A Bidirectional Multi-paragraph Reading Model for Zero-shot Entity Linking 제1부
A Bidirectional Multi-paragraph Reading Model for Zero-shot Entity Linking
Zero-shot Entity Linking을 위한 양방향 다중 단락 읽기 모델
Abstract
Recently, a zero-shot entity linking task is introduced to challenge the generalization ability of entity linking models. In this task, mentions must be linked to unseen entities and only the textual information is available. In order to make full use of the documents, previous work has proposed a BERT-based model which can only take fixed length of text as input.
최근 엔티티 연결 모델의 일반화 능력에 도전하기 위해 제로샷 엔티티 연결 작업이 도입된다. 이 작업에서 멘션은 보이지 않는 엔티티에 연결되어야 하며 텍스트 정보만 사용할 수 있다. 문서를 최대한 활용하기 위해 이전 연구에서는 텍스트의 고정 길이만 입력으로 취할 수 있는 BERT 기반 모델을 제안했다.
However, the key information for entity linking may exist in nearly everywhere of the documents thus the proposed model cannot capture them all. To leverage more textual information and enhance text understanding capability, we propose a bidirectional multi-paragraph reading model for the zero-shot entity linking task. Firstly, the model treats the mention context as a query and matches it with multiple paragraphs of the entity description documents.
그러나 엔티티 연결을 위한 핵심 정보는 문서의 거의 모든 곳에 존재할 수 있으므로 제안된 모델이 이를 모두 포착할 수는 없다. 더 많은 텍스트 정보를 활용하고 텍스트 이해 능력을 향상시키기 위해 제로샷 엔티티 연결 작업에 대한 양방향 다중 문단 읽기 모델을 제안한다. 첫째, 모델은 언급 컨텍스트를 쿼리로 처리하고 엔티티 설명 문서의 여러 문단과 일치시킨다.
Then, the mention-aware entity representation obtained from the first step is used as a query to match multiple paragraphs in the document containing the mention through an entity-mention attention mechanism. In particular, a new pre-training strategy is employed to strengthen the representative ability. Experimental results show that our bidirectional model can capture long-range context dependencies and outperform the baseline model by 3-4% in terms of accuracy.
그런 다음, 첫 번째 단계에서 얻은 언급 인식 엔티티 표현은 엔티티 언급 주의 메커니즘을 통해 언급을 포함하는 문서의 여러 단락을 일치시키는 쿼리로 사용된다. 특히 대표성 강화를 위해 새로운 사전 훈련 전략을 채용한다. 실험 결과는 우리의 양방향 모델이 장거리 컨텍스트 종속성을 포착하고 정확도 측면에서 기준 모델을 3-4% 능가할 수 있음을 보여준다.
Introduction
Entity Linking (EL) is a task of resolving ambiguous mentions to their referent entities in a knowledge base (KB).
EL is a fundamental task in the area of information extraction (IE) and can benefit other NLP applications such as question answering (Chang 2016), text summarization (Amplayo, Lim, and Hwang 2018), etc.
엔티티 연결(EL)은 지식 기반(KB)에서 참조 엔티티에 대한 모호한 언급을 해결하는 작업이다.
EL은 정보 추출(IE) 분야의 기본 작업이며 질문 답변(Chang 2016), 텍스트 요약(Amplayo, Lim, Hwang 2018) 등과 같은 다른 NLP 애플리케이션에 도움이 될 수 있다.
Most previous work focuses on linking mentions to general KBs (e.g. Wikipedia). They usually train models under a setting where the entities occurring in the test set are partially or fully available for training. Moreover, they typically utilize not only textual information but also powerful resources like frequency statistics and meta-data (Ganea and Hofmann 2017; Roth et al. 2014) existing in the KBs.
대부분의 이전 작업은 언급을 일반 KB(예: Wikipedia)와 연결하는 데 중점을 둔다. 그들은 일반적으로 테스트 세트에서 발생하는 엔티티가 부분적으로 또는 완전히 훈련에 사용 가능한 환경에서 모델을 훈련한다. 또한 일반적으로 텍스트 정보뿐만 아니라 KB에 존재하는 주파수 통계 및 메타 데이터(Ganea 및 Hofmann 2017; Roth et al. 2014)와 같은 강력한 리소스를 활용한다.
Compared to general domains, entity linking in specialized domains such as movies or fictions, needs to be addressed with a strong demand. However, this type of linking can be much more challenging in such domains since labeled data are not easily obtained and the resources in such KBs are not as abundant as the general ones. Therefore, models with the capability of generalizing to new domains need to be developed.
일반 도메인에 비해 영화나 소설과 같은 특화된 도메인에서의 엔티티 연계는 강력한 수요로 해결될 필요가 있다. 그러나 레이블이 지정된 데이터를 쉽게 얻을 수 없고 이러한 KB의 리소스가 일반 도메인만큼 풍부하지 않기 때문에 이러한 유형의 연결은 이러한 도메인에서 훨씬 더 어려울 수 있다. 따라서 새로운 도메인으로 일반화할 수 있는 모델이 개발되어야 한다.
To evaluate the domain generalization of entity linking systems, Lajanugen et al.(Logeswaran et al. 2019) presented a zero-shot entity linking task which has two key properties: (1) no mentions or entities in the testing have been observed during training, (2) no other information is available other than texts. In this task, each mention is extracted from a document and each entity corresponds to a document that describes the details of it. Meanwhile, they proposed a baseline model based on BERT (Devlin et al. 2019) which links the mention with its referent entity by reading two pieces of text, i.e., the mention context and the entity description.
엔티티 연결 시스템의 도메인 일반화를 평가하기 위해 Lajanugen et al.(Logeswaran et al. 2019)는 두 가지 핵심 속성을 가진 제로샷 엔티티 연결 작업을 제시했다. (1) 훈련 중에 테스트에서 언급 또는 엔티티가 관찰되지 않았으며, (2) 텍스트 외에 다른 정보는 사용할 수 없다. 이 태스크에서 각 언급은 문서에서 추출되고 각 엔티티는 문서의 세부 정보를 설명하는 문서에 해당합니다. 한편, 그들은 BERT(Devlin et al. 2019)를 기반으로 한 기준선 모델을 제안했는데, 이 모델은 두 가지 텍스트, 즉 언급 컨텍스트와 엔티티 설명을 읽음으로써 언급을 참조 엔티티와 연결한다.
Specifically, the baseline model truncates a fixed length of text around the mention as the mention context and the beginning of entity document as the entity description. Then, it concatenates the two pieces of texts and feeds it into BERT which is able to perform deep cross-attention between their tokens, producing a matching score indicating how much the candidate entity is related to the mention. However, this model cannot fully capture the coherence evidence between a mention and its golden entity due to the limitation of its input length.
구체적으로, 기준선 모델은 언급 컨텍스트로서의 언급과 엔터티 설명으로서의 엔터티 문서의 시작을 중심으로 고정된 길이의 텍스트를 잘라냅니다. 그런 다음 두 텍스트를 연결하여 BERT에 공급하여 토큰 간에 깊은 교차 주의를 수행할 수 있으며, 후보 엔티티가 언급과 얼마나 관련이 있는지 나타내는 일치 점수를 생성한다. 그러나 이 모델은 입력 길이의 제한으로 인해 언급과 황금 엔티티 간의 일관성 증거를 완전히 포착할 수 없다.
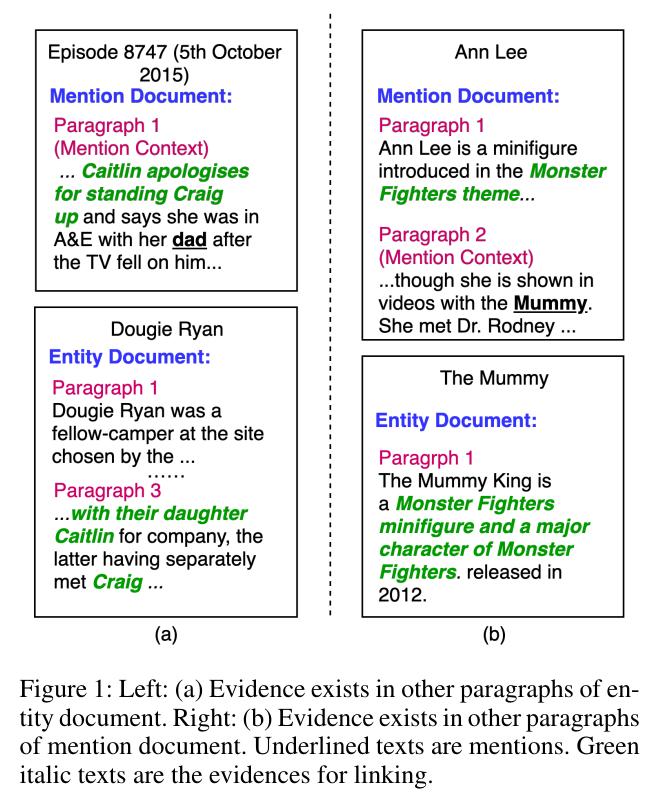
Figure 1: Left: (a) Evidence exists in other paragraphs of entity document. Right: (b) Evidence exists in other paragraphs of mention document. Underlined texts are mentions. Green italic texts are the evidences for linking.
그림 1: 왼쪽: (a) 실체 문서의 다른 문단에 증거가 존재한다. 권리: (나) 언급문서의 다른 문단에 증거가 존재한다. 밑줄 친 텍스트는 멘션입니다. 녹색 이탤릭체 텍스트는 연결을 위한 증거이다.
To illustrate why it is insufficient, we give two examples in Figure 1. The mention contexts and entity descriptions are extracted as the baseline model does. Then, we split the rest texts of the documents into paragraphs whose lengths are same as them. In the left example, the mention is “dad” whose daughter “Caitlin apologies for standing Craig up”.
왜 그것이 불충분한지 설명하기 위해, 우리는 그림 1에 두 가지 예를 제시한다. 언급 컨텍스트 및 엔티티 설명은 기준 모델이 하는 것처럼 추출된다. 그런 다음, 우리는 문서의 나머지 텍스트를 길이가 같은 단락으로 나눕니다. 왼쪽 예에서 언급된 것은 "아빠"이며, 그의 딸 "케이틀린이 크레이그를 바람맞힌 것에 대해 사과한다"이다.
The golden entity of the mention is “Doubie Ryan” since the paragraph 3 of the entity document shows “Caitlin” is “Doubie Ryan”’s daughter who met “Craig”. Obviously, the BERT-based baseline model may not link the entity correctly since the paragraph 3 is not fed in. In the right example, the golden entity of the mention “Mummy” is “in the Monster Fighters theme”. However, the evidence exists in paragraph 1 of the mention document which is not presented in the mention context, thus the baseline model would confuse which theme the “Mummy” belongs to.
언급의 황금 실체는 "더비 라이언"인데, 실체 문서의 3항에서 "케이틀린"이 "크레이그"를 만난 "더비 라이언"의 딸이라는 것을 알 수 있기 때문이다. 문단 3이 입력되지 않았기 때문에 BERT 기반 기준 모형은 기업을 정확하게 연결하지 못할 수 있다. 올바른 예에서, "Mummy"라는 언급의 황금 실체는 "몬스터 파이터즈 테마"에 있다. 그러나 언급 맥락에 제시되지 않은 언급 문서의 1항에 증거가 존재하므로 기준 모델은 "미이라"가 어떤 주제에 속하는지 혼동할 수 있다.
Such two examples show that in the entity linking task, the evidence may scatter in different paragraphs. Expanding the length of the mention context and entity description with more paragraphs may benefit the model’s performance.
However, since BERT is a deep cross-attention encoder, directly expanding the input length in the BERT-based baseline model is infeasible since both the time and space complexity grows with the square of tokens.
그러한 두 가지 사례는 기업 연결 과제에서 증거가 서로 다른 문단에 분산될 수 있음을 보여준다. 언급 맥락과 기업 설명의 길이를 더 많은 문단으로 확장하면 모형의 성능에 도움이 될 수 있다.
그러나 BERT는 심층 교차 주의 인코더이기 때문에 BERT 기반 기준선 모델에서 입력 길이를 직접 확장하는 것은 토큰의 제곱에 따라 시간과 공간 복잡성이 모두 증가하기 때문에 불가능하다.
This problem is rarely discussed in the entity linking literature. In contrast, some existing work in the machine reading comprehension area has already studied on finding answers from multiple paragraphs of documents. For example, (Clark and Gardner 2018) proposes a typical model which feeds the query and each paragraph into a reading comprehension module and then select a final answer from the extracted candidate answers of each paragraph. This paradigm is sufficient in reading comprehension task since there is an explicit query. However, in the entity linking task, both the mention context and entity description are en-wrapped with several different paragraphs in corresponding documents respectively. No explicit queries and answers are available.
Therefore, a new multi-paragraph reading model should be built to adapt for the zero-shot entity linking task.
이 문제는 문헌을 연결하는 주체에서 거의 논의되지 않는다. 대조적으로, 기계 독해 영역의 일부 기존 작업은 이미 문서의 여러 단락에서 답을 찾는 것을 연구했다. 예를 들어, (Clark and Gardner 2018)는 쿼리와 각 문단을 읽기 이해 모듈에 공급한 다음 각 문단의 추출된 후보 답변에서 최종 답변을 선택하는 전형적인 모델을 제안한다. 이 패러다임은 명시적 쿼리가 있기 때문에 이해 과제를 읽는 데 충분하다. 그러나 기업 연결 과제에서 언급 맥락과 기업 설명은 각각 해당 문서에서 여러 개의 다른 문단으로 정리된다. 명시적인 쿼리 및 답변을 사용할 수 없습니다.
따라서 제로샷 엔티티 연결 작업에 적응하기 위해 새로운 다중 단락 읽기 모델을 구축해야 한다.
In this paper, we propose a multi-paragraph reading model for zero-shot entity linking which can make use of more textual information. The key idea of our model is to take more paragraphs into consideration. In particular, during the encoding of each entity paragraph, we send both the mention context and one entity document paragraph into a BERT encoder to perform deep cross-attention between each other.
본 논문에서는 더 많은 텍스트 정보를 사용할 수 있는 제로샷 엔티티 연결을 위한 다중 단락 읽기 모델을 제안한다. 우리 모델의 핵심 아이디어는 더 많은 단락을 고려하는 것이다. 특히, 각 엔티티 단락을 인코딩하는 동안 언급 컨텍스트와 하나의 엔티티 문서 단락을 모두 BERT 인코더로 전송하여 서로 간에 깊은 교차 주의를 수행한다.
Then, the obtained encodings are aggregated by an inter-paragraph attention mechanism. To deal with the problem that information about mention context is insufficient, we add an additional backward multi-paragraph reading step. Specifically, the paragraphs of the mention document are encoded separately. Then, the encoding obtained in the first step and the encoded mention paragraphs are matched by another attention module. Such a model can be summarized as a Bidirectional Multi-Paragraph Reading (Bi-MPR) model for entity linking which exploits more textual information in both mention and entity documents. The main contributions of our work are summarized as follows.
그런 다음 얻은 인코딩은 문단 간 주의 메커니즘에 의해 집계된다. 언급 맥락에 대한 정보가 부족한 문제를 해결하기 위해, 우리는 역방향 다중 단락 읽기 단계를 추가한다. 구체적으로, 언급 문서의 단락들은 별도로 인코딩된다. 그런 다음, 첫 번째 단계에서 얻은 인코딩과 인코딩된 언급 단락은 다른 주의 모듈에 의해 일치된다. 이러한 모델은 언급 및 엔티티 문서 모두에서 더 많은 텍스트 정보를 활용하는 엔티티 연결을 위한 양방향 다중 문단 읽기(Bi-MPR) 모델로 요약될 수 있다. 우리 작업의 주요 기여는 다음과 같이 요약된다.
• We propose a two-step forward-backward matching process to deal with the zero-shot entity linking.
• We present an inter-paragraph attention mechanism to capture rich semantics in the forward matching step and an entity-mention attention mechanism to fully comprehend the mention context and entity description in the backward matching step.
• We evaluate the performance of Bi-MPR model on the zero-shot entity linking dataset. The experimental results show that our model achieves significant improvements over the BERT-based baseline. An extensive analysis of the length parameters shows our model achieves good accuracy using a relatively short inference time.
• 제로샷 엔티티 연결을 처리하기 위해 2단계 전진-후진 매칭 프로세스를 제안한다.
• 우리는 전방 일치 단계에서 풍부한 의미론을 포착하기 위한 문단 간 주의 메커니즘과 후방 일치 단계에서 언급 컨텍스트와 엔티티 설명을 완전히 이해하기 위한 엔티티 언급 주의 메커니즘을 제시한다.
• 제로샷 엔티티 연결 데이터 세트에서 Bi-MPR 모델의 성능을 평가한다. 실험 결과는 우리 모델이 BERT 기반 기준선에 비해 상당한 개선을 달성한다는 것을 보여준다. 길이 매개 변수에 대한 광범위한 분석은 우리 모델이 비교적 짧은 추론 시간을 사용하여 좋은 정확도를 달성한다는 것을 보여준다.
Conclusion
Zero-shot entity linking task forces the models to link mentions to unseen entities and leverage only textual information which challenges the generalization and text comprehension ability of entity linking models. Usually, the evidence for linking the golden entity could scatter in different paragraphs of a document which is hard to collect and comprehend. Focusing on this phenomena, we present a new bidirectional multi-paragraph reading model which can capture long-range text dependence between mention and entity documents but restrict the increasing amount of inference time in an acceptable range. The experimental results on the challenging zero-shot entity linking dataset show our model achieves state-of-the-art performance in different domains.
제로샷 엔티티 연결 작업은 모델이 언급을 보이지 않는 엔티티에 연결하고 엔티티 연결 모델의 일반화 및 텍스트 이해 능력에 도전하는 텍스트 정보만 활용하도록 한다. 일반적으로 황금 실체를 연결하는 증거는 수집하고 이해하기 어려운 문서의 다른 문단에 분산될 수 있다. 이러한 현상에 초점을 맞춰 언급과 엔티티 문서 간의 장거리 텍스트 의존성을 포착할 수 있지만 허용 가능한 범위에서 증가하는 추론 시간을 제한할 수 있는 새로운 양방향 다중 문단 읽기 모델을 제시한다. 도전적인 제로샷 엔티티 연결 데이터 세트에 대한 실험 결과는 우리 모델이 다양한 도메인에서 최첨단 성능을 달성한다는 것을 보여준다.
