명령어 파이프라이닝
명령어 파이프라이닝이란, 간단하게 CPU가 시간을 알뜰하게 사용해 명령어를 처리하는 방법을 말합니다.
명령어가 처리되는 과정을 비슷한 시간 간격으로 나누면 다음과 같이 나타낼 수 있습니다.
- 명령어 인출 (Instruction Fetch)
- 명령어 해석 (Instruction Decode)
- 명령어 실행 (Excute Instruction)
- 결과 저장 (Write Back)
최근 CPU의 단계는 세부적으로 단계를 나눌수록 속도가 빨라지기 때문에 16단계 정도이다.
CPU는 같은 아래 사진과 같이 같은 단계가 겹치지만 않는다면 각 단계를 동시에 실행할 수 있습니다.
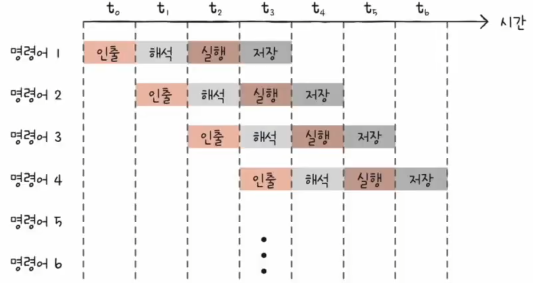
위 사진에 의하면 에서는 4개의 명렁어를 동시에 실행하고 있는 것입니다.
이것은 마치 컨베이어 밸트에 빗대어 설명할 수 있습니다. 이처럼 각 단계가 겹치지만 않는다면 여러 개의 명령어를 겹쳐 실행하는 기법을 말합니다.
파이프라인 사용 이유
만약, 파이프라인을 사용하지 않고 단일 사이클 (Single Cycle)을 사용하면 한 명령어가 끝날 때까지 다른 명령어를 실행하지 못하게 됩니다. 이래 사진처럼 같은 명렁어를 실행하더라도 시간이 매우 길어지는 것을 알 수 있습니다. 이에 현제 CPU에서는 명령어를 동시에 실행하는 기법인 파이프라이닝이 중요한 기술로서 자리매김했습니다.
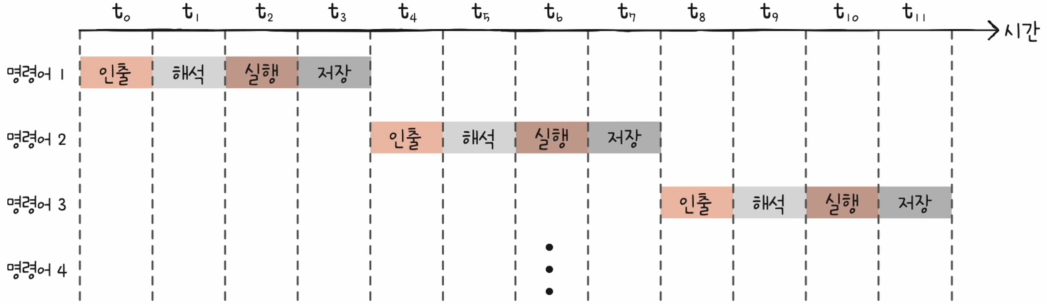
파이프라인에 의한 속도 향상
파이프라인의 단계 수를 , 실행할 명령어의 수는 , 각 파이프라인 단계가 한 클록 주기씩 걸린다고 가정하면 전체 명령어 실행시간 T는 다음과 같습니다.
즉, 첫번째 명령어를 실행하는 데 주기 걸리고, 나머지 개의 명령어 개수만큼 한 주기씩 추가됩니다. 한편 파이프라인을 적용하지 않았을 경우 소요 시간은 단순히 일 것입니다.
따라서 파이프라인의 속도 향상은 다음과 같이 얻어집니다.
명령어의 수 N이 무한히 증가할 때 다음 수식이 완성됩니다.
즉, 파이프라인의 단계 수만큼 속도가 빨라지는데 경우에 따라 이 효과를 100% 충족할 순 없습니다.
파이프라인 해저드 (Pipeline Hazard)
명령어 파이프라인이 CPU 성능향상에 실패하는 경우를 파이프라인 해저드(위험)라고 합니다.
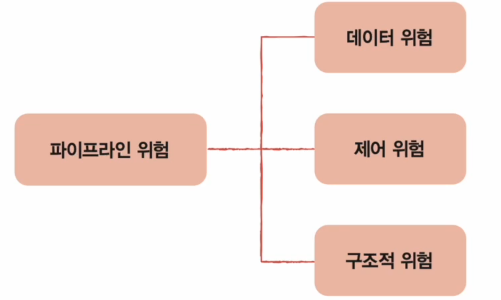
파이프라인 해저드의 3가지 종류
1. 구조적 해저드
- 하드웨어가 여러 명령들의 수행을 지원하지 않기 때문에 발생, 자원충돌(Resource Conflicts)
- 데이터 해저드
- 명령어 간의 의존성에 의해 발생
- RAW, WAR, WAW 해저드가 존재
- 제어 해저드
- 분기(jump나 bruch 등) 명령어에 의해서 발생
(분기를 결정하는 시점에 잘못된 명령어 파이프라인에 있을 경우)
파이프라인 해저드의 원인과 해결 방법
구조적 해저드 (Structural Hazard)
폰 노이만 구조에서 발생하는 해저드로 자원 충돌이 발생하여 H/W가 여러 명령들의 수행을 지원하지 않으면 아래 사진과 같은 상황이 발생합니다.
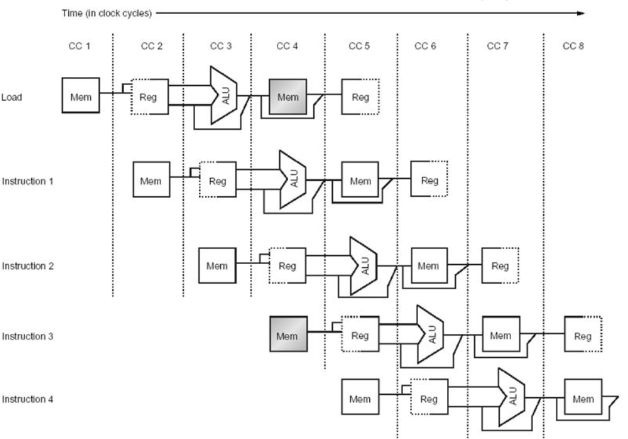
CC에서 Load명령어와 Instruction 3 명령어가 한순에 메모리를 동시에 사용해 충돌현상이 발생합니다.
해결방안
| 구분 | 설명 | 비고 |
|---|---|---|
| 하드웨어/리소스 추가 | 리소스 혹은 하드웨어를 추가하여, 메모리에 동시 접근 | H/W 병렬 구성 |
| 하바드 아키텍처 사용 | 데이터 명령어를 각각의 메모리에 분리하여 동시 접근 | 데이터와 명령어 메모리 분리 |
| 메모리 인터리빙 | 메모리 모듈별로 병렬 접근 | 인터리빙 통한 H/W 병렬 구성 |
| 지연 | nop명령어를 추가, 파이프라이닝 수행 일시정지 | nop 명령어 수행 |
데이터 해저드 (Data Hazard)
현재 수행중인 명령어가 이전 명령에 종속되어 명령의 결과를 기다려야 함으로서 발생하는 파이프라인을 말합니다. 데이터 해저드의 종류로 RAW(Read After Write), WAR(Write After Read), WAW(Write After Write) 가 있습니다.
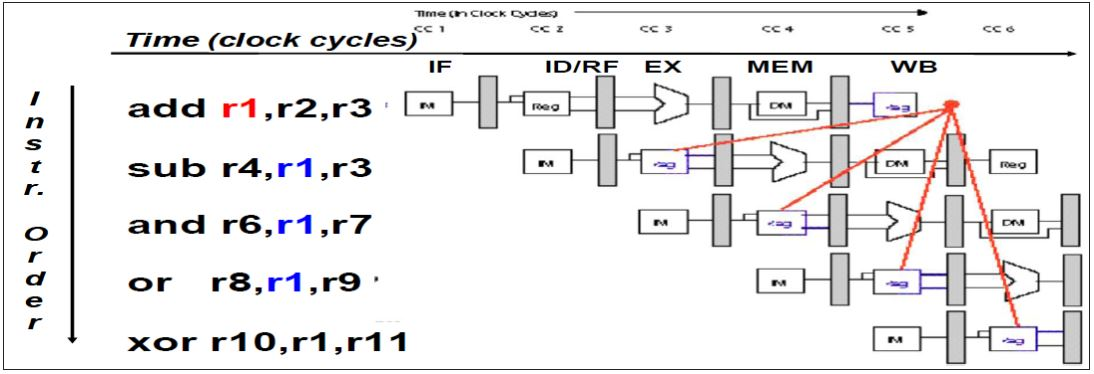
해결방안
| 구분 | 설명 | 비고 |
|---|---|---|
| 전방전달 | 레지스터 파일에 반영되기 전에 수행(EX) 단계에서 게산된 결과를 다음 인스트럭션의 수행단계로 전달 | H/W 추가 필요 |
| 지연 | 컴파일러 수준에서 해저드 발견, NOP 명령어 삽입 | nop 명령어 삽입 |
| 비순차 실행 | 접근 중인 데이터와 관련 없는 명령어를 삽입 | 컴파일러 수준 코드 실행 변경 |
| 프로그래밍 | 변수를 늘리거나, 계산이 완료된 후 한번에 실행 | 레지스터를 고려해서 프로그래밍 |
제어 해저드 (Control Hazard)
제어 해저드는 분기가 결정된 시점에 수행되지 않을 명령어가 파이프라인에 존재할 때 발생합니다.
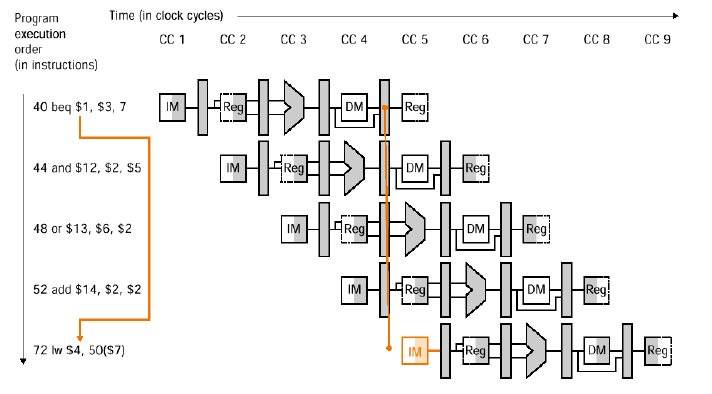
해결방안
| 구분 | 설명 | 비고 |
|---|---|---|
| 분기예측 | 명령이 분기하는지 미리 예측 | 정적 예측, 동적 예측 |
| 브랜치 지연 | 컴파일러가 분기문 발결 시, NOP 혹은 분기와 관련 없는 명령을 추가해 순서 재배치 | 비순차 실행과 유사 |
| 프로그래밍 | 조건분기 최소화 | Inline 메소드 사용, Loop unrolling사용 |

KITRI BoB 12th, Layer7 23rd