[연구] Chap 1. 금융 데이터 분석과 시각화 with yfinance, plotly
데이터 분석과 시각화는 기계학습의 여러 Task를 하기 앞서 꼭 해야하는 중요한 작업임. 이 노트에서는 금융 데이터 아카이브인 yahoofinance에서 반도체 관련 주식 데이터를 불러와 분석하고 시각화 하는 튜토리얼을 소개하려 함. 특히 python에서 시각화 할 때 주로 쓰는 matplotlib 이 아닌 plotly 라이브러리를 활용하여 좀 더 interactive한 시각화 방법을 보여줄 것임.
💁♂️컨텐츠는 이렇게
- Stock Chart 그리기
- 수익률 상관관계 분석
- 종가 Decomposition
- 종가 회귀분석
- 포트폴리오 최적화
⚠️ 주식 차트 읽는 법이나 관련 용어들을 알아두면 더 좋음
✅활용한 환경: Jupyter Notebook
#핵심 라이브러리
plotly==5.6.0
yfinance==0.2.14
#이외에 활용한 라이브러리 버전들
numpy==1.22.4
pandas==1.4.2
pandas_datareader==0.10.0
scipy==1.7.3
matplotlib==3.5.1
statsmodels==0.13.2🔰준비
라이브러리 불러오기
⚠️ import한 라이브러리들의 활용 순서는 다를 수 있음
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib.dates as mdates
from pandas_datareader import data as pdr
import yfinance as yf
from statsmodels.tsa.seasonal import STL
from scipy import stats
import plotly.graph_objects as go
import plotly.figure_factory as ff
import plotly.express as px
from plotly.subplots import make_subplotsyahoofinance 데이터 불러오기
yahoofinance는 금융 정보 및 주식 시세를 제공하는 온라인 플랫폼임. 주로 외국 주식들의 금융 및 투자 정보를 보여줌. 물론 당연히도 삼성이나 하닉같은 우리나라 메이저 기업들도 저기서 볼 수 있음.
yfinance 라이브러리는 이 yahoofinance 사이트에서의 주식 데이터를 불러오는 여러 함수들을 포함하고 있음. 이 노트에서는 반도체 관련 국내외 주식 10종목을
불러와서 갖고 놀 예정.
#key값은 회사 이름, value는 종목 코드를 의미함!
company_dict = {'Samsung Electronics': '005930.KS',
'SK Hynix': '000660.KS',
'ASML': 'ASML',
'Applied Materials': 'AMAT',
'Intel': 'INTC',
'Tokyo Electron': 'TOELY',
'TSMC': 'TSMC34.SA',
'NVIDIA': 'NVDA',
'Texas Instrument': 'TXN',
'AMD': 'AMD'}2018년 5월 4일부터의 데이터를 불러옴.
yf.pdr_override()
pdr_dict = {}
start_date = '2018-05-04'
for name, symbol in company_dict.items():
pdr_dict[name] = pdr.get_data_yahoo(symbol, start=start_date)
print(name + ' Download Complete\n')🖥️ 아래처럼 결과가 나오면 무사히 불러온 것!
[*********************100%***********************] 1 of 1 completed
Samsung Electronics Download Complete
[*********************100%***********************] 1 of 1 completed
SK Hynix Download Complete
.
.
.
[*********************100%***********************] 1 of 1 completed
AMD Download Complete
Stock Chart 그리기
Stock chart는 주식 시장에서 특정 주식 또는 시장 전체의 가격 움직임을 시각적으로 표현하는 도구임. 보통은 특정 기간 동안의 주가 데이터를 시간 순서에 따라 선, 막대 또는 양봉 형태로 그래픽으로 표현함.
여기서는 그 중에서도 Candlestick과 수익(Return) 그래프를 나타낼 것.
🔍 Candlestick
주식 시장에서 주가 움직임을 표현하는 데 사용되는 시각적인 도구. Candlestick 차트는 개시가격(시가), 최고가, 최저가, 종가 등을 나타내어 한 개의 "캔들"로 표현됨.
🔍 수익 그래프
시작 일자를 기준으로 수익의 변동을 일별로 나타냄. 백분율로 표현.
Candlestick은 plotly.graph_objects에서 Candlestick으로 불러올 수 있음. 이 때, 시가, 최고가, 최저가, 종가 데이터는 표시에 꼭 필요함.
def Candlestick_plotly(name_list):
for i in name_list:
df = pdr_dict[i]
fig = go.Figure(data=[go.Candlestick(
x=df.index,
open=df['Open'], high=df['High'],
low=df['Low'], close=df['Close'],
increasing_line_color= 'blue', decreasing_line_color= 'red'
)])
fig.update_layout(
title=dict(
text='<b>{}</b><br><sup>Stock Candlestick</sup>'.format(i),
x=0.5,
y=0.87,
font=dict(
family="Arial",
size=25,
color="#000000"
)
),
xaxis_title=dict(
text="<b>Date</b>"
),
yaxis_title="<b>Price</b>",
font=dict(
family="Courier New, Monospace",
size=12,
color="#000000"
),
showlegend=False,
margin = dict(l=10, r=10, b=10)
)
fig.show()
# 예시로 삼성전자, 하이닉스 차트 출력해보기
Candlestick_plotly(['Samsung Electronics', 'SK Hynix'])🖥️ 다음과 같이 Interactive한 결과를 볼 수 있음.
왜 이렇게 화질이 깨지지;;
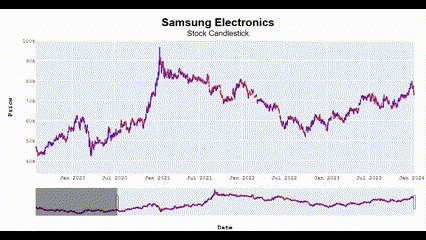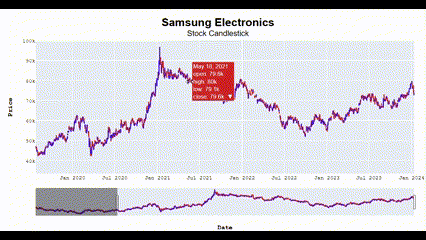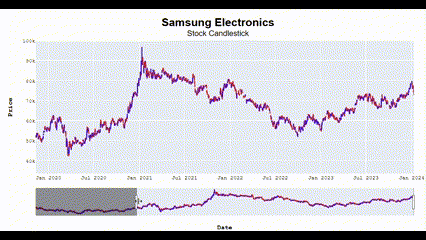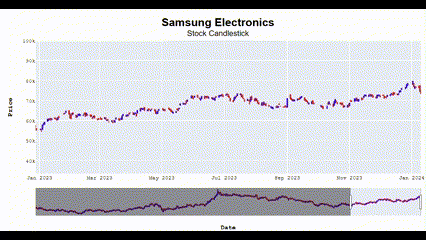
수익률은 그냥 단순하게 오늘 종가에서 어제 종가 뺀 값을 통해 계산함!
기존 주식 데이터프레임에 DPC_CP column으로 수익률을 추가했음.
def Returns():
for name, symbol in pdr_dict.items():
df = pdr_dict[name]
df_dpc = (df['Close']-df['Close'].shift(1)) / df['Close'].shift(1) * 100
df_dpc.iloc[0] = 0
df_dpc_cp = ((100+df_dpc)/100).cumprod()*100-100
df['DPC_CP'] = df_dpc_cp
Returns()수익률 가지고 그래프 그리는 방법은 plotly.graph_objects의 Scatter를 활용함.
def Returns_plot(name_list):
fig = go.Figure()
for i in name_list:
df = pdr_dict[i]
fig.add_trace(go.Scatter(x=df.index, y=df["DPC_CP"], name=i, mode="lines"))
fig.update_layout(
title="Stock Return Diagram", xaxis_title="Date", yaxis_title="Change %")
fig.show()
# 외국 친구들 4개 시범삼아 표시해 봄
Returns_plot(['Tokyo Electron', 'Applied Materials', 'TSMC', 'Intel'])🖥️ 결과는 아래 gif처럼!
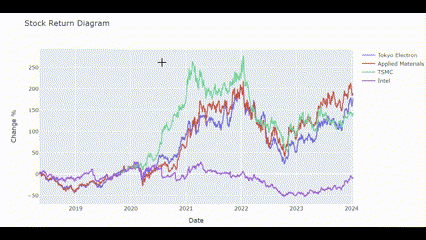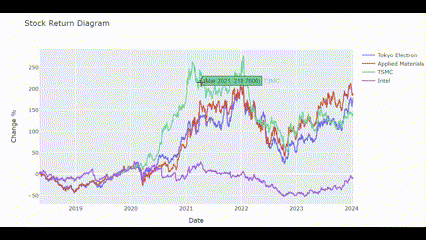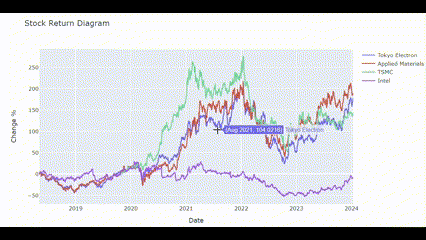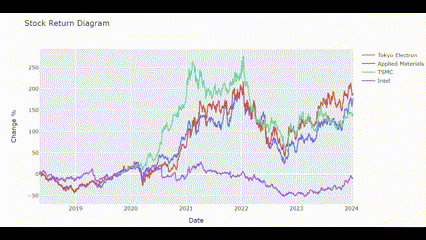
수익률 상관관계 분석
아까 정의한 Return()을 활용해서 각 종목에 수익률을 추가함.
이번에는 그 수익률을 가지고 Correlation Matrix을 그려보려 함.
Matrix는 plotly.express의 imshow로 보일 것!
def plot_corr(name_list):
data_list = {}
for i in name_list:
data_list[i] = pdr_dict[i].DPC_CP
df = pd.DataFrame(data_list)
df.replace(np.nan, 0)
corrM = df.corr()
fig = px.imshow(corrM, text_auto=True, aspect="auto")
fig.update_layout(
title=dict(
text='<b>Correlation Matrix</b>',
x=0.5,
y=0.95,
font=dict(
family="Arial",
size=25,
color="#000000"
)
)
)
fig.show()
# 10개 종목 몽땅 표시해 보기로 함
plot_corr(list(company_dict.keys()))🖥️ 결과는 아래 gif인데, 생각보다 별 거 없음 ㅎㅎ
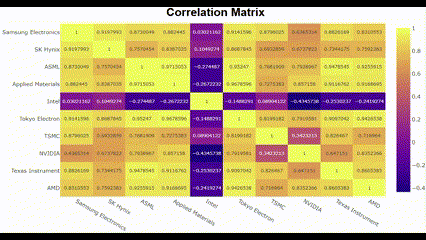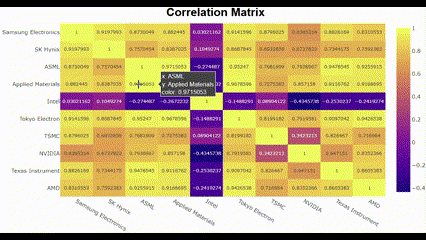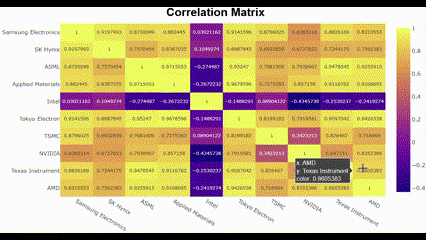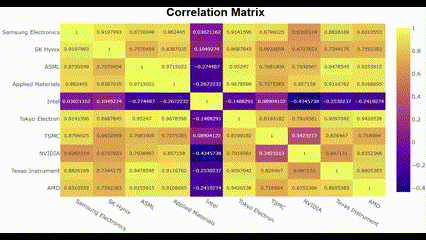
저 gif에서는 화질이 깨져서 잘 안 보이는데, Intel은 다른 친구들하고 상관성이 반대로 나타남. 나머지 9개의 종목은 대체로 강한 양의 상관관계를 나타냄. 아무래도 수집한 기간 동안 Intel에 특별한 이슈가 있어서 다른 반도체 회사들하고 결을 다르게 한 것이 아닐까.
종가 Decomposition
시계열 분해(Time Series Decomposition)은 시계열 데이터를 구성 요소로 분해하여 각 구성 요소의 기여를 이해하고 시계열 데이터의 패턴을 파악하는 분석 기법임. 주로 시계열 데이터가 추세(Trend), 계절성(Seasonality), 순환성(Cyclical), 불규칙성(Irregularity)의 네 가지 구성 요소로 나눔.
여기서는 plotly.subplots의 make_subplots를 통해 interactive한 subplot들을 만들어 보려 함. 각 subplot은 위에서 사용한 plotly.graph_objects의 Scatter를 활용함.
def STL_plot(name_list, Period = 30):
'''
주식 데이터는 주말 데이터가 없기 때문에, 비어있는 주말 데이터는 금요일과
다음주 월요일 데이터를 Interpolate하는 방식으로 보충함. 여기서는
그냥 Linear한 방법으로 Interpolate함
'''
for i in name_list:
df = pdr_dict[i]
interpolate = pd.Series(
df.Close, pd.date_range(df.index[0].strftime('%Y-%m-%d'),
end=df.index[-1].strftime('%Y-%m-%d'),
freq="D"), name="").interpolate()
res = STL(interpolate, period=Period).fit()
fig = make_subplots(rows=4, cols=1, subplot_titles=("Observed", "Trend", "Seasonal", "Residual"))
fig.append_trace(go.Scatter(
x=res.observed.index,
y=res.observed.values,
name="Observed", mode="lines"), row=1, col=1)
fig.append_trace(go.Scatter(
x=res.trend.index,
y=res.trend.values,
name="Trend", mode="lines"), row=2, col=1)
fig.append_trace(go.Scatter(
x=res.seasonal.index,
y=res.seasonal.values,
name="Seasonal", mode="lines"), row=3, col=1)
fig.append_trace(go.Scatter(
x=res.resid.index,
y=res.resid.values,
name="Residual", mode="lines"), row=4, col=1)
fig.update_layout(height=800, title_text= i + " STL Graphs")
fig.show()
# 킹갓 엔비디아님 한 번 보여주시옵소서
STL_plot(["NVIDIA"])🖥️ 결과는 아까거랑 비슷함!
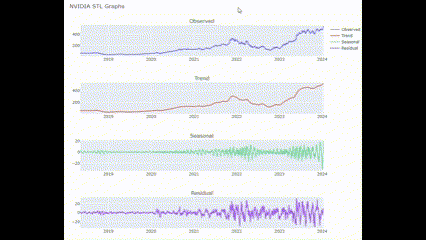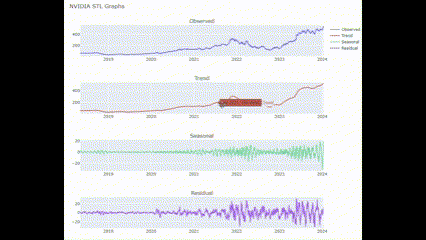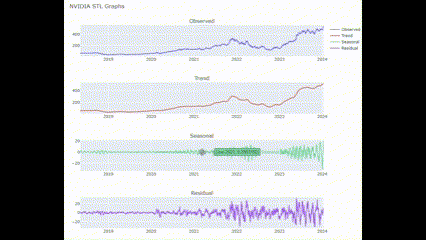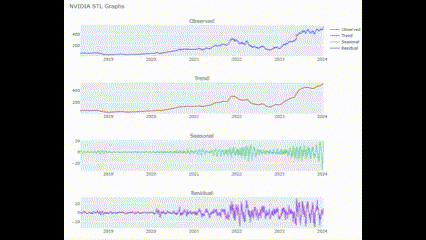
종가 MACD 전처리
MACD(Moving Average Convergence Divergence)는 주식 시장에서 주로 사용되는 기술적 분석 지표임. 이 지표는 빠른 이동평균(Short-term Moving Average)과 느린 이동평균(Long-term Moving Average) 간의 차이를 계산해 주가의 추세 변화를 나타냄.
MACD를 포함해서 다음 5개 항목을 표시해 보려 함.
- Candlestick
- 130일 EMA(지수이동평균)
- MACD
- MACD 시그널
- MACD 히스토그램
🔍 MACD 시그널
빠른 이동평균과 느린 이동평균의 차이에 대한 9일 동안의 이동평균.
🔍 MACD 히스토그램
MACD와 Signal Line 간의 차이를 세로 막대로 표시한 것.
하나에 다 때려박으면 정신 사나워서, Candlestick과 EMA 그리고 나머지 3개를 그룹지어 따로 표시하기로 함. 아까 썼던 Scatter랑 Candlestick을 갖다 썼음.
일단 MACD를 계산해서 데이터프레임에 추가.
def MACD():
for name, symbol in pdr_dict.items():
df = pdr_dict[name]
'''
60일은 빠른 이동평균에 해당하고,
130일은 느린 이동평균에 해당함.
'''
ema60 = df.Close.ewm(span=60).mean()
ema130 = df.Close.ewm(span=130).mean()
macd = ema60 - ema130
signal = macd.ewm(span=45).mean()
macdhist = macd - signal
df['Ema60'] = ema60
df['Ema130'] = ema130
df['MACD'] = macd
df['Signal'] = signal
df['MACDhist'] = macdhist
df['Idx'] = df.index.map(mdates.date2num)
MACD()그리고 차트 그리기 시작!
def MACD_plot(name_list):
for i in name_list:
df = pdr_dict[i]
fig = make_subplots(vertical_spacing = .1, rows=2, cols=1, row_heights=[0.5, 0.5])
fig.add_trace(go.Candlestick(
x=df.index,
open=df['Open'], high=df['High'],
low=df['Low'], close=df['Close'],
increasing_line_color= 'blue', decreasing_line_color= 'red'
, name='Stock'))
fig.add_trace(go.Scatter(x=df.index, y = df['Ema130'], name='Trend-EMA130',
line=dict(color='orange', width=2)))
fig.add_trace(go.Scatter(x=df.index, y = df['MACD'], name='MACD',
line=dict(color='purple', width=2)), row=2, col=1)
fig.add_trace(go.Scatter(x=df.index, y = df['Signal'], name='MACD-Signal',
line = dict(color='green', width=2, dash='dash')), row=2, col=1)
fig.add_trace(go.Bar(x=df.index, y = df['MACDhist'], name='MACD-Hist'), row=2, col=1)
fig.update_layout(xaxis_rangeslider_visible=False,
xaxis=dict(zerolinecolor='black'),
xaxis2=dict(zerolinecolor='black'))
fig.update_xaxes(showline=True, linewidth=1, linecolor='black', mirror=False)
fig.update_layout(
title=dict(
text='<b>{}</b><br><sup>MACD Trending</sup>'.format(i),
x=0.5,
y=0.87,
font=dict(
family="Arial",
size=25,
color="#000000"
)
),
showlegend=True,
margin = dict(l=10, r=10, b=10)
)
fig.show()
# 공학용 계산기 만드는 친구들 거 불러와봄
MACD_plot(["Texas Instrument"])🖥️ 결과는 아시다시피..
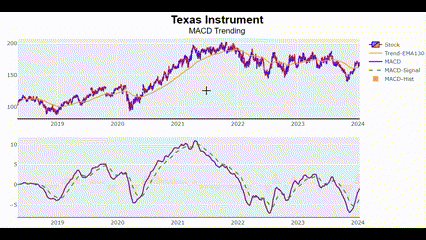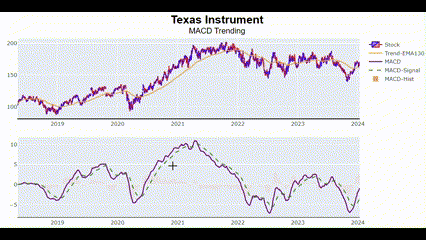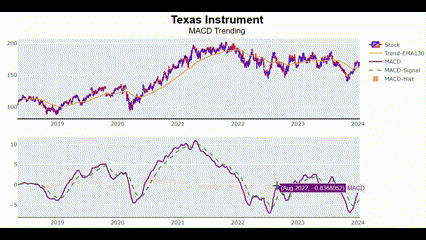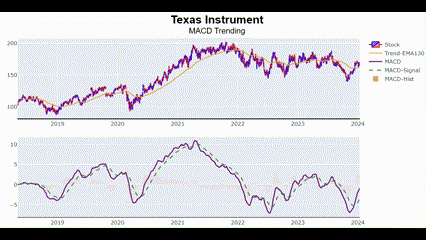
이 차트를 보고 금융 지식이 조금만 있으면 (골든 크로스랑 데드 크로스가 뭔지), 과거에 어떤 시점에 매도했어야 하고 어떤 시점에 매수했어야 하는지를 알 수 있음.
종가 회귀분석
주식 두 종목 가지고 회귀 분석을 해 볼 예정임. 대충 두 친구의 구체적인 상관관계를 파악할 수 있음. 이에 따라서 어떻게 두 친구들을 운용할지 사이즈를 재 볼 수도 있고.
이번에는 아까 썼던 Scatter랑 scipy.stats의 linregress를 써 보려고 함. linregress로 구체적인 회귀 함수식을 표현할 수 있음.
def Scat_and_LR(stock1, stock2):
df1 = pdr_dict[stock1]
df2 = pdr_dict[stock2]
fig = go.Figure()
fig.add_trace(go.Scatter(x=df1["Close"], y=df2["Close"],
mode='markers',
name='{} x {}'.format(stock1, stock2)))
rgr = stats.linregress(df1.Close, df2.Close)
rgr_line = f'Y={rgr.slope:.2f} * X + {rgr.intercept:.2f}'
fig.add_trace(go.Scatter(x=df1["Close"], y=(rgr.slope * df1["Close"] + rgr.intercept),
mode='lines',
name=rgr_line))
Title = f'{stock1} x {stock2} (R = {rgr.rvalue:.2f})'
fig.update_layout(
width=1000,
height=800,
title_text=Title, xaxis_title=stock1, yaxis_title=stock2
)
fig.show()
# 두 미국 친구들의 관계는 어떨까?
Scat_and_LR("Applied Materials", "Intel")🖥️ 결과가 조금 보기 어려운데..
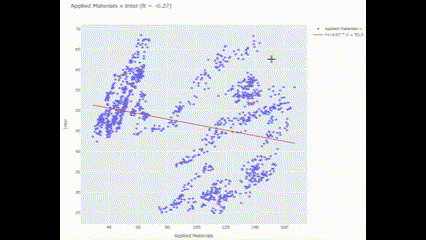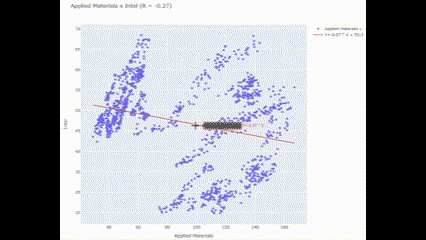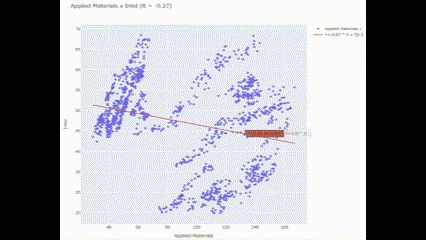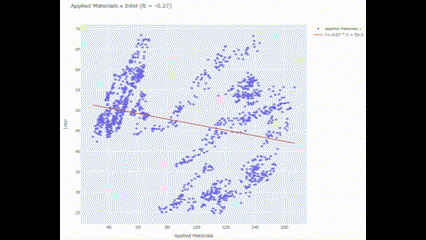
여기서 파란색 점들은 특정 시간에 대한 종가를 나타내고, 빨간 선은 회귀 분석식을 나타냄. 조사기간 동안 Applied Materials와 Intel은 그렇게까지 유의미한 상관관계를 보이지 않는 것으로 나타남. 그만큼 투자 분산 효과가 클 수 있다는 걸 의미!
포트폴리오 최적화
관심있는 종목들을 가지고 포트폴리오를 구성하여 최적화를 수행하면, 투자 목표에 대한 최적의 수익과 리스크 조절을 할 수 있음. 여기서는 4개의 종목을 가지고 포트폴리오를 구성하고, 몬테카를로 시뮬레이션과 샤프지수 등을 통해서 최적의 포트폴리오를 그려보려 함.
🔍 몬테카를로 시뮬레이션
확률적인 변수들의 여러 시나리오를 생성하여 통계적인 결과를 예측하는 수치적인 방법. 보통 초기 가중치는 무작위로 설정함.
🔍 샤프 지수
투자 수익에 대한 추가적인 리스크를 고려하여 투자 성과를 측정하는 지표. 투자 수익률과 리스크(변동성) 간의 균형을 나타내어, 높은 샤프 지수는 단위당 수익에 대한 리스크가 낮다는 것을 의미함.
def Portforlio(name_list):
df = pd.DataFrame()
for name in name_list:
df[name] = pdr_dict[name].Close
# 1년 중 평일이 252일 있다 가정함.
daily_ret = df.pct_change()
annual_ret = daily_ret.mean() * 252
daily_cov = daily_ret.cov()
annual_cov = daily_cov * 252
port_ret = []
port_risk = []
port_weights = []
sharpe_ratio = []
# 몬테카를로 시뮬레이션은 20000번!
for _ in range(20000):
weights = np.random.random(len(name_list))
weights /= np.sum(weights)
returns = np.dot(weights, annual_ret)
risk = np.sqrt(np.dot(weights.T, np.dot(annual_cov, weights)))
port_ret.append(returns)
port_risk.append(risk)
port_weights.append(weights)
sharpe_ratio.append(returns/risk)
portfolio = {'Returns': port_ret, 'Risk': port_risk, 'Sharpe': sharpe_ratio}
for i, s in enumerate(name_list):
portfolio[s] = [weight[i] for weight in port_weights]
df = pd.DataFrame(portfolio)
df = df[['Returns', 'Risk', 'Sharpe'] + [s for s in name_list]]
max_sharpe = df.loc[df['Sharpe'] == df['Sharpe'].max()]
min_risk = df.loc[df['Risk'] == df['Risk'].min()]
fig = px.scatter(df, x="Risk", y="Returns", color='Sharpe')
fig = go.Figure()
fig.add_trace(go.Scatter(x=df["Risk"], y=df["Returns"], mode='markers',
marker=dict(color=df["Sharpe"], colorscale='Viridis',showscale=True),
name="Portforlio"
)
)
fig.add_trace(go.Scatter(x=max_sharpe["Risk"], y=max_sharpe["Returns"], mode='markers',
marker_symbol="star",
marker_color="red",
marker_size=10,
name="Maximum Sharpe"
)
)
fig.add_trace(go.Scatter(x=min_risk["Risk"], y=min_risk["Returns"], mode='markers',
marker_symbol="diamond",
marker_color="orange",
marker_size=10,
name="Minimum Risk"
)
)
subtitle = ""
if len(name_list) > 2:
for i in range(len(name_list) - 2):
subtitle += name_list[i]
subtitle += ", "
subtitle += (name_list[-2] + " and " + name_list[-1])
else:
subtitle += (name_list[0] + " and " + name_list[1])
fig.update_layout(
title=dict(
text='<b>Portforlio Optimization</b><br><sup>{}</sup>'.format(subtitle),
x=0.5,
y=0.87,
font=dict(
family="Arial",
size=25,
color="#000000"
)
),
xaxis_title="Risk",
yaxis_title="Expected Returns",
legend=dict(
orientation="h",
yanchor="top", y=0.99,
xanchor="left", x=0.01
)
)
fig.show()
# 미국 사천왕들을 가지고 포트폴리오를 구성한 결과는?
Portforlio(["NVIDIA", "Intel", "AMD", "Texas Instrument"])🖥️ 2만번의 시뮬레이션 결과는 다음과 같음.
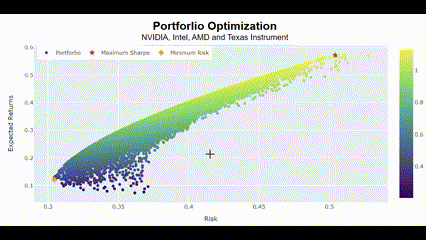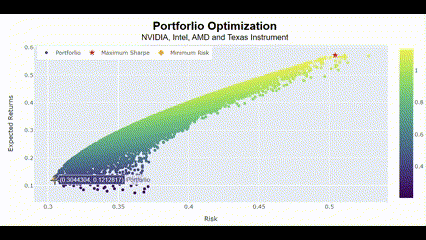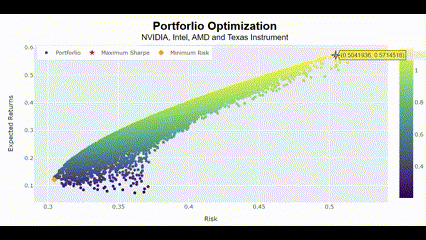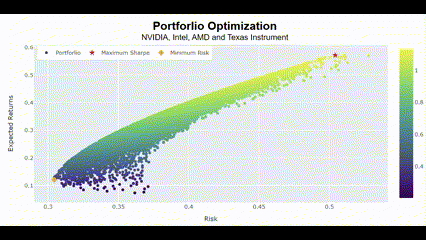
차트가 굉장히 날카로운 이즈리얼 궁(?)을 그리는 건 그만큼 네 종목이 서로 연관성이 크다는 것을 의미함. 그래서 리스크가 커도 보상이 큰 결과를 최적의 포트폴리오라고 선정한 거고.
이처럼 금융 데이터를 yfinance로 불러오고, plotly를 활용하여 금융 데이터 분석 현장에서 활용할 법한 여러 차트들과 분석 방법들을 수행해 봄. 주피터 노트북으로 해서 그런가 렉이 좀 걸리기는 하는데, interactive하게 차트를 볼 수 있다는 점은 굉장히 큰 장점이라고 생각함! 금융 지식이 있는 사람들이 활용하면 더 큰 재미(?)를 볼 수 있지 않을까 기대!
🔛 전체 코드 : 추후 공개
