Secondary Storage
- 메인 메모리(휘발성) 밖에 있는 데이터를 저장하는 어떤 것
- 전원이 나가도 데이터를 유지하고 있음(HDD, SSD)
- instruction의 직접적인 실행이 불가함.
- 직접적으로 데이터를 read/write 불가함.
- 용량이 메인 메모리보다 크고 싸고 느리다.
- 지속적이다(전원이 나가도 데이터를 유지한다.)
디스크는 어지러운 물리적 장비이다.
- 에러가 많다.
- Bad block이 생길 수 있다.(어디에 찍혀서 섹터를 사용하지 못할 수도 있다.)
- Missed seek: 데이터를 잘 못읽을 수도 있다.(기계장치이기 때문에)
OS는 하이레벨 sw로부터 이 어지러움을 숨기는 역할을 하기도 한다.
1. 로우레벨 DD는 배드 블럭이 생겨서 읽기를 했는데 잘 못읽은 것을 감지할 수 있어야 하고 다시 try하는 과정을 거친다.
2. files, databases 등 하이 레벨 abstraction까지 이런 오류들이 안보이도록 해주는 역할을 담당한다.
OS는 디스크 액세스를 하는데 있어 여러 레벨을 거친다.
- user libary에서 액세스할 수 있는 Logical file(filename, block or record or byte)
- Disk logical block은 파일 시스템에서 disk block #로 불린다.
- block layer에 의해 physical disk block(surface, cylinder, sector 몇 번인지 거치는 과정, 실제 disk에 있는 것들을 액세스)
디스크 요청은 실제로 많은 정보를 요구한다.
- cylinder #, surface #, track #, sector #, transfer size 등
- 과거 디스크들은 OS가 이 정보를 정해서 알려줘야 했다.
- 그래서 OS가 모든 디스크 파라미터를 알아야 했다.
but 현재 디스크들은 조금 더 복잡하다.
-> 모든 섹터가 동일한 사이즈를 갖고 있지 않고 섹터들이 다른 곳으로 remapped되어 있는 일도 있다.
현재 디스크들은 하이 레벨 인터페이스를 제공한다.
- cylinder #, surface #, track #, sector #를 제공하지 않는다.
- 운영체제에게 logical block #만 보여준다.
- 디스크가 알아서 logical block을 cyliner/surface/track/sector로 맵핑한다. 운영체제가 할 일이 줄어듦
- OS가 logical block #이 read/write할 것인지만 알려주면 디스크가 알아서 처리한다.
- 결과적으로 디스크의 물리적인 파라미터는 OS로부터 숨겨진다.
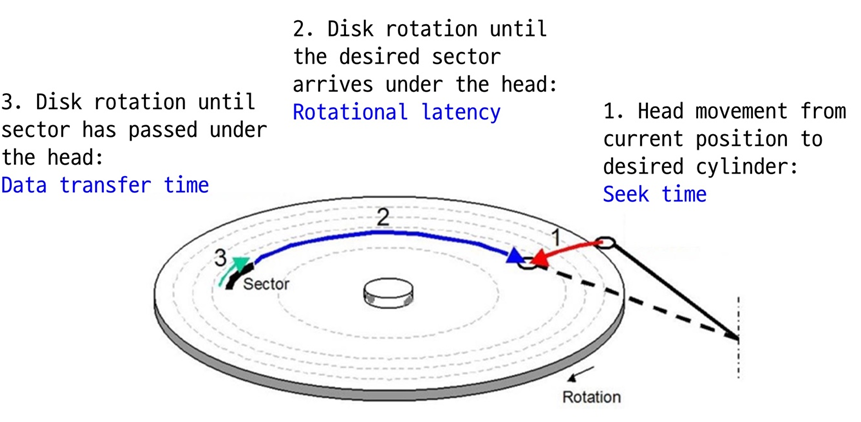
디스크 성능
- Seek(가장 느림)
-> disk arm(헤드)을 적절한 cylinder까지 옮기는데 걸리는 시간
-> 기계적인 arm이 왔다갔다하며 움직여야 하기 때문에 굉장히 느리다.- Rotation(그다음 느림)
-> 특정한 섹터가 헤드 밑에 오도록 디스크 판을 돌리는데 걸리는 시간
-> 디스크의 rotation rate에 이 시간이 결정된다.- Transfer(비교적 빠름)
-> 헤드에서 읽은 다음에 디스크 컨트롤러를 거쳐서 호스트한테까지 전달하는데 걸리는 시간
-> 디스크에서 bytes의 밀도에 따라 이 시간이 결정된다.
디스크 스케쥴링
여러 개의 섹터를 읽어야 하는데 어떤 섹터부터 읽을지 고민 because seeks의 비용이 너무 비쌈
-> 디스크에 read/write job이 요청되었을 때, 디스크는 다른 일을 하고 있는 상황
-> 그래서 이러한 요청들은 디스크 큐(디스크 내부에 있는 작은 버퍼)에 들어간다.
-> queueing을 하게 되면 내부에서 봤을 때 어디부터 읽으면 조금 더 좋을지를 결정할 수 있다.
-> 디스크 스케쥴링은 디스크의 대역폭(디스크가 액세스되는 속도를 높인다.)을 증가시킨다.
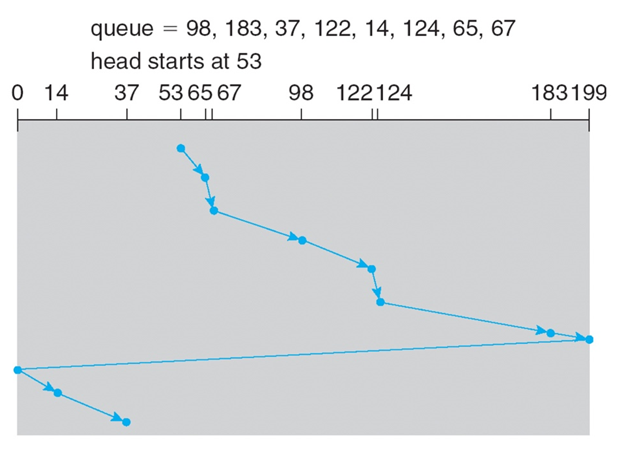
FCFS(FIFO)
들어오는대로 처리해준다.
합리적이지만 seek time이 늘어날 수 있다.

SSTF(Shortest Seek Time First)
seek time이 가장 짧은 것을 먼저 처리해주는 방식
arm의 움직임(seek time)을 최소화할 수 있다.
request rate을 최대화할 수 있다.
단점
-> 중간 블록에 선호도를 줄 수 있다는 것이다.(가운데 쪽에 몰려 있는 블락을 선호해서 빨리 먼저 읽게 되는 현상, non-fair)
-> 따라서 starvation이 생길 수 있다.

SCAN(엘리베이터 알고리즘)
한 방향의 service requests가 끝나면 방향을 바꿔서 올라갔다가 내려갔다가를 반복
waiting times이 불균일하게 삐뚤어질 수 있다.(어떤 경우에는 많이 기다리고 어떤 경우는 조금 기다린다.)

C-SCAN(Circular SCAN)(합리적임)
- SCAN과 비슷하지만 한 방향으로만 움직인다.
- 한 방향 처리해주고 다시 처음으로 돌아와서 처리하고 반복
- waiting time이 균일해진다.
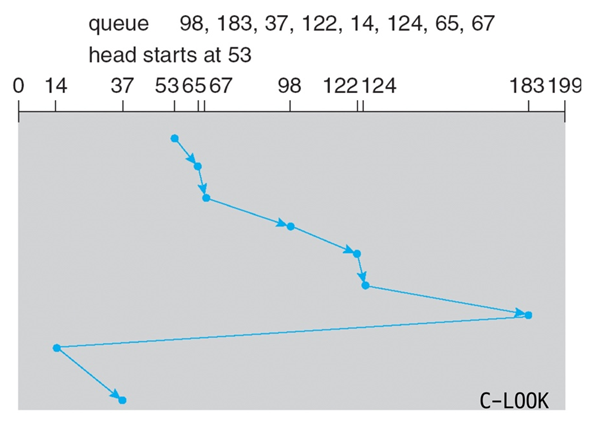
LOOK/C-LOOK(SCAN/C-SCAN과 비슷함)(합리적임)
- arm이 끝까지 가지 않고 마지막 request까지만 간다는 차이점이 있다.
디스크 스케쥴링 알고리즘을 고르는 것
- SSTF는 흔하며 실제로 많이 쓰임(seek time을 줄여줌)
- 디스크 request가 많은 상황에서 SCAN/C-SCAN이 더 좋음
- SSTF or LOOK이 적절한 선택이 된다.
- 성능은 request의 개수와 유형에 달려 있다.
- 디스크 request는 file allocation method에 의해 영향을 받을 수 있다. 따라서 이 HDD를 만드는 사람이 적절하게 두 가지 알고리즘을 잘 조합해서 좋은 알고리즘을 만들 필요가 있다.
- 현대 디스크들은 그들 스스로 디스크 스케쥴링을 한다.
-> 디스크는 자기 레이아웃에 대해 더 잘 알고 있기 때문이다.
-> OS가 내려보낸 스케쥴링 정보를 무시하고 스스로 알아서 한다.
현재 디스크
intelligent controllers
- smart CPU+아주 작은 메모리
- controller 생산자에 의해 만들어진 프로그램을 돌린다.
- 기능
-> Read-ahead: 요청이 오지 않았지만 현재 트랙에 있는 섹터들을 미리 읽는 것이다.
-> Caching: 자주 쓰는 것을 미리 올려놓음
-> Command queuing
-> Request reordering: 자체적으로 seek or rotational delay들을 최적화
-> HW fairlure에서 Request retry
-> Bad block/track identification(인지)
-> Bad block/track remapping : 다시 사용할 수 있게 해줌
I/O Scheduler가 해야하는 것
- 전반적인 디스크 throughput을 향상시킨다.
-> request의 수를 줄이고자 merging requests를 한다.
-> 디스크 seek time을 줄이고자 Reordering and sorting requests를 한다.
- starvation 예방
-> deadline 이전에 requests를 제출한다.- 프로세스 간에 공정성을 제공한다.
- 일정 시간내에 quality of service(QOS)를 보장한다.
