2. Background
2.1 vanilla Transformer
The vansilla Trnsformer is a sequence-tosequence model and consists of an encoder and a decoder, each of which is a stack of identical blocks.
바닐라 트랜스포머[137]는 시퀀스 대 시퀀스 모델이며 인코더와 디코더로 구성되며 각각은 𝐿개의 동일한 블록 스택입니다.
Each encoder block in mainly composed of a multi-head self-attention module and a positio-wise fee-forward network(FFN).
각 인코더 블록은 주로 다중 헤드 자기 주의 모듈과 위치별 피드 포워드 네트워크(FFN)로 구성된다.
For building a deeper model, a residual connection is employed around each module, followed by Layer Normalization module.
더 심층적인 모델을 구축하기 위해 각 모듈 주위에 잔여 연결부 [49]가 사용되며, 그 다음 계층 정규화 [4] 모듈이 사용됩니다.
Compared to the encoder blocks, decoder blocks additionally insert cross-attention modules between the multi-head self-attention modules and the position-wise FFNs.
인코더 블록과 비교하여 디코더 블록은 다중 헤드 자기 주의 모듈과 위치별 FFN 사이에 교차 주의 모듈을 추가로 삽입한다.
Furthermore, the self-attention modules in the decoder are adapted to prevent each position from attending to subsequent position.
또한 디코더의 자체 주의 모듈은 각 위치가 다음 위치에 주의를 기울이는 것을 방지하도록 구성됩니다.
The overall architecture of the vanilla Transformer is shown in Fig. 1.
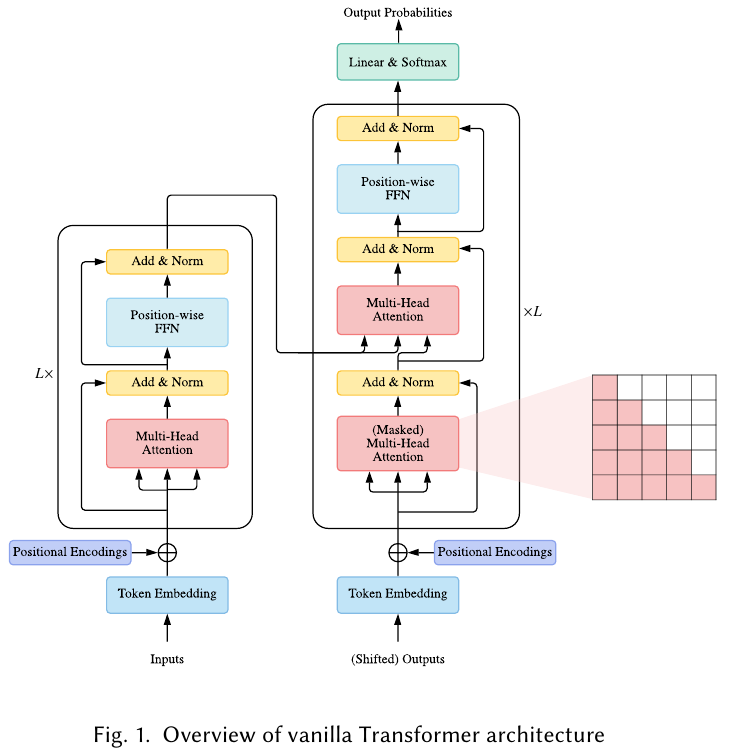
2.1.1 Attention Modules
Transformer adopts attention mechansim with Query-Key-Value (QKV) model.
Given the packed matirx representations of queries , keys , and valeus , the scaled dot-product attention used by Transformer is given by1
if not stated otherwise, we use row-major notations throughout this survey (e.g., the 𝑖-th row in Q is the query q𝑖 ) and all the vectors are row vectors by default.
달리 명시되지 않은 경우, 우리는이 설문 조사 전체에서 행 주 표기법을 사용하며 (예 : Q의 i 번째 행은 쿼리 qi입니다) 모든 벡터는 기본적으로 행 벡터입니다.
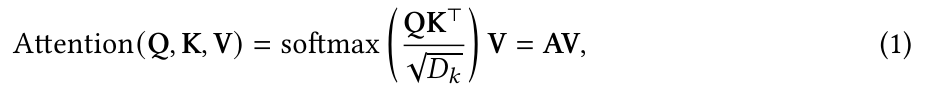
where N and M denote(나타내다) the lengths of queries and keys (or values); and denote the dimensions of keys (or queries) and values; is often called attention matrix; softmax is applied in a row-wise manner.
softmax is applied in a row-wise manner. :softmax는 행 단위로 적용됩니다.
The dot-products of queries and keys are divided by to alleviate(완하하다) gradeint vanishing problem of the softmax function.
쿼리와 키의 내적을 로 나누어 softmax 함수의 그래디언트 소실 문제를 완화합니다.
Instead of simply applying a single attention function, Transformer uses multi-head attention, where the -dimensional original queries, keys and values are projected into , and dimensions, respectively, with H different sets of learned projections.
Transformer는 단순히 단일 어텐션 기능을 적용하는 대신 다중 헤드 어텐션을 사용합니다. 여기서 𝐷𝑚 -차원 원본 쿼리, 키 및 값은 각각 𝐻 학습된 투영 세트와 함께 𝐷𝑘 , 𝐷𝑘 및 𝐷𝑣 차원으로 투영됩니다.
For each of the projected queries, keys and values, and output is computed with attention according to Eq. (1)
각각의 투영된 '쿼리', '키' 및 '값'에 대해, 출력은 Eq. (1)에 따라 'attention'로 계산된다.
The model then concatenated all the outputs and projects them back to a -dimensional representation.
그런 다음 모델은 모든 출력을 연결하고 다시 𝐷𝑚 -차원 표현으로 투영합니다.
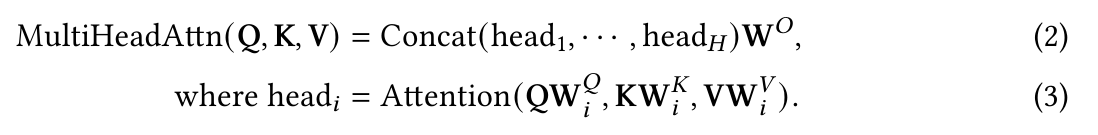
In Transformer, there are three types of attention in terms of the source of queries and eky-value pairs:
Transformer에는 쿼리 소스와 키-값 쌍의 관점에서 세 가지 유형의 주의가 있습니다. in terms of(~의 유형, 면에서)
-
Self-attention. In Transformer encoder, we set = = = in Eq.(2), where X is the outputs of the previous layer.
-
Masked Self attention. In the Transformer decoder, the self-attention is restricted such that queries at each position can only to all key-value pairs up to and including that position.
Masked self attention. Transformer 디코더에서 self-attention은 각 위치의 쿼리가 해당 위치까지의 모든 키-값 쌍에만 해당 위치를 포함하도록 제한됩니다.
To enable parallel training, this is typically done by applying a mask function to the unnormalized attention matrix , where the illegal positions are masked out by setting if .
This kind of self-attention is often referred to as autoregressive or causal attention.2
이런 종류의 자기 주의는 종종 자기 회귀 적 또는 인과 적 관심이라고합니다.
2This term seems to be borrowed from the causal system, where the output depends on past and current inputs but not future inputs.
이 용어는 인과 관계 시스템에서 차용 된 것으로 보이며, 출력은 과거와 현재의 입력에 의존하지만 미래의 입력에는 의존하지 않습니다.
- Cross-attention. The queries are projected from the outputs of the previous (decoder) layer, whereas the keys and values are projected using the outputs of the encoder.
쿼리는 이전(디코더) 계층의 출력에서 프로젝션되는 반면, 키와 값은 인코더의 출력을 사용하여 프로젝션됩니다.
whereas: ~인 반면
2.1.2 Position-wise FFN
The position-wise FFN3 is a fully connected feed-forward module that operates separately and identically on each position.
위치 단위 FFN은 각 위치에서 개별적으로 동일하게 작동하는 완전히 연결된 피드포워드 모듈입니다.
3The parameters are shared across different positions, thus the position-wise FFN can also be understood as two convolution layers with kernel size of 1.
파라미터는 서로 다른 위치에 걸쳐 공유되므로 위치 별 FFN은 커널 크기가 1 인 두 개의 컨볼루션 레이어로도 이해 될 수 있습니다.
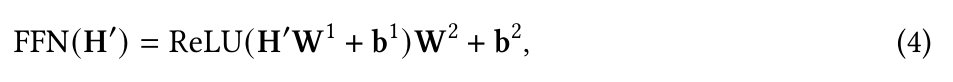
where is the outputs of previous layer, and , , . are trainable parameters.
Typically the intermediate dimension of the FFN is set to be larger than . intermediate : 중간
전형적으로 FFN의 중간 치수 Df는 Dm보다 크게 설정된다.
