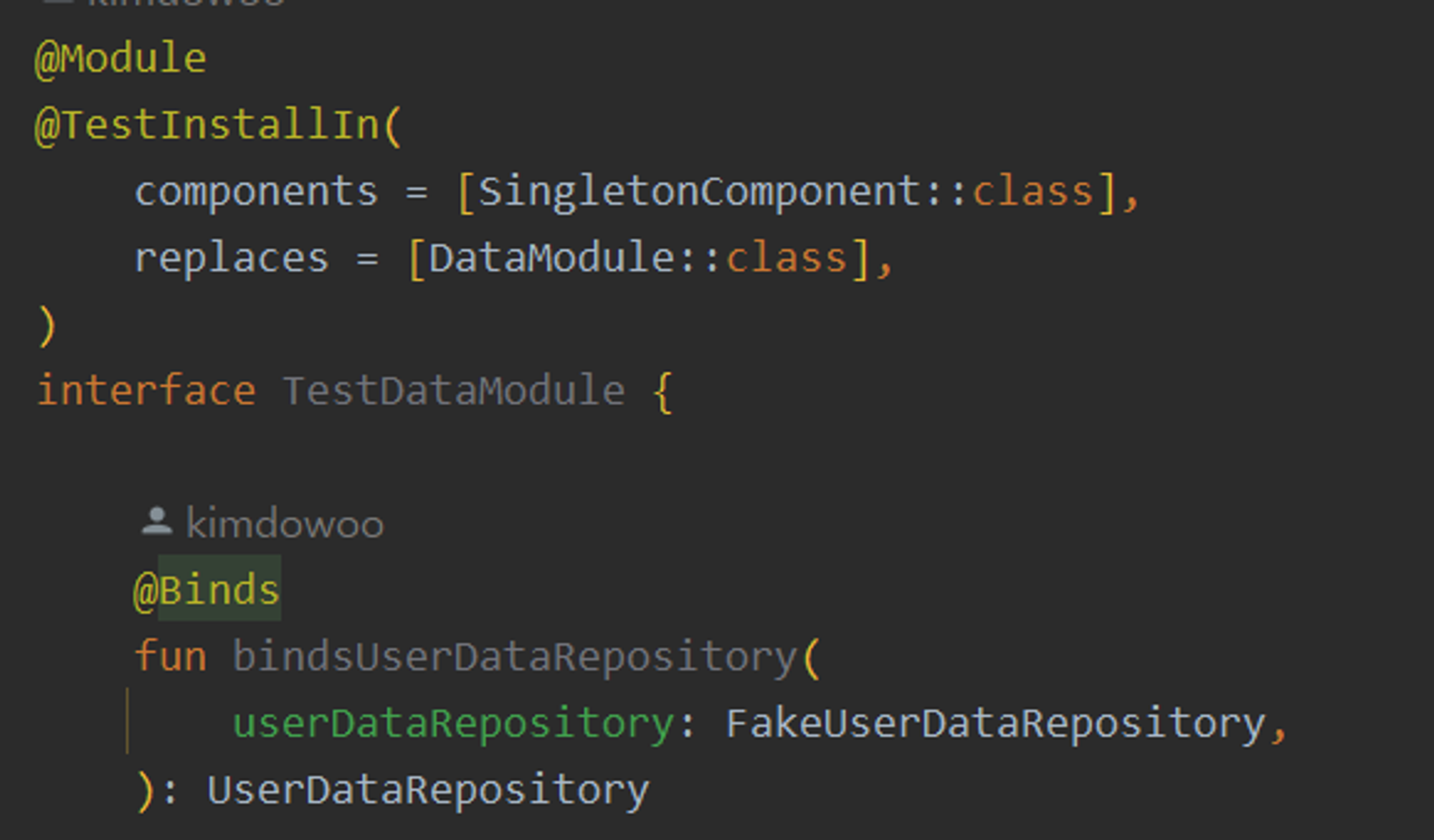
해당 코드는 테스트 실행 시 기존의 DataModule을 대체하는 테스트 의존성 주입 모듈이다.
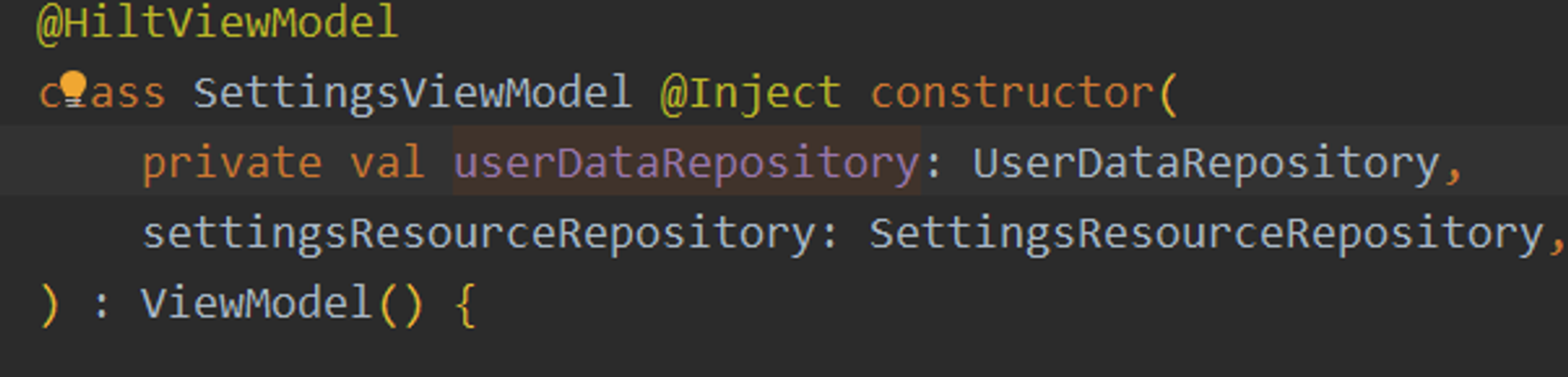
간단히 설명하자면 Hilt의 테스트 API를 사용하여 현실적이며 네트워크,데이터베이스 등 외부에 영향을 받지 않고 오로지 테스트에 집중하기 위해 단순화된 구현을 제공하기 위한 코드이다.
이로 인해 hilt를 통해 간편하게 상황에 맞는 구체화된 구현 객체를 바인딩할 수 있다.
이런식으로 Interface에 상속받게하면 테스트에도 용이하다 이는 개방폐쇠원칙에 따라 확장 및 변경으로도 설명이 가능한다.
-
만약 특정 실제 구현체에 확장이 일어났을 때 이에 의존하는 다른 부분은 변경이 되지 않았도 된다. 왜냐하면 의존하는 부분은 추상화된 Interface에 의존하기 때문이다.
-
변경 측면에서도 위 예제처럼 Interface에 의존하므로 Test구현체 또는 실제 구현체 등 실제 바인딩 되는 부분에 대해서 변경이 일어나더라도 코드 변경은 없어도 된다.
아래 코드를 보자.
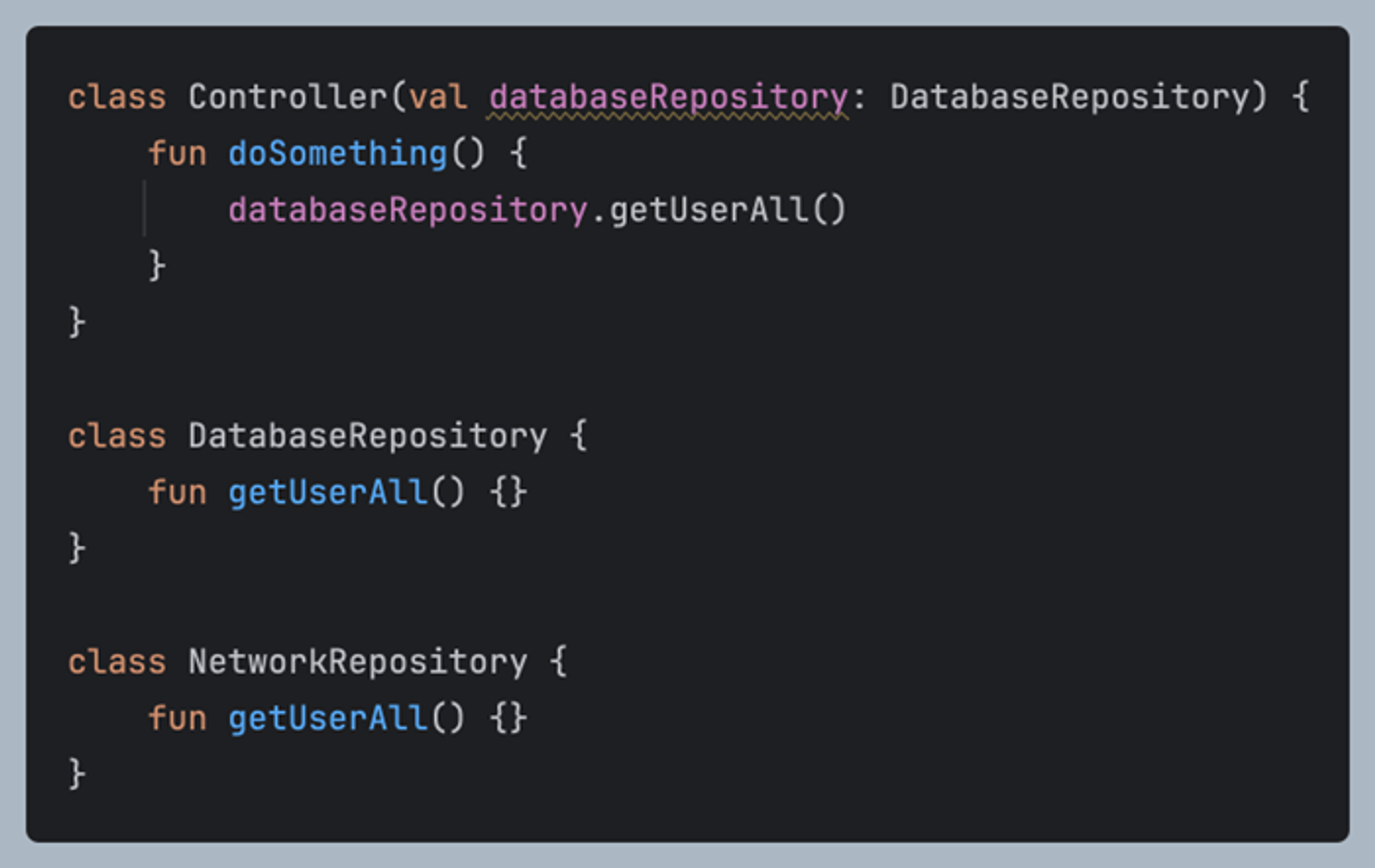
의존하는 구현체가 변경되야 할 때 만약에 실제 구현체를 의존받고있다면 해당 Controller 부분의 코드 변화 또한 존재한다. 또한 내부적인 코드나 메소드의 차이 또한 있다면 이를 또 의존하는 곳에 모두 변경이 일어나야한다.
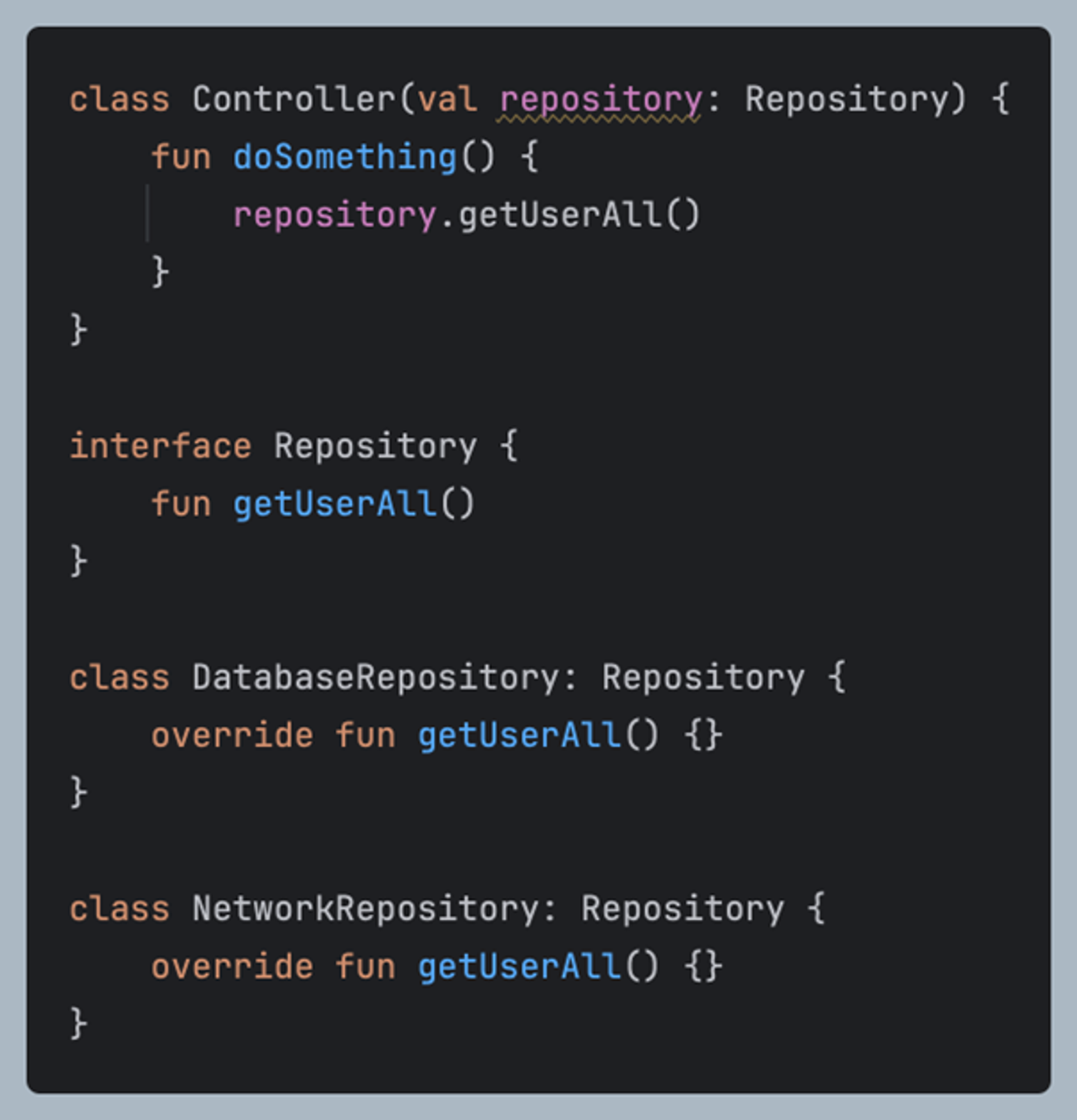
이렇게 Interface에 의존하게 만든다면 구현체의 변경이 필요할 때 Controller의 변화는 없어도 된다. 그저 필요에 따라 바인딩되는 객체를 명시해서 바꿔주기만하면 된다.
정리하자면 변경을 최소화 하기 위해서는 구현체에 대한 직접 참조를 회피해야 한다.
단일 책임 원칙에서도 언급했지만 이는 모듈 차원에서도 확장이 가능하다.
Data 모듈이 Domain 모듈을 참조하고 Domain 모듈은 Data 모듈을 모른다면 Data 모듈 내부에 클래스가 새로 생기던, 수정되던 Domain 모델은 변경될 필요가 없다. 왜냐 Domain은 Data를 모르기 때문 즉 영향을 안 받기 때문이다.
이 또한 어디까지 추상화를 해야할지 고민해야한다. 경험을 기반으로 변경 될 부분을 예측해서 추상화하는 능력을 기르는게 중요하다.
3. Liskov Substitution Principle / 리스코프 치환 원칙
리스코프 치환 원칙은 하위 클래스의 객체가 상위 클래스의 객체와 동일한 역할을 수행할 수 있어야 한다고 말합니다. 이 원칙은 인터페이스를 구현할 때 특히 주의해야 하는 사항이다.
예를 들어, 'FakeUserDataRepository'라는 테스트용 구현체를 살펴보겠습니다. 만약 이 페이크 레포지토리가 페이크 데이터 소스를 적절히 구현하지 못하여 테마 설정 정보 저장 시 예외가 발생한다면, 'setDarkThemeConfig' 메소드는 올바르게 동작하지 않는 것이 됩니다.
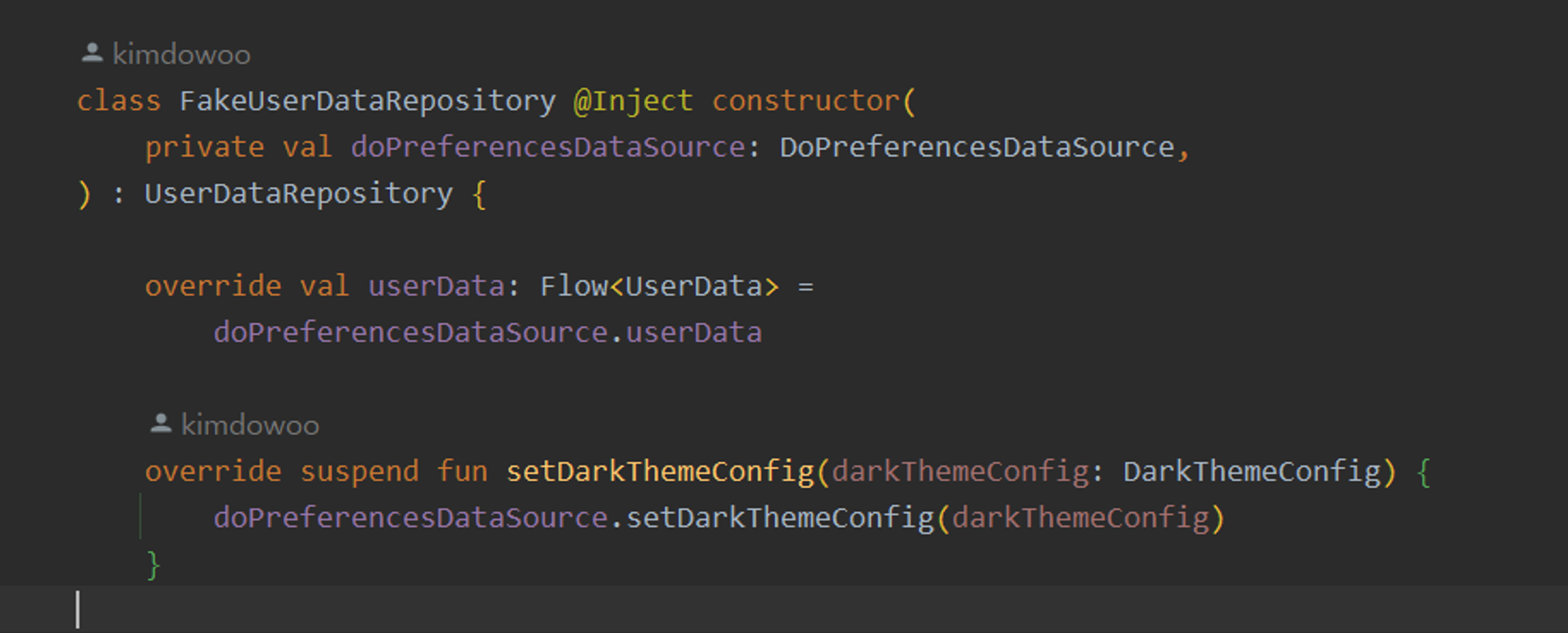
UserDataRepository에서 유저 데이터 저장을 전제하고 기능을 작성하였지만 하위 클래스에서 이를 적절히 처리하지 않고 에러를 던지는 것은 리스코프 치환 원칙에 위반된다.
특정 기능의 구현이 특정 구현체에서는 불가능하거나 필요하지 않을 경우, 그 기능은 별도의 인터페이스로 분리해야 합니 다.
예를 들어, 테스트용 가짜 레포지토리에서 데이터 소스에 데이터를 저장하는 것이 불가능하다면, 해당 기능을 다루는 인터페이스를 분리하고 실제 프로덕션 코드에서는 이 인터페이스를 다중 상속하여 사용하며, 필요한 부분만을 상속받아 구현하게 하면 됩니다.
4. Interface Segregation Principle / 인터페이스 분리 원칙
클라이언트가 자신이 이용하지 않는 메소드에 의존하지 않아야 한다.
즉 범용적인 인터페이스가 아닌 구체적이고 명확한 인터페이스를 사용해야 한다는 것

ViewModel에서 fetchUser를 사용하기 위해 NetworkClient를 참조합니다.
만약 NetworkClient 구현체가 fetchProduct로 인해 변경되었다면 ViewModel에 영향이 없는지 확인을 해야하는 cost가 들게 됩니다.
viewModel은 fetchProduct를 사용하지 않는데도 말이죠
핵심은 자신이 의존하는 범위를 최소화해서, 외부 변경으로부터 보호하는 것 내가 변경한 코드가 어디까지 의존하는지 찾아가는 것 자체가 코스트이고 코스트가 있다면 실수의 여지도 커진다는 것
애초에 의존 범위를 줄여서 서로 연관이 없음을 분명히 하는 것이 중요합니다.
이는 모듈의 의존성에도 중요합니다. 한 모듈에 적은 부분에만 의존한다면 이는 분리 고려 대상입니다.
이렇게 예시와 함께 SOLID를 전부 살펴보았는데요
좋은 아키택처란
좋은 아키택처란 무엇일까요?
보통 아래와 같은 공통 특성이 있다고 합니다.
- 프레임워크 독립성 : 프레임워크에 API에 의존하지 않는 구조
- 테스트 용이성 : 각 계층은 서로 분리되어서 테스트가 가능함
- UI 독립성 : 시스템 UI에 의존하지 않는 구조
- 데이터베이스 독립성 : 데이터베이스에 의존하지 않는 구조
- 모든 외부 에이전시에 대한 독립성 : 외부 세계에 의존하지 않는 구조
공통되는 단어를 찾으셨나요?
의존입니다.
의존성을 명확하고 낮게 가져가는게 중요한 핵심입니다.
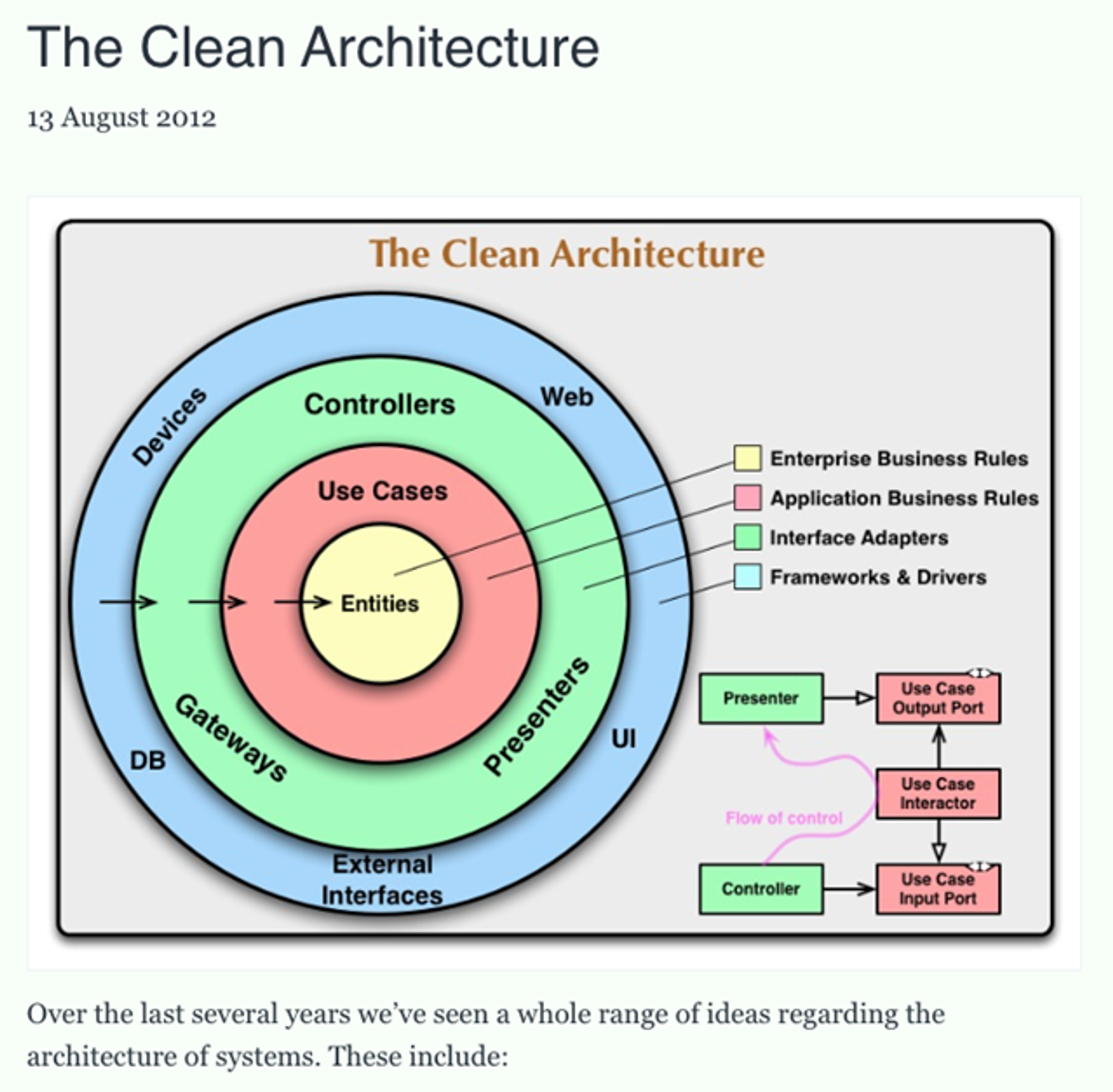
클린 아키택처 공부하려면 굉장히 이해하기 어렵죠.
중요한 부분은 의존성이 안으로 흐른다는 것 입니다.
바깥 원이 안쪽 원을 의존하도록 되어 있는데요
이는 많은 개발자들이 시행착오를 겪으며 변경이 많은 컴포넌트를 변경이 적은 컴포넌트에 의존하게 만들기 위해 설계한 것이라고 합니다.
즉 이러한 구조는 원의 안쪽은 외부의 상황을 모르기에 외부의 변화에 영향이 없습니다.
ANDROID 보통 아래 그림이 이해하기 조금 더 쉽더라구요
크게 3가지 레이어로 나눕니다.
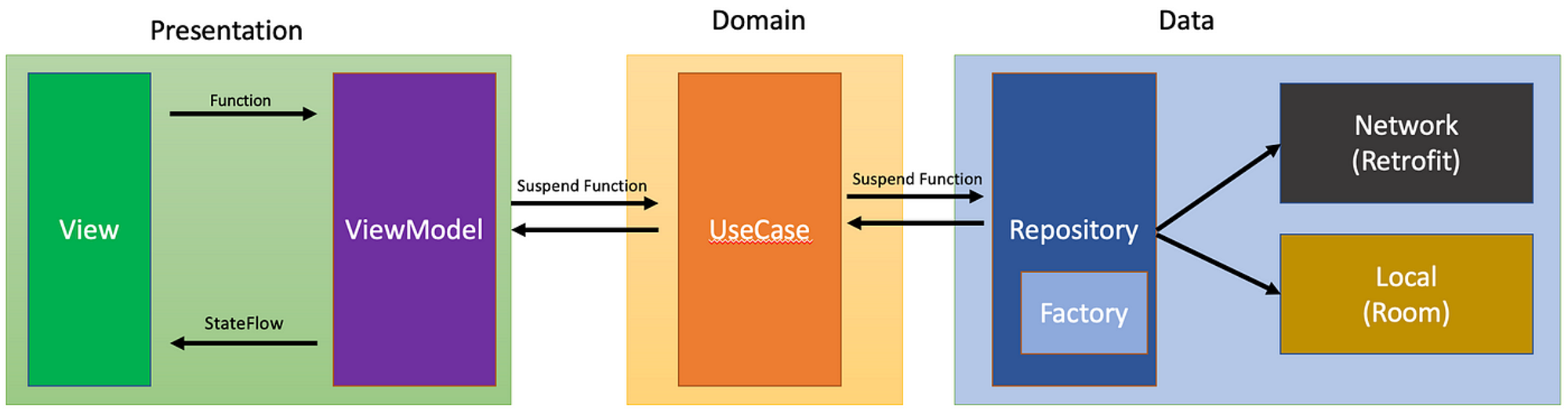
Domain이 가장 안쪽에 있는 레이어로 외부의 변화에 전혀 알지못합니다.
또한 Data와 Presentation은 서로에 대해 알지못하면 Domain에만 의존하여 Domain의 추상화에 의존하며 간접적으로 소통하게 됩니다.
저는 Mineme 프로젝트에서 Domain Layer을 크게 presentation과 data로만 분리를 했습니다.
그 이유는 재사용되는 Usecase가 없었기에 Domain을 따로 만드는 것이 오버헤드라고 판단했습니다.
따라서 Domain에 Usecase에 해당하는 로직은 viewModel에서 처리하게 두었고 data class등 Entity들은 model이라는 모듈로 따로 관리하였습니다. Repository interface는 Data에 두었습니다.
이러한 구조를 통해 도메인 레이어를 제거할 수 있었고, 공식 문서에서도 도메인 레이어의 사용은 선택적이라고 언급하고 있습니다.
Clean ArchiTecture와 함께 Presentation, Data 에서 내부적으로 또 자주 사용되는 아키택처가 있습니다. 여러분이 흔히 알고 계신 mvvm,mvi,mv..등등이 Presentation Architecture 입니다.
또한 Data에서는 흔히 저장소 패턴이 사용되는데요 그것 또한 알아보겠습니다
Presentation Architecture
Presentation Architecture란 데이터를 이용해 뷰를 보여주기 위한 아키텍처입니다.
흔히 말하는 mv? 패턴이 전부 Presentation Architecture의 예시입니다.
Android는 현대에 이르러서는 대부분 mvvm을 사용한다고 합니다.
구글 또한 간편한 mvvm 적용을 위해 여러 AAC를 지원하고 있습니다.
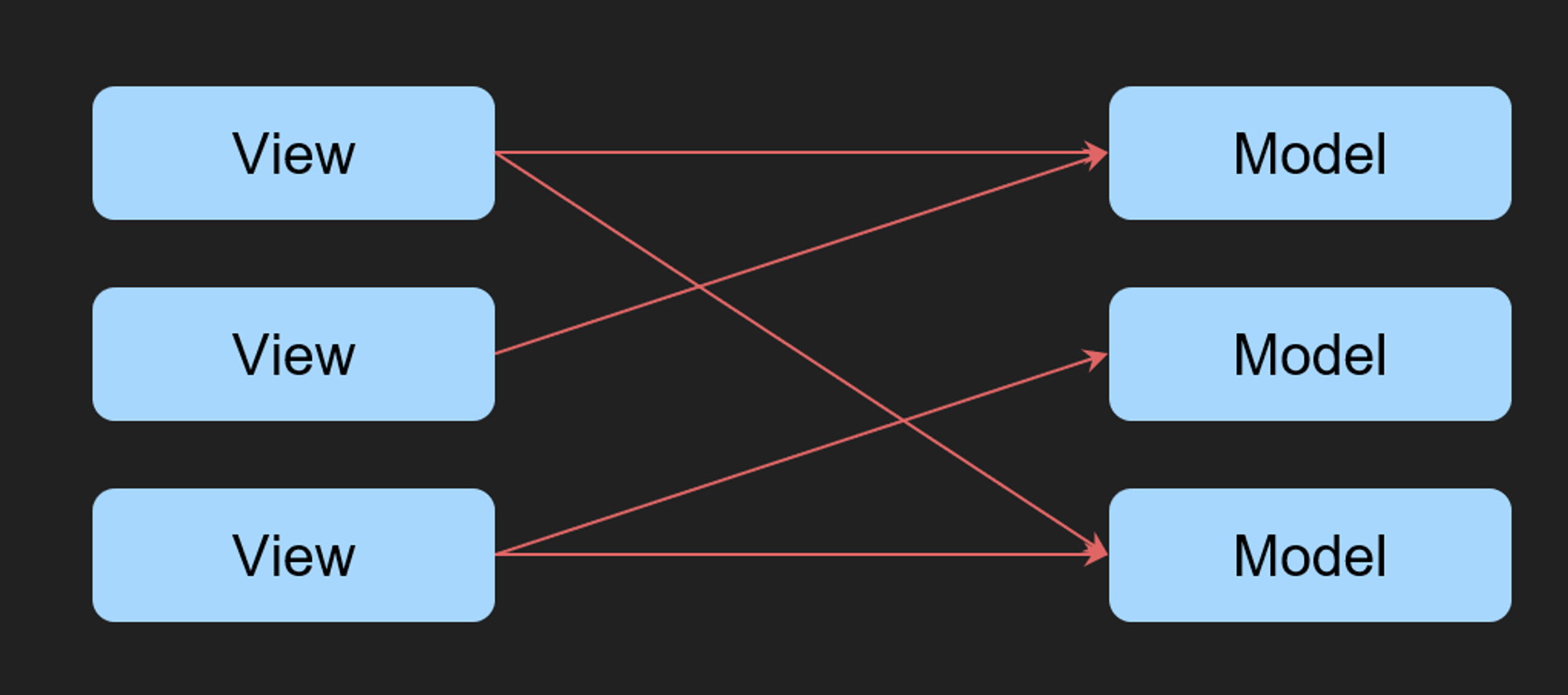
MV
최초에는 뷰가 데이터를 직접 참조해서 기능을 수행 했습니다.
이전에 단일책임원칙을 어기는 패턴 중 하나죠 이럴 경우 모델 하나가 변경되었을 때도 의존하는 모든 뷰가 변경되어야 한다는 단점이 존재했습니다.
MVC
그래서 view와 model간의 의존성을 낮추기 위해 나온 방법이 mvc입니다.
변경의 전파를 막기 위해 Controller라는 중계자가 중간에 들어가게 됩니다.
이벤트는 Controller로 전달 되며 View와 Model을 이용해서 기능을 수행했습니다.
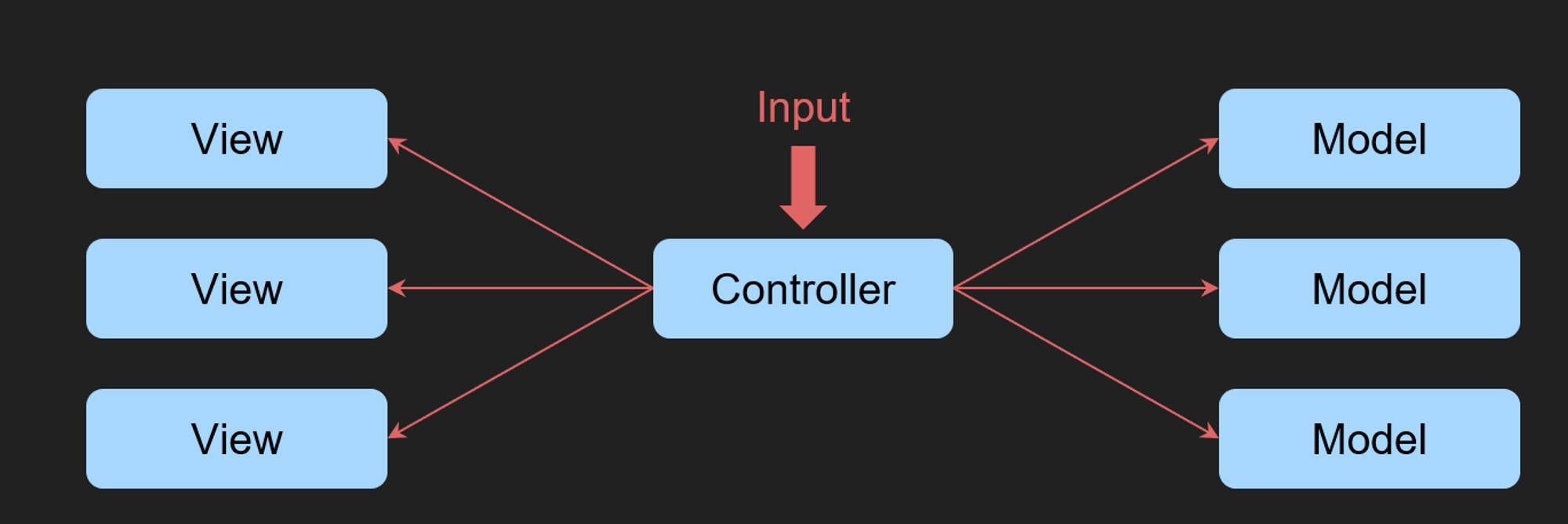
이렇게 함으로 써 이제 모델이 바뀌어도 Controller 부분만 수정하면 View 까지 변경하지 않아도 되었지만 MVC는 Controller 내부에서 View와 Model이 밀접하게 결합되기 때문에 코드의 재사용이 어려워지고 전체적으로 Controller가 과도하게 거대해지는 문제를 야기했습니다.
MVP
따라서 여러 VIEW에 대해 Controller를 하나를 두기보다는 각각의 view에 매핑되는 presenter을 정의해 이러한 문제를 해결하고자 했는데요 이게 MVP입니다.
이벤트는 View로 들어오고 이를 Presenter에게 보내면 **내부적으로 Model과 비지니스 로직을 수행해서 반환**
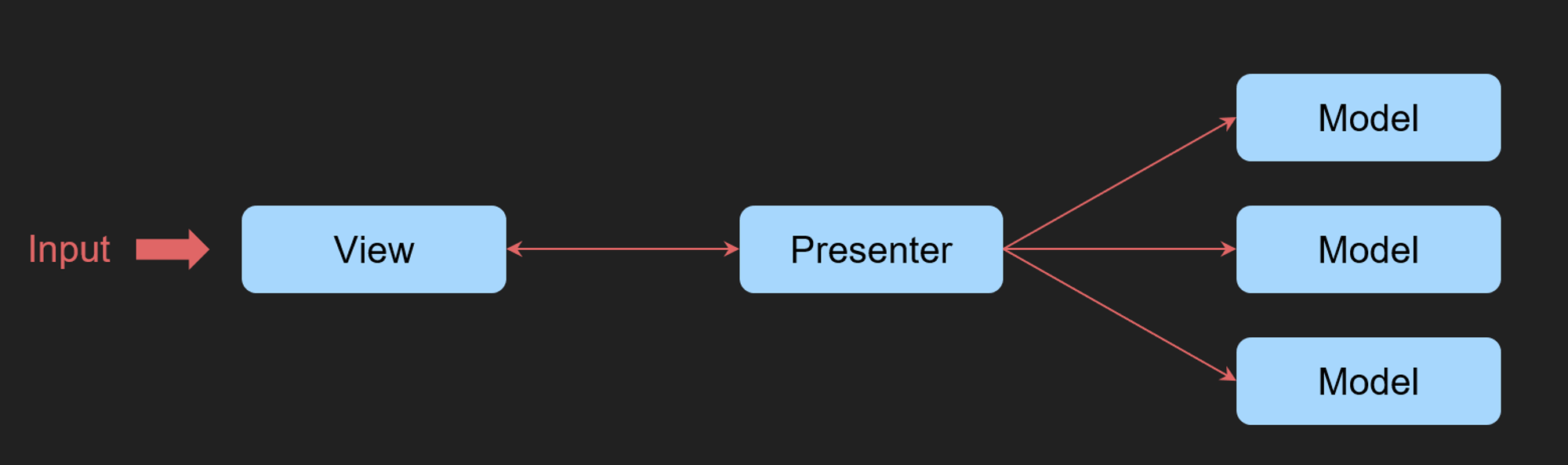
하지만 이벤트를 받고 model과 비즈니스 로직을 수행해서 view에 다시 반환하는 흐름에서 view와 presenter사이의 결합이 증가하는 문제가 되었습니다.
구체적으로 뷰와 프리젠터 간의 통신이 많을수록 코드가 더 복잡해질 수 있고 데이터 바인딩의 부재로 뷰와 프리젠테 간의 데이터 동기화를 수동으로 관리해야 함을 의미합니다.
이러한 로직이 다수 들어가면서 여전히 프리젠터의 과부화가 남아있고 이로 인해 유지보수가 쉽지 않았습니다.
특히 자주 변하는 view의 변화에 있어 presenter 또한 영향이 있기 때문에 이러한 부분에서 cost가 많이 생겼습니다.
MVVM
따라서 프리젠터가 View에 대해서 알지 못하게 하는 방식이 나옵니다.
이는 중계자와 View간의 결합을 끊기 위해 Observer Pattern이 이용하는 것인데요
View는 ViewModel을 알고 함수 호출과 상태값에 대한 구독을 수행
ViewModel은 자신의 상태와 비지니스 로직의 구현에만 집중하고 View를 알지 못 하게 하였습니다.
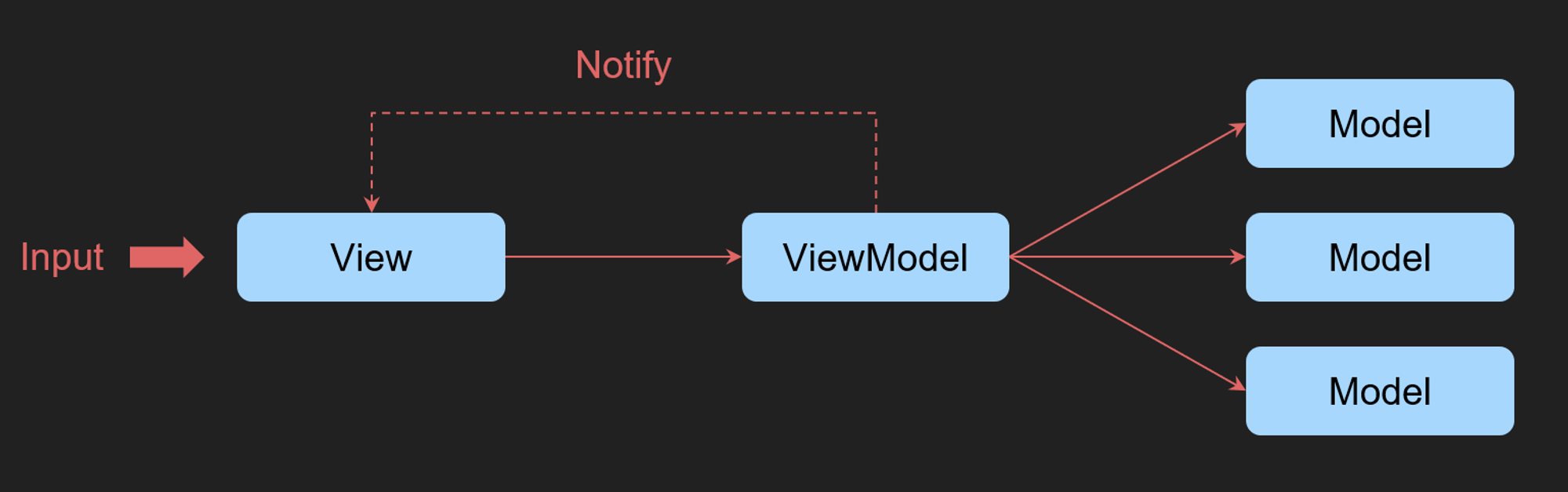
이로 인해 view의 변화에 있어 viewModel는 적극적인 변화가 필요 없게 되었습니다.
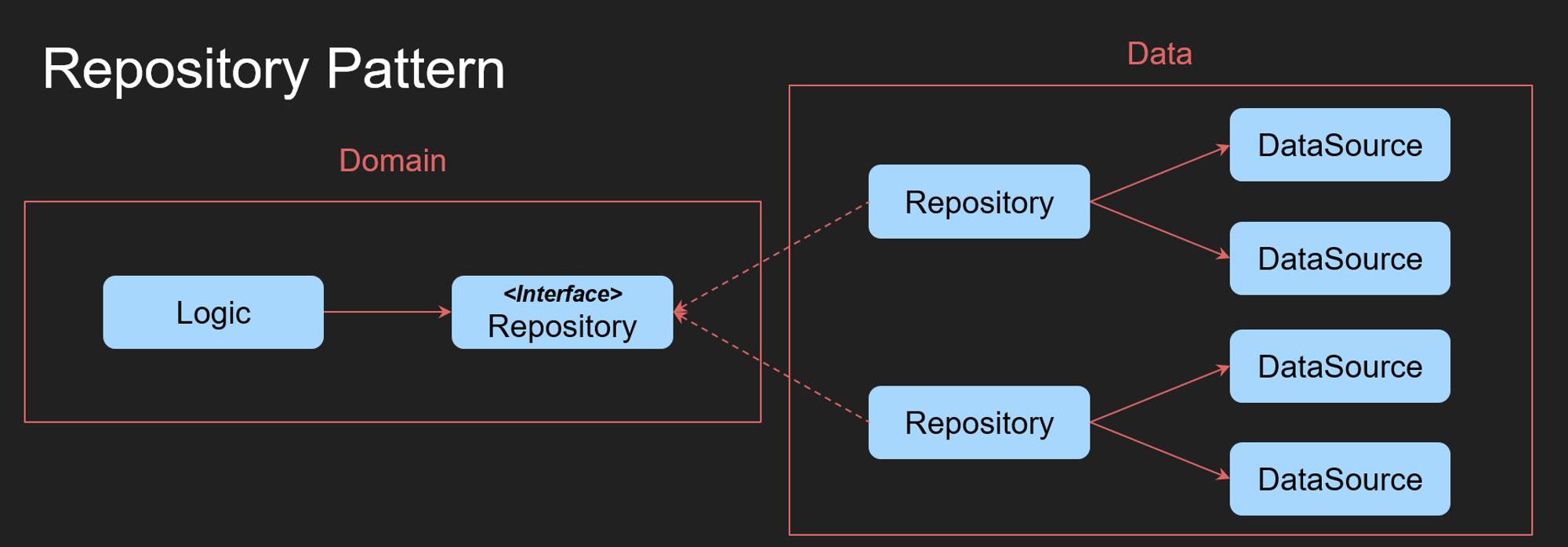
Repository Pattern 설명
Repository Pattern은 데이터에 대한 접근 및 처리를 실제 인프라와 분리하여 추상화하는 패턴이다.
이전에 말했던 SOLID 원칙이 강하게 적용된 예시이다. 자세히 알아보자
미리 결론부터 말하자면 Repository를 참조하는 객체가 Repository의 데이터가 어떠한 데이터 소스 (데이터베이스, 네트워크 등)에서 오는지 모르게하여 Repository의 데이터를 필요로 하는 부분은 그러한 데이터 소스의 변화에도 영향이 없게 만드는 것이다.
코드로 볼까요?
제가 Paging Picsum Gallery App을 구현하며 OfflineFirstApp을 구현할 때 예시 입니다.
해당 부분은 offline first를 구현하기 위해 데이터베이스와 Network 두 개의 DataSource를 사용하는데요
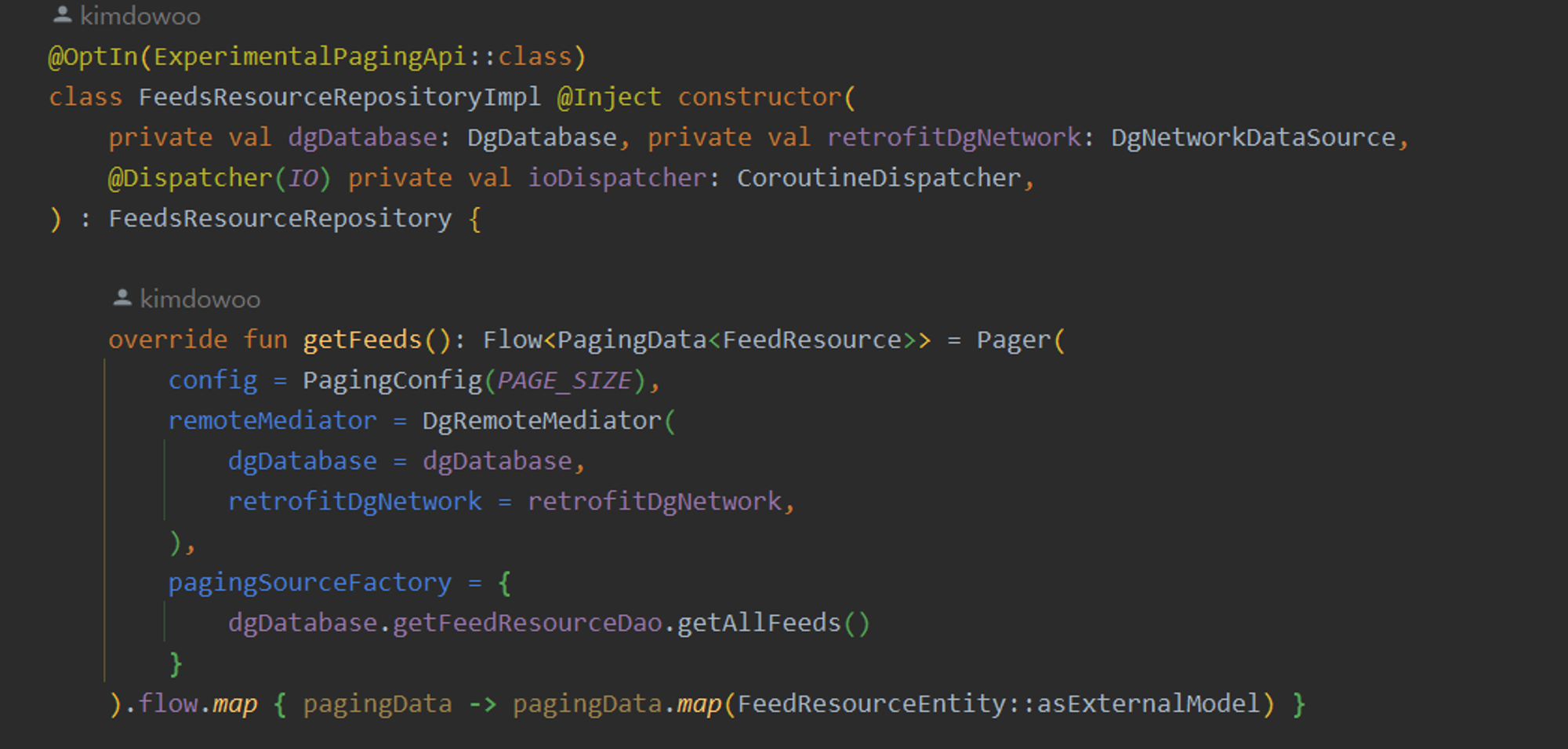
이 때 데이터 소스(데이터베이스, 네트워크 등)의 로직이변경되었다고 합시다.
그렇다면 해당 부분의 Repository의 구현체는 이러한 변경에 영향을 받을 수 있습니다.
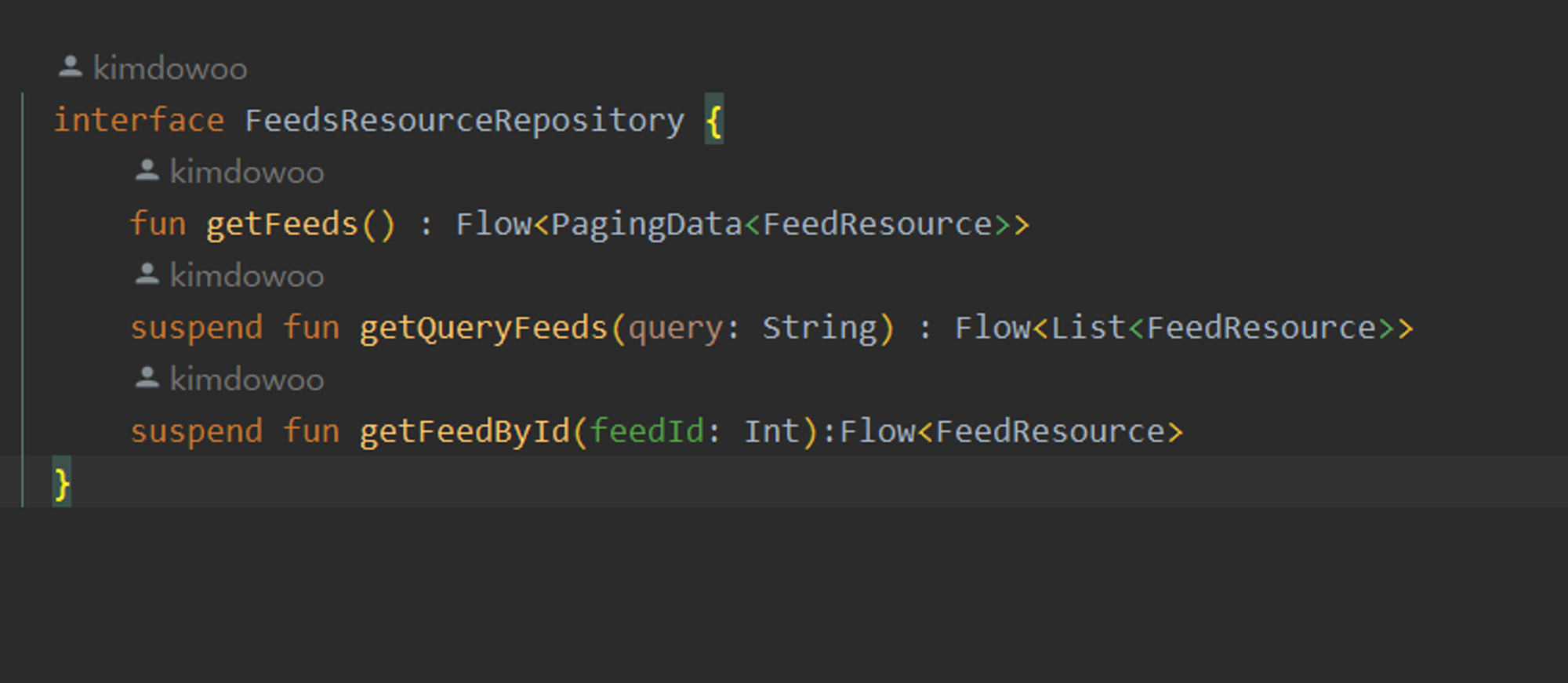
하지만 해당 Repository를 참조하는 ViewModel은 이러한 참조를 구현체가 아닌 Interface로 하게 됩니다.
결과적으로 외부의 변화 특히 DataSource의 변화에 영향이 없는 것을 보장할 수 있습니다.
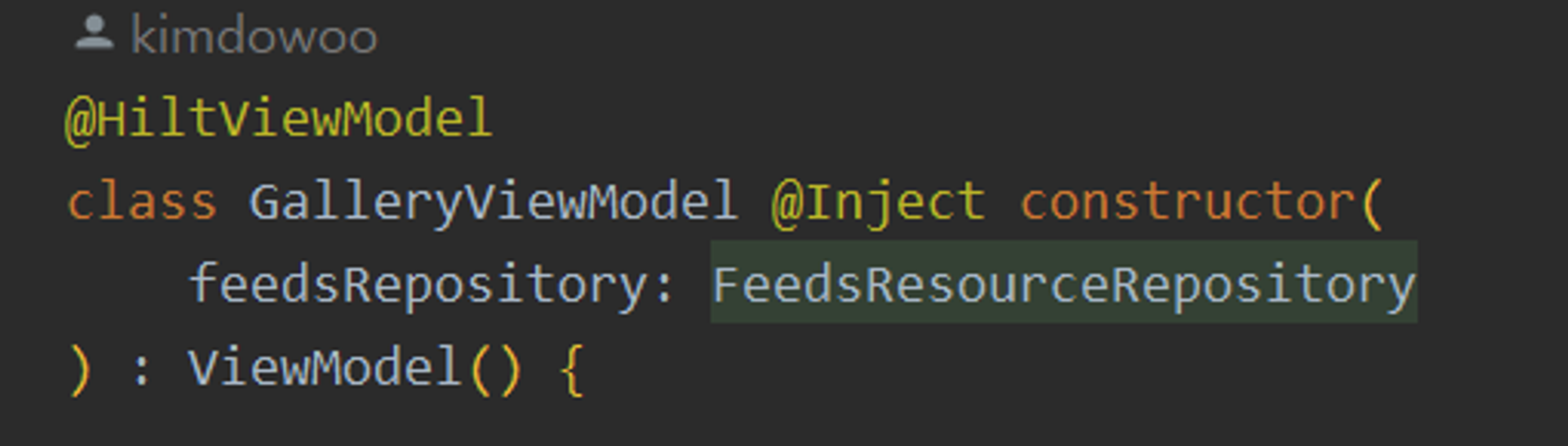
이 패턴을 사용하면 Domain 레이어에서 Interface를 정의 후 실제 Data 레이어에서 실제 구현체를 만들어 View에서는 이러한 Interface에 의존하게 하여 각 레이어간의 의존성 또한 느슨하게 가져갈 수 있습니다.
Mapper
이러한 Domain과 Data의 분리는 Interface로 가능하지만 좀 더 완벽하게 하기 위해서 필수적인것이 Mapper입니다.
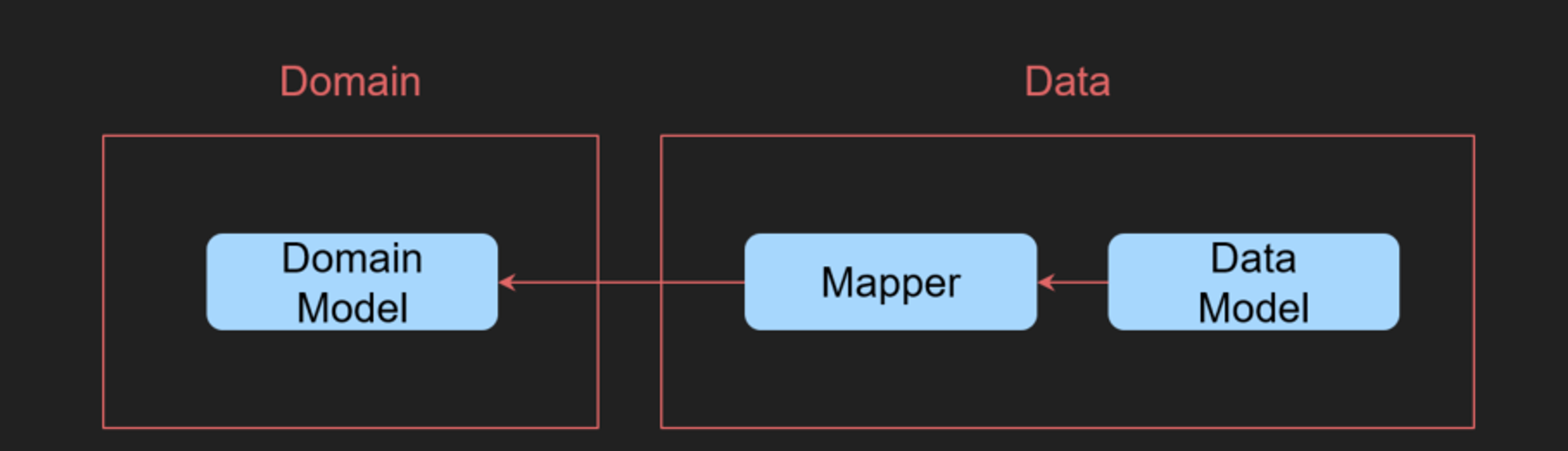
Domain Layer에서 DomainModel은 Database나 Network에서 사용하는 DataModel과 분리되어야 합니다.
즉 DTO, Database Entity와 분리되어야 한다는것인데요
이는 외부 데이터 소스 변화에 좀 더 영향을 최소화 할 수 있는 중요한 부분입니다.
보통 DB Schema를 정의하거나 API 스펙을 정의할 때 그에 특화된 Data Model을 정의하는데 이는 Domain 내부에서 사용하는 Domain Model 다르게 관리해야 함
이러한 Mapper가 있어야 외부 DTO의 변화에 유연하게 대처할 수 있습니다.
즉 Domain 내부의 Domain Model은 외부 Database나 API 스펙이 어떻게 변하든 일관되게 비지니스 로직을 표현해야 합니다.
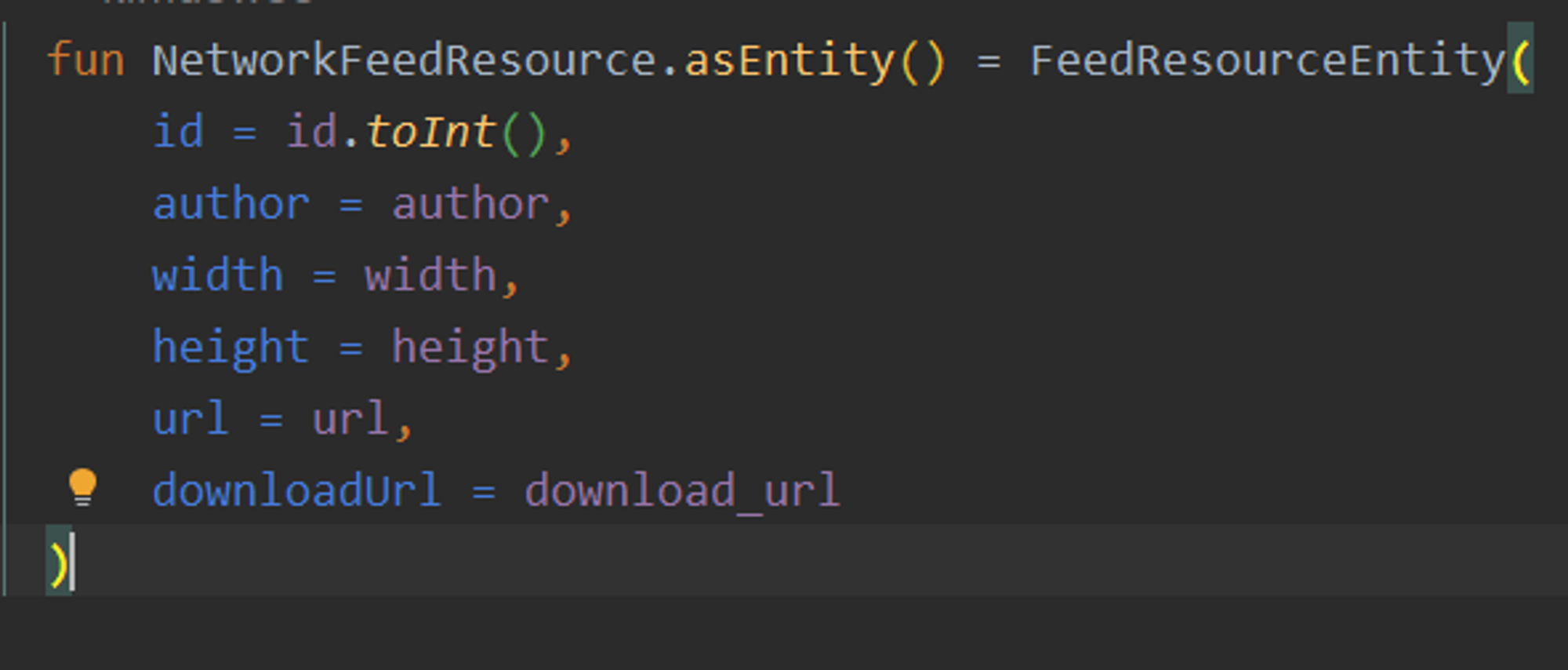
추가적으로 저는 해당 앱에서 offlineFirstApp을 구현하기위해 3개의 Mapper을 썼습니다.
DTO(Network) → Entity(Database) → ExternalModel(View)
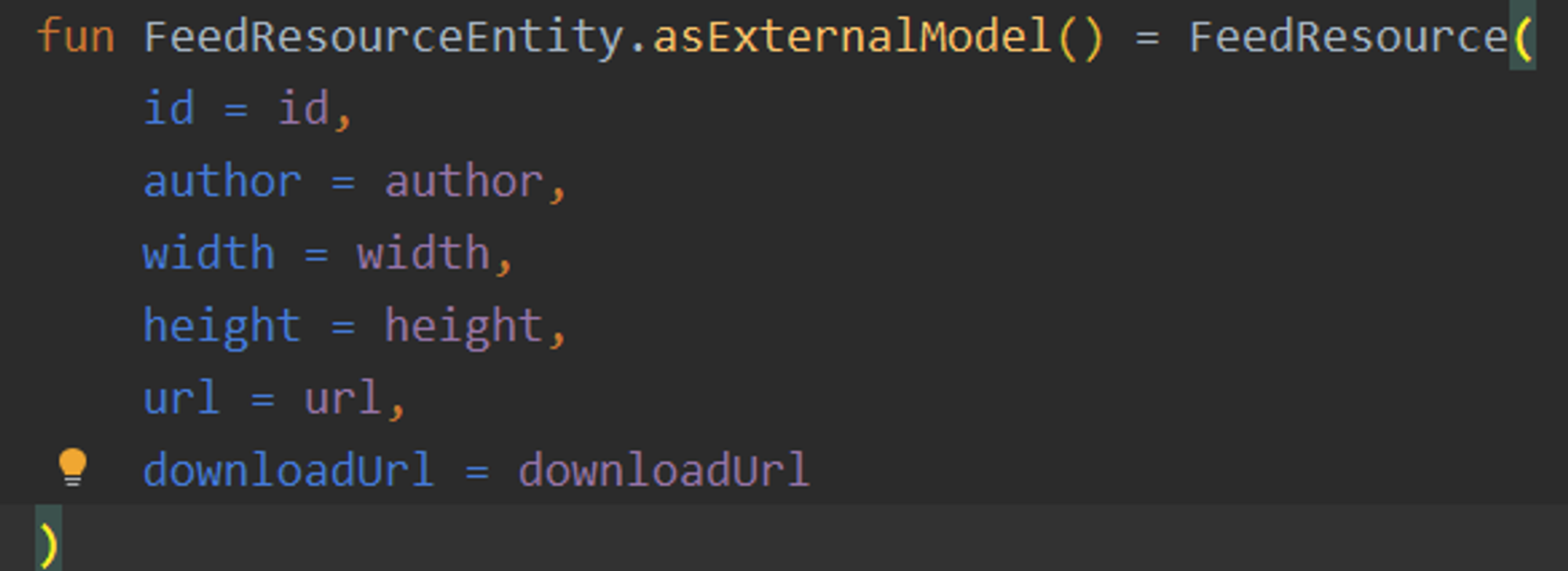
정리
클린 아키택처 및 각종 디자인 패턴에 대해서 제가 적용했던 예시를 통해 개인적인 견해와 이해를 바탕으로 작성해봤습니다.
클린 아키텍처는 절대적인 규칙이 아닙니다. 아키택처는 얼마나 많은 사람과 얼마나 큰 규모의 앱을 구현하냐에 따라 적절히 적용하는게 좋다고 합니다.
앱 크기에 비해 과도하게 아키택처를 적용하면 오히려 코드의 복잡성만 증가시키는 것이죠
아키택처는 경험 및 숙련도 부분에 큰 영향을 가지는 것 같습니다. 초기 부터 이러한 부분을 고려하며 점점 역량을 쌓아가는게 중요한 것이라고 생각합니다.
