연결리스트
-
배열의 단점으로는 연속된 공간이 필요하다는 점과
초기 배열의 크기를 모르면 메모리가 낭비될 수 있다는 점이 있다.
컴퓨터 과학자들은 이 단점을 해결하기 위해
다음과 같이 데이터를 분산하여 할당한 다음 연결하는 방식을 고안하였다.
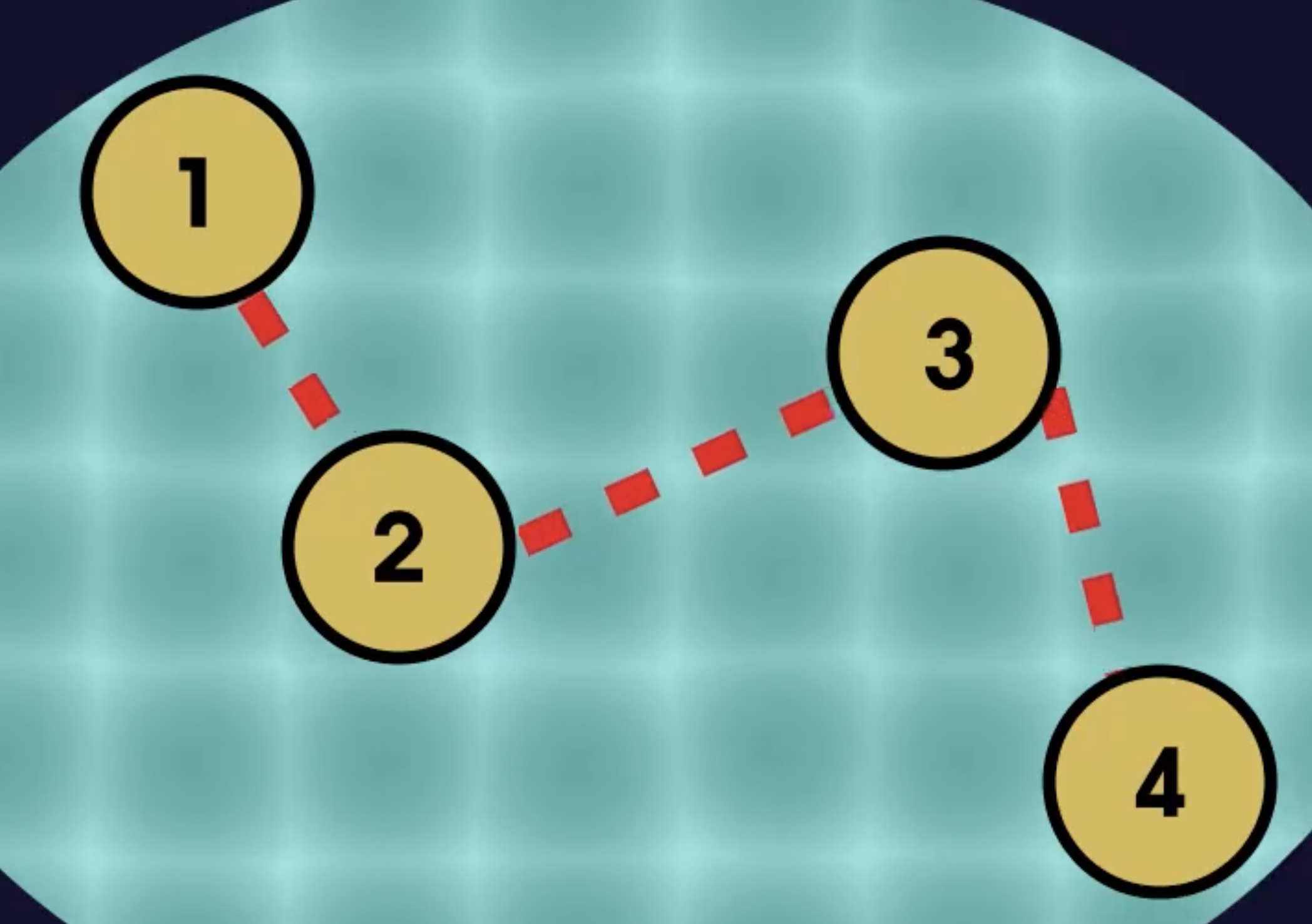
-
이는 노드(Node)라는 것을 만들어 수행하는데 노드의 구조는 단순하다.
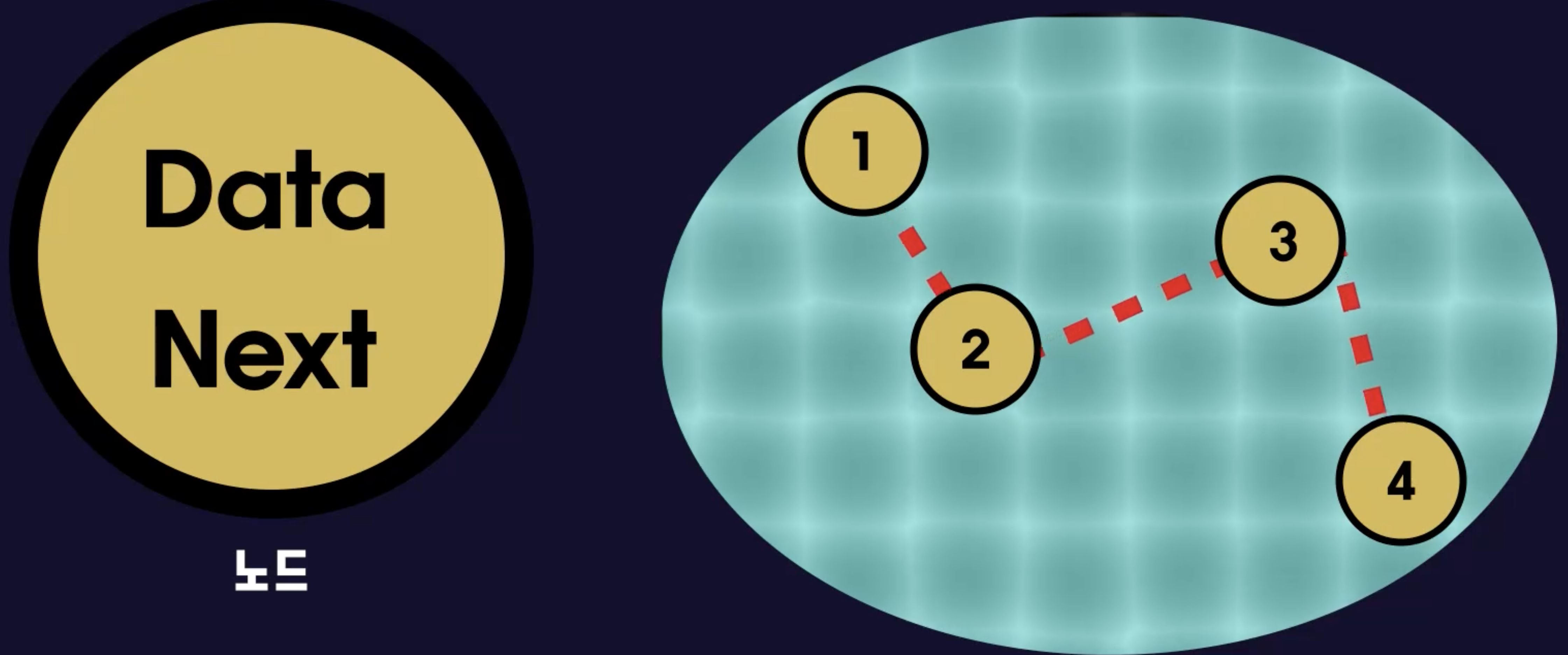
노드는 데이터를 담는 변수 하나와 다음 노드를 가리키는 변수 하나를 가지고 있다.
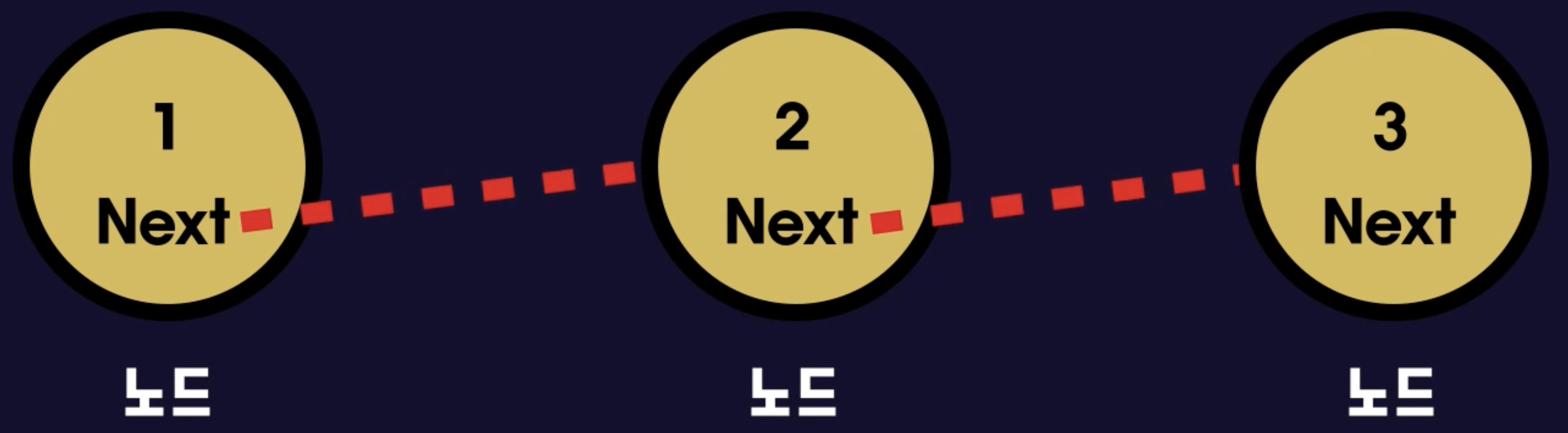
데이터가 필요하다면 필요한 데이터만큼 노드를 만들어 데이터를 저장하고,
다른 노드를 가리켜 연결한다.이러한 구조 때문에 연결리스트라고 부른다.
연결리스트의 특징
- 연결리스트는 첫 노드의 주소만 알고 있으면 다른 모든 노드에 접근할 수 있다.
- 연결이라는 특성 때문에 배열과는 다른 장단점을 가지고 있다.
연결리스트의 장점
-
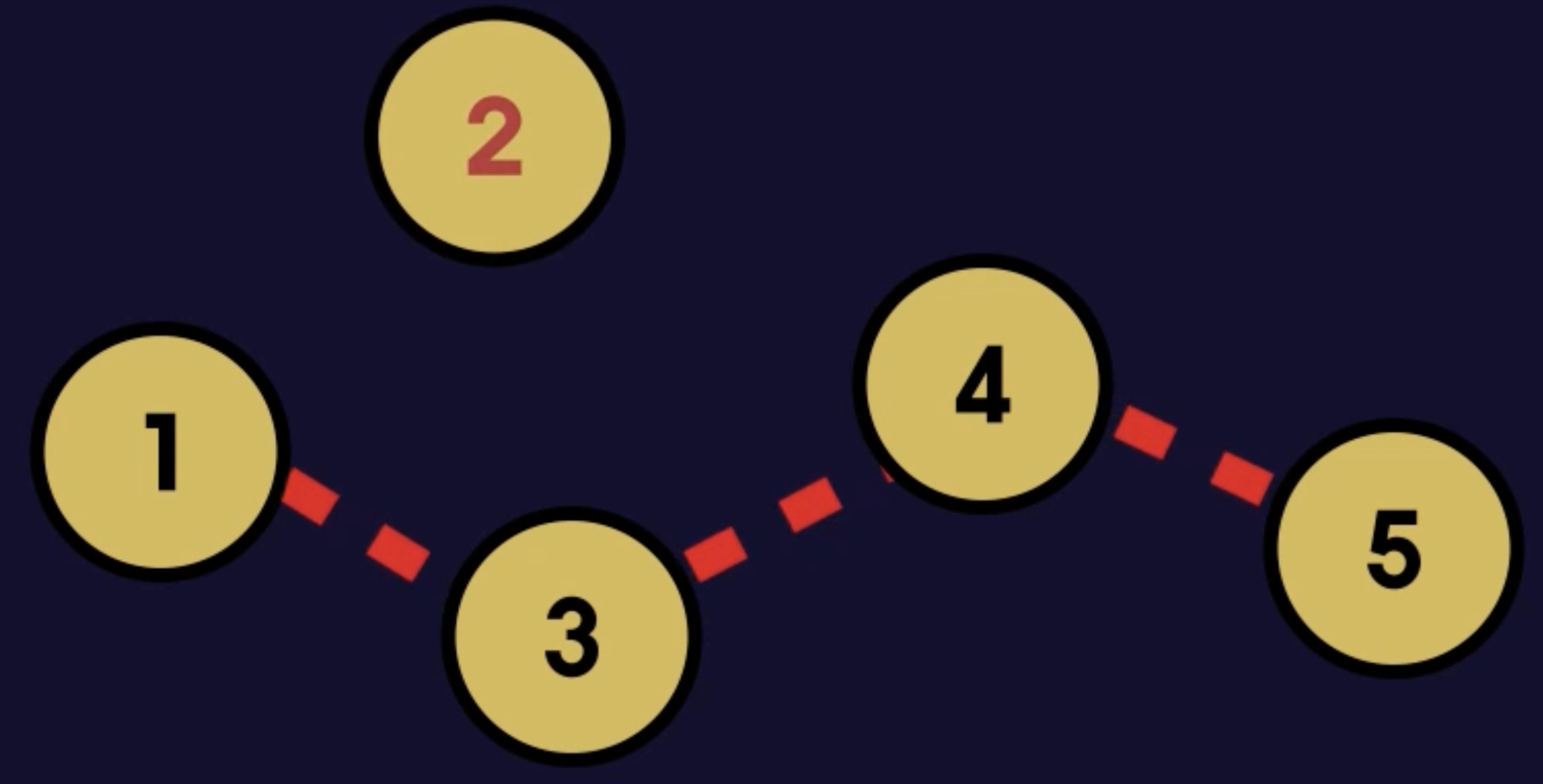
연결리스트에서 데이터를 추가한다면 빈 메모리공간 아무 곳에 데이터를 생성하고 연결해주면 된다.
때문에 배열에서 초기 크기를 알아야 한다는 단점이 연결리스트에는 없다.배열에서는 중간에 데이터를 삽입하려면 그 뒤의 데이터드를 모두 뒤로 밀려나기 때문에
오버헤드가 많이 든다.오버헤드란 어떤 처리를 하기 위해 들어가는 간접적인 처리시간, 메모리를 말한다.


-
반면 연결리스트는 중간에 데이터를 삽입하면 다음 크리키는 노드만 바꿔주면 된다.
연결리스트의 단점
-
배열은 메모리의 연속된 공간에 할당되어있어 시작 주소만 알면 뒤에 있는 데이터 접근이 굉장이 쉽다.
인덱스 크기만큼 떨어진 부분을 찾으면 되기 때문이다.
따라서 O(1)의 성능을 가진다. -
반면 연결리스트는 데이터들이 전부 떨어져 있기 때문에 바로 접근할 수 없다.
노드는 연속 된 데이터가 아니기 때문에 첫번째 노드를 찾고, 다음 노드를 찾고, 그 다음 노드를 찾는
방식으로 데이터를 찾을 수 밖에 없다.
따라서 연결리스트에서의 데이터 성능은 O(n) 성능을 가진다.
정리

이 개념을 앎으로써 프로그래밍을 할 때 두 가지 선택권이 생긴다.
데이터의 수가 자주 바뀌지 않고 참조가 자주 일어난다면 배열을 사용하면 성능이 좋다.
데이터의 삽입과 삭제가 자주 일어나서 데이터의 수가 자주 바뀐다면 연결리스트를 사용하면 성능이 좋다.
