Neural Graph Collaborative Filtering 제2부 - introduction
introduction
-
Generally speaking, there are two key components in learnable CF models -- 1) embedding, which transforms users and items to vectorized representations, and 2) interaction modeling, which reconstructs historical interactions based on the embedings.
일반적으로 학습 가능한 CF 모델에는 두 가지 주요 구성 요소가 있습니다 - 1) 사용자와 항목을 벡터화 된 표현으로 변환하는 임베딩과 2) 임베딩을 기반으로 과거 상호 작용을 재구성하는 상호 작용 모델링. -
For example, matirx factorization (MF) directly embeds user/item ID as an vector and models user-item interaction with inner product; collaborative deep learning extends the MF embedding function by integrating the deep representations learned from rich side information of items; neural collaborative filtering models replace th MF interaction fuction of innter product with nonlinear neural networks; and translation-based CF models instead use Euclidean distance metirc as the interaction function, among others.
예를 들어, 행렬 분해(MF)는 사용자/항목 ID를 벡터로 직접 포함하고 내적과 사용자 항목 상호 작용을 모델링합니다. 협업 딥 러닝은 항목의 풍부한 부가 정보에서 학습된 딥 표현을 통합하여 MF 임베딩 기능을 확장합니다. 신경 협력 필터링 모델은 내적의 MF 상호 작용 함수를 비선형 신경망으로 대체합니다[14]. 번역 기반 CF 모델은 대신 상호 작용 함수로 유클리드 거리 측정법을 사용합니다[28].
-
Despite thier effectiveness, we argue that these methods are not sufficien to yield satisfactory embeddings for CF.
그 효과에도 불구하고, 우리는 이러한 방법이 CF에 대한 만족스러운 임베딩을 산출하기에 충분하지 않다고 주장한다. -
The key reason is that the embedding function lack an explicit encoding of the crucial collaborative signal, which is latent in user-item interactions to reveal the behavioral similarity between users(or items).
주요 이유는 임베딩 기능에 중요한 협업 신호의 명시적 인코딩이 부족하기 때문입니다. 이는 사용자(또는 항목) 간의 행동 유사성을 나타내기 위해 사용자-항목 상호작용에 잠재되어 있습니다. -
To be more specific, most existing methods build the embedding function with te descriptive features only(e.g., ID and attributes), without considering the user-item interactions -- wich are only used to define the objective function for model training.
보다 구체적으로, 대부분의 기존 방법들은 사용자-아이템 상호작용을 고려하지 않고 설명적 특징들(예를 들어, ID 및 속성들)만을 갖는 임베딩 함수를 구축한다 - 이는 모델 훈련을 위한 목적 함수를 정의하기 위해서만 사용된다[26, 28]. -
As a reuslt, when the embeddings, are insufficient in caputring CF, the methods have to rely on the interaction fuction to make up for the deficiency of suboptimal embeddings.
결과적으로, 임베딩이 CF를 캡처하는 데 불충분한 경우, 방법은 차선의 임베딩의 부족을 보충하기 위해 상호 작용 함수에 의존해야 한다[14].
-
While intuitively useflul to integrated user-item interactions into the embedding function, it is non-trivail to do it well.
사용자-항목 상호 작용을 임베딩 기능에 통합하는 데 직관적으로 유용하지만, 이를 잘 수행하는 것은 사소하지 않다. -
In particular, the scale of interactions can easily reach milions or even larger in real applications, making it difficult to distill the desired collaborative signal.
특히, 상호 작용의 규모는 실제 애플리케이션에서 수백만 또는 심지어 더 클 수 있으므로 원하는 협업 신호를 증류하는 것이 어렵다. -
In this work, we tackle the challenge by exploting the high-order connectivity from user-tiem iteractions, a natural way that encodes collaborative signal in the interaction graph structre.
본 연구에서는 상호 작용 그래프 구조에서 협업 신호를 인코딩하는 자연스러운 방법인 사용자 항목 상호 작용의 고차 연결을 활용하여 문제를 해결한다.
Running Example.
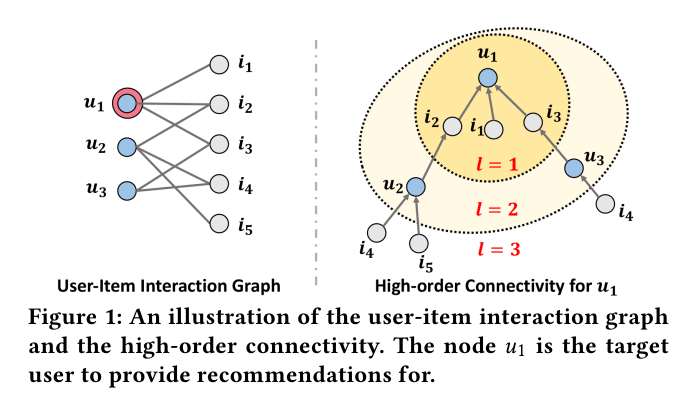
An illustration of the user-item interaction graph and the high-order connectivity. The node u1 is the target user to provide recommendations for.
사용자 항목 상호 작용 그래프와 고차 연결성에 대한 그림입니다. 노드 u1은 권장 사항을 제공할 대상 사용자입니다.
-
Figure 1 illustrates the concept of high-order connectivitiy.
그림 1은 고차 연결의 개념을 보여줍니다. -
The user of interes for recommendation is u1, labeled with the double circle in the left subfigure of user-item interaction graph.
추천 대상 사용자는 u1이며, 사용자 항목 상호 작용 그래프의 왼쪽 하위 그림에 이중 원으로 레이블이 지정되어 있다. -
The right subfigure shows the tree structure that is expanded from u1.
오른쪽 하위 그림은 u1에서 확장된 트리 구조를 보여줍니다. -
The high-odrder connectivity denotes the path that reaches u1 from any node with the path length l larger thatn 1.
고차 연결은 경로 길이 l이 1보다 큰 임의의 노드에서 u1에 도달하는 경로를 나타냅니다. -
Such high-order connectivity contains rich semantics that carry collaborative signal.
이러한 고차 연결은 협업 신호를 전달하는 풍부한 의미론을 포함한다. -
For example, the path u1 ← i2 ← u2 indicates the behavior similarity between u1 and u2 , as both users have interacted with i2 ; the longer path u1 ← i2 ← u2 ← i4 suggests that u1 is likely to adopt i4 , since her similar user u2 has consumed i4 before.
예를 들어 경로 u1 ← i2 ← u2는 두 사용자가 i2와 상호 작용했기 때문에 u1과 u2 사이의 동작 유사성을 나타냅니다. 경로 u1 ← i2 ← u2 ← i4가 길수록 유사한 사용자 u2가 이전에 i4를 사용했으므로 u1이 i4를 채택할 가능성이 높습니다.
- Moreover, from the holistic view of l = 3, item i4 is more likely to be of interest to u1 than item i5 , since there are two paths connecting <i4 , u1 >, while only one path connects <i5 , u1 >.
더욱이, l = 3의 전체론적 관점에서 볼 때, 항목 i4는 항목 i5보다 u1에 더 관심을 가질 가능성이 높다. <i4, u1>을 연결하는 경로가 두 개 있는 반면, 하나의 경로만 <i5, u1>을 연결하기 때문이다.
