Bi-Directional Cascade Network for Perceptual Edge Detection 제1부
Bi-Directional Cascade Network for Perceptual Edge Detection
지각 에지 검출을 위한 양방향 캐스케이드 네트워크
abstract
Exploiting multi-scale representations is critical to improve edge detection for objects at different scales. To extract edges at dramatically different scales, we propose a Bi-Directional Cascade Network (BDCN) structure, where an individual layer is supervised by labeled edges at its specific scale, rather than directly applying the same supervision to all CNN outputs. Furthermore, to enrich multi-scale representations learned by BDCN, we introduce a Scale Enhancement Module (SEM) which utilizes dilated convolution to generate multi-scale features, instead of using deeper CNNs or explicitly fusing multi-scale edge maps.
다중 스케일 표현을 활용하는 것은 서로 다른 스케일의 개체에 대한 에지 탐지를 개선하는 데 중요하다. 극적으로 다른 스케일에서 에지를 추출하기 위해, 우리는 모든 CNN 출력에 동일한 감독을 직접 적용하지 않고 개별 레이어가 특정 스케일에서 레이블이 지정된 에지에 의해 감독되는 양방향 캐스케이드 네트워크(BDCN) 구조를 제안한다. 또한, BDCN이 학습한 다중 스케일 표현을 풍부하게 하기 위해 더 깊은 CNN을 사용하거나 다중 스케일 에지 맵을 명시적으로 융합하는 대신 확장 컨볼루션을 활용하여 다중 스케일 기능을 생성하는 스케일 강화 모듈(SEM)을 소개한다.
These new approaches encourage the learning of multi-scale representations in different layers and detect edges that are well delineated by their scales. Learning scale dedicated layers also results in compact network with a fraction of parameters. We evaluate our method on three datasets, i.e., BSDS500, NYUDv2, and Multicue, and achieve ODS Fmeasure of 0.828, 1.3% higher than current state-of-the art on BSDS500. The code has been available .
이러한 새로운 접근 방식은 서로 다른 레이어에서 다중 스케일 표현의 학습을 장려하고 스케일로 잘 묘사된 에지를 감지한다. 또한 스케일 전용 계층을 학습하면 매개 변수의 일부로 컴팩트한 네트워크가 생성된다. BSDS500, NYUDv2 및 Multicue의 세 가지 데이터 세트에서 방법을 평가하고 BSDS500의 현재 최신 기술보다 1.3% 높은 0.828의 ODSF 측정을 달성한다. 코드를 사용할 수 있습니다.
1. Introduction
Edge detection targets on extracting object boundaries and perceptually salient edges from natural images, which preserve the gist of an image and ignore unintended details. Thus, it is important to a variety of mid- and high-level vision tasks, such as image segmentation [1, 41], object detection and recognition [13, 14], etc.
에지 감지는 이미지의 요지를 보존하고 의도하지 않은 세부 사항을 무시하는 자연 이미지에서 객체 경계와 지각적으로 돌출된 에지를 추출하는 것을 목표로 한다. 따라서, 이미지 분할[1, 41], 객체 감지 및 인식[13, 14] 등과 같은 다양한 중간 및 고급 비전 작업에 중요하다.
Thanks to research efforts ranging from exploiting low-level visual cues with hand-crafted features [4, 22, 1, 28, 10] to recent deep models [3, 30, 23, 47], the accuracy of edge detection has been significantly boosted. For example, on the Berkeley Segmentation Data Set and Benchmarks 500 (BSDS500) [1], the detection performance has been boosted from 0.598 [7] to 0.815 [47] in ODS F-measure.
수작업 기능이 있는 낮은 수준의 시각적 단서[4, 22, 1, 28, 10]부터 최근의 심층 모델[3, 30, 23, 47]까지 다양한 연구 노력 덕분에 에지 감지의 정확도가 크게 향상되었다. 예를 들어, Berkeley Segmentation Data Set and Benchmarks 500(BSDS500)[1]에서 ODSF 측정에서 검출 성능이 0.598[7]에서 0.815[47]로 향상되었다.
Nevertheless, there remain some open issues worthy of studying. As shown in Fig. 1, edges in one image stem from both object-level boundaries and meaningful local details, e.g., the silhouette of human body and the shape of hand gestures. The variety of scale of edges makes it crucial to exploit multi-scale representations for edge detection.
그럼에도 불구하고, 연구할 가치가 있는 몇 가지 미해결 문제들이 남아 있다. 그림 1에서 보는 바와 같이, 한 이미지의 가장자리는 물체 수준의 경계와 인체의 실루엣 및 손동작의 형태와 같은 의미 있는 국소 세부 사항 모두에서 비롯된다. 에지의 스케일이 다양하기 때문에 에지 감지를 위해 다중 스케일 표현을 활용하는 것이 중요하다.
Recent neural net based methods [2, 42, 49] utilize hierarchal features learned by Convolutional Neural Networks (CNN) to obtain multi-scale representations. To generate more powerful multi-scale representation, some researchers adopt very deep networks, like ResNet50 [18], as the backbone model of the edge detector. Deeper models generally involve more parameters, making the network hard to train and expensive to infer. Another way is to build an image pyramid and fuse multi-level features, which may involve redundant computations. In another word, can we use a shallow or light network to achieve a comparable or even better performance?
최근의 신경망 기반 방법[2, 42, 49]은 컨볼루션 신경망(CNN)에서 학습한 계층적 특징을 활용하여 다중 스케일 표현을 얻는다. 더 강력한 다중 스케일 표현을 생성하기 위해 일부 연구자들은 ResNet50[18]과 같은 매우 심층적인 네트워크를 에지 검출기의 백본 모델로 채택한다. 심층 모델은 일반적으로 더 많은 매개 변수를 포함하므로 네트워크를 교육하기 어렵고 추론 비용이 많이 든다. 또 다른 방법은 이미지 피라미드를 구축하고 중복 계산을 수반할 수 있는 다단계 기능을 융합하는 것이다. 즉, 얕은 네트워크나 가벼운 네트워크를 사용하여 비슷한 성능 또는 훨씬 더 나은 성능을 달성할 수 있습니까?
Another issue is about the CNN training strategy for edge detection, i.e., supervising predictions of different network layers by one general ground truth edge map [49, 30].
For instance, HED [49, 50] and RCF [30] compute edge prediction on each intermediate CNN output to spot edges at different scales, i.e., the lower layers are expected to detect more local image patterns while higher layers capture object-level information with larger receptive fields.
또 다른 문제는 에지 감지를 위한 CNN 훈련 전략, 즉 하나의 일반적인 지상 실측 에지 맵에 의해 다른 네트워크 계층의 예측을 감독하는 것에 관한 것이다[49, 30].
예를 들어, HED[49, 50]와 RCF[30]는 서로 다른 척도에서 에지를 발견하기 위해 각 중간 CNN 출력에서 에지 예측을 계산한다. 즉, 하위 계층은 더 많은 로컬 이미지 패턴을 감지하는 반면 상위 계층은 더 큰 수용 필드로 객체 수준 정보를 캡처할 것으로 예상된다.
Since different network layers attend to depict patterns at different scales, it is not optimal to train those layers with the same supervision. In another word, existing works [49, 50, 30] enforce each layer of CNN to predict edges at all scales and ignore that one specific intermeadiate layer can only focus on edges at certain scales. Liu et al. [31] propose to relax the supervisions on intermediate layers using Canny [4] detectors with layer-specific scales. However, it is hard to decide layer-specific scales through human intervention.
서로 다른 네트워크 계층이 서로 다른 규모의 패턴을 나타내기 때문에 동일한 감독으로 이러한 계층을 교육하는 것이 최적이 아닙니다. 즉, 기존 작업[49, 50, 30]은 CNN의 각 레이어가 모든 스케일에서 에지를 예측하도록 강제하고 하나의 특정 중간 레이어가 특정 스케일의 에지에만 집중할 수 있다는 점을 무시합니다. Liu et al. [31] 레이어별 스케일이 있는 Canny [4] 검출기를 사용하여 중간 레이어에 대한 감독을 완화할 것을 제안합니다. 그러나 인간의 개입을 통해 계층별 척도를 결정하기는 어렵습니다.
Aiming to fully exploit the multiple scale cues with a shallow CNN, we introduce a Scale Enhancement Module (SEM) which consists of multiple parallel convolutions with different dilation rates.
얕은 CNN으로 다중 스케일 신호를 완전히 활용하는 것을 목표로 확장 속도가 다른 다중 병렬 컨볼루션으로 구성된 스케일 향상 모듈(SEM)을 소개한다.
As shown in image segmentation [5], dilated convolution effectively increases the size of receptive fields of network neurons. By involving multiple dilated convolutions, SEM captures multi-scale spatial contexts.
Compared with previous strategies, i.e., introducing deeper networks and explicitly fusing multiple edge detections, SEM does not significantly increase network parameters and avoids the repetitive edge detection on image pyramids.
이미지 분할[5]에서 볼 수 있듯이, 확장된 컨볼루션은 네트워크 뉴런의 수용 필드 크기를 효과적으로 증가시킨다. 다중 확장 컨볼루션을 포함함으로써 SEM은 다중 스케일 공간 컨텍스트를 캡처한다.
더 깊은 네트워크를 도입하고 여러 에지 탐지를 명시적으로 융합하는 이전 전략과 비교하여 SEM은 네트워크 매개 변수를 크게 증가시키지 않으며 이미지 피라미드에서 반복적인 에지 탐지를 피한다.
To address the second issue, each layer in CNN shall be trained by proper layer-specific supervision, e.g., the shallow layers are trained to focus on meaningful details and deep layers should depict object-level boundaries. We propose a Bi-Directional Cascade Network (BDCN) architecture to achieve effective layer-specific edge learning.
두 번째 문제를 해결하기 위해 CNN의 각 계층은 적절한 계층별 감독에 의해 훈련되어야 한다. 예를 들어, 얕은 계층은 의미 있는 세부 사항에 초점을 맞추도록 훈련되고 심층 계층은 객체 수준 경계를 나타내야 한다. 우리는 효과적인 계층별 에지 학습을 달성하기 위해 양방향 캐스케이드 네트워크(BDCN) 아키텍처를 제안한다.
For each layer in BDCN, its layer-specific supervision is inferred by a bi-directional cascade structure, which propagates the outputs from its adjacent higher and lower layers, as shown in Fig. 2. In another word, each layer in BDCN predicts edges in an incremental way w.r.t scale. We hence call the basic block in BDCN, which is constructed by inserting several SEMs into a VGG-type block, as the Incremental Detection Block (ID Block). This bi-directional cascade structure enforces each layer to focus on a specific scale, allowing for a more rational training procedure.
BDCN의 각 계층에 대해, 그것의 계층별 감독은 그림 2에 나타낸 것과 같이, 그것의 인접한 더 높은 계층과 더 낮은 계층으로부터의 출력을 전파하는 양방향 캐스케이드 구조에 의해 추론된다. 즉, BDCN의 각 레이어는 증분 방식으로 에지를 예측한다. 따라서 우리는 여러 SEM을 VGG 유형 블록에 삽입하여 구성되는 BDCN의 기본 블록을 증분 탐지 블록(ID 블록)이라고 부른다. 이 양방향 캐스케이드 구조는 각 레이어가 특정 규모에 집중하도록 하여 보다 합리적인 훈련 절차를 가능하게 한다.
By combining SEM and BDCN, our method achieves consistent performance on three widely used datasets, i.e., BSDS500, NYUDv2, and Multicue. It achieves ODS Fmeasure of 0.828, 1.3% higher than current state-of-the art CED [47] on BSDS500. It achieves 0.806 only using the trainval data of BSDS500 for training, and outperforms the human perception (ODS F-measure 0.803).
SEM과 BDCN을 결합하여, 우리의 방법은 BSDS500, NYUDv2 및 Multicue와 같이 널리 사용되는 세 가지 데이터 세트에서 일관된 성능을 달성한다. 그것은 BSDS500의 현재 최첨단 CED[47]보다 1.3% 높은 0.828의 ODSF 측정을 달성한다. 훈련을 위해 BSDS500의 훈련량 데이터만 사용하여 0.806을 달성하고 인간의 인식(ODSF-측정치 0.803)을 능가한다.
To our best knowledge, we are the first that outperforms human perception by training only on trainval data of BSDS500. Moreover, we achieve a better trade-off between model compactness and accuracy than existing methods relying on deeper models. With a shallow CNN structure, we obtain comparable performance with some well-known methods [3, 42, 2].
우리가 아는 한, BSDS500의 기차 데이터에 대해서만 훈련함으로써 인간의 인식을 능가하는 것은 우리가 처음이다. 또한, 우리는 더 깊은 모델에 의존하는 기존 방법보다 모델 컴팩트성과 정확성 사이에서 더 나은 균형을 달성한다. 얕은 CNN 구조를 사용하여 잘 알려진 일부 방법과 비슷한 성능을 얻는다[3, 42, 2].
For example, we outperform HED [49] using only 1/6 of its parameters. This shows the validity of our proposed SEM, which enriches the multi-scale representations in CNN. This work is also an original effort studying a rational training strategy for edge detection, i.e., employing the BDCN structure to train each CNN layer with layer-specific supervision.
예를 들어, 매개 변수의 1/6만 사용하여 HED[49]를 능가한다. 이것은 CNN의 다중 스케일 표현을 풍부하게 하는 제안된 SEM의 타당성을 보여준다. 이 작업은 또한 에지 감지를 위한 합리적인 훈련 전략을 연구하는 독창적인 노력이다. 즉, BDCN 구조를 사용하여 각 CNN 계층을 계층별 감독으로 훈련시킨다.
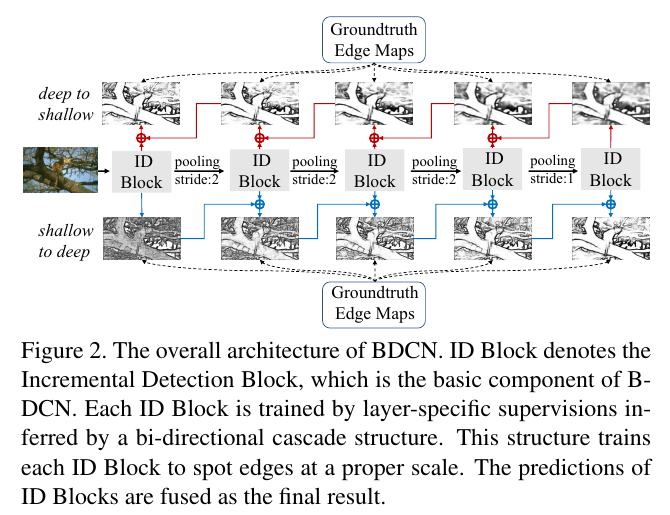
Figure 2. The overall architecture of BDCN. ID Block denotes the Incremental Detection Block, which is the basic component of BDCN. Each ID Block is trained by layer-specific supervisions inferred by a bi-directional cascade structure. This structure trains each ID Block to spot edges at a proper scale. The predictions of ID Blocks are fused as the final result.
그림 2. BDCN의 전반적인 아키텍처입니다. ID 블록은 BDCN의 기본 구성 요소인 증분 탐지 블록을 나타냅니다. 각 ID 블록은 양방향 캐스케이드 구조에 의해 추론된 계층별 감독에 의해 훈련된다. 이 구조는 각 ID 블록을 적절한 축척으로 가장자리를 지정하도록 훈련합니다. ID 블록의 예측은 최종 결과로 융합됩니다.
