CSWin Transformer: A General Vision Transformer Backbone with Cross-Shaped Windows 제2부
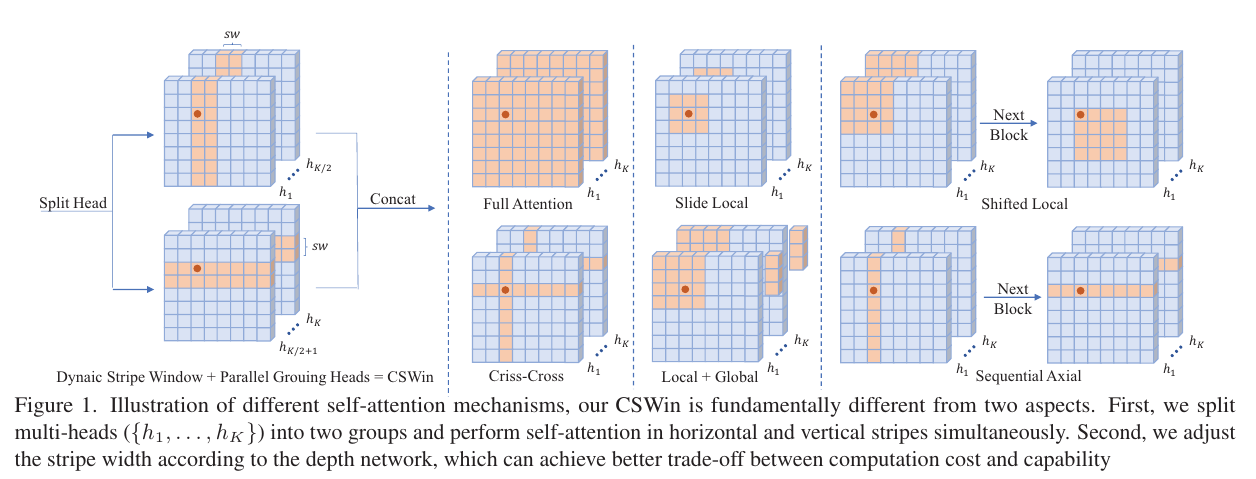
Illustration of different self-attention mechanisms, our CSWin is fundamentally different from two aspects. First, we split multi-heads ({h 1 , . . . , h K }) into two groups and perform self-attention in horizontal and vertical stripes simultaneously. Second, we adjust the stripe width according to the depth network, which can achieve better trade-off between computation cost and capability
서로 다른 self-attention 메커니즘의 예인 우리 CSWin은 두 가지 측면에서 근본적으로 다릅니다. 먼저 멀티헤드({h 1 , . . , h K })를 두 그룹으로 나누고 가로 세로 줄무늬로 자기 주의를 동시에 수행합니다. 둘째, 깊이 네트워크에 따라 스트라이프 너비를 조정하여 계산 비용과 기능 간의 더 나은 균형을 달성할 수 있습니다.
1. Introduction
Transformer-based architectures [12, 30, 42, 49] have recently achieved competitive performances compared to their CNN counterparts in various vision tasks. By leveraging the multi-head self-attention mechanism, these vision Transformers demonstrate a high capability in modeling the longrange dependencies, which is especially helpful for handling high-resolution inputs in downstream tasks, e.g., object detection and segmentation. Despite the success, the Transformer architecture with full-attention mechanism [12] is computationally inefficient.
트랜스포머 기반 아키텍처[12, 30, 42, 49]는 최근 다양한 비전 작업에서 CNN에 비해 경쟁력 있는 성능을 달성했습니다. 이 비전 트랜스포머는 다중 헤드 자체 주의 메커니즘을 활용하여 장거리 종속성을 모델링하는 높은 기능을 보여주며, 이는 특히 객체 감지 및 세분화와 같은 다운스트림 작업에서 고해상도 입력을 처리하는 데 유용합니다. 성공에도 불구하고 전체 주의 메커니즘[12]이 있는 Transformer 아키텍처는 계산적으로 비효율적입니다.
To improve the efficiency, one typical way is to limit the attention region of each token from full-attention to local/windowed attention [30, 44]. To bridge the connection between windows, researchers further proposed halo and shift operations to exchange information through nearby windows. However, the receptive field is enlarged quite slowly and it requires stacking a great number of blocks to achieve global self-attention. A sufficiently large receptive field is crucial to the performance especially for the downstream tasks(e.g., object detection and segmentation). Therefore it is important to achieve large receptive filed efficiently while keeping the computation cost low.
효율성을 향상시키기 위한 한 가지 일반적인 방법은 각 토큰의 주의 영역을 전체 주의에서 로컬/창 주의로 제한하는 것입니다[30, 44]. 창 사이의 연결을 연결하기 위해 연구원들은 가까운 창을 통해 정보를 교환하는 후광 및 교대 작업을 추가로 제안했습니다. 그러나 수용 영역은 매우 느리게 확장되며 글로벌 자기 주의를 달성하기 위해 많은 블록을 쌓아야 합니다. 충분히 큰 수용 필드는 특히 다운스트림 작업(예: 개체 감지 및 분할)의 성능에 중요합니다. 따라서 계산 비용을 낮게 유지하면서 큰 수용 필드를 효율적으로 달성하는 것이 중요합니다.
In this paper, we present the Cross-Shaped Window (CSWin) self-attention, which is illustrated in Figure 1 and compared with existing self-attention mechanisms. With CSWin self-attention, we perform the self-attention calculation in the horizontal and vertical stripes in parallel, with each stripe obtained by splitting the input feature into stripes of equal width.
본 논문에서는 CSWin(Cross-Shaped Window) 셀프 어텐션(Self-attention)을 그림 1과 같이 기존 셀프 어텐션 메커니즘과 비교하여 제시한다. CSWin self-attention을 사용하여 수평 및 수직 스트라이프에서 self-attention 계산을 병렬로 수행합니다. 각 스트라이프는 입력 기능을 동일한 너비의 스트라이프로 분할하여 얻은 것입니다.
This stripe width is an important parameter of the cross-shaped window because it allows us to achieve strong modelling capability while limiting the computation cost.
이 스트라이프 너비는 계산 비용을 제한하면서 강력한 모델링 기능을 얻을 수 있기 때문에 십자형 창의 중요한 매개변수입니다.
Specifically, we adjust the stripe width according to the depth of the network: small widths for shallow layers and larger widths for deep layers. A larger stripe width encourages a stronger connection between long-range elements and achieves better network capacity with a small increase in computation cost. We will provide a mathematical analysis of how the stripe width affects the modeling capability and computation cost.
특히, 우리는 네트워크의 깊이에 따라 스트라이프 너비를 조정합니다: 얕은 레이어의 경우 작은 너비, 깊은 레이어의 경우 더 큰 너비. 스트라이프 너비가 클수록 장거리 요소 간의 연결이 강화되고 계산 비용이 약간 증가하여 네트워크 용량이 향상됩니다. 스트라이프 너비가 모델링 기능과 계산 비용에 미치는 영향에 대한 수학적 분석을 제공합니다.
It is worthwhile to note that with CSWin self-attention mechanism, the self-attention in horizontal and vertical stripes are calculated in parallel. We split the multi-heads into parallel groups and apply different self-attention operations onto different groups. This parallel strategy introduces no extra computation cost while enlarging the area for computing self-attention within each Transformer block.
CSWin self-attention 메커니즘을 사용하면 가로 및 세로 줄무늬의 self-attention이 병렬로 계산된다는 점에 유의할 필요가 있습니다. 우리는 멀티 헤드를 병렬 그룹으로 분할하고 다른 그룹에 서로 다른 자기 주의 작업을 적용합니다. 이 병렬 전략은 각 Transformer 블록 내에서 self-attention을 계산하기 위한 영역을 확장하면서 추가 계산 비용을 도입하지 않습니다.
This strategy is fundamentally different from existing selfattention mechanisms [18, 30, 45, 56] that apply the same attention operation across multi-heads((Figure 1 b,c,d,e), and perform different attention operations sequentially(Figure 1 c,e).
We will show through ablation analysis that this difference makes CSWin self-attention much more effective for general vision tasks.
이 전략은 기존의 selfattention 메커니즘[18, 30, 45, 56]과 근본적으로 다릅니다. 이는 multi-heads에 걸쳐 동일한 주의 작업을 적용하고((그림 1b,c,d,e), 다른 주의 작업을 순차적으로 수행합니다(그림 1). c,e).
우리는 이러한 차이가 CSWin self-attention을 일반적인 비전 작업에 훨씬 더 효과적으로 만든다는 것을 절제 분석을 통해 보여줄 것입니다.
Based on the CSWin self-attention mechanism, we follow the hierarchical design and propose a new vision Transformer architecture named “CSWin Transformer” for general-purpose vision tasks. This architecture provides significantly stronger modeling power while limiting computation cost.
CSWin self-attention 메커니즘을 기반으로 계층적 설계를 따르고 범용 비전 작업을 위한 "CSWin Transformer"라는 새로운 비전 Transformer 아키텍처를 제안합니다. 이 아키텍처는 계산 비용을 제한하면서 훨씬 더 강력한 모델링 능력을 제공합니다.
To further enhance this vision Transformer, we introduce an effective positional encoding, Locally-enhanced Positional Encoding (LePE), which is especially effective and friendly for input varying downstream tasks such as object detection and segmentation. Compared with previous positional encoding methods [9, 35, 45], our LePE imposes the positional information within each Transformer block and directly operates on the attention results instead of the attention calculation. The LePE makes CSWin Transformer more effective and friendly for the downstream tasks.
이 비전 Transformer를 더욱 향상시키기 위해 객체 감지 및 분할과 같은 다양한 다운스트림 작업을 입력하는 데 특히 효과적이고 친숙한 효과적인 위치 인코딩인 LePE(Locally-enhanced Positional Encoding)를 도입했습니다. 이전의 위치 인코딩 방법[9, 35, 45]과 비교하여 LePE는 각 Transformer 블록 내에서 위치 정보를 부과하고 주의 계산 대신 주의 결과에 직접 작동합니다. LePE는 CSWin Transformer를 다운스트림 작업에 더 효과적이고 친숙하게 만듭니다.
As a general vision Transformer backbone, the CSWin Transformer demonstrates strong performance on image classification, object detection and semantic segmentation tasks.
Under the similar FLOPs and model size, CSWin Transformer variants significantly outperforms previous state-of-the-art (SOTA) vision Transformers. For example, our base variant CSWin-B achieves 85.4% Top-1 accuracy on ImageNet-1K without any extra training data or label, 53.9 box AP and 46.4 mask AP on the COCO detection task, 51.7 mIOU on the ADE20K semantic segmentation task, surpassing previous state-of-the-art Swin Transformer counterpart by +1.2, +2.0, 1.4 and +2.0 respectively.
일반적인 비전 Transformer 백본으로서 CSWin Transformer는 이미지 분류, 객체 감지 및 의미론적 분할 작업에서 강력한 성능을 보여줍니다.
유사한 FLOP 및 모델 크기에서 CSWin Transformer 변형은 이전의 SOTA(state-of-the-art) 비전 Transformer를 훨씬 능가합니다. 예를 들어, 기본 변형 CSWin-B는 추가 교육 데이터 또는 레이블 없이 ImageNet-1K에서 85.4% Top-1 정확도, COCO 감지 작업에서 53.9 박스 AP 및 46.4 마스크 AP, ADE20K 시맨틱 분할 작업에서 51.7 mIOU, 이전의 최첨단 Swin Transformer를 각각 +1.2, +2.0, 1.4 및 +2.0 능가했습니다.
Under a smaller FLOPs setting, our tiny variant CSWin-T even shows larger performance gains, i.e.,, +1.4 point on ImageNet classification, +3.0 box AP, +2.0 mask AP on COCO detection and +4.6 on ADE20K segmentation. Furthermore, when pretraining CSWin Transformer on the larger dataset ImageNet-21K, we achieve 87.5% Top-1 accuracy on ImageNet-1K and high segmentation performance on ADE20K with 55.7 mIoU.
더 작은 FLOP 설정에서 우리의 작은 변종 CSWin-T는 ImageNet 분류에서 +1.4 포인트, COCO 감지에서 +2.0 마스크 AP, ADE20K 세분화에서 +4.6과 같은 더 큰 성능 향상을 보여줍니다. 또한 더 큰 데이터 세트 ImageNet-21K에서 CSWin Transformer를 사전 훈련할 때 ImageNet-1K에서 87.5% Top-1 정확도를 달성하고 ADE20K에서 55.7mIoU로 높은 세분화 성능을 달성했습니다.
