연구실 과제로 Efficient and Scalable Graph Pattern Mining on GPUs 논문을 정리한 내용을 적어 보겠습니다.
Efficient and Scalable Graph Pattern Mining on GPUs
제목부터 분석해보겠습니다.
GPU에서 효율적이고 확장 가능한 그래프 패턴 마이닝이라는 뜻 입니다.
그래프 패턴 마이닝이 뭐길래 gpu에서 효율적이고 확장가능 하게 하려는 것 일까요

논문에서는 작은 관심 패턴을 검색하여 큰 그래프에서 고차정보를 추출하는 것이라고 설명하고 있습니다.
이 말을 설명해보자면
빅데이터 시대에 대용량 데이터 분석, 처리 등을 효과적으로 하는 솔루션이 필요해졌습니다.
그러한 솔루션으로 제안된 것이 그래프 패턴 마이닝이고
그래프 패턴마이닝은 대용량 데이터 그래프를 효율적으로 분석하기 위해 작은 관심 패턴으로 관심있거나 중요한 정보를 추출하는 것을 말합니다.
예를 들어 설명하자면
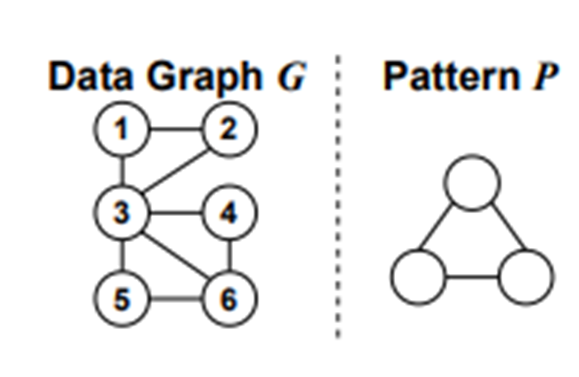
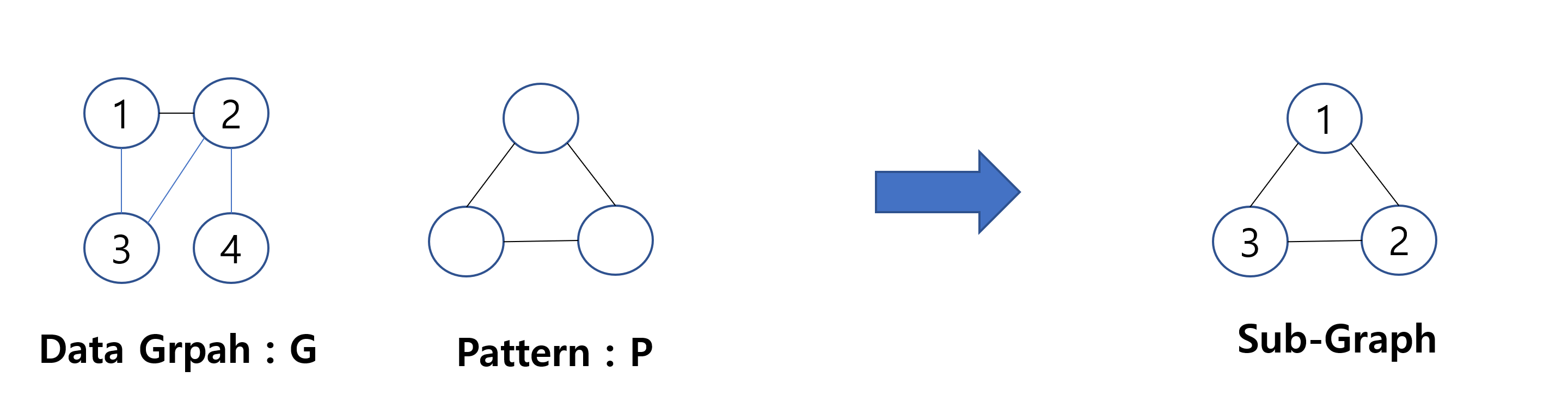
데이터 그래프 G가 주어집니다
예시라서 작지만 현실에서는 매우 큰 대용량 그래프가 주어지겠죠
그리고 관심있는 패턴 P를 정의해서
G에서 P와 일치하는 서브 그래프를 추출해냅니다.
추출하면 어떤 서브 그래프가 나올까요
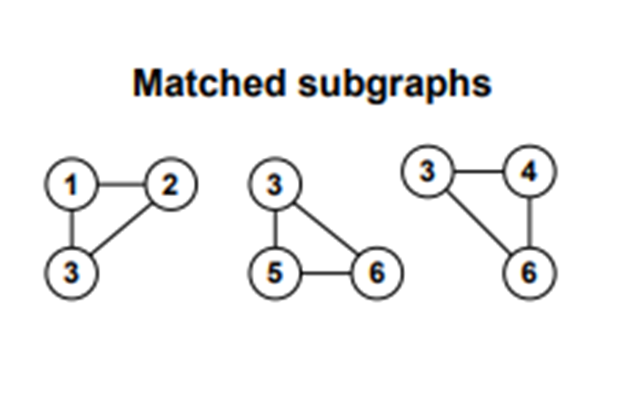
이렇게 나오겠죠
여기서 말하는 서브그래프란
어떤 그래프 G의 정점과 간선의 일부를 제거하여 얻어지는 그래프입니다.
논문에서 말하길 그래프 패턴 마이닝은 단백질 기능 예측, 네트워크 정렬, 스팸 탐지,이상 탐지등에 사용된다고 합니다.
이렇게만 설명하면 어떻게 와닿지 않으니깐 예시를 하나 만들어서 설명해보겠습니다
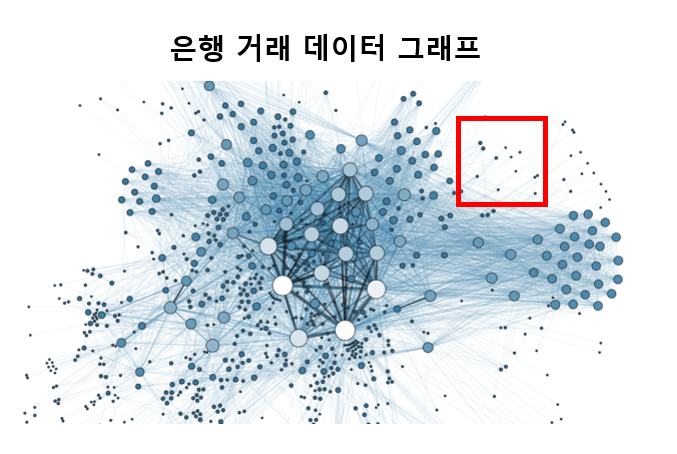
대용량 돈 거래 데이터 그래프가 있다고 합시다
여기서 한 부분을 확대에서 예시를 들어보겠습니다
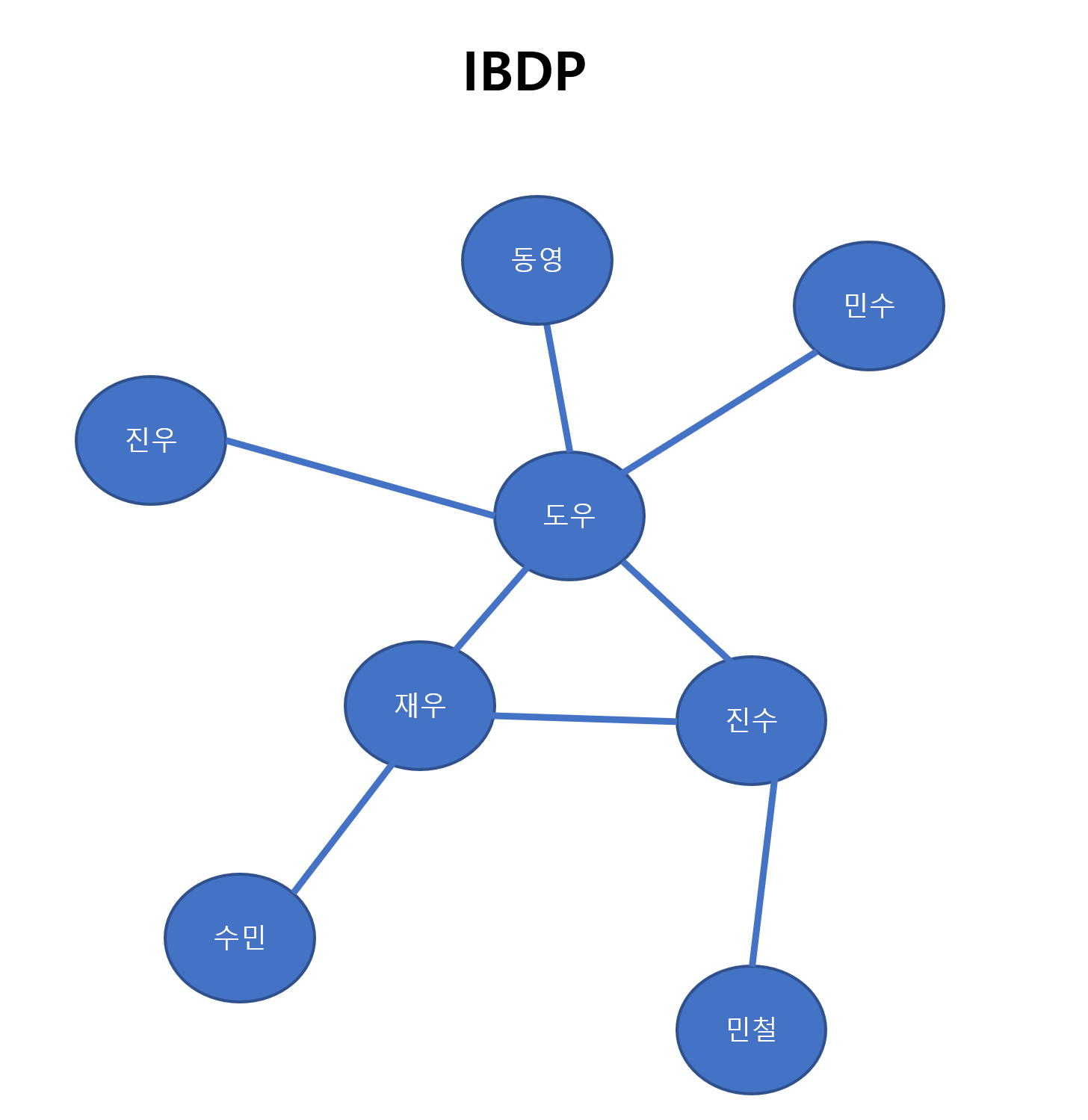
이 그래프에서 그래프 분석을 하려는 사람이 3개의 사이클 패턴을 돈 세탁 의심 패턴으로 정의하고 이것을 전체그래프 G에서 추출합니다.
그러면 어떤 그래프가 나올까요
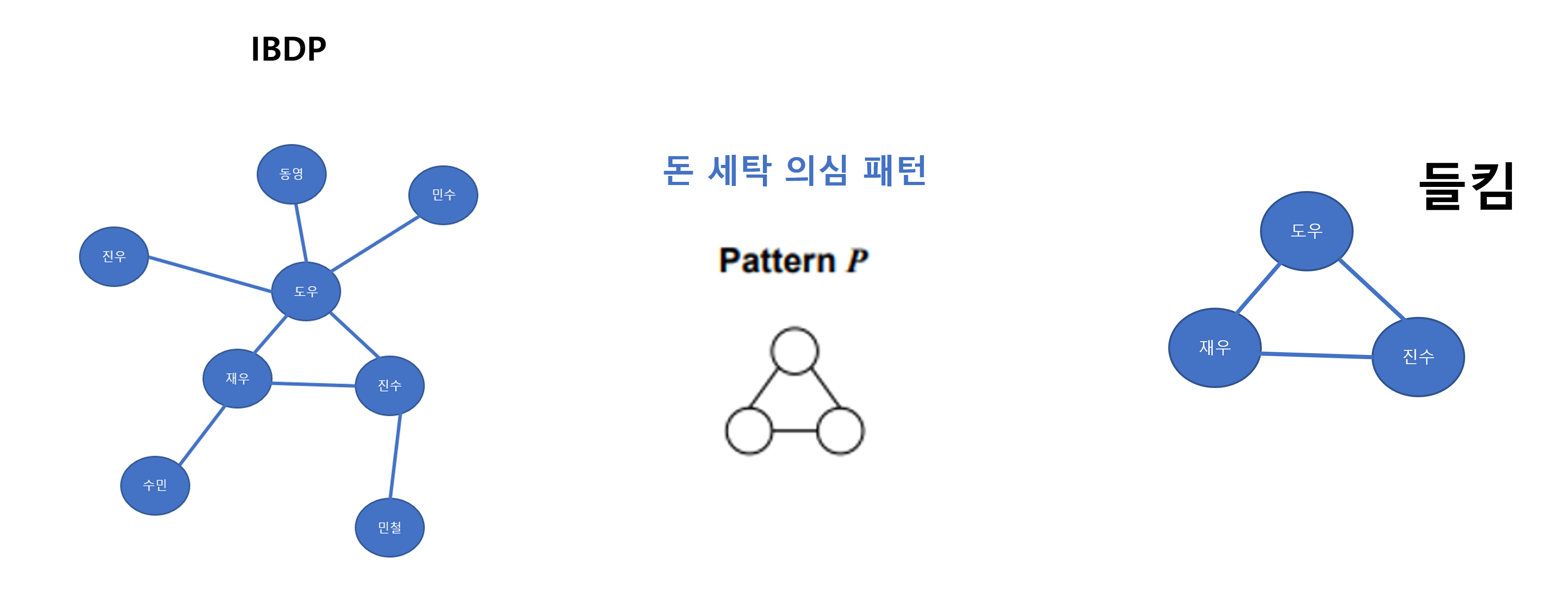
이제 좀 그래프 패턴 마이닝이 이해가 되시나요
논문에서 말하길 GPU는 CPU에 비해 병렬처리에 특화되어 그래프 패턴 마이닝(GPM) 가속에 적합하다고 합니다
하지만 GPU 환경에서 GPM을 효율적으로 구현하는 것은 GPU의 특성 때문에 어렵다고 합니다.
이런 이유가 있다고 하는데 GPU의 특성에 대해 간단하게 설명하고 다시 설명하겠습니다

GPU는 그래픽 카드 내부에 위치한 부품입니다.

GPU는 순차적인 작업에 불리하고 독립적인 작업에 유리합니다
왜냐하면 처리량을 높이는게 목적으로 저렴한 코어를 많이 박았는데 순차적인 작업을 하면 많은 코어를 쓰지 못하고 하나의 코어가 순차적으로 하나의 결과를 기다리고 진행하고 기다리고 진행하고 이렇게 되기때문에 온전히 GPU의 성능을 사용하지 못합니다.
GPU는 모니터 화면의 픽셀의 정보를 처리 할 목적으로 나왔습니다
각 픽셀은 행렬형태의 값을 가집니다.
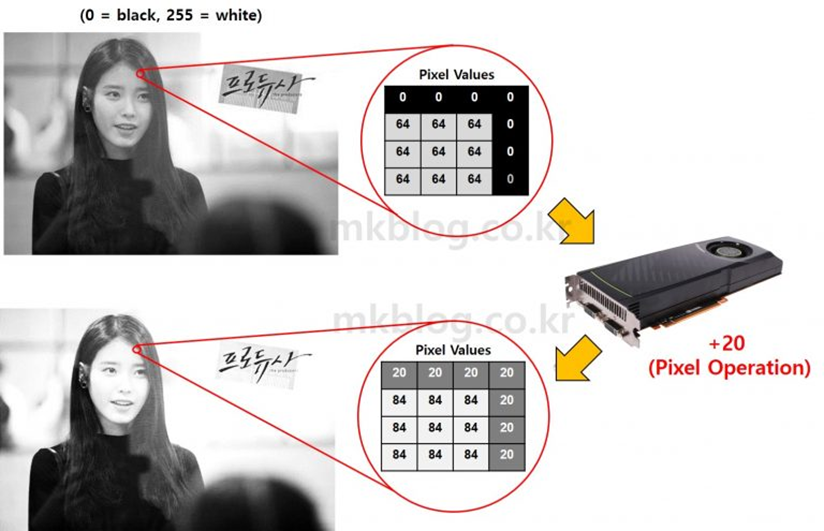
만약 이러한 아이유 화면에서 화면 밝기를 높이고 싶다면 모니터의 각 픽셀에 행렬연산으로 20을 더해주면 됩니다.
이렇게 간단한 행렬연산에 GPU가 사용됩니다.
이제 사람들은 이러한 GPU의 특징을 활용해 대량의 데이터를 처리하고자 하는 욕구 생기기 시작했습니다.
딥러닝, 가상 화폐 채굴과 같은 단순하고 반복적인 수학적 계산을 할 때도 GPU를 활용해 효과적으로 처리하고 싶다 등등의 욕구 말이죠
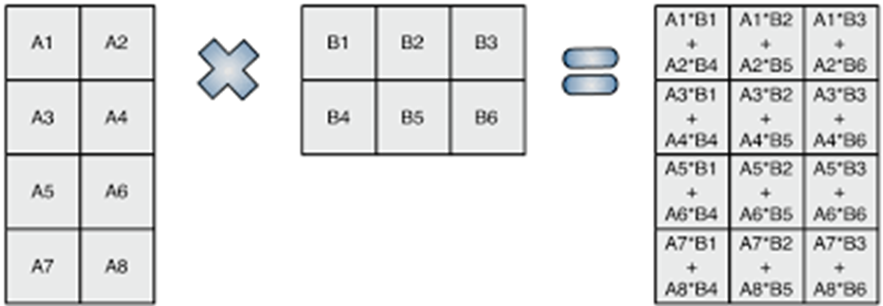
하지만 GPU는 그래픽 처리를 목적으로 만들어졌기 때문에 행렬 연산 방식으로 처리되어야 하는데 많은 데이터를 행렬의 곱셈 방식으로 처리하는 것은 어렵다고 합니다
이러한 불편함을 개선하고자 CUDA, OpenCL 같은 프로그램이 개발되었습니다.

저도 CUDA를 얼마전에 사용했는데 캡스톤 디자인으로 딥러닝이 필요해서 학습을 돌렸는데 너무 느려서 찾아보니 CPU로 학습을 돌리고 있어서 느렸더라고요
그래서 CUDA를 설치하고 환경설정들을 해서 GPU를 잡아서 빠르게 처리하는 속도차이를 실제로 느꼈습니다.
다음으로 Thread 계층에 대해 설명해보겠습니다.
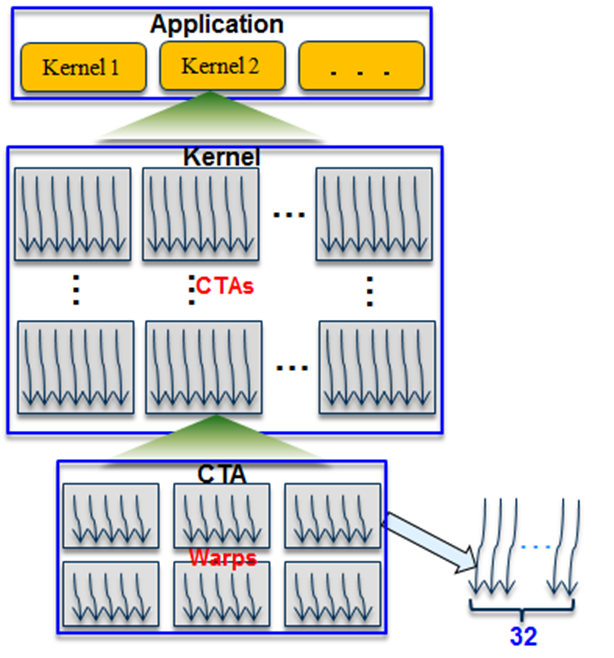
여기서 나오는 용어들이 논문에 종종 등장합니다
100개의 서로 독립적인 스레드를 처리 할 가장 이상적인 방법은 뭘까요?

각 스레드에 각 처리를 병렬적으로 부여 해주면 되겠죠
참고로 스레드는 작업의 최소 단위이고 CORE는 그 작업을 처리하는 장비 정도로 생각하시면 됩니다.
하지만 현실은 대부분의 상황에서 Thread는 Core의 양에 비해 더 많을 수 밖에 없다는 것 입니다.
이것은 곧 Thread의 스케줄링이 필요하다는 것을 뜻합니다.
GPU에서는 이런 스케줄링 단위를 Warp라는 단위로 처리하는데
Warp는 instruction 한 개를 실행하기 위한 최소 단위를 뜻 합니다.
즉 Warp는(32개 Thread)는 같은 하나의 명령어로 동작하는데 이러한 동작 방식을 SIMT(Single Instruction Multiple Threading) 이라고 합니다
Warp를 마치 하나의 작업처럼 생각하고 Warp 단위로 스케줄링하는 것이죠
이제 이 스레드 계층 그림이 조금은 이해가 가시나요?
이제 다시 논문으로 돌아가보겠습니다.
논문에서는 GPU에서 GPM을 효율적으로 구현하는 것은 그래프 희소성, 복잡한 알고리즘, 중간 데이터 관리등의 이유로 정교한 최적화가 필요하다고 합니다.
정교한 최적화가 필요하다
정교한 최적화를 하기위해서는 하드웨어,아키택처,패턴,입력 데이터 그래프 정보가 필요합니다.

논문에서는 이러한 3가지 정보를 활용하여 정교한 최적화를 한 G2Miner 시스템을 제안 했습니다.
어떻게 이러한 정보들을 활용해서 효율적으로 GPM을 구현했는지 알아볼까요?
그래프 패턴마이닝이 어떤 방식으로 동작하는지 알아보면서 알아봅시다..!
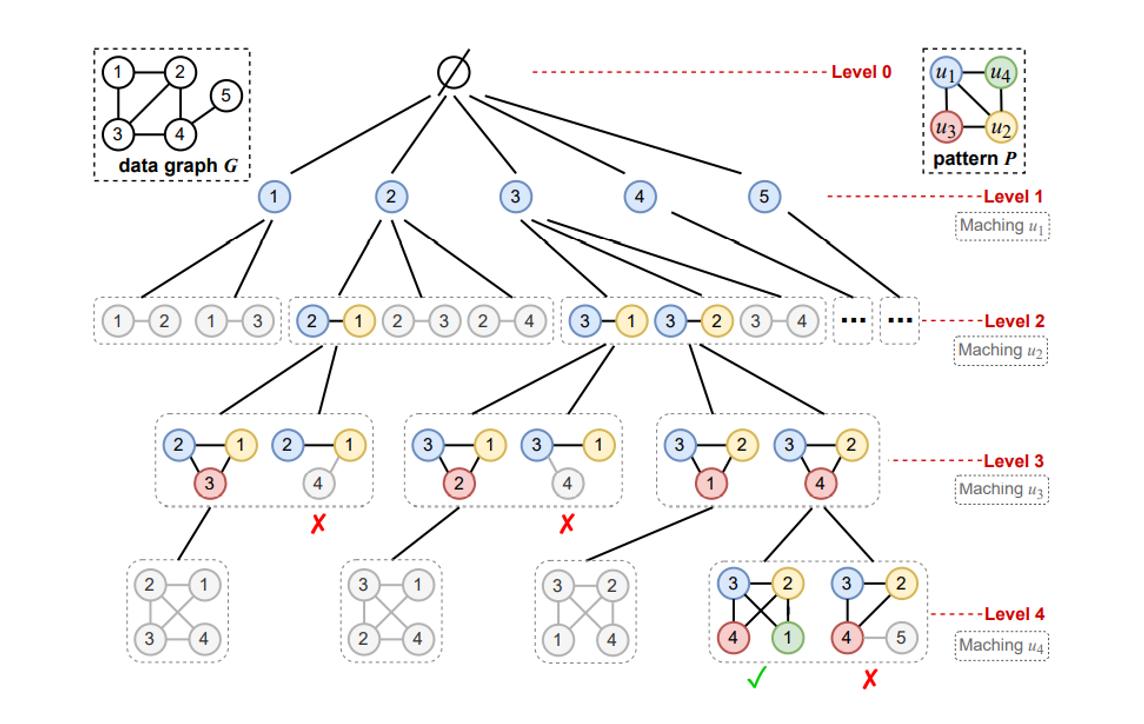
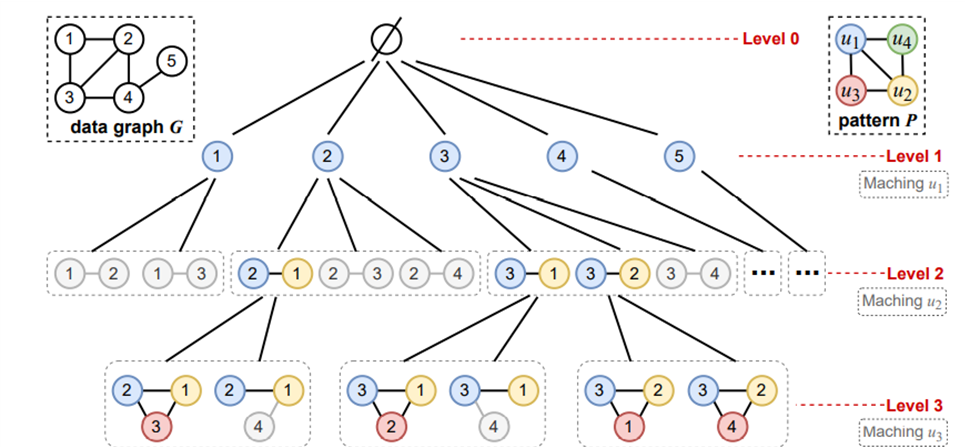
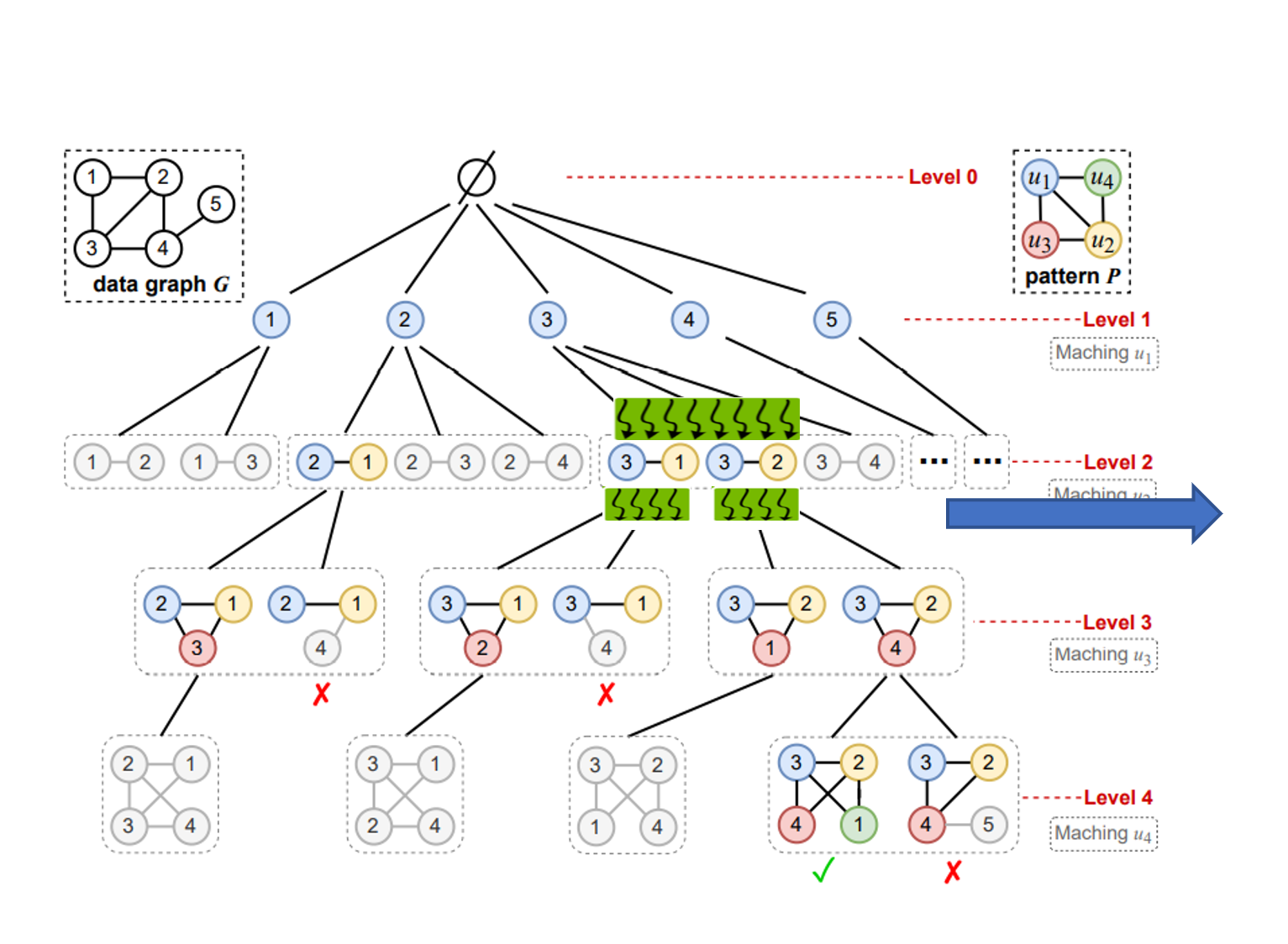
먼저 그래프 예시입니다.
전체 데이터 그래프 G와 패턴 P가 주어집니다.

그래프 패턴 마이닝은 sub-graph 트리를 구축해가며 진행됩니다.
가장 Level0은 루트 노드, 빈 그래프로 모든 그래프의 서브 그래프 Level1은 데이터 그래프의 각 정점으로 구성됩니다.
Level2는 Level 1에서 확장됩니다.
Parent Subgraph에서 근접 정점을 하나 더 추가하면 된다
Level3는 Level 2에서 확장
….
….
언제 까지 확장할까요?
레벨(depth)이 마이닝하는 패턴의 정점의 개수와 동일할 때 까지 확장하면 되겠죠
그림에 보면 x 표시로 가지치기를 하는 부분이 보입니다.
이 가지치기를 할 때 아까 말한 최적화를 위한 정보 중 하나가 사용됩니다.
가지치기란 공간적,시간적 비용을 개선하기 위해 사전에 일치하지 않은 부분을 제거하는 기법인데요
이 가지치기가 필요한 이유는 데이터 그래프가 너무 크면 이 하위 그래프 트리가 너무 커진다는 것 즉, 검색 공간이 너무 커서 시간 문제가 발생하고 하위 그래프 트리 크기(중간 데이터)가 너무 커지면서 메모리 문제가 발생한다.
그리고 또 다른 문제는 중복 열거입니다.
이렇게 상위 서브 트리에서 확장해가면서 패턴을 찾다보면 중복된 서브 그래프가 발생합니다
해당 그림 처럼 그래프 패턴 마이닝을 하면 1-2-3 이 서브그래프 하나만 나오는게 맞지만 실제로 위의 동작방식처럼 하게 되면

이렇게 6개가 나오게 됩니다.
GPM은 완전성을 보장을 해야합니다. 즉, 전체 입력 그래프에서 주어진 패턴과 일치하는 항목을 모두 찾아야 함
또 고유성을 위해 일치 항목을 한 번만 보고해야 함
이러한 특성이 만족되지않으면 GPM의 의미가 없어지겠죠
이러한 symmetry를 breaking을 하면서 검색 공간을 줄이기 위해 최첨단 GPM 프레임은 패턴의 속성을 활용하여 트리를 가지치기를 한다.
이러한 가지치기는 Matching Order와 Symmety Order을 이용해서 한다.
Matching Order(매칭 순서)은 데이터 정점이 패턴 정점과 일치하는 방법을 정의하는 순서
이 매칭 순서는 관련 없는 하위 그래프를 즉석에서 제거하는 데 사용됩니다.
즉 탐색 공간을 탐색 중간에 줄일 수 있습니다.
예를 들어 설명해보자면
매칭 순서를 u1 → u2 → u3 → u4 라고 했을 때
level 2 에서 추가된 각 정점 u3는 패턴 p에 의하면 u1과 u2에 모두 연결되어 있어야 한다.
즉 u3 ∈ N(u1) ∩ N(u2)을 만족하는 u3만 구해지고 만족하지 않은 패턴은 가지치기로 인해 제외된다.
u4에도 똑같은 방식으로 적용하면된다,
효율적인 가지치기를 위해서 매칭 순서를 잘 선택하는게 중요하다. 매칭 순서의 성능을 예측하기 위한 다양한 비용 모델을 제안하고 기대 성능이 가장 높은 것을 택한다.
symmetry Order는 중복 하위 그래프 열거를 제거하기 위해 즉 symmetry를 breaking 하여 고유성을 보장하기 위해 데이터 정점 간에 적용되는 순서입니다.
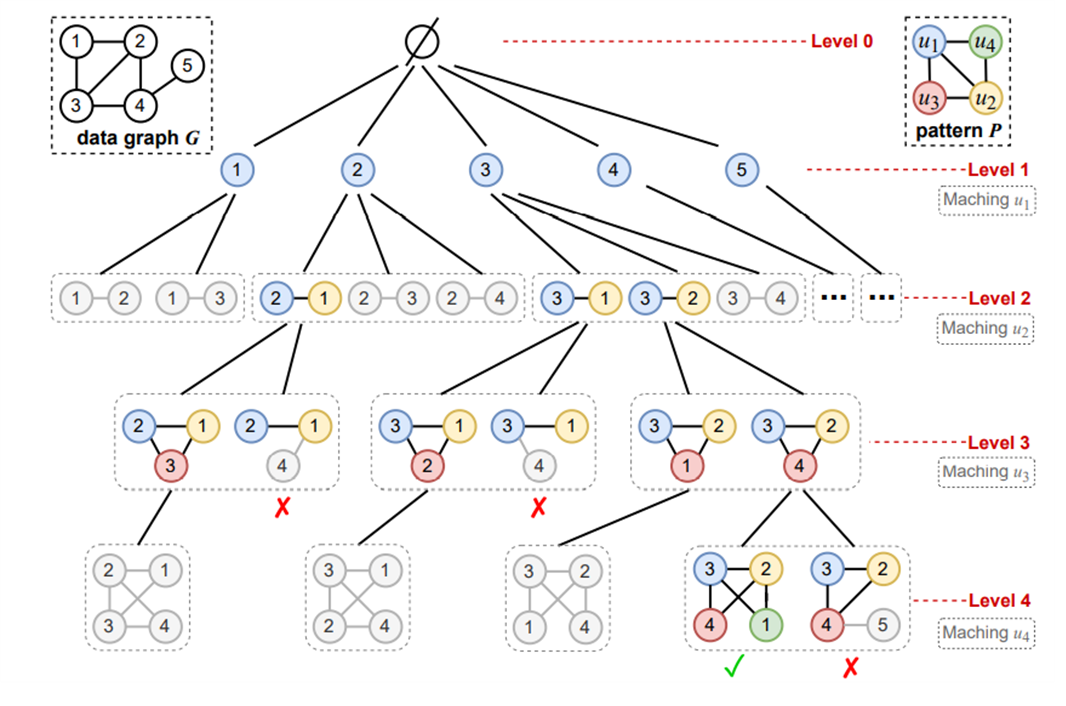
여기서 대칭 순서를 {v1 > v2, v3 > v4} 이라고 해서 예를 들어보자
레벨 1에서 추가된 정점은 레벨 2에서 추가된 정점 보다 더 큰 ID를 가져아 한다.
ID가 뭔지는 잘 모르겠지만 정점마다 ID라는 값이 정해져 있겠죠
따라서 위 그림에서 트리의 레벨 2에서 하위 그래프 {2,1}은 더 확장되도록 선택되지만 하위 그래프 {1, 2}는 가지치기 된다.
이렇게 하여 검색공간을 가지치기하며 중복 열거까지 제거하여
시간, 메모리, 중복 열거 문제를 완화할 수 있습니다.
지금 이 가지치기 기법을 위해 앞에서 말한 3가지 정보 중 패턴 정보가 활용된 것을 알 수 있습니다.
다음으로 아키택처 정보를 활용하여 최적하는 방법에 대해 말씀드리겠습니다.
문제 상황은 이렇습니다

위에서 GPU에 대해 설명했던거 기억 나시나요?
한번 더 정리하고 가자면
GPU는 행렬 곱셈과 같은 알고리즘에 능숙한 벡터 머신이다
Warp(Thread 모음)는 같은 하나의 명령어로 동작한다
Warp를 구성하는 독립적인 Thread를 SIMT(Single Instruction Multiple threads) 방식으로 병렬적으로 처리한다.
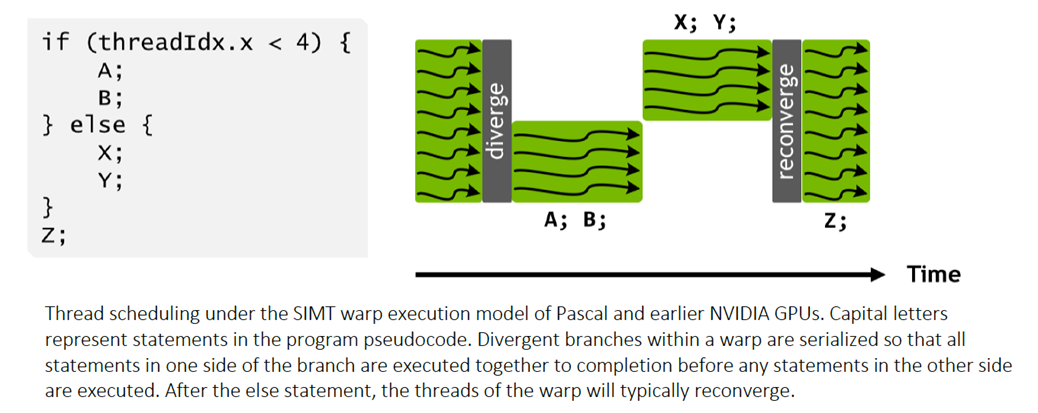
Branch Divergence는 무엇일까요?
하나의 Warp안에 Thread들이 분기로 인해 순차적으로 실행되어 병렬처리를 하지 못하는 문제를 말합니다.
이로 인해 SM(코어)의 몇몇 ALU는 놀게 됩니다 이것은 곧 GPU의 성능저하(Poor Performance)를 야기하게됩니다.
GPM의 경우 Parent에 뿌리들 두고 분기되며 확장
정점마다 이웃이 다르기 때문에 워프의 스레드는 서로 다룬 경로를 택하게 되고 이로인해 Branch Divergence가 발생할 수 있습니다.
논문에서 말하길 그래프 마이닝 아골리즘에서 대부분의 실행 시간(총 실행 시간의 약 80%)은 집합 작업을 처리하는데 사용 되는 것을 발견했다고 합니다.
집합 작업이란 앞서 말한

이 동작을 말합니다.

그래서 집합 작업 처리를 병렬화하고 Branch Divergence를 완화 하기 위해서 논문에서 제안한 기법은 작업을 2단계 세분 병렬화 하자는 것입니다.
1단계는 하위 트리 순회를 위한 워프(Thread 모음)간 병렬 처리
2 단계 집합 작업을 위한 워프(Thread 모음)간 병렬 처리
이렇게 2단계로 세분하하자는 것입니다
1단계로 트리 순회를 위한 병렬처리를 수행하고

이렇게 2단계에서 집합 작업을 수행 할 때 워프의 각 스레드가 하나의 요소를 취하게 하여 GPU 성능을 올리자는 것입니다.
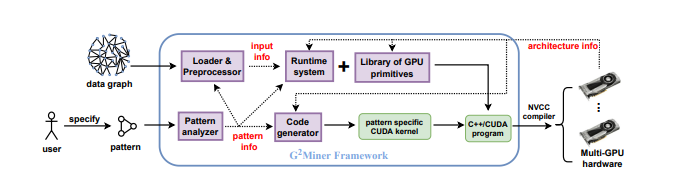
이제 논문에서 제시한 G2miner의 전체적인 구성도를 설명하며 아키택처 정보가 사용되는 흐름을 보고 포스팅을 마치겠습니다.
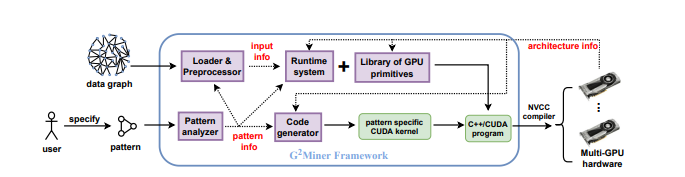
G2Mniner 시스템 프레임워크는
Graph Loader and PreProcessor(그래프 로더 and 전처리)
Pattern analyzer(패턴 분석기)
Code Generator(코드 생성기)
Runtime System(런타임 시스템)등으로 구성된다.
패턴 분석기는 사용자가 제공하는 패턴을 분석하여 유용한 패턴 정보를 추출
이렇게 추출한 패턴 정보를 통해 Matching Order, Symmetry Order와 같은 패턴 별 가지치기 체계를 포함한 검색 계획을 작성
이 검색 계획을 코드 생성기로 공급하고 코드 생성기는 이 제공 받은 검색 계획과 GPU 아키택처 정보를 활용하여 GPU에서 실행할 수 있는 패턴별 Cuda 코드를 생성
입력 데이터 그래프는 그래프 로더&전처리기에 의해 로드되고 전처리된다.
로더는 유용한 입력 정보를 런타임 시스템에 제공
런타임 시스템은 이 입력정보를 사용하여 런타임 결정을 생성한다
예) 그래프 패턴 마이닝 중 생기는 중간 데이터에 대한 메모리 할당 ⇒ 즉, 런타임 시스템은 최적화 담당
패턴 분석기는 유용한 패턴 정보를 로더& 전처리기와 런타임 시스템에 제공
이 유용한 패턴 정보는 패턴별로 로더&전처리기에 의해 전처리되고 런타임 시스템에 의해 최적화
GPU 아키택처 정보는 또한 런타임 시스템에 제공되어 GPU별 최적화를 한다.
패턴 분석기는 사용자가 정의한 패턴 P의 강능한 모든 Matching 순서를 열거하고 비용 모델을 사용하여 최상의 것을 선택합니다
또 각 단계에서 대칭 정점 쌍을 감지하고 그에 따라 symmetry 순서를 정의
패턴 분석기는 matching order와 symmetry order등의 패턴 별 가지치기 체계를 포함한 Search Plan을 작성합니다
이 Search Plan은 코드 생성기에게 공급됩니다.
정리
감사합니다!
