산업협력과제와 졸업작품을하면서 텐서플로우 라이트를 사용할 일이 생겼다..
근데 구글링만 하면서 사용하기에는 너무 삽질을 많이 하게 되서 따로 공부할 필요가 느껴졌다.
그래서 텐서플로우 라이트 책을 샀다 이걸로 공부하면서 배운 내용을 블로그에 정리할 예정이다!
흐에~
책은 한빛미디어의 텐서플로 라이트를 활용한 안드로이드 딥러닝 책을 구매했다.

텐서플로우 라이트란?
텐서플로우 라이트는 기기 내 추론을 위한 오픈소스 딥러닝 프레임 워크이다.
TensorFlow Lite는 TensorFlow의 경량 솔루션으로 모바일 및 임베디드 기기에서 on-device machine learning inference를 가능하게 한다
TensorFlow Lite는 기존의 TensorFlow와 호환되며, 모바일 기기에서 실행 가능한 머신러닝 모델을 제공하며, 성능과 리소스 사용량을 최적화하여 모바일 기기에서의 사용성을 향상
TensorFlow Lite는 안드로이드, iOS, 라즈베리파이 등 다양한 플랫폼을 지원
TensorFlow Lite의 특징
- 경량화된 머신러닝 모델 실행
TensorFlow Lite는 기존의 TensorFlow 모델을 경량화하여 모바일 기기에서 빠르고 효율적으로 실행할 수 있도록 지원한다. 이를 위해 TensorFlow Lite는 텐서 컨버터와 옵티마이저 등의 도구를 제공한다. - 하드웨어 가속
TensorFlow Lite는 CPU, GPU, DSP 등 다양한 하드웨어 가속을 지원한다. 이를 통해 모바일 기기에서 더욱 빠른 머신러닝 모델 실행이 가능해진다. - 사용성 향상
TensorFlow Lite는 간편한 API를 제공하여 개발자들이 모바일 기기에서 머신러닝 모델을 실행하고 관리할 수 있도록 지원한다. 또한, 모바일 기기에서의 성능과 전력 사용량 등을 모니터링할 수 있는 도구를 제공하여 머신러닝 모델의 최적화를 도와준다. - 지원되는 모델 형식
TensorFlow Lite는 TensorFlow 모델 형식을 지원하며, ONNX, TensorFlow Hub, Keras 등 다양한 모델 형식을 지원한다.
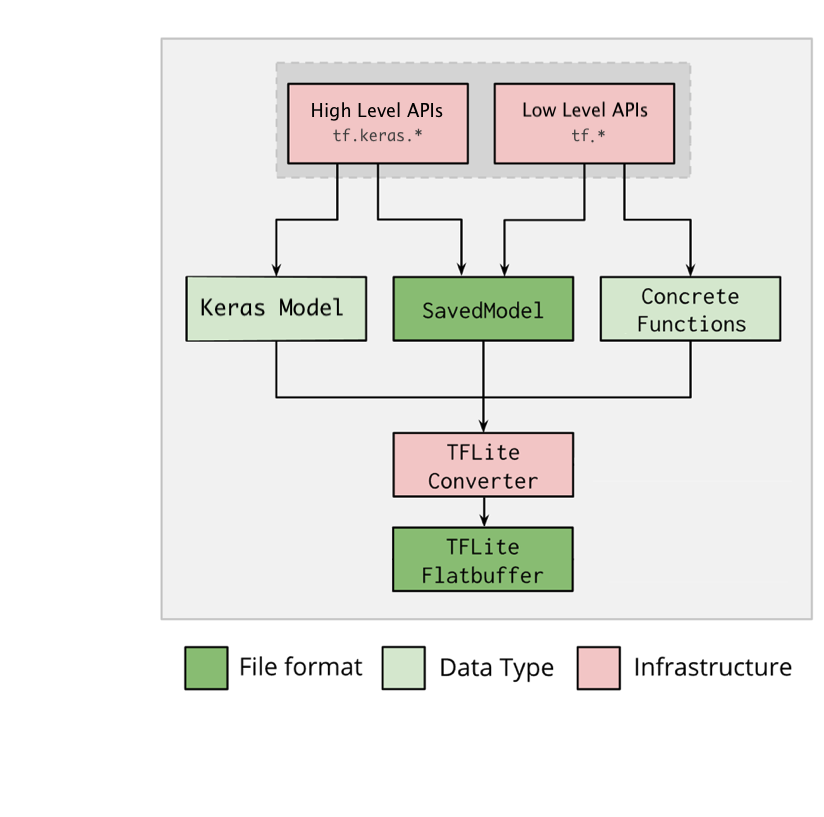
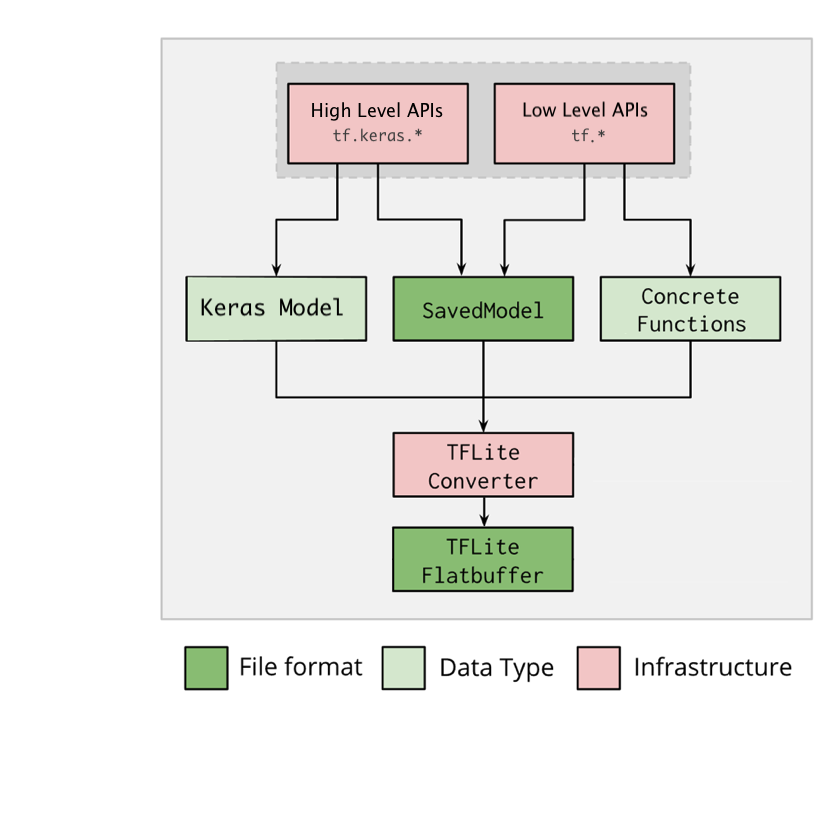
TensorFlow Lite converter
TensorFlow Lite는 Android Neural Networks API와 같은 하드웨어 가속도를 지원
TensorFlow Lite는 TensorFlow 모델을 interpreter가 사용할 수 있는 효율적인 형태로 변환하는 TensorFlow Lite converter를 제공한다.
TensorFlow 모델을 TensorFlow Lite 모델로 변환하는 도구
TensorFlow Lite converter는 SavedModel을 로드하거나 코드에서 직접 만든 모델을 변환할 수 있다.
TensorFlow 모델을 TensorFlow Lite 모델로 변환하기 위해 3가지 주요 플래그를 사용
- -input_shape: 입력 텐서의 크기를 지정
- -output_format: 출력 형식을 지정
- -inference_input_type: 입력 텐서의 데이터 형식을 지정
모바일에서 모델을 사용하는 방법
나는 졸업작품을 진행하면서 서버에 모델을 올려놓고 API 형태로 추론을 사용하는 Cloud-based inference 형태로 진행하였고 산업협력과제는 텐서플로우 라이트를 이용해 On-device inference 형태로 진행하였다.
두 방법의 차이점에 대해 설명하겠다.
On-device Inference
모델을 기기에 넣어서 사용하는 방법, 이 방법은 인터넷 연결이 없어도 작동하기 때문에 사용자의 개인정보를 보호
장점
- 빠른 응답 시간: 모델을 on-device로 구현하면, 인터넷 연결이 필요하지 않기 때문에 모델 추론까지 시간이 걸리지 않는다. 따라서, 빠른 응답 시간을 보장할 수 있다.
- 보안성: on-device 모델은 모델 추론에 필요한 데이터를 로컬에서 처리하기 때문에 데이터 보안이 더욱 강화된다.
단점
- 제한된 자원: on-device 딥러닝 모델을 실행하려면 제한된 자원을 사용해야 한다. 이는 모델 크기, 메모리 사용, 연산 속도 등에서 제약을 받을 수 있으며, 제한된 자원을 사용하므로 대규모 데이터 처리 및 대용량 모델 사용이 어려울 수 있다.
- 하드웨어 호환성: on-device 모델은 모든 하드웨어에서 동일하게 작동하지 않을 수 있다. 따라서, 다양한 하드웨어에서 작동하도록 모델을 수정하거나 하드웨어를 대체해야 할 수도 있다.
- 유지보수 어려움: 서버에서 모델을 서빙하면, 업데이트와 유지보수가 용이하다. 그러나 on-device 모델은 사용자의 디바이스에서 작동하기 때문에, 문제가 발생했을 때 문제를 해결하는 것이 어렵다.
Cloud-based Inference
서버에 모델을 올려놓고 API 형태로 추론을 사용하는 방법, 이 방법은 인터넷 연결이 필요하지만, 서버에서 처리하기 때문에 기기의 성능에 영향을 주지 않는다.
장점
- 대규모 데이터 처리: 서버는 대규모의 데이터를 처리할 수 있는 능력을 가지고 있다. 그렇기 때문에 서버에서 모델을 서빙하면 대량의 데이터 처리가 가능하다.
- 높은 정확도: 서버는 높은 성능의 CPU/GPU를 사용하기 때문에 모델 추론 성능이 높아진다. 또한, 매우 정교한 모델을 만들어 사용할 수 있으며, 새로운 데이터가 추가될 때마다 모델을 재학습할 수 있다.
- 대용량 모델 사용 가능: 서버는 기기보다 높은 성능을 가지고 있기 때문에 대용량 모델을 사용할 수 있다.
- 유지보수 용이: 서버에서 모델을 서빙하면, 모델 업데이트가 용이하다. 새로운 데이터를 추가하거나 모델의 하이퍼파라미터를 변경하는 등의 작업이 쉽다.
단점
- 인터넷 연결 필요: API 통신을 이용하려면 인터넷에 연결되어 있어야 한다. 그렇지 않으면 모델 추론이 불가능하다.
- 지연 시간 발생: 인터넷 연결이 필요하기 때문에 모델 추론까지 시간이 걸릴 수 있다. 이는 응답 시간이 늦어질 수 있는 문제를 초래한다.
- 데이터 보안: 서버에 데이터를 보내야 하므로, 데이터 보안 문제가 발생할 수 있다.
