Bidirectional Attention-Recognition Model for Fine-Grained Object Classification 제3부
Abstract
Fine-grained object classification (FGOC) is a challenging research topic in multimedia computing with machine learning, which faces two pivotal conundrums: focusing attention on the discriminate part regions, and then processing recognition with the part-based features. Existing approaches generally adopt a unidirectional two-step structure, that first locate the discriminate parts and then recognize the part-based features.
세분화된 객체 분류(FGOC)는 기계 학습을 사용하는 멀티미디어 컴퓨팅에서 어려운 연구 주제로, 구별되는 부분 영역에 주의를 집중한 다음 부분 기반 기능으로 인식을 처리하는 두 가지 핵심적인 문제에 직면한다. 기존 접근 방식은 일반적으로 식별된 부품을 먼저 찾은 다음 부품 기반 특징을 인식하는 단방향 2단계 구조를 채택한다.
However, they neglect the truth that part localization and feature recognition can be reinforced in a bidirectional process. In this paper, we propose a novel bidirectional attention-recognition model (BARM) to actualize the bidirectional reinforcement for FGOC. The proposed BARM consists of one attention agent for discriminate part regions proposing and one recognition agent for feature extraction and recognition. Meanwhile, a feedback flow is creatively established to optimize the attention agent directly by recognition agent.
Therefore, in BARM the attention agent and the recognition agent can reinforce each other in a bidirectional way and the overall framework can be trained end-to-end without neither object nor parts annotations.
Moreover, a novel Multiple Random Erasing data augmentation is proposed, and it exhibits impressive pertinency and superiority for FGOC. Conducted on several extensive FGOC benchmarks, BARM outperforms the present state-of-the-art methods in classification accuracy. Furthermore, BARM exhibits a clear interpretability and keeps consistent with the human perception in visualization experiments.
그러나, 그들은 양방향 프로세스에서 부품 국산화와 특징 인식이 강화될 수 있다는 사실을 무시한다. 본 논문에서는 FGOC에 대한 양방향 강화를 실현하기 위한 새로운 양방향 주의 인식 모델(BARM)을 제안한다. 제안된 BARM은 차별적 부분 영역 제안을 위한 주의 에이전트 1개와 특징 추출 및 인식을 위한 인식 에이전트 1개로 구성된다. 한편, 피드백 흐름은 인식 에이전트에 의해 주의 에이전트를 직접 최적화하기 위해 창의적으로 설정된다.
따라서 BARM에서 주의 에이전트와 인식 에이전트는 양방향 방식으로 서로를 강화할 수 있으며 전체 프레임워크는 객체나 부품 주석 없이 종단 간 훈련을 받을 수 있다.
또한, 새로운 다중 무작위 소거 데이터 증강이 제안되며, FGOC에 대한 인상적인 적합성과 우수성을 보여준다. 여러 광범위한 FGOC 벤치마크에서 수행된 BARM은 분류 정확도에서 현재의 최첨단 방법을 능가한다. 또한, BARM은 명확한 해석 가능성을 나타내며 시각화 실험에서 인간의 인식과 일치한다.
V. CONCLUSION
In this paper, we present a novel bidirectional attentionrecognition model(BARM) for fine-grained object categorization. The attention agent and recognition agent can reinforce each other mutually and the overall network can be trained end-to-end without bounding box/part annotations. We claim two major contributions. First, a feedback flow is established to optimize the attention agent by recognition result. Hence the attention and recognition of FGOC can be reinforced mutually.
Second, a novel data augmentation, Multiple Random Erasing, is proposed in our approach. It is proved by our Multiple Random Erasing that, date translations on the part region is targeted and effective to FGOC. Experimental results demonstrate the superiority of our BARM compared with existing state-of-the-art methods. Moreover, the visualization experiments illustrate the interpretability of BARM with human perception.
본 논문에서는 세분화된 객체 분류를 위한 새로운 양방향 주의 인식 모델(BARM)을 제시한다. 주의 에이전트와 인식 에이전트는 서로 강화할 수 있으며 전체 네트워크는 경계 상자/부품 주석 없이 종단 간 훈련을 받을 수 있다. 우리는 두 가지 주요 기여를 주장한다. 첫째, 인식 결과에 따라 주의 에이전트를 최적화하기 위해 피드백 흐름이 설정된다. 따라서 FGOC에 대한 관심과 인식은 상호적으로 강화될 수 있다.
둘째, 우리의 접근 방식에서 새로운 데이터 확대인 다중 무작위 소거가 제안된다. 부품 영역의 날짜 변환이 FGOC를 대상으로 하고 효과적이라는 것이 다중 무작위 소거에 의해 입증되었다. 실험 결과는 기존의 최첨단 방법과 비교하여 BARM의 우수성을 입증한다. 또한 시각화 실험은 인간의 인식으로 BARM의 해석 가능성을 보여준다.
In the future, we will conduct the research on two directions.
First, we will focus on designing attention agent and its optimization strategy, which can proposal effective and precise part regions. Second, we will also attempt to search targeted augmentation operation for FGOC.
앞으로 우리는 두 가지 방향으로 연구를 진행할 것입니다.
첫째, 효과적이고 정확한 부품 영역을 제안할 수 있는 주의 에이전트와 최적화 전략을 설계하는 데 중점을 둘 것이다. 둘째, 우리는 또한 FGOC에 대한 표적 증강 작업을 검색하려고 시도할 것이다.
I. INTRODUCTION
Fine-grained
Fine grained object classification (FGOC) is a challenging research topic in multimedia computing with machine learning [1]–[5], which aims to distinguish objects from different subordinate-level categories within a general category [6], [7], such as bird species [8], dog breeds [9], pet breeds [10], car models [11], air-craft models [12], flowers categories [13], video retrieval [14]–[16], activity recognition [17], [18] and temporal prediction [19], [20], etc.
FGOC(Finegrained Object Classification)는 기계 학습[1]–[5] 멀티미디어 컴퓨팅에서 도전적인 연구 주제로, 조류 종[6], 개 품종[7], 애완 품종[10], 자동차 모델[11], 항공기 모델[12], 꽃과 같은 일반 범주 내에서 개체를 구별하는 것을 목표로 한다 범주 [13], 비디오 검색 [14]–[16], 활동 인식 [17], [18] 및 시간 예측 [19], [20] 등.
In FGOC task, the objects from intra-category usually appear with marginal visual differences, meanwhile, the objects within the same category can appear significant variation due to the complex backgrounds and changeable pose (Fig. 1).
FGOC 작업에서 범주 내 객체는 일반적으로 근소한 시각적 차이를 가지고 나타나는 반면, 동일한 범주 내 객체는 복잡한 배경과 변경 가능한 포즈로 인해 상당한 차이를 보일 수 있다(그림 1).
Due to the low inter-class but high intra-class variations, the traditional one-step process for inter-class visual categorization encounters bottlenecks. Moreover, the one-step process is a black box method, which takes the entire image for feature learning and directly generates the recognition result. Hence it lacks in the interpretability of the learning strategy. FGOC should be capable of localizing and representing the marginal visual differences within subordinate categories. Correspondingly, the key to an interpretable FGOC lies in two steps: discriminative region localization and fine-grained feature learning from these regions.
클래스 간 차이는 낮지만 클래스 내 차이가 크기 때문에 클래스 간 시각적 분류를 위한 기존의 한 단계 프로세스는 병목 현상에 직면한다. 또한 1단계 프로세스는 기능 학습을 위해 전체 이미지를 가져와서 인식 결과를 직접 생성하는 블랙박스 방식이다. 따라서 학습 전략의 해석 가능성이 부족하다. FGOC는 하위 범주 내의 한계 시각적 차이를 현지화하고 표현할 수 있어야 한다. 이에 상응하여 해석 가능한 FGOC의 핵심은 차별적 지역 현지화와 이러한 지역에서 세분화된 기능 학습의 두 단계에 있다.
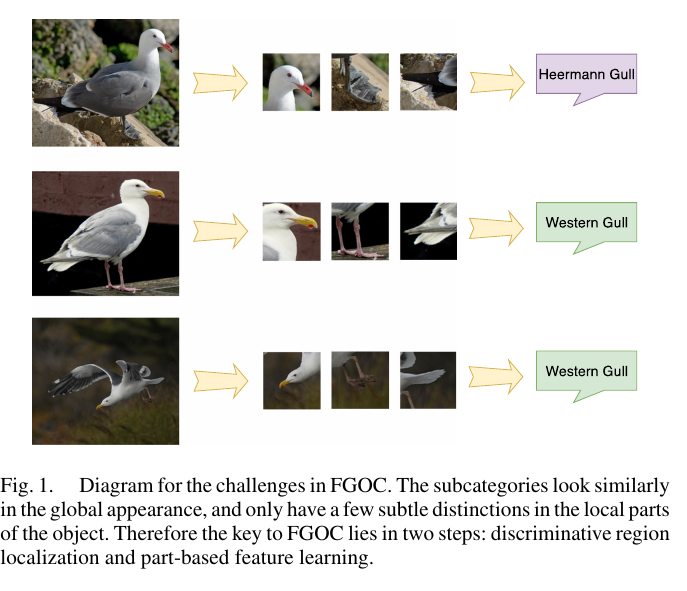
Diagram for the challenges in FGOC. The subcategories look similarly in the global appearance, and only have a few subtle distinctions in the local parts of the object. Therefore the key to FGOC lies in two steps: discriminative region localization and part-based feature learning.
FGOC의 과제에 대한 도표. 하위 범주는 전체적인 모양에서 유사하게 보이고 개체의 로컬 부분에서 몇 가지 미묘한 차이만 보입니다. 따라서 FGOC의 핵심은 차별적 지역 현지화와 부분 기반 기능 학습의 두 단계에 있다.
Recently, deep learning methods have achieved impressive success in computer vision [21]–[23] and a variety of methods have been proposed relying on human bounding box/part annotations [24]–[29]. However, human annotations are expensive.
최근 딥 러닝 방법은 컴퓨터 비전[21-23]에서 인상적인 성공을 거두었으며 인간의 경계 상자/부품 주석[24]-[29]에 의존하는 다양한 방법이 제안되었습니다. 그러나 사람의 주석은 비용이 많이 듭니다.
It requires specialized knowledge and a large amount of time during labeling, making those methods less applicable in practice. To overcome these problems, researchers begin focusing on how to achieve promising performance under the weakly supervised setting without human bounding box/part annotations [30]–[38]. These methods first automatically predict the location of object parts and then extract corresponding local features to predict the object category. Following the strategy finding discriminative parts and then extracting fine-grained features, they neglect the fact that part localization and feature learning can be reinforced mutually by each other [33]. Accordingly, these unidirectional two-step structure exhibit limitations for FGOC.
라벨링 과정에서 전문 지식과 많은 시간이 필요하기 때문에 이러한 방법은 실제로 적용하기 어렵습니다. 이러한 문제를 극복하기 위해 연구자들은 인간의 경계 상자/부품 주석 없이 약하게 감독되는 설정에서 유망한 성능을 달성하는 방법에 집중하기 시작했습니다[30]-[38]. 이러한 방법은 먼저 개체 부분의 위치를 자동으로 예측한 다음 해당 로컬 기능을 추출하여 개체 범주를 예측합니다. 변별적인 부분을 찾은 다음 세분화된 특징을 추출하는 전략에 따라, 그들은 부분 현지화와 특징 학습이 서로에 의해 강화될 수 있다는 사실을 간과한다[33]. 따라서 이러한 단방향 2단 구조는 FGOC에 한계를 보인다.
To fill the gap between part localization and feature learning, in this paper, we propose a novel bidirectional attention recognition model (BARM) for FGOC. As shown in Fig. 2, the proposed BARM consists of one attention agent for part localization and one recognition agent for feature learning and recognition. BARM is well interpretable, since the two agents imitate the attention and recognition in human perception. The attention agent can propose discriminative part localization, helping the recognition agent to learn part-base feature. Meanwhile, the recognition agent feeds back the prediction result to attention agent, which can help the attention agent locate the discriminative part. Moreover, the two-step structure makes BARM transparent for visualization experiments of the attention region.
Therefore, the interpretability of BARM can be clearly validated by human.
부품 현지화와 기능 학습 사이의 격차를 메우기 위해 본 논문에서는 FGOC를 위한 새로운 양방향 주의 인식 모델(BARM)을 제안한다. 제안된 BARM은 그림 2와 같이 부품 현지화를 위한 주의 에이전트 1개와 특징 학습 및 인식을 위한 인식 에이전트 1개로 구성된다. BARM은 두 에이전트가 인간 인식의 주의와 인식을 모방하기 때문에 잘 해석할 수 있다. 주의 에이전트는 식별 가능한 부품 위치 지정을 제안하여 인식 에이전트가 부품 기반 기능을 학습할 수 있도록 지원할 수 있다. 한편, 인식 에이전트는 예측 결과를 주의 에이전트에게 피드백하여 주의 에이전트가 식별 부분을 찾는 데 도움을 줄 수 있다. 또한, 2단계 구조는 주의 영역의 시각화 실험을 위해 BARM을 투명하게 만든다.
따라서 BARM의 해석 가능성은 인간에 의해 명확하게 검증될 수 있다.
Specifically, in this paper, we investigate how the attention and recognition can reinforce each other mutually. Given one image, the attention agent takes the image as input and produces the proposal of discriminative part regions, then the recognition agent learns the part-based features and makes classification. While the recognition agent can be optimized directly by classification result, the optimization strategy for attention agent varies in different research, e.g. saliency information [34], channel grouping loss [33].
구체적으로, 본 논문에서는 관심과 인식이 서로를 강화할 수 있는 방법을 조사한다. 하나의 이미지가 주어지면 주의 에이전트는 이미지를 입력으로 받아들여 차별적인 부분 영역의 제안을 생성한 다음 인식 에이전트는 부품 기반 특징을 학습하고 분류한다. 인식 에이전트는 분류 결과에 의해 직접 최적화될 수 있지만, 주의 에이전트에 대한 최적화 전략은 서로 다른 연구(예: 돌출성 정보[34], 채널 그룹화 손실[33])에서 다양하다.
However, they neglect the fact that part localization and feature learning can be reinforced mutually by each other. As a contrast, the attention agent of BARM can be directly optimized by recognition agent. In BARM, a feedback flow is creatively established to transfer the prediction result from recognition agent to attention agent. Hence the attention agent can understand whether its proposed region produces a correct recognition, therefore it can get optimized directly by recognition agent. In this bi-directional two-step process, the attention agent and recognition agent can reinforce each other mutually and the overall network can be trained end-to-end.
그러나, 그들은 부분 현지화와 특징 학습이 서로에 의해 강화될 수 있다는 사실을 무시한다. 대조적으로, BARM의 주의 에이전트는 인식 에이전트에 의해 직접 최적화될 수 있다. BARM에서는 예측 결과를 인식 에이전트에서 주의 에이전트로 전달하기 위해 피드백 흐름이 창의적으로 설정된다. 따라서 주의 에이전트는 제안된 영역이 올바른 인식을 생성하는지 이해할 수 있으므로, 인식 에이전트에 의해 직접 최적화될 수 있다. 이 양방향 2단계 프로세스에서 주의 에이전트와 인식 에이전트는 서로를 강화하고 전체 네트워크를 종단 간에 훈련시킬 수 있다.
Moreover, a novel data augmentation Multiple Random Erasing is proposed in BARM, which randomly masks serval local rectangle regions out of training images. Since FGOC relies on discriminative part localization and part-based feature learning, the motivation of Multiple Random Erasing is interpretable, as it yields rich local region variations for FGOC.
또한, 훈련 이미지에서 서벌 로컬 직사각형 영역을 무작위로 마스킹하는 새로운 데이터 증강 Multiple Random Eraseing이 BARM에서 제안된다. FGOC는 차별적인 부품 현지화와 부품 기반 기능 학습에 의존하기 때문에, FGOC에 풍부한 로컬 영역 변형을 산출하기 때문에 다중 무작위 소거의 동기는 해석할 수 있다.
Our contributions can be summarized as follows:
-
We address the challenges of fine-grained object classification by proposing a novel bidirectional attentionrecognition model. A feedback flow is established to transfer the prediction result from recognition agent to attention agent, enabling the attention agent and the recognition agent to reinforce each other in a mutual way.
우리는 새로운 양방향 주의 인식 모델을 제안하여 세분화된 객체 분류의 과제를 해결한다. 예측 결과를 인식제에서 주의제로 전달하기 위해 피드백 흐름이 설정되어 주의제와 인식제가 상호적으로 강화될 수 있다. -
A novel data augmentation named Multiple Random Erasing, is specially proposed for FGOC. Since erasing randomly on images is able to introduce information drop on the local part regions, it can improve the robustness of FGOC on discriminative region localization and part-based feature learning. Experiments prove the superiority of Multiple Random Erasing in FGOC.
다중 무작위 소거라는 새로운 데이터 확대는 FGOC를 위해 특별히 제안되었다. 이미지에서 무작위로 지우는 것은 로컬 부품 영역에 정보 드롭을 도입할 수 있기 때문에 차별적 영역 현지화 및 파트 기반 기능 학습에 대한 FGOC의 견고성을 향상시킬 수 있다. 실험은 FGOC에서 다중 무작위 소거의 우수성을 증명한다. -
Our model can be trained end-to-end without the need of bounding box/part annotations. We conduct extensive experiments on three FGOC datasets and achieve the state-of-the-art performance (89.52% on CUB-200-2011, 94.30% on Stanford Cars and 92.50% on FGVC-Aircraft, respectively).
우리의 모델은 경계 상자/부품 주석 없이 종단 간 훈련을 받을 수 있다. 우리는 세 개의 FGOC 데이터 세트에 대해 광범위한 실험을 수행하고 최첨단 성능(CUB-200-2011에서 89.52%, 스탠포드 자동차에서 94.30%, FGVC-항공기에서 92.50%)을 달성한다. -
Our model is highly interpretable according to human perception and the two-step structure makes it transparent for visualization.
우리 모델은 인간의 인식에 따라 해석 가능성이 높으며 2단계 구조로 시각화를 위해 투명하다.
The remainder of this paper is organized as follows. Section II reviews the related work. Section III presents the details of our BARM. Section IV introduces our experimental results and analysis on public benchmark datasets, followed by the conclusions in Section V.
이 논문의 나머지 부분은 다음과 같이 구성되어 있다. 섹션 II는 관련 작업을 검토한다. 섹션 III는 우리의 BARM의 세부사항을 제시한다. 섹션 IV는 공개 벤치마크 데이터 세트에 대한 실험 결과와 분석을 소개한 후 섹션 V의 결론을 소개한다.
II. RELATED WORK
In this section, we will introduce the most related work to our approach. A benchmark of the existing methods is firstly summarized and analyzed. The following is Region Proposal Network, which is employed in our attention agent for discriminative part localization. In the end, we introduce data augmentation methods for training the convolutional neural network
이 섹션에서는 접근 방식과 가장 관련된 작업을 소개합니다. 기존 방법의 벤치마크를 먼저 요약하고 분석한다. 다음은 차별적 부품 현지화를 위한 주의 에이전트에 사용되는 지역 제안 네트워크입니다. 마지막으로, 우리는 컨볼루션 신경망을 훈련하기 위한 데이터 증강 방법을 소개한다
A. Weakly Supervised Fine-Grained Object Classification
The dependence on prior knowledge and human-annotated bounding box/part annotations brings a serious drawback to FGOC. Therefore, most researchers begin to avoid relying on the prior knowledge, and focus on a weakly supervised way to automatically discover which region is discriminative.
사전 지식과 인간 주석이 달린 경계 상자/부품 주석에 대한 의존성은 FGOC에 심각한 단점을 가져온다. 따라서 대부분의 연구자들은 사전 지식에 의존하는 것을 피하기 시작하고, 어떤 지역이 차별적인지 자동으로 발견하기 위해 약하게 감독되는 방법에 초점을 맞추기 시작한다.
Some researches produce the part candidates by selective search [39]. Xiao et al. [31] apply selective search to propose image regions which contain parts of certain objects.
Zhang et al. [40] propose s a dense graph mining algorithm that hierarchically localizes discriminative object parts in each image. Li et al. [6] generate a set of polygons of parts then apply greedy algorithm to select discriminative classifier. Zhang et al. [41] generate multi-scale part proposals and select useful ones to compute a global image representation. Zhang et al. [42], [43] propose a picking strategy to elaborately select distinctive and consistent patches based on the responses of CNN filter banks. However, selective search is time-consuming [44] and poses challenges to accurate part localization.
일부 연구에서는 선택적 검색을 통해 부품 후보를 생성합니다[39]. 샤오 외. [31] 특정 객체의 일부를 포함하는 이미지 영역을 제안하기 위해 선택적 검색을 적용한다.
장 외. [40]은 각 이미지에서 차별적 객체 부분을 계층적으로 국소화하는 고밀도 그래프 마이닝 알고리듬을 제안한다. 거짓말 등. [6] 부품의 폴리곤 집합을 생성한 다음 그리디 알고리즘을 적용하여 판별 분류기를 선택합니다. 장 외. [41] 다중 스케일 부품 제안을 생성하고 글로벌 이미지 표현을 계산하는 데 유용한 제안을 선택합니다. 장 외. [42], [43] CNN 필터 뱅크의 응답을 기반으로 독특하고 일관된 패치를 정교하게 선택하기 위한 선택 전략을 제안한다. 그러나 선택적 검색은 시간이 많이 걸리고[44] 정확한 부품 위치 파악에 어려움을 제기한다.
Some other researches apply visual attention mechanism to automatically capture the informative regions. Liu et al. [36] employ a fully convolutional attention network to adaptively localize multiple parts simultaneously. Fu et al. [32] propose a recurrent attention convolutional neural network, which recursively learns discriminative region attention and region-based feature representation at multiple scales.
Similarly, Zheng et al. [33], [45] propose a part learning approach by a multi-attention convolutional neural network, which jointly learns part proposals and the feature representations on each part. He et al. [46] propose a stacked deep reinforcement learning approach. It adopts a two-stage learning architecture, and the part localization is driven by semantic reward function. Xie et al. [4] introduce a novel fine-grained inference task, Visual Entailment, and propose an explainable architecture with self-attention module [47] to address this task effectively. Qi et al. [48] introduce a multi-scale deep network to model spatial contexts and gated attention surrounding different pixels at various scales. Still, these methods are highly difficult to train due to sophisticated optimization strategy [49].
일부 다른 연구는 시각적 주의 메커니즘을 적용하여 정보 영역을 자동으로 포착한다. 류 외. [36] 여러 부분을 동시에 적응적으로 현지화하기 위해 완전 컨볼루션 주의 네트워크를 사용한다. 퓨우 외. [32] 여러 척도에서 차별적 지역 주의와 지역 기반 특징 표현을 재귀적으로 학습하는 반복 주의 컨볼루션 신경망을 제안한다.
마찬가지로, 정 외. [33], [45]는 부품 제안과 각 부품의 특징 표현을 공동으로 학습하는 다중 주의 컨볼루션 신경망에 의한 부품 학습 접근법을 제안한다. 그 외. [46] 스택형 심층 강화 학습 접근법을 제안한다. 2단계 학습 아키텍처를 채택하고 있으며, 부분 현지화는 의미 보상 기능에 의해 구동된다. 시에 외. [4] 새로운 세분화된 추론 과제인 시각적 수반을 소개하고, 이 과제를 효과적으로 해결하기 위해 자기 주의 모듈[47]로 설명 가능한 아키텍처를 제안한다. 치 외. [48] 공간 컨텍스트와 다양한 스케일의 픽셀을 둘러싼 게이트 주의를 모델링하기 위해 다중 스케일 심층 네트워크를 도입한다. 그럼에도 불구하고, 이러한 방법은 정교한 최적화 전략으로 인해 훈련하기가 매우 어렵다[49].
These researches predominantly solve the task with a unidirectional process, locating discriminative parts and then extracting fine-grained features. Therefore, the process of part localization can not be directly optimized. This limits the accuracy of part localization as well as the final recognition.
이러한 연구는 주로 차별적인 부분을 찾은 다음 세분화된 특징을 추출하는 단방향 프로세스로 작업을 해결한다. 따라서 부품 현지화 프로세스를 직접 최적화할 수 없습니다. 이는 최종 인식뿐만 아니라 부품 위치 파악의 정확도를 제한합니다.
B. Region Proposal Network
A Region Proposal Network (RPN) is a sliding-window class-agnostic object detector. It takes an image as input and outputs a set of rectangular object proposals, each with an objectness score. The idea of RPN is widely used in object detection task [44], [50]–[52]. Similarly, FGOC requires selecting informative part regions, which can also be viewed as object detection.
지역 제안 네트워크(RPN)는 슬라이딩 윈도우 클래스에 구애받지 않는 객체 탐지기이다. 그것은 이미지를 입력으로 받아들이고 각각 객관성 점수를 가진 직사각형 객체 제안 세트를 출력한다. RPN의 개념은 객체 감지 작업[44], [50]–[52]에서 널리 사용된다. 마찬가지로, FGOC는 정보를 제공하는 부분 영역을 선택해야 하며, 이는 객체 감지로도 볼 수 있다.
Drawing on the experience of object detection, some researches introduce RPN for localizing the discriminative regions automatically. He et al. propose a discriminative localization approach via saliency-guided Faster R-CNN (SGFR-CNN) [34], where RPN produces the region proposal to accelerate the process of proposal generation. Yang et al. propose a Navigator-Teacher-Scrutinizer Network (NTS-Net) [35], where the Navigator navigates the model to focus on the most informative regions with RPN.
물체 감지 경험을 바탕으로, 일부 연구는 차별적 영역을 자동으로 현지화하기 위한 RPN을 도입한다. 그 등은 돌출성 유도 고속 R-CNN(SGFR-CNN)[34]을 통해 차별적인 현지화 접근법을 제안한다. 여기서 RPN은 제안 생성 프로세스를 가속화하기 위해 지역 제안을 생성한다. Yang 등은 Navigator-Teacher-Scrutinizer Network(NTS-Net)[35]를 제안한다. 여기서 Navigator는 RPN이 있는 가장 유익한 영역에 초점을 맞추기 위해 모델을 탐색한다.
The RPN is employed in the attention agent of our BARM.
Different from SGFR-CNN which extracts the saliency information for training RPN, our attention agent is directly trained with the feedback from recognition agent. Therefore, our approach is more targeted to the classification task. While the NTS-Net employs a three-agent learning, our BARM imitates human’s vision and employs a two-agent learning with attention agent and recognition agent. Hence the BARM is more consistent with the human perception and the network design is more efficient.
Experimental results show that BARM achieves better performance in recognition over the two mentioned methods.
RPN은 우리 BARM의 주의 에이전트에 사용된다.
RPN을 훈련하기 위해 돌출성 정보를 추출하는 SGFR-CNN과 달리, 우리의 주의 에이전트는 인식 에이전트의 피드백으로 직접 훈련된다. 따라서 우리의 접근 방식은 분류 작업을 더 대상으로 한다. NTS-Net이 3개의 에이전트 학습을 사용하는 반면, 우리의 BARM은 인간의 비전을 모방하고 주의 에이전트와 인식 에이전트가 있는 2개의 에이전트 학습을 사용한다. 따라서 BARM은 인간의 인식과 더 일치하며 네트워크 설계가 더 효율적이다.
실험 결과는 BARM이 언급된 두 가지 방법보다 인식에서 더 나은 성능을 달성한다는 것을 보여준다.
