A Deep Bi-directional Attention Network for Human Motion Recovery 제2부
2 Related Work
Human motion recovery.
Because of the inherent properties and structural constraints of human motion, the repair of missing joints cannot be simply regarded as data filling [Xia et al., 2018]. Many researchers have developed various methods to solve the problem of human motion recovery based upon the statistical properties (i.e., sparsity) of human motion [Lai et al., 2011]. Xiao et al.consider motion recovery from the perspective of sparse representation and propose a novel method named L-sparse representation (SR-L1) of missing markers prediction [Xiao et al., 2011].
인간 움직임의 고유한 특성과 구조적 제약 때문에, 누락된 관절의 수리는 단순히 데이터 채우기로 간주될 수 없다 [Xia et al., 2018]. 많은 연구자들이 인간 움직임의 통계적 특성(즉, 희소성)에 기초하여 인간 움직임 회복 문제를 해결하기 위한 다양한 방법을 개발했다[Lai et al., 2011]. Xiao 등은 희소 표현의 관점에서 움직임 복구를 고려하고 누락된 마커 예측의 L-sparse 표현(SR-L1)이라는 새로운 방법을 제안한다[Xiao 등, 2011년].
Low-rank matrix completion [Tan et al., 2013; Hu et al., 2018], which usually seeks to find the lowest rank matrix for observed data, has been widely used for motion recovery. [Lai et al., 2011] first propose that damaged human motion can be efficiently recovered based on the low-rank prior, in which they use the singular value threshold method to solve the rank minimization problem.
일반적으로 관찰된 데이터에 대한 가장 낮은 순위 행렬을 찾는 낮은 순위 행렬 완성[Tan et al., 2013; Hu et al., 2018]은 모션 복구에 널리 사용되어 왔다. [Lai et al., 2011]은 먼저 낮은 순위 이전을 기반으로 손상된 인간의 움직임을 효율적으로 복구할 수 있다고 제안한다. 여기서 그들은 단일 값 임계값 방법을 사용하여 순위 최소화 문제를 해결한다.
[Tan et al., 2013] suggest that mocap data based on trajectory representation can be used instead of frame representation, and the rank of this representation can be reduced because the lower rank is more suitable for the low-rank model. Nevertheless, these prior-based methods tend to yield unreasonable results for severely corrupted motion sequences. Because if the missing ratio is too large or the missing time is too long, the statistical property of low rank will no longer be satisfied.
[Tan et al., 2013]은 프레임 표현 대신 궤적 표현에 기반한 mocap 데이터를 사용할 수 있으며, 낮은 순위 모델에 더 적합하기 때문에 이 표현의 순위를 줄일 수 있다고 제안한다. 그럼에도 불구하고, 이러한 사전 기반 방법은 심각하게 손상된 모션 시퀀스에 대해 불합리한 결과를 산출하는 경향이 있다. 결측 비율이 너무 크거나 결측 시간이 너무 길면 낮은 순위의 통계 속성이 더 이상 충족되지 않기 때문입니다.
Deep learning for human motion.
Human motion is essentially a sequential data, which is naturally suitable for the sequential model in deep learning [Ruiz et al., 2018;
Holden et al., 2017; Martinez et al., 2017]. Holden et al.develop various networks for human motion denoising and editing [Holden, 2018], but these structures abandon the temporal aspect of motion data.
인간의 움직임은 본질적으로 순차적 데이터이며, 이는 딥 러닝에서 순차적 모델에 자연스럽게 적합하다 [Ruiz 등, 2018;
Holden et al., 2017; Martinez et al., 2017]. Holden 등은 인간 모션 노이즈 제거 및 편집을 위한 다양한 네트워크를 개발하지만 [Holden, 2018], 이러한 구조는 모션 데이터의 시간적 측면을 포기한다.
Alternatively, [Mall et al., 2017] propose a deep bi-directional recurrent network to clean up incomplete motion data wherein they use fully connected network to capture the joint correlation and temporal consistency of the human skeleton.
또는 [Mall et al., 2017]은 완전 연결된 네트워크를 사용하여 인간 골격의 관절 상관 관계와 시간적 일관성을 포착하는 불완전한 모션 데이터를 정리하기 위한 심층 양방향 반복 네트워크를 제안한다.
[Fragkiadaki et al., 2015] present a recurrent autoencoder structure named EncoderRecurrent-Decoder (ERD) to predict human body pose, in which they use LSTM [Hochreiter and Schmidhuber, 1997; Rumelhart et al., 1986] layer to learn temporal-spatial correlation of motion sequence.
[Fragkiadaki et al., 2015]는 LSTM [Hochreiter and Schmidhuber, 1997; Rumelhart et al., 1986] 레이어를 사용하여 동작 시퀀스의 시간-공간 상관 관계를 학습하는 EncoderRecurrent-Decoder(ERD)라는 반복 자동 인코더 구조를 제시한다.
These structures achieve excellent results only in short-term sequences and cannot be directly used for recovering missing joints. For motion recovery, [Kucherenko and Kjellström, 2018] use a standard LSTM structure to recover motion sequence with missing markers in a short period of time.
이러한 구조는 단기 시퀀스에서만 우수한 결과를 얻으며 누락된 관절을 복구하는 데 직접 사용할 수 없다. 모션 복구를 위해 [Kucherenko and Kjellström, 2018]은 마커가 누락된 모션 시퀀스를 짧은 시간 내에 복구하기 위해 표준 LSTM 구조를 사용한다.
Attention modeling.
The seq2seq networks have produced stellar results, but one of the most challenging problems is the performance decline rapidly with the increase of sequence length [Bahdanau et al., 2014; Zhou et al., 2016; Yang et al., 2016]. To solve this problem, Bahdanau et al.adaptively select the relevant partially hidden state into the decoder at each time step using the attention mechanism [Bahdanau et al., 2014].
seq2seq 네트워크는 별의 결과를 만들어냈지만, 가장 어려운 문제 중 하나는 시퀀스 길이가 증가함에 따라 성능이 급격히 저하된다는 것이다[Bahdanau et al., 2014; Zhou et al., 2016; Yang et al., 2016]. 이 문제를 해결하기 위해, Bahdanau 등은 주의 메커니즘을 사용하여 각 시간 단계에서 관련 부분적으로 숨겨진 상태를 디코더에 적응적으로 선택한다 [Bahdanau 등, 2014].
Yang et al., propose a hierarchical attention network for text classification using stacked recurrent layers, with each layer utilizing attention mechanism [Yang et al., 2016]. You et al., build an attention variant to learn to selectively tend to semantic concept proposals and integrate them into the recurrent neural network [You et al., 2016], which has achieved great success in the image caption.
Yang et al., 각 레이어가 주의 메커니즘을 활용하여 스택형 반복 레이어를 사용하는 텍스트 분류를 위한 계층적 주의 네트워크를 제안합니다 [Yang et al., 2016]. 당신 등은 의미론적 개념 제안을 선택적으로 기울이는 경향을 학습하기 위해 주의 변형을 구축하고 이미지 캡션에서 큰 성공을 거둔 반복 신경망에 통합한다[You 등, 2016].
More recently, a dual-stage attention mechanism is proposed by [Qin et al., 2017] for time series prediction. In the first stage, the attention mechanism is equipped on a standard LSTM encoder to select the relevant inputs, while in the second stage the feature representation is also adaptively selected for decoding.
더 최근에는 시계열 예측을 위해 [Qin et al., 2017]에 의해 이중 단계 주의 메커니즘이 제안된다. 첫 번째 단계에서는 주의 메커니즘이 표준 LSTM 인코더에 장착되어 관련 입력을 선택하고, 두 번째 단계에서는 디코딩을 위해 기능 표현도 적응적으로 선택된다.
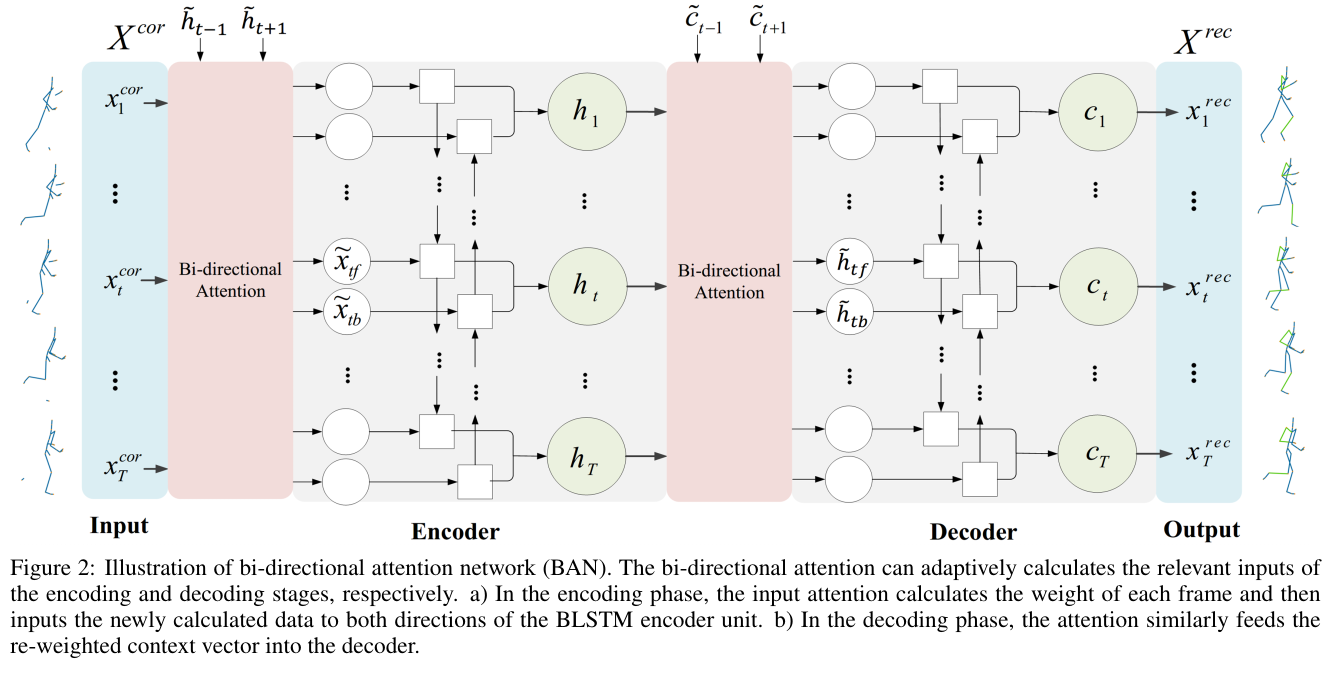
Figure 2: Illustration of bi-directional attention network (BAN). The bi-directional attention can adaptively calculates the relevant inputs of the encoding and decoding stages, respectively. a) In the encoding phase, the input attention calculates the weight of each frame and then inputs the newly calculated data to both directions of the BLSTM encoder unit. b) In the decoding phase, the attention similarly feeds the re-weighted context vector into the decoder.
그림 2: 양방향 주의 네트워크(BAN) 그림. 양방향 어텐션은 각각 인코딩 및 디코딩 단계의 관련 입력을 적응적으로 계산할 수 있습니다. a) 인코딩 단계에서 입력 어텐션은 각 프레임의 가중치를 계산한 다음 새로 계산된 데이터를 BLSTM 인코더 장치의 양방향으로 입력합니다. b) 디코딩 단계에서 어텐션은 유사하게 재가중된 컨텍스트 벡터를 디코더에 공급합니다.
